 【免費送書】DeepSeek 核心技術揭秘免費申請體驗
【免費送書】DeepSeek 核心技術揭秘免費申請體驗

2025年年初,DeepSeek成為全球人工智能(AI)領域的焦點,其DeepSeek-V3和DeepSeek-R1版本在行業內引發了結構性震動。
DeepSeek-V3是一個擁有6710億個參數的混合專家模型(MoE),每個token(模型處理文本的基本單位)激活370億個參數。該模型在14.8萬億個高質量token上進行預訓練,采用MLA和MoE架構。DeepSeek-V3的發布幾乎沒有預熱和炒作,僅憑借其出色的效果和超低的成本迅速走紅。
DeepSeek-R1則是在DeepSeek-V3的基礎上構建的推理模型,它在后訓練階段大規模使用強化學習技術,僅憑極少標注數據便大幅提升了模型的推理能力。在數學、代碼、自然語言推理等任務上,DeepSeek-R1的效果已可比肩OpenAI-o1正式版。
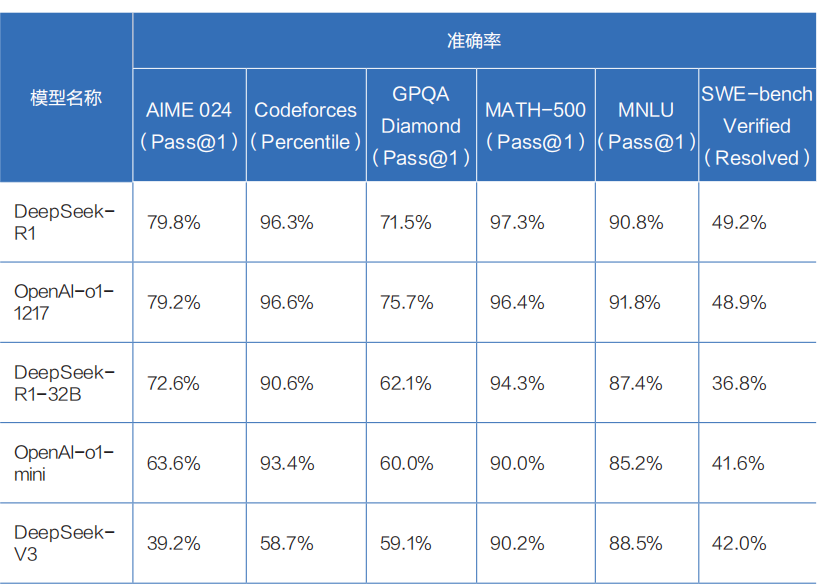
DeepSeek-R1 在基準測試中的表現
DeepSeek-V3技術突破
DeepSeek-V3的模型架構整體上基于Transformer的MoE架構,并在細節實現上做了大量的創新和優化,如大量小專家模型、多頭潛在注意力、無輔助損失的負載平衡、多token預測技術(MTP)等,大幅提升了模型的性能。
在模型訓練方面,DeepSeek依托自研的輕量級分布式訓練框架HAI-LLM,通過算法、框架和硬件的緊密配合,突破了跨節點MoE訓練中的通信瓶頸,實現了高效穩定的訓練。DeepSeek-V3 是業界率先使用FP8進行混合精度訓練的開源模型。
在推理部署方面,DeepSeek-V3采用預填充(Prefilling)和解碼(Decoding)分離的策略,以及冗余專家策略,在提高推理速度的同時確保了系統的穩定性和可靠性。
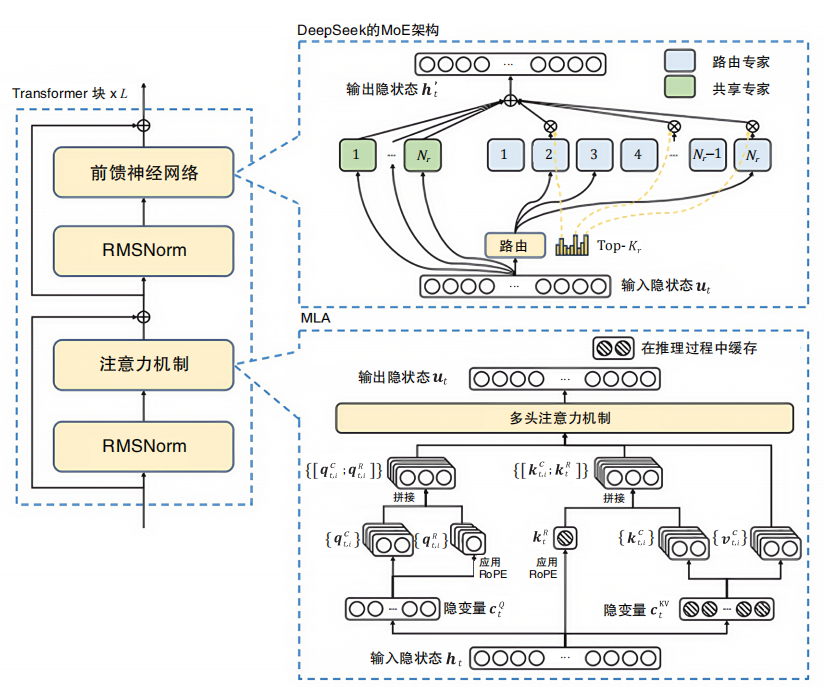
DeepSeek 架構圖
DeepSeek-R1技術突破
01.純強化學習訓練
