") 淺顯理解傳統(tǒng)GAN,分享學(xué)習(xí)心得
淺顯理解傳統(tǒng)GAN,分享學(xué)習(xí)心得
??
GAN網(wǎng)絡(luò)是近兩年深度學(xué)習(xí)領(lǐng)域的新秀,火的不行,本文旨在淺顯理解傳統(tǒng)GAN,分享學(xué)習(xí)心得。現(xiàn)有GAN網(wǎng)絡(luò)大多數(shù)代碼實(shí)現(xiàn)使用Python、torch等語言,這里,后面用matlab搭建一個(gè)簡單的GAN網(wǎng)絡(luò),便于理解GAN原理。
GAN的鼻祖之作是2014年NIPS一篇文章:Generative Adversarial Net(https://arxiv.org/abs/1406.2661),可以細(xì)細(xì)品味。
分享一個(gè)目前各類GAN的一個(gè)論文整理集合
https://deephunt.in/the-gan-zoo-79597dc8c347
再分享一個(gè)目前各類GAN的一個(gè)代碼整理集合
https://github.com/zhangqianhui/AdversarialNetsPapers
▌開始
我們知道GAN的思想是是一種二人零和博弈思想(two-player game),博弈雙方的利益之和是一個(gè)常數(shù),比如兩個(gè)人掰手腕,假設(shè)總的空間是一定的,你的力氣大一點(diǎn),那你就得到的空間多一點(diǎn),相應(yīng)的我的空間就少一點(diǎn),相反我力氣大我就得到的多一點(diǎn),但有一點(diǎn)是確定的就是,我兩的總空間是一定的,這就是二人博弈,但是呢總利益是一定的。
引申到GAN里面就是可以看成,GAN中有兩個(gè)這樣的博弈者,一個(gè)人名字是生成模型(G),另一個(gè)人名字是判別模型(D)。他們各自有各自的功能。
相同點(diǎn)是:
這兩個(gè)模型都可以看成是一個(gè)黑匣子,接受輸入然后有一個(gè)輸出,類似一個(gè)函數(shù),一個(gè)輸入輸出映射。
不同點(diǎn)是:
生成模型功能:比作是一個(gè)樣本生成器,輸入一個(gè)噪聲/樣本,然后把它包裝成一個(gè)逼真的樣本,也就是輸出。
判別模型:比作一個(gè)二分類器(如同0-1分類器),來判斷輸入的樣本是真是假。(就是輸出值大于0.5還是小于0.5)
直接上一張個(gè)人覺得解釋的好的圖說明:
在之前,我們首先明白在使用GAN的時(shí)候的2個(gè)問題
我們有什么?比如上面的這個(gè)圖,我們有的只是真實(shí)采集而來的人臉樣本數(shù)據(jù)集,僅此而已,而且很關(guān)鍵的一點(diǎn)是我們連人臉數(shù)據(jù)集的類標(biāo)簽都沒有,也就是我們不知道那個(gè)人臉對應(yīng)的是誰。
我們要得到什么?至于要得到什么,不同的任務(wù)得到的東西不一樣,我們只說最原始的GAN目的,那就是我們想通過輸入一個(gè)噪聲,模擬得到一個(gè)人臉圖像,這個(gè)圖像可以非常逼真以至于以假亂真。
好了再來理解下GAN的兩個(gè)模型要做什么。
首先判別模型,就是圖中右半部分的網(wǎng)絡(luò),直觀來看就是一個(gè)簡單的神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu),輸入就是一副圖像,輸出就是一個(gè)概率值,用于判斷真假使用(概率值大于0.5那就是真,小于0.5那就是假),真假也不過是人們定義的概率而已。
其次是生成模型,生成模型要做什么呢,同樣也可以看成是一個(gè)神經(jīng)網(wǎng)絡(luò)模型,輸入是一組隨機(jī)數(shù)Z,輸出是一個(gè)圖像,不再是一個(gè)數(shù)值而已。從圖中可以看到,會存在兩個(gè)數(shù)據(jù)集,一個(gè)是真實(shí)數(shù)據(jù)集,這好說,另一個(gè)是假的數(shù)據(jù)集,那這個(gè)數(shù)據(jù)集就是有生成網(wǎng)絡(luò)造出來的數(shù)據(jù)集。好了根據(jù)這個(gè)圖我們再來理解一下GAN的目標(biāo)是要干什么:
