") 在IAR Embedded Workbench for Arm中使用Arm Cortex-R52 NEON
在IAR Embedded Workbench for Arm中使用Arm Cortex-R52 NEON
隨著嵌入式系統(tǒng)變得越來(lái)越智能,對(duì)嵌入式處理器的要求也越來(lái)越高。為了更好應(yīng)對(duì)汽車(chē)、醫(yī)療和工業(yè)機(jī)器人等領(lǐng)域?qū)η度胧教幚砥鞯囊螅?a target="_blank">Arm推出了采用Armv8-R架構(gòu)的Cortex-R52。Cortex-R52相對(duì)之前的處理器引入了很多新的特性,其中一個(gè)就是NEON。
本文主要介紹如何在IAR Embedded Workbench for Arm中使用Arm Cortex-R52NEON。
注意:由于Cortex-R52和Cortex-R52+具有相同的指令集并且軟件兼容, 除非特別說(shuō)明,本文中的Cortex-R52同時(shí)包括Cortex-R52和Cortex-R52+。
01Arm Cortex-R52 NEON介紹
Arm NEON概述
大多數(shù)Arm指令是單指令單數(shù)據(jù) (SISD,Single Instruction Single Data):即每條指令對(duì)單個(gè)數(shù)據(jù)執(zhí)行指定的操作,因此,處理多個(gè)數(shù)據(jù)需要多條指令,相對(duì)較慢。為了提高性能和效率,Arm推出了對(duì)應(yīng)的高級(jí)單指令多數(shù)據(jù) (SIMD, Single Instruction Multiple Data)架構(gòu)擴(kuò)展NEON。Arm NEON 是針對(duì)Armv8架構(gòu)Cortex-A和Cortex-R處理器的高級(jí)單指令多數(shù)據(jù)架構(gòu)擴(kuò)展。
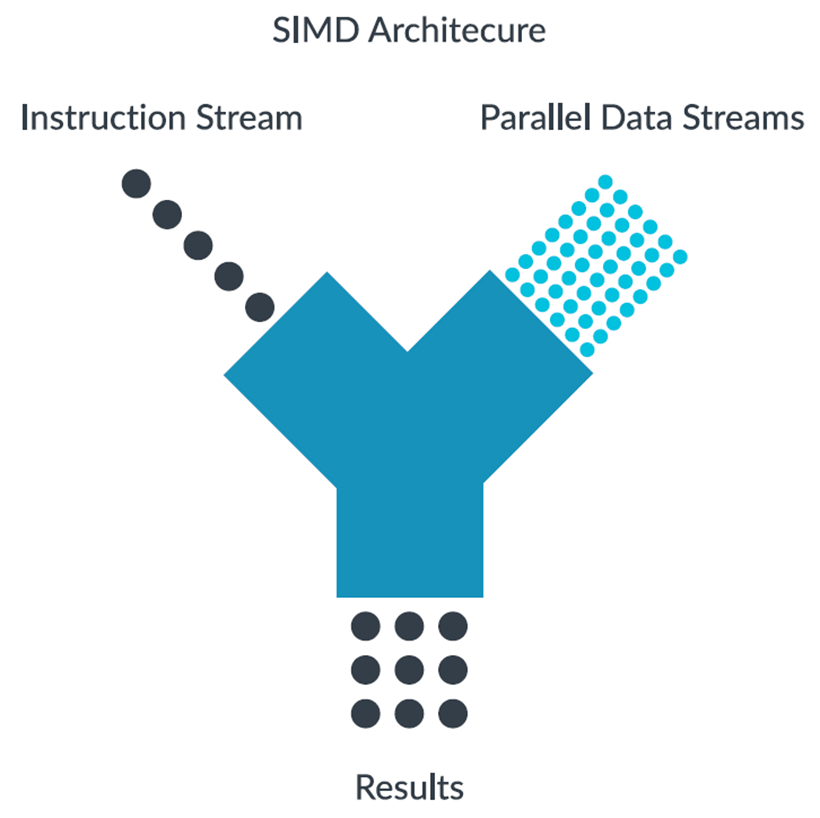