DeepSeek-R1-Zero的核心創新之一是采用純強化學習(Reinforcement Learning,RL)進行訓練。這一方法顛覆了傳統的依賴有監督微調(Supervised Fine-Tuning,SFT)和人類反饋強化學習(Reinforcement Learning from Human Feedback,RLHF)的訓練模式,首次驗證了無須任何SFT數據,僅通過強化學習即可實現推理能力的自主進化。
02.GRPO 算法GRPO算法是DeepSeek-R1-Zero使用的另一個重要的創新算法。與傳統的強化學習算法(如PPO、DPO)不同,GRPO算法通過組內獎勵對比直接優化策略網絡。具體而言,GRPO 算法將同一問題生成的N條候選答案劃為一組,以組內平均獎勵為基線,計算相對優勢值。這種方法不需要額外訓練價值模型,降低了訓練復雜度,提高了訓練效率。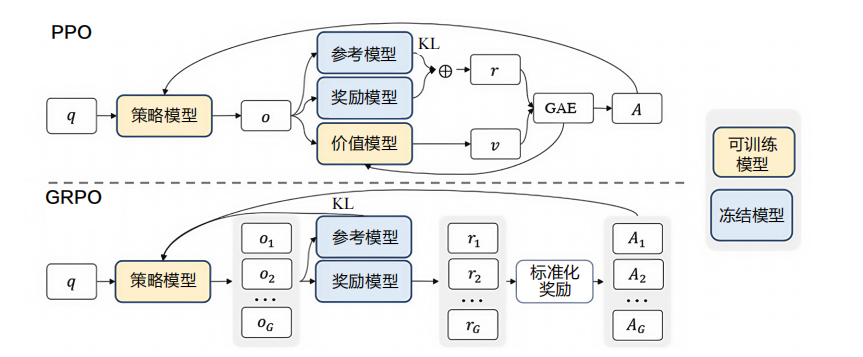
GRPO 與 PPO 對比示意圖
03.獎勵模型的創新在強化學習的訓練過程中,DeepSeek研究團隊選擇面向結果的獎勵模型,而不是通常的面向過程的獎勵模型。這種方式可以較好地避免獎勵欺騙,同時,由于不需要大量標注數據,可以降低訓練復雜度。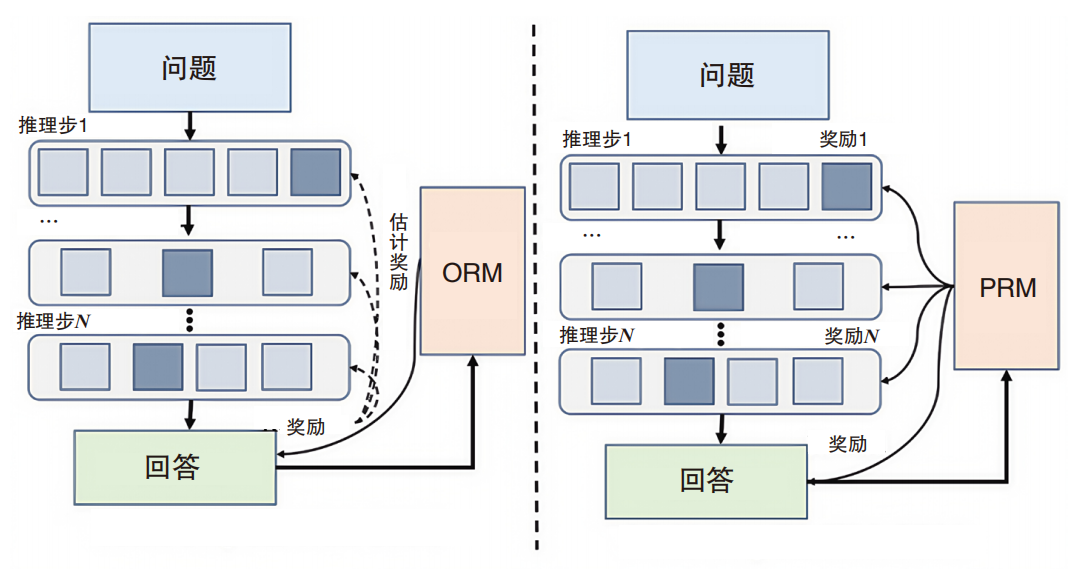
結果獎勵和過程獎勵
“冷啟動+多階段RL”
為了解決純強化學習訓練帶來的可讀性差和多語言混雜等問題,DeepSeek-R1采用“冷啟動+多階段RL”的訓練策略。在冷啟動階段,引入數千條高質量的長思維鏈數據對基礎模型進行微調,強制規范輸出格式,提高可讀性。隨后,通過兩階段強化學習進一步優化模型的性能。
推理導向RL:結合規則獎勵(如答案準確性、語言一致性),優化模型在數學、編程等結構化任務中的表現。
通用對齊RL:融入人類偏好獎勵模型,確保模型在開放域任務中的安全性與實用性。
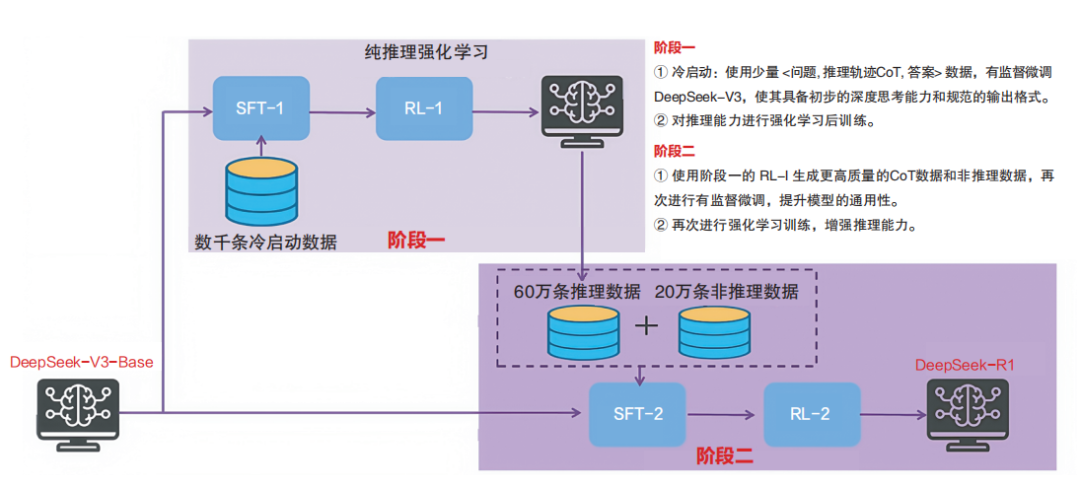
DeepSeek-R1 的訓練過程
DeepSeek-R1-Zero在訓練初期沒有人工示范,完全靠自己摸索。就像讓小孩自己解謎題,結果他居然悟出了很多強大的解題技巧!但僅靠自我摸索的 DeepSeek-R1-Zero 給出的答案有時很難讀懂,甚至會中英文混雜,或者偏離人們習慣的表達方式。