判別網(wǎng)絡(luò)的目的:就是能判別出來屬于的一張圖它是來自真實(shí)樣本集還是假樣本集。假如輸入的是真樣本,網(wǎng)絡(luò)輸出就接近1,輸入的是假樣本,網(wǎng)絡(luò)輸出接近0,那么很完美,達(dá)到了很好判別的目的。
生成網(wǎng)絡(luò)的目的:生成網(wǎng)絡(luò)是造樣本的,它的目的就是使得自己造樣本的能力盡可能強(qiáng),強(qiáng)到什么程度呢,你判別網(wǎng)絡(luò)沒法判斷我是真樣本還是假樣本。
有了這個(gè)理解我們再來看看為什么叫做對抗網(wǎng)絡(luò)了。判別網(wǎng)絡(luò)說,我很強(qiáng),來一個(gè)樣本我就知道它是來自真樣本集還是假樣本集。生成網(wǎng)絡(luò)就不服了,說我也很強(qiáng),我生成一個(gè)假樣本,雖然我生成網(wǎng)絡(luò)知道是假的,但是你判別網(wǎng)絡(luò)不知道呀,我包裝的非常逼真,以至于判別網(wǎng)絡(luò)無法判斷真假,那么用輸出數(shù)值來解釋就是,生成網(wǎng)絡(luò)生成的假樣本進(jìn)去了判別網(wǎng)絡(luò)以后,判別網(wǎng)絡(luò)給出的結(jié)果是一個(gè)接近0.5的值,極限情況就是0.5,也就是說判別不出來了,這就是納什平衡了。
由這個(gè)分析可以發(fā)現(xiàn),生成網(wǎng)絡(luò)與判別網(wǎng)絡(luò)的目的正好是相反的,一個(gè)說我能判別的好,一個(gè)說我讓你判別不好。所以叫做對抗,叫做博弈。那么最后的結(jié)果到底是誰贏呢?這就要?dú)w結(jié)到設(shè)計(jì)者,也就是我們希望誰贏了。作為設(shè)計(jì)者的我們,我們的目的是要得到以假亂真的樣本,那么很自然的我們希望生成樣本贏了,也就是希望生成樣本很真,判別網(wǎng)絡(luò)能力不足以區(qū)分真假樣本位置。
▌再理解
知道了GAN大概的目的與設(shè)計(jì)思路,那么一個(gè)很自然的問題來了就是我們該如何用數(shù)學(xué)方法解決這么一個(gè)對抗問題。這就涉及到如何訓(xùn)練這樣一個(gè)生成對抗網(wǎng)絡(luò)模型了,還是先上一個(gè)圖,用圖來解釋最直接:
需要注意的是生成模型與對抗模型可以說是完全獨(dú)立的兩個(gè)模型,好比就是完全獨(dú)立的兩個(gè)神經(jīng)網(wǎng)絡(luò)模型,他們之間沒有什么聯(lián)系。
好了那么訓(xùn)練這樣的兩個(gè)模型的大方法就是:單獨(dú)交替迭代訓(xùn)練。
什么意思?因?yàn)槭?個(gè)網(wǎng)絡(luò),不好一起訓(xùn)練,所以才去交替迭代訓(xùn)練,我們一一來看。
假設(shè)現(xiàn)在生成網(wǎng)絡(luò)模型已經(jīng)有了(當(dāng)然可能不是最好的生成網(wǎng)絡(luò)),那么給一堆隨機(jī)數(shù)組,就會得到一堆假的樣本集(因?yàn)椴皇亲罱K的生成模型,那么現(xiàn)在生成網(wǎng)絡(luò)可能就處于劣勢,導(dǎo)致生成的樣本就不咋地,可能很容易就被判別網(wǎng)絡(luò)判別出來了說這貨是假冒的),但是先不管這個(gè),假設(shè)我們現(xiàn)在有了這樣的假樣本集,真樣本集一直都有,現(xiàn)在我們?nèi)藶榈亩x真假樣本集的標(biāo)簽,因?yàn)槲覀兿M鏄颖炯妮敵霰M可能為1,假樣本集為0,很明顯這里我們就已經(jīng)默認(rèn)真樣本集所有的類標(biāo)簽都為1,而假樣本集的所有類標(biāo)簽都為0.