單指令多數(shù)據(jù)指令可同時(shí)對(duì)多個(gè)數(shù)據(jù)執(zhí)行相同的操作,如果數(shù)據(jù)處理很簡(jiǎn)單并且重復(fù)多次,單指令多數(shù)據(jù)指令可以帶來(lái)顯著的性能提升。如下圖所示,單指令多數(shù)據(jù)指令 (ADD V10.4S, V8.4S, V9.4S)可以同時(shí)對(duì)4個(gè)數(shù)據(jù)進(jìn)行加法運(yùn)算:

Arm NEON寄存器(Registers), 向量(Vectors), 通道(Lanes)和元素(Elements)
Arm處理器有通用寄存器(R0-R15),AArch32的通用寄存器寬度是32位,AAarch64的通用寄存器寬度是64位。Arm NEON有對(duì)應(yīng)的NEON寄存器(NEON寄存器數(shù)目跟對(duì)應(yīng)處理器相關(guān)),NEON寄存器寬度是128位,同時(shí)NEON寄存器可以8位、16位、32位、64位或128位寄存器訪問(wèn)。NEON寄存器包含相同數(shù)據(jù)類(lèi)型元素(Elements)的向量(Vectors),輸入和輸出NEON寄存器中相同的元素(Elements)位置稱為通道(Lanes)。
通常,每條NEON指令會(huì)并行執(zhí)行n個(gè)操作,其中n是輸入向量被劃分為的通道數(shù)。每個(gè)操作都包含在通道中,從一個(gè)通道到另一個(gè)通道不能有進(jìn)位或溢出。NEON向量中的通道數(shù)量取決于向量的大小和向量中的元素大小。
128位NEON向量可以包含以下元素大小:
16個(gè)8位元素(操作數(shù)后綴.16B,其中B表示字節(jié)Byte)
8個(gè)16位元素(操作數(shù)后綴.8H,其中H表示半字Half word)
4個(gè)32位元素(操作數(shù)后綴.4S,其中S表示單字Single word)
2個(gè)64位元素(操作數(shù)后綴.2D,其中D表示雙字Double word)
64位NEON向量可以包含以下元素大小(128位寄存器的高64位清零):