因此,在訓練 DeepSeek-R1 時,DeepSeek 研究團隊對模型進行了兩次額外的調整:第一次是喂給它一些冷啟動的例子,相當于給模型打好基礎,讓它知道回答時的基本禮儀和清晰度;第二次是在強化學習之后,收集在訓練中表現優秀的解題示例,再混合一些人工整理的題目,重新訓練模型。通過這樣的流程,DeepSeek-R1 就像一個經歷了自學、糾錯、再學習、再實戰的學生,已成長為解題高手。
上述過程還揭示了一個少有人注意的基本原則,那就是要讓模型自由地思考。在許多 AI實驗中,模型的結構約束越少,則當計算資源增加時,最終性能的上限越高。反之,如果在早期給模型添加過多的結構約束,則它的最終表現可能會受到限制,失去了更多自主探索的可能性。在各種訓練模型推理能力的范式中,基于結果獎勵的強化學習給模型的約束最少。以結果為導向,用結果來激勵——“Don’t teach, incentivize.”也就是說,不要去“教”模型,而要“激勵”它自主探索。
《DeepSeek核心技術揭秘》是剖析DeepSeek技術原理的專業技術書,以全面的內容、深入的技術原理解析和前瞻性的行業洞察,為技術人員、研究人員和大模型相關技術愛好者提供了寶貴的學習資料。
本書目錄結構 第1章介紹DeepSeek的一系列技術突破與創新,如架構創新、訓練優化、推理與部署優化等,讓讀者對DeepSeek的性能突破形成直觀的認識。同時,介紹DeepSeek的模型家族,涵蓋通用語言模型、多模態模型、代碼生成與理解等領域,展現了DeepSeek在大模型的不同細分領域取得的成就。
第2章為初學者深入淺出地講解DeepSeek的使用方法。從推理模型與通用模型的差異,到具體的使用案例,讀者可以直觀地感受DeepSeek在實際應用中的強大功能。對提示工程的詳細介紹,可以幫助讀者了解如何通過精心設計的提示詞更好地發揮DeepSeek的能力。對提示詞鏈的高級使用技巧的介紹,為讀者進一步提升DeepSeek使用效果提供參考。
第3章和第4章是本書的核心與精華。
第3章深入剖析DeepSeek-V3的模型架構、訓練框架、推理階段優化、后訓練優化等關鍵技術。從混合專家模型(MoE)的起源與發展,到DeepSeek-V3的MoE優化,再到對多頭潛在注意力(MLA)機制和多token預測的詳細解讀,幫助讀者全面了解DeepSeek-V3在技術上的先進性和創新性。同時,對訓練框架的并行策略、FP8混合精度訓練及推理階段的優化等內容的深入分析,展示了DeepSeek在提升效率和性能方面的不懈追求。