有人會說,在真樣本集里面的人臉中,可能張三人臉和李四人臉不一樣呀,對于這個(gè)問題我們需要理解的是,我們現(xiàn)在的任務(wù)是什么,我們是想分樣本真假,而不是分真樣本中那個(gè)是張三label、那個(gè)是李四label。況且我們也知道,原始真樣本的label我們是不知道的。回過頭來,我們現(xiàn)在有了真樣本集以及它們的label(都是1)、假樣本集以及它們的label(都是0),這樣單就判別網(wǎng)絡(luò)來說,此時(shí)問題就變成了一個(gè)再簡單不過的有監(jiān)督的二分類問題了,直接送到神經(jīng)網(wǎng)絡(luò)模型中訓(xùn)練就完事了。假設(shè)訓(xùn)練完了,下面我們來看生成網(wǎng)絡(luò)。
對于生成網(wǎng)絡(luò),想想我們的目的,是生成盡可能逼真的樣本。那么原始的生成網(wǎng)絡(luò)生成的樣本你怎么知道它真不真呢?就是送到判別網(wǎng)絡(luò)中,所以在訓(xùn)練生成網(wǎng)絡(luò)的時(shí)候,我們需要聯(lián)合判別網(wǎng)絡(luò)一起才能達(dá)到訓(xùn)練的目的。什么意思?就是如果我們單單只用生成網(wǎng)絡(luò),那么想想我們怎么去訓(xùn)練?誤差來源在哪里?細(xì)想一下沒有,但是如果我們把剛才的判別網(wǎng)絡(luò)串接在生成網(wǎng)絡(luò)的后面,這樣我們就知道真假了,也就有了誤差了。所以對于生成網(wǎng)絡(luò)的訓(xùn)練其實(shí)是對生成-判別網(wǎng)絡(luò)串接的訓(xùn)練,就像圖中顯示的那樣。好了那么現(xiàn)在來分析一下樣本,原始的噪聲數(shù)組Z我們有,也就是生成了假樣本我們有,此時(shí)很關(guān)鍵的一點(diǎn)來了,我們要把這些假樣本的標(biāo)簽都設(shè)置為1,也就是認(rèn)為這些假樣本在生成網(wǎng)絡(luò)訓(xùn)練的時(shí)候是真樣本。
那么為什么要這樣呢?我們想想,是不是這樣才能起到迷惑判別器的目的,也才能使得生成的假樣本逐漸逼近為正樣本。好了,重新順一下思路,現(xiàn)在對于生成網(wǎng)絡(luò)的訓(xùn)練,我們有了樣本集(只有假樣本集,沒有真樣本集),有了對應(yīng)的label(全為1),是不是就可以訓(xùn)練了?有人會問,這樣只有一類樣本,訓(xùn)練啥呀?誰說一類樣本就不能訓(xùn)練了?只要有誤差就行。還有人說,你這樣一訓(xùn)練,判別網(wǎng)絡(luò)的網(wǎng)絡(luò)參數(shù)不是也跟著變嗎?沒錯(cuò),這很關(guān)鍵,所以在訓(xùn)練這個(gè)串接的網(wǎng)絡(luò)的時(shí)候,一個(gè)很重要的操作就是不要判別網(wǎng)絡(luò)的參數(shù)發(fā)生變化,也就是不讓它參數(shù)發(fā)生更新,只是把誤差一直傳,傳到生成網(wǎng)絡(luò)那塊后更新生成網(wǎng)絡(luò)的參數(shù)。這樣就完成了生成網(wǎng)絡(luò)的訓(xùn)練了。
在完成生成網(wǎng)絡(luò)訓(xùn)練好,那么我們是不是可以根據(jù)目前新的生成網(wǎng)絡(luò)再對先前的那些噪聲Z生成新的假樣本了,沒錯(cuò),并且訓(xùn)練后的假樣本應(yīng)該是更真了才對。然后又有了新的真假樣本集(其實(shí)是新的假樣本集),這樣又可以重復(fù)上述過程了。我們把這個(gè)過程稱作為單獨(dú)交替訓(xùn)練。我們可以實(shí)現(xiàn)定義一個(gè)迭代次數(shù),交替迭代到一定次數(shù)后停止即可。這個(gè)時(shí)候我們再去看一看噪聲Z生成的假樣本會發(fā)現(xiàn),原來它已經(jīng)很真了。
看完了這個(gè)過程是不是感覺GAN的設(shè)計(jì)真的很巧妙,個(gè)人覺得最值得稱贊的地方可能在于這種假樣本在訓(xùn)練過程中的真假變換,這也是博弈得以進(jìn)行的關(guān)鍵之處。
▌進(jìn)一步