8個(gè)8位元素(操作數(shù)后綴.8B,其中B表示字節(jié)Byte)
4個(gè)16位元素(操作數(shù)后綴.4H,其中H表示半字Half word)
2個(gè)32位元素(操作數(shù)后綴.2S,其中S表示單字Single word)
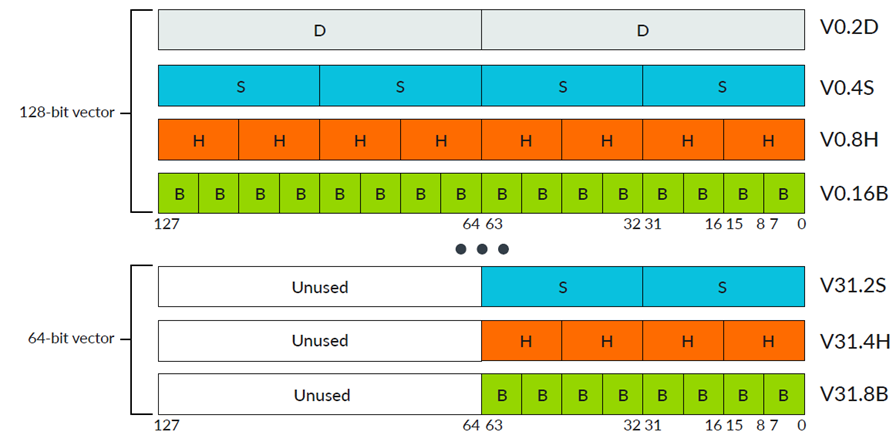
向量中的元素從最低有效位開(kāi)始排序,元素0使用最低有效位。
下面是8個(gè)通道16位元素(8*16 =128)相加的示例:

Arm Cortex-R52 NEON概述
Arm Cortex-R52屬于Armv8-R架構(gòu),Armv8-R架構(gòu)本身支持NEON,Cortex-R52具有對(duì)應(yīng)的NEON配置選項(xiàng):只支持單精度浮點(diǎn)運(yùn)算或者支持單精度、雙精度浮點(diǎn)運(yùn)算和NEON。


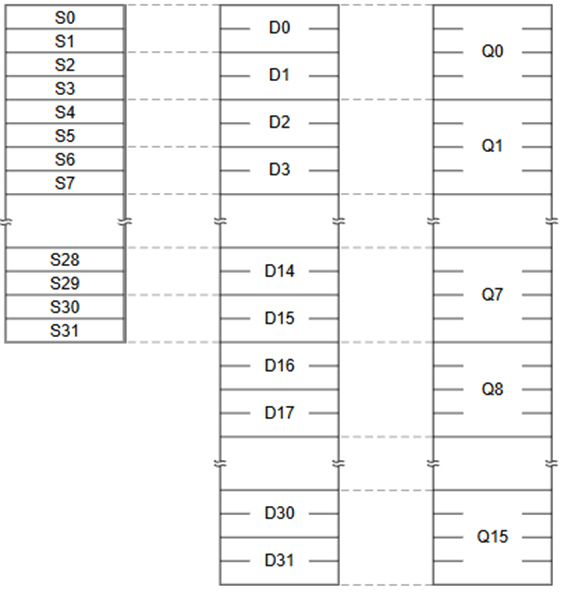
Cortex-R52 NEON包含16個(gè)128位的寄存器,這些寄存器可以當(dāng)作32位的單精度寄存器S0-S31,64位的雙精度寄存器D0-D31或者128位的四字寄存器Q0-Q15:
02Arm NEON使用介紹
作為程序員,您可以有多種方法使用Arm NEON:
支持Arm NEON的庫(kù)
使用支持Arm NEON的庫(kù)(比如Arm Compute Library, Ne10等庫(kù))可以很快捷方便地使用Arm NEON。
編譯器自動(dòng)向量化(Auto-vectorization)
編譯器自動(dòng)向量化可以自動(dòng)優(yōu)化代碼,充分利用Arm NEON。編譯器自動(dòng)向量化一般包含兩部分:
循環(huán)向量化(Loop vectorization):展開(kāi)循環(huán)以減少迭代次數(shù),同時(shí)在每次迭代中執(zhí)行更多操作;
超字并行向量化(SLP,Superword-Level Parallelism vectorization):將多個(gè)標(biāo)量運(yùn)算綁定到一起,使其成為向量運(yùn)算,以充分利用高級(jí)單指令多數(shù)據(jù)指令。
