") Transformer架構(gòu)概述
Transformer架構(gòu)概述
由于Transformer模型的出現(xiàn)和快速發(fā)展,深度學(xué)習(xí)領(lǐng)域正在經(jīng)歷一場(chǎng)翻天覆地的變化。這些突破性的架構(gòu)不僅重新定義了自然語言處理(NLP)的標(biāo)準(zhǔn),而且拓寬了視野,徹底改變了AI的許多方面。
以其獨(dú)特的attention機(jī)制和并行處理能力為特征,Transformer模型證明了在理解和生成人類語言方面的創(chuàng)新飛躍,其準(zhǔn)確性和效率是以前無法實(shí)現(xiàn)的。
谷歌在2017年一篇題為《attention就是你所需要的一切》的文章中首次提出,Transformer架構(gòu)是ChatGPT等突破性模型的核心。它們?cè)贠penAI的尖端語言模型中發(fā)揮了重要作用,并在DeepMind的AlphaStar中發(fā)揮了關(guān)鍵作用。
在這個(gè)AI的變革時(shí)代,Transformer模型對(duì)有抱負(fù)的數(shù)據(jù)科學(xué)家和NLP從業(yè)者的重要性怎么強(qiáng)調(diào)都不為過。作為大多數(shù)最新技術(shù)飛躍的核心領(lǐng)域之一,本文旨在破譯這些模型背后的秘密。
什么是Transformer?
Transformer最初是為了解決序列轉(zhuǎn)導(dǎo)或神經(jīng)機(jī)器翻譯的問題而開發(fā)的,這意味著它們旨在解決將輸入序列轉(zhuǎn)換為輸出序列的任何任務(wù)。這就是為什么他們被稱為“Transformer”。
什么是Transformer模型?
Transformer模型是一個(gè)神經(jīng)網(wǎng)絡(luò),它學(xué)習(xí)順序數(shù)據(jù)的上下文并從中生成新數(shù)據(jù)。簡(jiǎn)單地說是一種AI模型,它通過分析大量文本數(shù)據(jù)中的模式來學(xué)習(xí)理解和生成類似人類的文本。
Transformer是當(dāng)前最先進(jìn)的NLP模型,被認(rèn)為是編碼器-解碼器架構(gòu)的演變。但編碼器-解碼器架構(gòu)主要依賴于循環(huán)神經(jīng)網(wǎng)絡(luò)(RNN)來提取序列信息,Transformer則完全缺乏這種循環(huán)性。
那么,他們是怎么做到的呢?

Transformer是專門設(shè)計(jì)來通過分析不同元素之間的關(guān)系來理解上下文和意義的,它們幾乎完全依賴于一種叫做attention的數(shù)學(xué)技巧來做到這一點(diǎn)。
歷史背景
Transformer模型起源于谷歌2017年的一篇研究論文,是機(jī)器學(xué)習(xí)領(lǐng)域最新和最有影響力的發(fā)展之一。第一個(gè)Transformer模型在有影響力的論文《attention就是你所需要的一切》中得到了解釋。
這個(gè)開創(chuàng)性的概念不僅是一個(gè)理論的進(jìn)步,而且還找到了實(shí)現(xiàn),特別是在TensorFlow的Tensor2Tensor包中。此外,哈佛NLP小組通過提供論文的注釋指南以及PyTorch實(shí)現(xiàn)對(duì)這個(gè)新興領(lǐng)域做出了貢獻(xiàn)。
它們的引入刺激了該領(lǐng)域的顯著增長(zhǎng),通常被稱為Transformer AI。這個(gè)革命性的模型為隨后在大型語言模型領(lǐng)域(包括BERT)的突破奠定了基礎(chǔ)。到2018年,這些發(fā)展已經(jīng)被譽(yù)為NLP的分水嶺。
2020年,OpenAI的研究人員宣布了GPT-3。在幾周內(nèi),GPT-3的多功能性很快得到了證明,人們用它來創(chuàng)作詩歌、程序、歌曲、網(wǎng)站和更多吸引全球用戶想象力的東西。
在2021年的一篇論文中,斯坦福大學(xué)的學(xué)者們恰當(dāng)?shù)貙⑦@些創(chuàng)新稱為基礎(chǔ)模型,強(qiáng)調(diào)了它們?cè)谥厮蹵I方面的基礎(chǔ)作用。他們的工作突出了Transformer模型如何不僅徹底改變了該領(lǐng)域,而且推動(dòng)了AI可實(shí)現(xiàn)的前沿,預(yù)示著一個(gè)充滿可能性的新時(shí)代。
谷歌的前高級(jí)研究科學(xué)家、企業(yè)家Ashish Vaswani說:“我們正處在這樣一個(gè)時(shí)代,像神經(jīng)網(wǎng)絡(luò)這樣的簡(jiǎn)單方法正在給我們帶來新能力的爆炸式增長(zhǎng)。”
從像LSTM這樣的RNN模型到用于NLP問題的transformer的轉(zhuǎn)變
在Transformer模型引入時(shí),RNN是處理順序數(shù)據(jù)的首選方法,其特征在于其輸入中的特定順序。RNN的功能類似于前饋神經(jīng)網(wǎng)絡(luò),但它按順序處理輸入,每次處理一個(gè)元素。
Transformer的靈感來自于RNN中的編碼器-解碼器架構(gòu)。但是,Transformer模型完全基于attention機(jī)制,而不是使用遞歸。
除了提高RNN的性能,Transformer還提供了一種新的架構(gòu)來解決許多其他任務(wù),如文本摘要、圖像字幕和語音識(shí)別。
那么,RNN的主要問題是什么呢?它們對(duì)于NLP任務(wù)是無效的,主要有兩個(gè)原因:
它們依次處理輸入數(shù)據(jù)。這種循環(huán)過程不使用現(xiàn)代GPU,GPU是為并行計(jì)算而設(shè)計(jì)的,因此,使得這種模型的訓(xùn)練相當(dāng)緩慢。
當(dāng)元素彼此距離較遠(yuǎn)時(shí),它們就變得無效。這是因?yàn)樾畔⑹窃诿恳徊絺鬟f的,鏈越長(zhǎng),信息在鏈上丟失的可能性越大。
從像LSTM這樣的RNN到NLP中Transformer的轉(zhuǎn)變是由這兩個(gè)主要問題驅(qū)動(dòng)的,Transformer通過利用attention機(jī)制的改進(jìn)來評(píng)估這兩個(gè)問題的能力:
注意具體的詞語,不管它們相距多遠(yuǎn)。
提高性能速度。
因此,Transformer成為RNN的自然改進(jìn)。接下來,讓我們來看看Transformer是如何工作的。
Transformer架構(gòu)
概述
最初設(shè)計(jì)用于序列轉(zhuǎn)導(dǎo)或神經(jīng)機(jī)器翻譯,Transformer擅長(zhǎng)將輸入序列轉(zhuǎn)換為輸出序列。這是第一個(gè)完全依靠自關(guān)注來計(jì)算輸入和輸出表示的轉(zhuǎn)導(dǎo)模型,而不使用序列對(duì)齊RNN或卷積。Transformer架構(gòu)的主要核心特征是它們維護(hù)編碼器-解碼器模型。
如果我們開始將用于語言翻譯的Transformer視為一個(gè)簡(jiǎn)單的黑盒,那么它將接受一種語言(例如英語)的句子作為輸入,并輸出其英語翻譯。