文字的描述相信已經(jīng)讓大多數(shù)的人知道了這個(gè)過程,下面我們來看看原文中幾個(gè)重要的數(shù)學(xué)公式描述,首先我們直接上原始論文中的目標(biāo)公式吧:
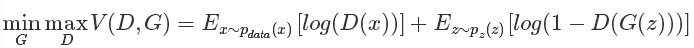
上述這個(gè)公式說白了就是一個(gè)最大最小優(yōu)化問題,其實(shí)對應(yīng)的也就是上述的兩個(gè)優(yōu)化過程。有人說如果不看別的,能達(dá)看到這個(gè)公式就拍案叫絕的地步,那就是機(jī)器學(xué)習(xí)的頂級專家,哈哈,真是前路漫漫。同時(shí)也說明這個(gè)簡單的公式意義重大。
這個(gè)公式既然是最大最小的優(yōu)化,那就不是一步完成的,其實(shí)對比我們的分析過程也是這樣的,這里現(xiàn)優(yōu)化D,然后在取優(yōu)化G,本質(zhì)上是兩個(gè)優(yōu)化問題,把拆解就如同下面兩個(gè)公式:
優(yōu)化D:
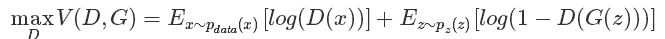
優(yōu)化G:
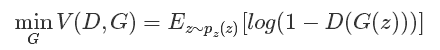
可以看到,優(yōu)化D的時(shí)候,也就是判別網(wǎng)絡(luò),其實(shí)沒有生成網(wǎng)絡(luò)什么事,后面的G(z)這里就相當(dāng)于已經(jīng)得到的假樣本。優(yōu)化D的公式的第一項(xiàng),使的真樣本x輸入的時(shí)候,得到的結(jié)果越大越好,可以理解,因?yàn)樾枰鏄颖镜念A(yù)測結(jié)果越接近于1越好嘛。對于假樣本,需要優(yōu)化是的其結(jié)果越小越好,也就是D(G(z))越小越好,因?yàn)樗臉?biāo)簽為0。但是呢第一項(xiàng)是越大,第二項(xiàng)是越小,這不矛盾了,所以呢把第二項(xiàng)改成1-D(G(z)),這樣就是越大越好,兩者合起來就是越大越好。 那么同樣在優(yōu)化G的時(shí)候,這個(gè)時(shí)候沒有真樣本什么事,所以把第一項(xiàng)直接卻掉了。這個(gè)時(shí)候只有假樣本,但是我們說這個(gè)時(shí)候是希望假樣本的標(biāo)簽是1的,所以是D(G(z))越大越好,但是呢為了統(tǒng)一成1-D(G(z))的形式,那么只能是最小化1-D(G(z)),本質(zhì)上沒有區(qū)別,只是為了形式的統(tǒng)一。之后這兩個(gè)優(yōu)化模型可以合并起來寫,就變成了最開始的那個(gè)最大最小目標(biāo)函數(shù)了。
所以回過頭來我們來看這個(gè)最大最小目標(biāo)函數(shù),里面包含了判別模型的優(yōu)化,包含了生成模型的以假亂真的優(yōu)化,完美的闡釋了這樣一個(gè)優(yōu)美的理論。
▌再進(jìn)一步
有人說GAN強(qiáng)大之處在于可以自動的學(xué)習(xí)原始真實(shí)樣本集的數(shù)據(jù)分布,不管這個(gè)分布多么的復(fù)雜,只要訓(xùn)練的足夠好就可以學(xué)出來。針對這一點(diǎn),感覺有必要好好理解一下為什么別人會這么說。
我們知道,傳統(tǒng)的機(jī)器學(xué)習(xí)方法,我們一般都會定義一個(gè)什么模型讓數(shù)據(jù)去學(xué)習(xí)。比如說假設(shè)我們知道原始數(shù)據(jù)屬于高斯分布呀,只是不知道高斯分布的參數(shù),這個(gè)時(shí)候我們定義高斯分布,然后利用數(shù)據(jù)去學(xué)習(xí)高斯分布的參數(shù)得到我們最終的模型。再比如說我們定義一個(gè)分類器,比如SVM,然后強(qiáng)行讓數(shù)據(jù)進(jìn)行東變西變,進(jìn)行各種高維映射,最后可以變成一個(gè)簡單的分布,SVM可以很輕易的進(jìn)行二分類分開,其實(shí)SVM已經(jīng)放松了這種映射關(guān)系了,但是也是給了一個(gè)模型,這個(gè)模型就是核映射(什么徑向基函數(shù)等等),說白了其實(shí)也好像是你事先知道讓數(shù)據(jù)該怎么映射一樣,只是核映射的參數(shù)可以學(xué)習(xí)罷了。
