 工業數據中臺如何支持智能決策
工業數據中臺如何支持智能決策

工業數據中臺通過數據整合、模型構建、實時響應與業務閉環四大核心能力,將數據轉化為可執行的決策依據,推動企業從“經驗驅動”向“數據驅動”轉型。以下是具體支持路徑與案例說明:
一、數據整合與特征工程:構建決策基礎
多源異構數據融合
工業場景中,設備數據(如PLC、傳感器)、業務數據(ERP、MES)和外部數據(天氣、供應鏈)分散且格式不一。數據中臺通過統一數據模型(如工業時序數據庫InfluxDB+關系型數據庫)整合多源數據,形成完整的決策數據集。
案例:某汽車制造廠整合沖壓車間的設備振動數據、ERP的訂單排期數據和天氣數據,預測設備故障對生產計劃的影響,避免因設備停機導致的交貨延遲。
特征工程自動化
數據中臺內置特征工程工具(如特征衍生、降維算法),從原始數據中提取關鍵特征(如設備健康度指數、生產瓶頸指數),為模型訓練提供高質量輸入。
案例:某風電企業通過數據中臺自動生成“葉片磨損指數”,結合風速、功率數據訓練故障預測模型,準確率提升25%。
二、AI模型工廠:從訓練到部署的全流程支持
模型開發與管理
數據中臺提供模型開發環境(如JupyterLab集成)、預置工業算法庫(如時序預測、異常檢測)和模型版本管理功能,加速模型迭代。
案例:某鋼鐵廠利用數據中臺的“高爐溫度預測模型”,通過歷史數據訓練+實時數據反饋,將溫度預測誤差從15℃降至5℃,優化了焦炭配比。
模型服務化
將訓練好的模型封裝為API服務(如基于TensorFlow Serving或ONNX Runtime),供業務系統調用。
案例:某化工企業將“反應釜壓力預測模型”部署為API,實時監控壓力趨勢并觸發自動調節,事故率下降40%。
三、實時決策引擎:毫秒級響應與閉環控制
流批一體計算
數據中臺結合流處理框架(如Flink)與批處理引擎(如Spark),實現實時數據與歷史數據的聯合分析。