NEON內(nèi)在(intrinsics)函數(shù)
NEON內(nèi)在函數(shù)是編譯器用適當(dāng)?shù)?NEON指令替換的函數(shù)調(diào)用。NEON內(nèi)在函數(shù)提供的控制幾乎與編寫(xiě)匯編語(yǔ)言一樣多,但將寄存器的分配留給編譯器,以便開(kāi)發(fā)人員可以更專注于算法。NEON內(nèi)在函數(shù)在arm_neon.h中定義。
NEON匯編
為了獲得非常高的性能,對(duì)于經(jīng)驗(yàn)豐富的程序員來(lái)說(shuō),編寫(xiě) NEON匯編也是一種選擇。
03在IAR Embedded Workbench for Arm中使用Arm Cortex-R52 NEON
前面介紹了Arm NEON的基本概念和對(duì)應(yīng)的使用方法,下面介紹如何在IAR Embedded Workbench for Arm中使用Arm Cortex-R52 NEON,主要包括使用編譯器自動(dòng)向量化和NEON內(nèi)在函數(shù)。
編譯器自動(dòng)向量化
編譯器自動(dòng)向量化需要指定對(duì)應(yīng)的編譯器選項(xiàng)才能讓編譯器進(jìn)行對(duì)應(yīng)的自動(dòng)向量化優(yōu)化:
對(duì)應(yīng)的處理器支持NEON
對(duì)應(yīng)的編譯選項(xiàng)使能編譯器自動(dòng)向量化
首先要確保對(duì)應(yīng)的處理器支持NEON:
對(duì)應(yīng)的Core要選擇為Cortex-R52/Cortex R52+:
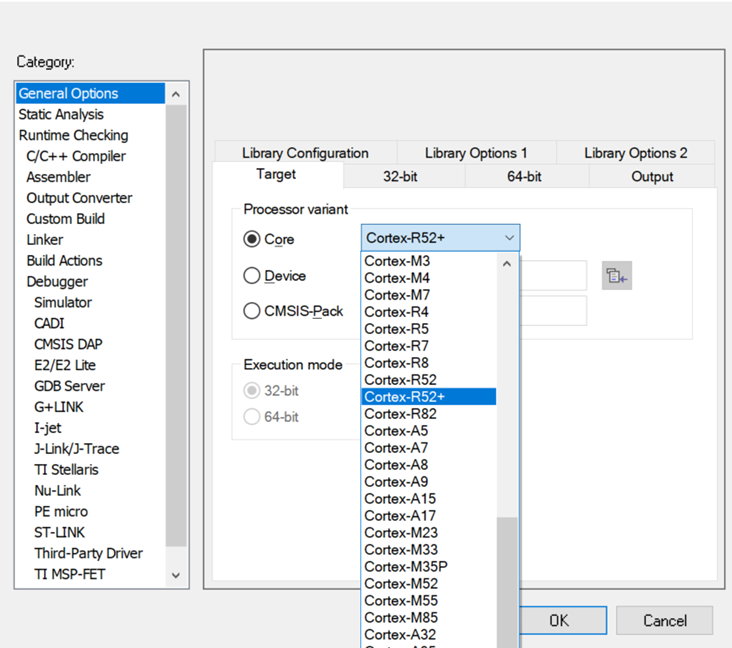
同時(shí)對(duì)應(yīng)FPU要選擇為VFPv5 double precision, D registers要選擇為32,并且要勾選Advanced SIMD (NEON/HELIUM)選項(xiàng):