所有的這些方法都在直接或者間接的告訴數(shù)據(jù)你該怎么映射一樣,只是不同的映射方法能力不一樣。那么我們再來看看GAN,生成模型最后可以通過噪聲生成一個(gè)完整的真實(shí)數(shù)據(jù)(比如人臉),說明生成模型已經(jīng)掌握了從隨機(jī)噪聲到人臉數(shù)據(jù)的分布規(guī)律了,有了這個(gè)規(guī)律,想生成人臉還不容易。然而這個(gè)規(guī)律我們開始知道嗎?顯然不知道,如果讓你說從隨機(jī)噪聲到人臉應(yīng)該服從什么分布,你不可能知道。這是一層層映射之后組合起來的非常復(fù)雜的分布映射規(guī)律。然而GAN的機(jī)制可以學(xué)習(xí)到,也就是說GAN學(xué)習(xí)到了真實(shí)樣本集的數(shù)據(jù)分布。
再拿原論文中的一張圖來解釋:
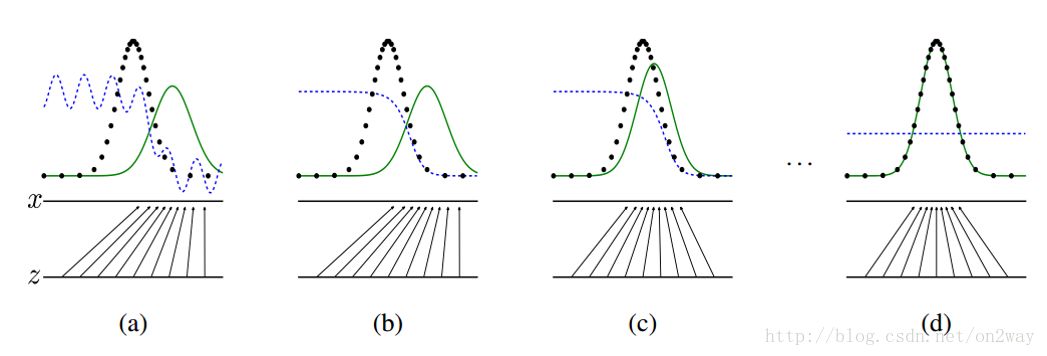
這張圖表明的是GAN的生成網(wǎng)絡(luò)如何一步步從均勻分布學(xué)習(xí)到正太分布的。原始數(shù)據(jù)x服從正太分布,這個(gè)過程你也沒告訴生成網(wǎng)絡(luò)說你得用正太分布來學(xué)習(xí),但是生成網(wǎng)絡(luò)學(xué)習(xí)到了。假設(shè)你改一下x的分布,不管什么分布,生成網(wǎng)絡(luò)可能也能學(xué)到。這就是GAN可以自動學(xué)習(xí)真實(shí)數(shù)據(jù)的分布的強(qiáng)大之處。
還有人說GAN強(qiáng)大之處在于可以自動的定義潛在損失函數(shù)。什么意思呢,這應(yīng)該說的是判別網(wǎng)絡(luò)可以自動學(xué)習(xí)到一個(gè)好的判別方法,其實(shí)就是等效的理解為可以學(xué)習(xí)到好的損失函數(shù),來比較好或者不好的判別出來結(jié)果。雖然大的loss函數(shù)還是我們?nèi)藶槎x的,基本上對于多數(shù)GAN也都這么定義就可以了,但是判別網(wǎng)絡(luò)潛在學(xué)習(xí)到的損失函數(shù)隱藏在網(wǎng)絡(luò)之中,不同的問題這個(gè)函數(shù)就不一樣,所以說可以自動學(xué)習(xí)這個(gè)潛在的損失函數(shù)。
▌開始做小實(shí)驗(yàn)
本節(jié)主要實(shí)驗(yàn)一下如何通過隨機(jī)數(shù)組生成mnist圖像。mnist手寫體數(shù)據(jù)庫應(yīng)該都熟悉的。這里簡單的使用matlab來實(shí)現(xiàn),方便看到整個(gè)實(shí)現(xiàn)過程。這里用到了一個(gè)工具箱DeepLearnToolbox,關(guān)于該工具箱的一些其他使用說明:
DeepLearnToolbox
https://github.com/rasmusbergpalm/DeepLearnToolbox
其他使用說明
https://blog.csdn.net/dark_scope/article/details/9447967
網(wǎng)絡(luò)結(jié)構(gòu)很簡單,就定義成下面這樣子:
將上述工具箱添加到路徑,然后運(yùn)行下面代碼:
clcclear%% 構(gòu)造真實(shí)訓(xùn)練樣本 60000個(gè)樣本 1*784維(28*28展開)load mnist_uint8;train_x = double(train_x(1:60000,:)) / 255;% 真實(shí)樣本認(rèn)為為標(biāo)簽 [1 0];
生成樣本為[0 1];train_y = double(ones(size(train_x,1),1));% normalizetrain_x = mapminmax(train_x, 0, 1);rand('state',0)%% 構(gòu)造模擬訓(xùn)練樣本 60000個(gè)樣本 1*100維test_x = normrnd(0,1,[60000,100]); % 0-255的整數(shù)test_x = mapminmax(test_x, 0, 1);test_y =