第4章關于DeepSeek-R1的技術剖析同樣精彩紛呈。預備知識的介紹為讀者理解后續內容打下了堅實的基礎。對DeepSeek-R1-Zero的組相對策略優化(GRPO)算法、獎勵模型等關鍵技術的深入剖析,可以幫助讀者了解DeepSeek在強化學習領域的創新性探索。對DeepSeek-R1 的訓練過程和推理能力的蒸餾等內容的詳細闡述,能讓讀者對這一創新技術的特點有全面的認知。
第5章從宏觀的角度分析DeepSeek對人工智能技術格局的影響,包括打破硬件依賴迷思、沖擊英偉達CUDA護城河、引發大模型技術路線的重新思考等多個方面。同時,總結了DeepSeek 成功背后的啟示,如領導者敏銳的技術直覺、長期主義的堅持、極致的工程優化等,為讀者提供了寶貴的經驗和啟示。
第6章對DeepSeek“開源周”的多個技術項目進行了深入的分析。通過對FlashMLA、DeepEP、DeepGEMM、DualPipe與EPLB、3FS等項目的介紹,展示了DeepSeek在開源領域的積極探索,體現了其推動大模型技術普及和發展的決心。這些技術項目的詳細解讀,能讓讀者了解DeepSeek在降低人工智能技術門檻、促進技術交流與合作方面的巨大貢獻。
第7章對大模型的發展進行了討論。從MoE的發展趨勢、MLA的展望,大模型的訓練方法、推理部署,到GPU硬件及推理模型的發展趨勢,以前瞻性的視角為讀者描繪了大模型的發展藍圖。
 DeepSeek核心+配套視頻課程
DeepSeek核心+配套視頻課程
本書由一線資深技術人員編寫,知識點講解清晰。內容完全圍繞DeepSeek核心技術展開,提煉精華,不討論與DeepSeek有關的大模型基礎,而是關注DeepSeek本身。
盧菁,北京科技大學博士,北京大學博士后,B站、視頻號優秀科技博主。曾任職于騰訊、愛奇藝等知名互聯網公司,主要從事人工智能技術的應用和研發工作,主要研究方向為大模型、多模態、自然語言處理、知識圖譜、推薦系統等。著有《速通機器學習》《速通深度學習數學基礎》。
戴志仕,資深AI架構師,“寒武紀人工智能”公眾號的創立者。2024年CCF國際AIOps挑戰賽優秀獎獲得者。擁有十余年人工智能算法研究和產業落地經驗,成功實施過多個人工智能項目。
申請時間