如果稍微深入一點(diǎn),我們會(huì)發(fā)現(xiàn)這個(gè)黑盒子由兩個(gè)主要部分組成:
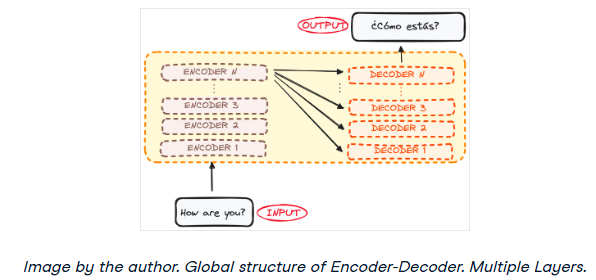
編碼器接受輸入并輸出該輸入的矩陣表示。例如,英語句子“How are you?”
解碼器接受該編碼表示并迭代地生成輸出。在我們的例子中,翻譯后的句子“?Cómo estás?”

然而,編碼器和解碼器實(shí)際上都是一個(gè)多層的堆棧(每層的數(shù)量相同)。所有編碼器都呈現(xiàn)相同的結(jié)構(gòu),輸入進(jìn)入每個(gè)編碼器并傳遞給下一個(gè)編碼器。所有解碼器也呈現(xiàn)相同的結(jié)構(gòu),并從最后一個(gè)編碼器和前一個(gè)解碼器獲得輸入。
最初的架構(gòu)由6個(gè)編碼器和6個(gè)解碼器組成,但我們可以根據(jù)需要復(fù)制盡可能多的層。假設(shè)每個(gè)都有N層。
現(xiàn)在對(duì)整個(gè)Transformer架構(gòu)有了一個(gè)大致的了解,讓我們把重點(diǎn)放在編碼器和解碼器上,以更好地理解它們的工作流程。
-
編碼器
+關(guān)注
關(guān)注
45文章
3783瀏覽量
137432 -
模型
+關(guān)注
關(guān)注
1文章
3500瀏覽量
50127 -
Transformer
+關(guān)注
關(guān)注
0文章
151瀏覽量
6427
原文標(biāo)題:Transformer架構(gòu)詳細(xì)解析——概述
文章出處:【微信號(hào):SSDFans,微信公眾號(hào):SSDFans】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
基于DINO知識(shí)蒸餾架構(gòu)的分層級(jí)聯(lián)Transformer網(wǎng)絡(luò)
關(guān)于深度學(xué)習(xí)模型Transformer模型的具體實(shí)現(xiàn)方案
如何更改ABBYY PDF Transformer+界面語言
概述隔離式電源集中式電源架構(gòu)
CMSIS軟件架構(gòu)概述?
谷歌將AutoML應(yīng)用于Transformer架構(gòu),翻譯結(jié)果飆升!
解析Transformer中的位置編碼 -- ICLR 2021

如何使用Transformer來做物體檢測(cè)?
Transformer深度學(xué)習(xí)架構(gòu)的應(yīng)用指南介紹
利用Transformer和CNN 各自的優(yōu)勢(shì)以獲得更好的分割性能
RetNet架構(gòu)和Transformer架構(gòu)對(duì)比分析
基于Transformer模型的壓縮方法

Transformer架構(gòu)在自然語言處理中的應(yīng)用
transformer專用ASIC芯片Sohu說明

Transformer架構(gòu)中編碼器的工作流程






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論