double(zeros(size(test_x,1),1));test_y_rel = double(ones(size(test_x,1),1));%%nn_G_t = nnsetup([100 784]);nn_G_t.activation_function = 'sigm';nn_G_t.output = 'sigm';nn_D = nnsetup([784 100 1]);nn_D.weightPenaltyL2 = 1e-4; % L2 weight decaynn_D.dropoutFraction = 0.5; % Dropout fraction nn_D.learningRate = 0.01;
% Sigm require a lower learning ratenn_D.activation_function = 'sigm';nn_D.output = 'sigm';% nn_D.weightPenaltyL2 = 1e-4; % L2 weight decaynn_G = nnsetup([100 784 100 1]);nn_G.weightPenaltyL2 = 1e-4; % L2 weight decaynn_G.dropoutFraction = 0.5; % Dropout fraction nn_G.learningRate = 0.01;
% Sigm require a lower learning ratenn_G.activation_function = 'sigm';nn_G.output = 'sigm';% nn_G.weightPenaltyL2 = 1e-4; % L2 weight decayopts.numepochs = 1;
% Number of full sweeps through dataopts.batchsize = 100;
% Take a mean gradient step over this many samples%%num = 1000;ticfor each = 1:1500 %----------計(jì)算G的輸出:假樣本------------------- for i = 1:length(nn_G_t.W) %共享網(wǎng)絡(luò)參數(shù)
nn_G_t.W{i} = nn_G.W{i}; end G_output = nn_G_out(nn_G_t, test_x); %-----------訓(xùn)練D------------------------------ index = randperm(60000); train_data_D = [train_x(index(1:num),:);G_output(index(1:num),:)];
train_y_D = [train_y(index(1:num),:);test_y(index(1:num),:)]; nn_D = nntrain(nn_D, train_data_D, train_y_D, opts);%訓(xùn)練D %-----------訓(xùn)練G------------------------------- for i = 1:length(nn_D.W) %共享訓(xùn)練的D的網(wǎng)絡(luò)參數(shù)
nn_G.W{length(nn_G.W)-i+1} = nn_D.W{length(nn_D.W)-i+1}; end %訓(xùn)練G:此時(shí)假樣本標(biāo)簽為1,認(rèn)為是真樣本
nn_G = nntrain(nn_G, test_x(index(1:num),:), test_y_rel(index(1:num),:), opts);endtocfor i = 1:length(nn_G_t.W)
nn_G_t.W{i} = nn_G.W{i};endfin_output = nn_G_out(nn_G_t, test_x);
函數(shù)nn_G_out為:
function output = nn_G_out(nn, x)
nn.testing = 1;
nn = nnff(nn, x, zeros(size(x,1), nn.size(end)));
nn.testing = 0;
output = nn.a{end};end