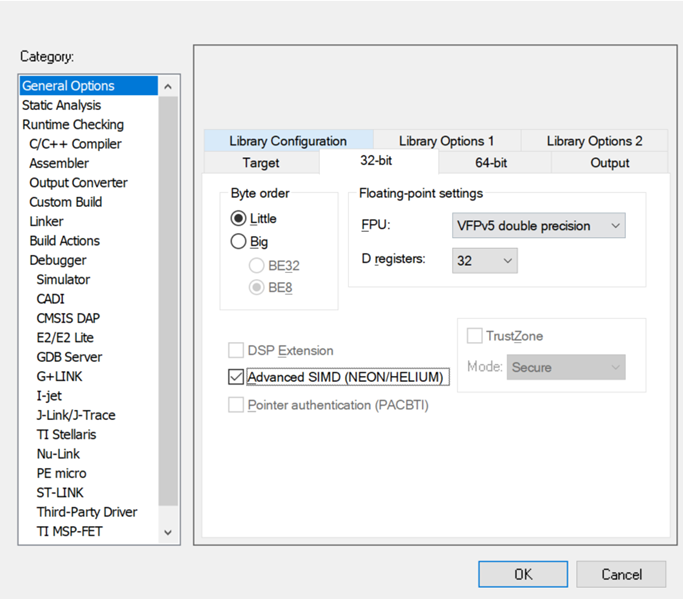
對(duì)應(yīng)CPU和FPU的編譯器選項(xiàng)分別為:--cpu=Cortex-R52/Cortex-R52+和--fpu=VFPv5。
然后對(duì)應(yīng)的編譯器優(yōu)化選項(xiàng)要使能編譯器自動(dòng)向量化:
編譯器優(yōu)化等級(jí)需要選擇為High Speed,并且勾選Vectorization選項(xiàng)才會(huì)使能編譯器自動(dòng)向量化:
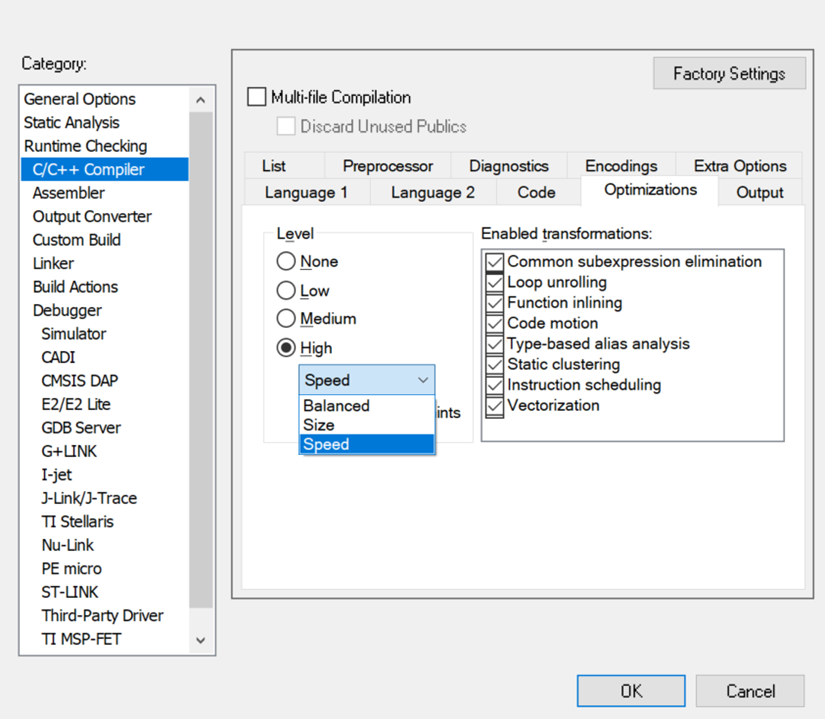
對(duì)應(yīng)編譯器優(yōu)化等級(jí)和自動(dòng)向量化的編譯器選項(xiàng)分別為:-Ohs和--vectorize。
另外可以通過(guò)#pragma vectorize命令對(duì)后面的循環(huán)單獨(dú)使能/不使能編譯器自動(dòng)向量化(只有在編譯器優(yōu)化等級(jí)為High的時(shí)候#pragma vectorize命令才會(huì)生效):

下面通過(guò)一個(gè)簡(jiǎn)單的示例進(jìn)行介紹:
void vec_mul_int (int* vec_A, int* vec_B, int* vec_C, int len_vec)
{
int i;
for (i=0; i
{
vec_C[i] = vec_A[i] * vec_B[i];
}
}
首先不使能編譯器自動(dòng)向量化進(jìn)行編譯,然后查看對(duì)應(yīng)的反匯編代碼(可以使用ielfdumparm xxx.o xxx.txt --code --source命令將對(duì)應(yīng)的.o文件輸出為對(duì)應(yīng)的.txt文件),對(duì)應(yīng)的乘法操作采用的是普通的乘法指令MULS R5, R4, R5:
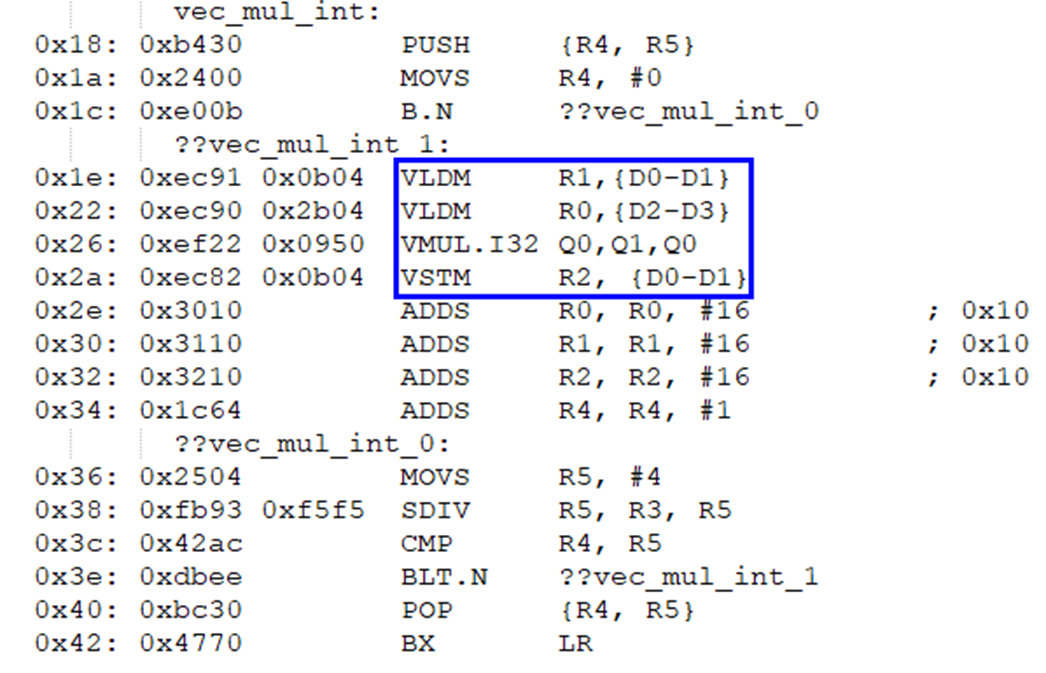
