 訊飛星辰MaaS平臺實現高性能DeepSeek V3上線
訊飛星辰MaaS平臺實現高性能DeepSeek V3上線
以DeepSeek模型為代表的MoE技術路線,正不斷突破通用大模型的效果上限。其創新的PD優化與大EP推理方案,推動大模型邁向“高性能、低成本、強普惠”的新階段。
事實上,早在1991年,兩位人工智能界的泰斗Michael Jordan與Geoffrey Hinton在論文《Adaptive Mixture of Local Experts》中,就首次提出了MoE框架。隨著大模型應用場景愈加復雜和垂直,大模型參數增大的同時,消耗的算力資源和時間成本也隨之增加。憑借“稀疏激活、低資源消耗、高模型容量”的優勢,MoE逐漸成為大模型開發者的新寵。
DeepSeek模型的成功實踐,為MaaS平臺廠商指明了方向,也帶來了挑戰:如何在提供高性能大模型推理服務的同時,實現對成本的極致控制?四月份,科大訊飛技術團隊通過深度解析DeepSeek-V3 / R1 推理系統成本,發現除了極致的推理性能及吞吐優化外,大模型成本與算力資源有效利用率、首響用戶體驗等體系化的綜合策略緊密關聯。
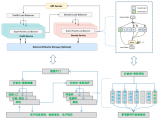
基于以上洞察,訊飛星辰MaaS平臺成功復現了生產級PD(生產部署優化)+大EP(大規模跨節點專家并行),實現了高性能的DeepSeek V3上線:
萬路并發保障:大規模并發場景下,系統穩定、延遲低,用戶體驗更流暢;
請求級指標提升 :TTFT(首Token延遲)性能提升30%,TPOT(單Token生成時間)性能提升35%,顯著減少延遲,降低用戶「等候感」;
彈性混合云架構:支持多源異構算力調度,靈活應對流量波峰波谷。
高性能DeepSeek V3上線:
萬路并發無壓力,批量處理享半價
訊飛星辰 MaaS 平臺始終致力于打造高效、穩定、低成本的大模型推理服務。目前平臺上提供星火全系列,以及DeepSeek、Qwen3等共50+個行業主流模型。在對DeepSeek V3推理系統成本進行深度分析基礎上,實現了DeepSeek V3推理性能的階躍:
關鍵指標對齊官網,萬路并發流暢響應
實現生產級PD+大EP復現,極致壓榨硬件性能,TTFT、TPOT等關鍵指標對齊DeepSeek官網,其中TTFT性能提升30%,TPOT性能提升35%。大規模生產集群吞吐再翻倍,即使在萬級并發壓力下,依然能保持低延遲與流暢響應。
Batch API升級,高效低價數據處理
重點升級了支持DeepSeek V3的Batch API,為需要處理大規模數據且非實時場景的任務,如:企業級數據分析、內容生產、客戶反饋處理等,提供高性價比推理服務且無并發限制,可實現價格比傳統調用降低50%,并在24小時內完成任務處理。
彈性混合云架構,流量洪峰更有保障
星辰MaaS平臺自研了彈性多源異構混合云架構,以自建算力為中心擴展接入多個混合算力,提供穩定可靠的算力保障用戶的流量洪峰,確保服務的穩定性。 針對有大量調用需求的開發者和企業,訊飛星辰MaaS平臺提供了專人對接的定制化方案。
模型工具升級:
精調方案隨心用,500+開源模型自主托管
為進一步降低模型定制門檻,助力開發者快速創新,在提供高性能開源模型的同時,近期,訊飛星辰MaaS平臺實現了多項功能上新:精調方案共享:開放數據分類、表格問答、劇本生成等多個精調方案,零門檻上手,開箱即用,可快速落地在真實業務場景中。
星辰MaaS平臺提供了多種精調方案
以營銷創作腳本為例,用戶只需輸入推廣場景、產品賣點、腳本風格、面向人群等資料,即可實現從「創意構思」到「爆款腳本」的全鏈路智能化生產。
Qwen3全系上線:繼率先支持Qwen3旗艦模型Qwen3-235B-A22B和Qwen3-30B-A3B推理之后,目前Qwen3全系模型均已在星辰MaaS平臺上線,支持推理/訓練,為開發者提供了更為多元的模型選擇空間。
開放自主托管渠道:支持開發者自主托管開源模型,包括HuggingFace提供的開源模型(500+)及平臺預置模型,均可一鍵部署,即用即銷,進一步降低了開發成本,使開發者和企業得以專注于業務邏輯創新,推動AI創新應用落地。
開發者可在“模型選擇”中搜索HuggingFace提供的開源模型平臺預置模型
秉承開放開源理念,下一步,星辰MaaS平臺將開源面向大規模生產級的支持PD調度的集群鏡像方案,實現拓撲感知調度,兼容SGlang、自研等多種推理框架、自帶多源異構彈性混合云調度,支持訓推一體潮汐調度,進一步降低多模型、多算力、高并發的大模型集群部署復雜度。
關于訊飛星辰MaaS平臺:
低門檻一站式大模型精調訓練平臺,助力企業高效構建專屬大模型。
開箱即用,上手快:覆蓋數據工程、精調訓練、推理服務等全生命周期工具鏈,提供開箱即用、即用即銷的平臺服務能力。
模型豐富,應用快:支持星火全系列并兼容DeepSeek、Qwen3等,共50+行業主流大模型版本的微調與服務,微調到應用的工期從幾天降低到小時級。
成熟訓推框架,高可用:構建開箱即用的訓推工具與框架,支持lora、full sft等多種訓練方式,定制模型按需托管,服務可用性99.95%。
算力利用率高,成本低:實現基于彈性混合云訓推算力的潮汐調度,支持即用即銷的大模型自主托管推理模式,持續提升算力資源利用率,實現大模型推理成本持續降低。
-
科大訊飛
+關注
關注
19文章
840瀏覽量
62273 -
大模型
+關注
關注
2文章
3062瀏覽量
3909 -
DeepSeek
+關注
關注
1文章
785瀏覽量
1490
原文標題:高性能DeepSeek V3上線,更快、更穩定
文章出處:【微信號:訊飛開放平臺,微信公眾號:訊飛開放平臺】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
訊飛星辰Agent開發平臺發布
科大訊飛深度解析DeepSeek-V3/R1推理系統成本
商湯大裝置DeepSeek企業版上線
DeepSeek V3昇思MindSpore版本上線開源社區

了解DeepSeek-V3 和 DeepSeek-R1兩個大模型的不同定位和應用選擇
DeepSeek V3/R1滿血版登陸華為云
訊飛開放平臺上線DeepSeek大模型
扣子平臺支持DeepSeek R1與V3模型
DeepSeek-R1全尺寸版本上線Gitee AI
云天勵飛上線DeepSeek R1系列模型






 工商網監
工商網監
評論