2025年6月9日——2025年7月11日
活動參與方式
1、在本帖下方留言回帖說說你想要這本書的理由15字以上。
2、我們將從本帖留言中挑選3位幸運者贈送此書籍,共贈送4本。
3、請在收到書籍后2個星期內提交不少于2篇試讀報告要求300字以上圖文并茂。
4、試讀報告發表在電子發燒友論壇>>社區活動專版標題名稱必須包含【「DeepSeek 核心技術揭秘」閱讀體驗】+自擬標題
注意事項
1、活動期間如有作弊、灌水等違反電子發燒友論壇規則的行為一經發現將立即取消獲獎資格
2、活動結束后獲獎名單將在論壇公示請活動參與者盡量完善個人信息如管理員無法聯系到選中的評測者則視為自動放棄。
3、申請人收貨后14天內未完成書評無權將書籍出售或轉贈給他人。如無法在收貨后14天內提交書評請將書籍退回電子發燒友論壇運費自理。
4、如有問題請咨詢工作人員(微信:elecfans123)。


聲明:本文由電子發燒友社區發布,轉載請注明以上來源。如需平臺(包括:試用+專欄+企業號+學院+技術直播+共建社區)合作及入群交流,請咨詢18925255684(微信同號:elecfans123),謝謝!
-
人工智能
+關注
關注
1807文章
49029瀏覽量
249586 -
DeepSeek
+關注
關注
1文章
798瀏覽量
1757
發布評論請先 登錄
【「DeepSeek 核心技術揭秘」閱讀體驗】書籍介紹+第一章讀后心得
大家都在用什么AI軟件?有沒有好用的免費的AI軟件推薦一下?
【書籍評測活動NO.62】一本書讀懂 DeepSeek 全家桶核心技術:DeepSeek 核心技術揭秘
比亞迪 · 超級e平臺 · 技術方案的全面揭秘 | 第三曲: 30000轉驅動電機 · 12項核心技術揭秘

【干貨】開關電源相關設計資料46篇--2
【干貨】開關電源相關設計資料46篇--1
算力筑基!揭秘DeepSeek爆火的“心跳密碼”——時鐘同步

鴻蒙原生應用開發也可以使用DeepSeek了
淺談DeepSeek核心技術與應用場景
添越智創基于 RK3588 開發板部署測試 DeepSeek 模型全攻略
了解DeepSeek-V3 和 DeepSeek-R1兩個大模型的不同定位和應用選擇
深入探討DeepSeek大模型的核心技術







 工商網監
工商網監
評論