然后使能編譯器自動(dòng)向量化進(jìn)行編譯,查看對(duì)應(yīng)的反匯編代碼使用了NEON相關(guān)的高級(jí)單指令多數(shù)據(jù)指令,其中乘法操作使用了VMUL.I32 Q0,Q0,Q1指令,同時(shí)對(duì)4個(gè)32位整型數(shù)據(jù)(.I32)進(jìn)行乘法操作(VMUL):
NEON內(nèi)在函數(shù)
使用NEON內(nèi)在函數(shù)需要包含對(duì)應(yīng)的頭文件 arm_neon.h:
#include
其中int32x4_t表示的是4個(gè)32位整型數(shù)據(jù),vmulq_s32表示的是對(duì)s32(32位整型)數(shù)據(jù)進(jìn)行向量乘法操作。
查看對(duì)應(yīng)的反匯編代碼,對(duì)應(yīng)的vmulq_s32 NEON內(nèi)在函數(shù)被翻譯為對(duì)應(yīng)NEON相關(guān)的高級(jí)單指令多數(shù)據(jù)指令,其中乘法操作使用了VMUL.I32 Q0,Q1,Q0指令,同時(shí)對(duì)4個(gè)32位整型數(shù)據(jù)(.I32)進(jìn)行乘法操作(VMUL):
04總結(jié)
本文首先介紹了Arm NEON的基本概念,然后介紹了使用Arm NEON的通用方法,最后詳細(xì)介紹了如何在IAR Embedded Workbench for Arm中使用Arm Cortex-R52 NEON,包括使用編譯器自動(dòng)向量化和NEON內(nèi)在函數(shù),用戶可以根據(jù)項(xiàng)目具體情況選擇合適的策略。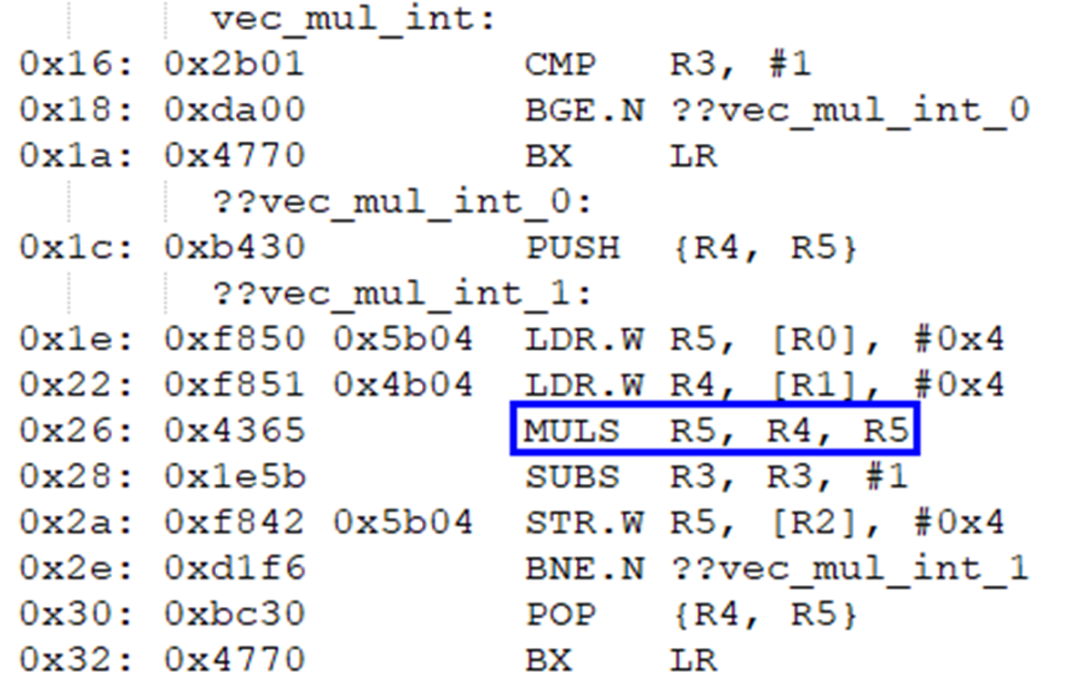

void vec_mul_int(int* vec_A, int* vec_B, int* vec_C, int len_vec)
{
int i;
for (i=0; i<(len_vec / 4); i++)
{
*((int32x4_t*)vec_C) = vmulq_s32(*((int32x4_t*)vec_A), *((int32x4_t*)vec_B));
vec_A = vec_A + 4;
