 RISC-V向量處理器:現代計算的革命性引擎
RISC-V向量處理器:現代計算的革命性引擎
在數字化高速發展的當下,人工智能、大數據處理、物聯網等前沿技術日新月異,現代計算需求面臨著嚴峻挑戰。海量數據的爆發式增長,讓傳統計算架構在處理大規模數據時顯得力不從心,效率低下、能耗過高、處理速度瓶頸等問題愈發突出。以人工智能領域為例,深度學習模型訓練需要進行海量矩陣運算和復雜的神經網絡計算,對計算設備的計算能力和并行處理能力要求極高;在大數據分析場景中,快速處理TB甚至PB級數據,傳統架構難以在可接受時間內完成任務。這些挑戰迫切需要計算架構創新,以突破現有局限,滿足不斷增長的計算需求。
為應對上述難題,向量擴展(Vector Extension,RVV)作為RISC-V指令集架構的重要拓展被正式引入。RISC-V指令集架構以其開源開放特性著稱,賦予了開發者在設計處理器時極大的靈活性與可擴展性,可針對不同應用場景進行定制化設計。RVV向量擴展通過引入向量指令,實現了對多個數據元素的并行處理,為提升計算性能提供了全新的途徑。相較于傳統的標量計算模式,向量計算在多媒體數據處理、科學計算等領域展現出顯著優勢,能夠有效減少指令執行次數,進而降低計算延遲,全面提升系統整體性能。RVV的出現,為開發者提供了一種高效、靈活且具有成本效益的解決方案,有力推動了計算架構的創新發展,在諸多領域呈現出巨大的應用潛力。在RVV發展浪潮中,賽昉科技昉·天樞-83(Dubhe-83) CPU IP 嶄露頭角。

昉·天樞-83 RISC-V CPU IP
Dubhe-83是一款能效卓越的處理器,具備諸多先進特性:
1. 指令集支持
全面兼容RVA23與RVV Crypto指令集,賦予芯片卓越的指令處理能力,從容應對復雜計算任務。在加密應用場景中,RVV Crypto指令集提供硬件級加密加速,極大提升數據加密與解密效率,為數據安全提供堅實保障。
2. 前端取指和分支預測策略
前端取指和分支預測采用Decouple策略,將取指和分支預測兩個關鍵操作解耦,更高效地處理指令流。同時,分支預測采用業界先進的TAGE-Style算法,能更精準預測程序分支走向,減少因分支預測錯誤導致的流水線停頓,提升處理器執行效率。
3. 流水線設計
擁有10-14 Stage的Pipeline,合理的流水線深度設計在保障指令處理效率的同時,兼顧硬件復雜度與成本。通過多級流水線操作,指令可在不同階段并行處理,加快指令執行速度。
4. 解碼和提交機制
采用3-Way Decode/Rename/Commit機制,可同時對三條指令進行解碼、重命名和提交操作,進一步提升指令處理并行度,提高處理器整體性能。
5. 性能表現
在Benchmark SPECint2006測試中,Dubhe-83分數達9.4/GHz,充分展現其在整數計算性能方面的出色表現,能滿足多種對整數運算要求較高的應用場景。
Dubhe-83在RVV上具有顯著的技術亮點和優勢:
1. 向量計算單元設計
Dubhe-83的Vector的VLEN=DLEN=256,配備2條128-bit的計算單元。此設計大幅提升向量計算能力,可同時處理2x128-bit的數據元素,在向量運算中充分發揮并行計算優勢,加速數據處理。
2. 存儲加載單元(LSU)設計
LSU采用2條Pipeline實現方式,Vector Load/Store和 Scalar Load/Store深度融合。Vector Load/Store帶寬為2x128-bit,這種融合設計在滿足高帶寬需求的同時盡可能節省資源(面積)的開銷,在數據加載和存儲過程中,無論是向量數據還是標量數據,均可高效傳輸和處理,減少數據訪問延遲,提高數據處理效率。
3. 向量工作方式與指令實現
Vector支持LMUL工作方式,每條Vector宏指令采用拆分uop實現方式。只要uop的所有Element在連續兩個Cache Line范圍內,則該 uop可一次性完成讀/寫操作。該設計優化了向量指令執行過程,減少指令執行周期,提升向量帶寬。
4. 向量Load/Store uop實現優勢
Vector Load/Store采用拆分uop實現方式,相較于一些廠商拆分Element的實現方式,在絕大多數應用場景中具有絕對性能優勢。這種實現方式能更高效利用存儲帶寬,減少數據傳輸次數,提高數據加載和存儲效率,進而提升整個系統性能。
5. 亂序執行機制
不僅Scalar采用深度亂序實現方式,Vector也采用深度亂序實現機制。與Vector按序實現方式相比,亂序方式能天然解決許多數據依賴場景。在實際應用中,數據間存在復雜依賴關系,按序執行可能因數據未準備好導致流水線停頓,而亂序執行可靈活調整指令執行順序,優先執行不依賴未就緒數據的uop,顯著提升性能。
6. RVV性能表現
與市場上一些通過In-Order實現的RVV產品相比,Dubhe-83在RiVEC基準測試套件(RiVEC Benchmark Suite,是一個由來自不同領域的數據并行應用程序組成的集合,該套件專注于對向量微架構進行基準測試,各個case的描述詳見下表格)上有著顯著的性能提升,提升從最少22%(Pathfinder)到最高817%(Matmul),其中,應用于高性能計算領域的幾個BLAS算子模型的平均性能提升為357.55%,應用于金融分析/物理仿真/數據挖掘等領域的幾個Dense Linear Algebra算子模型的平均性能提升為315.70%。這些實際應用場景中的性能優勢,充分證明 Dubhe-83在RVV架構和微架構上的先進性和卓越性能表現,能更好滿足用戶對高性能計算的需求。
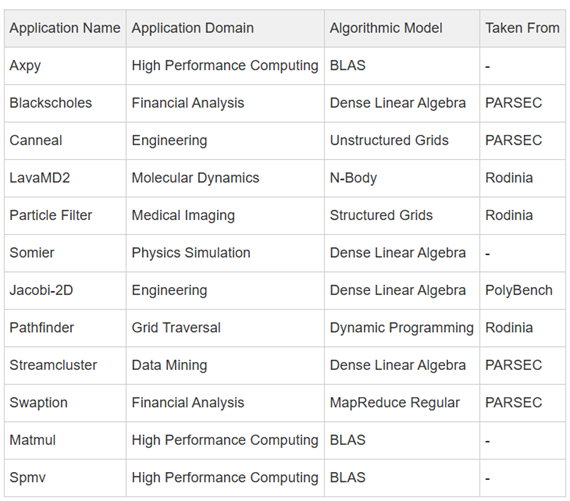
RiVEC Benchmark Suite
-
處理器
+關注
關注
68文章
19833瀏覽量
233945 -
人工智能
+關注
關注
1805文章
48843瀏覽量
247457 -
RISC-V
+關注
關注
46文章
2513瀏覽量
48409
發布評論請先 登錄
RISC-V架構下的編譯器自動向量化






 工商網監
工商網監
評論