看一下這個(gè)及其簡單的函數(shù),其實(shí)最值得注意的就是中間那個(gè)交替訓(xùn)練的過程,這里我分了三步列出來:
重新計(jì)算假樣本(假樣本每次是需要更新的,產(chǎn)生越來越像的樣本)
訓(xùn)練D網(wǎng)絡(luò),一個(gè)二分類的神經(jīng)網(wǎng)絡(luò);
訓(xùn)練G網(wǎng)絡(luò),一個(gè)串聯(lián)起來的長網(wǎng)絡(luò),也是一個(gè)二分類的神經(jīng)網(wǎng)絡(luò)(不過只有假樣本來訓(xùn)練),同時(shí)D部分參數(shù)在下一次的時(shí)候不能變了。
就這樣調(diào)一調(diào)參數(shù),最終輸出在fin_output里面,多運(yùn)行幾次顯示不同運(yùn)行次數(shù)下的結(jié)果:
可以看到的是結(jié)果還是有點(diǎn)像模像樣的。
▌實(shí)驗(yàn)總結(jié)
運(yùn)行上述簡單的網(wǎng)絡(luò)我發(fā)現(xiàn)幾個(gè)問題:
網(wǎng)絡(luò)存在著不收斂問題;網(wǎng)絡(luò)不穩(wěn)定;網(wǎng)絡(luò)難訓(xùn)練;讀過原論文其實(shí)作者也提到過這些問題,包括GAN剛出來的時(shí)候,很多人也在致力于解決這些問題,當(dāng)你實(shí)驗(yàn)自己碰到的時(shí)候,還是很有意思的。那么這些問題怎么體現(xiàn)的呢,舉個(gè)例子,可能某一次你會發(fā)現(xiàn)訓(xùn)練的誤差很小,在下一代訓(xùn)練時(shí),馬上又出現(xiàn)極限性的上升的很厲害,過幾代又發(fā)現(xiàn)訓(xùn)練誤差很小,震蕩太嚴(yán)重。
其次網(wǎng)絡(luò)需要調(diào)才能出像樣的結(jié)果。交替迭代次數(shù)的不同結(jié)果也不一樣。比如每一代訓(xùn)練中,D網(wǎng)絡(luò)訓(xùn)練2回,G網(wǎng)絡(luò)訓(xùn)練一回,結(jié)果就不一樣。
這是簡單的無條件GAN,所以每一代訓(xùn)練完后,只能出現(xiàn)一個(gè)結(jié)果,那就是0-9中的某一個(gè)數(shù)。要想在一代訓(xùn)練中出現(xiàn)好幾種結(jié)果,就需要使用到條件GAN了。
▌最后
現(xiàn)在的GAN已經(jīng)到了五花八門的時(shí)候了,各種GAN應(yīng)用也很多,理解底層原理再慢慢往上層擴(kuò)展。GAN還是一個(gè)很厲害的東西,它使得現(xiàn)有問題從有監(jiān)督學(xué)習(xí)慢慢過渡到無監(jiān)督學(xué)習(xí),而無監(jiān)督學(xué)習(xí)才是自然界中普遍存在的,因?yàn)楹芏鄷r(shí)候沒有辦法拿到監(jiān)督信息的。要不Yann Lecun贊嘆GAN是機(jī)器學(xué)習(xí)近十年來最有意思的想法。
-
神經(jīng)網(wǎng)絡(luò)
+關(guān)注
關(guān)注
42文章
4811瀏覽量
103053 -
GaN
+關(guān)注
關(guān)注
19文章
2186瀏覽量
76344 -
機(jī)器學(xué)習(xí)
+關(guān)注
關(guān)注
66文章
8497瀏覽量
134236
原文標(biāo)題:一文詳解生成對抗網(wǎng)絡(luò)(GAN)的原理,通俗易懂
文章出處:【微信號:AI_Thinker,微信公眾號:人工智能頭條】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
協(xié)會學(xué)長學(xué)習(xí)stm32的學(xué)習(xí)心得及筆記
嵌入式基礎(chǔ)學(xué)習(xí)心得

ARM9入門學(xué)習(xí)心得分享
嵌入式學(xué)習(xí)心得

ESP8266 Nodemcu學(xué)習(xí)心得②
【學(xué)習(xí)心得】學(xué)習(xí)SDRAM課程體會





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論