vec_B = vec_B + 4;
vec_C = vec_C + 4;
}
}
-
ARM
+關(guān)注
關(guān)注
134文章
9328瀏覽量
375712 -
嵌入式
+關(guān)注
關(guān)注
5144文章
19575瀏覽量
315813 -
IAR
+關(guān)注
關(guān)注
5文章
372瀏覽量
37320 -
Embedded
+關(guān)注
關(guān)注
0文章
50瀏覽量
22747 -
編譯器
+關(guān)注
關(guān)注
1文章
1657瀏覽量
49983
原文標(biāo)題:在IAR Embedded Workbench for Arm中使用Arm Cortex-R52 NEON
文章出處:【微信號(hào):IAR愛(ài)亞系統(tǒng),微信公眾號(hào):IAR愛(ài)亞系統(tǒng)】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
IAR Systems支持全新Arm Cortex-M85處理器

ARM發(fā)布實(shí)時(shí)處理用CPU內(nèi)核Cortex-R52 瞄準(zhǔn)自動(dòng)駕駛汽車(chē)

在IAR Embedded Workbench中進(jìn)行ARM+RISC-V多核調(diào)試
在 IAR Embedded Workbench中進(jìn)行ARM+RISC-V多核調(diào)試
Arm Cortex-R52處理器技術(shù)參考手冊(cè)
ARM Cortex-R52處理器技術(shù)參考手冊(cè)
Cortex-R52循環(huán)模型用戶指南
IAR Systems發(fā)布 IAR Embedded Wor
IAR_embedded_Workbench用戶指南介紹
ARM Cortex-R52專屬汽車(chē)安全管理程序面世

IAR ARM集成開(kāi)發(fā)環(huán)境學(xué)習(xí)教程






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論