案例:某半導體工廠通過流批一體計算,實時分析晶圓檢測數據與歷史工藝參數的關聯,動態調整光刻機參數,良品率提升3%。
規則引擎與決策流
將專家經驗轉化為可配置的規則(如“當溫度>80℃且振動>5mm/s時,啟動冷卻系統”),并通過可視化決策流設計器(如Drools+Camunda)實現復雜邏輯編排。
案例:某水泥廠通過規則引擎自動調節窯爐燃燒參數,能耗降低12%。
四、決策仿真與優化:降低試錯成本
數字孿生與仿真
數據中臺結合數字孿生技術,構建虛擬工廠模型,模擬不同決策方案的效果(如產能調整、設備維護計劃)。
案例:某航空發動機企業通過數字孿生仿真,優化維修計劃,減少停機時間20%。
多目標優化算法
內置遺傳算法、強化學習等優化工具,解決工業場景中的多目標沖突問題(如成本、質量、交期)。
案例:某家電企業通過多目標優化算法,平衡庫存成本與缺貨風險,庫存周轉率提升18%。
五、決策評估與反饋:持續改進
決策效果追蹤
記錄決策執行結果(如模型預測值、實際值、業務影響),構建決策效果評估體系。
案例:某汽車零部件企業通過決策追蹤系統,發現某批次質量預測模型的誤報率較高,及時優化模型特征。
閉環反饋機制
將決策結果反饋至數據中臺,驅動模型迭代與規則優化,形成“數據-決策-效果-優化”的閉環。
案例:某光伏企業通過閉環反饋,將組件功率預測模型的MAE(平均絕對誤差)從3%降至1.5%。
審核編輯 黃宇
-
仿真
+關注
關注
52文章
4283瀏覽量
135815 -
數字化
+關注
關注
8文章
9513瀏覽量
63563 -
數字孿生
+關注
關注
4文章
1483瀏覽量
12840
發布評論請先 登錄
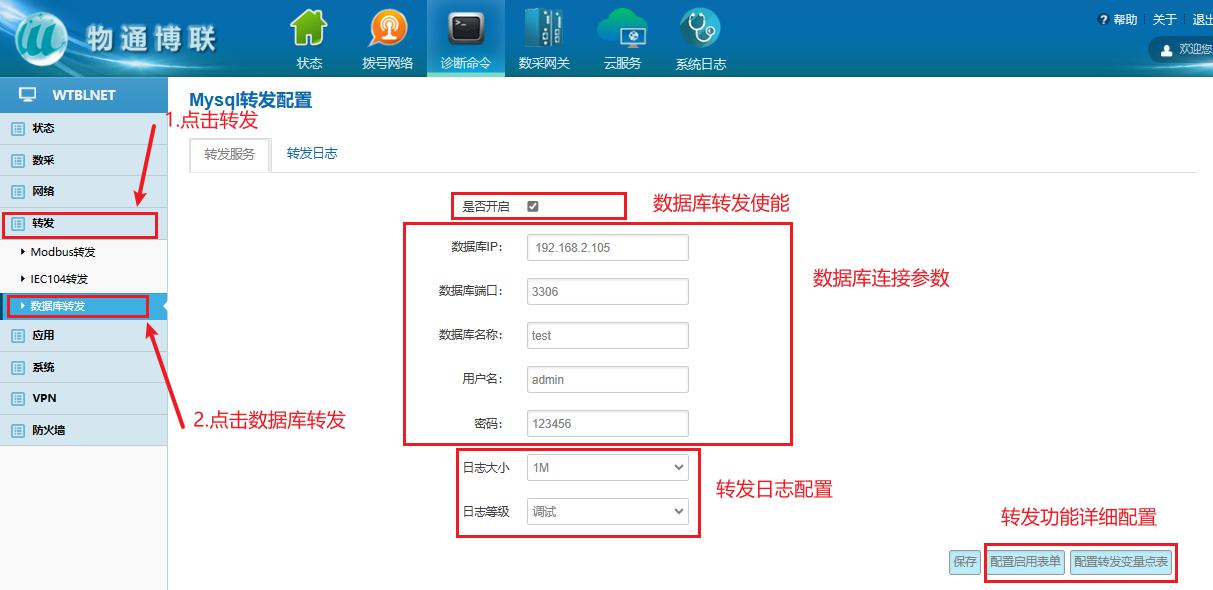
工業智能網關如何采集數據上傳到數據庫(MYSQL和SQLSERVER)
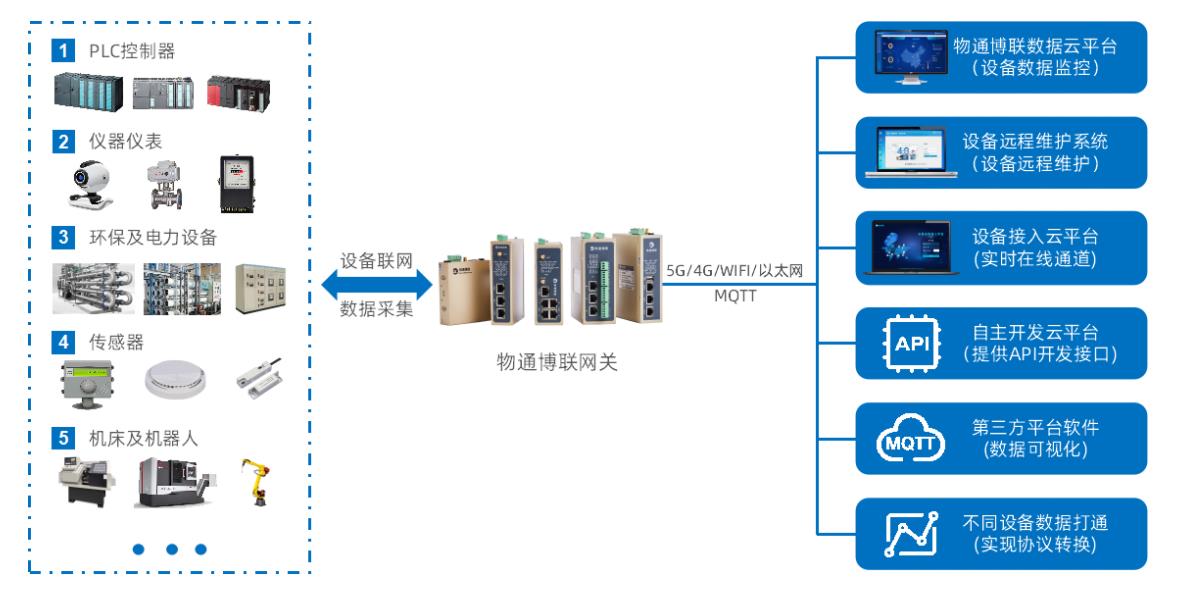
除了PLC、CNC外,工業數據中臺還能接入哪些設備?

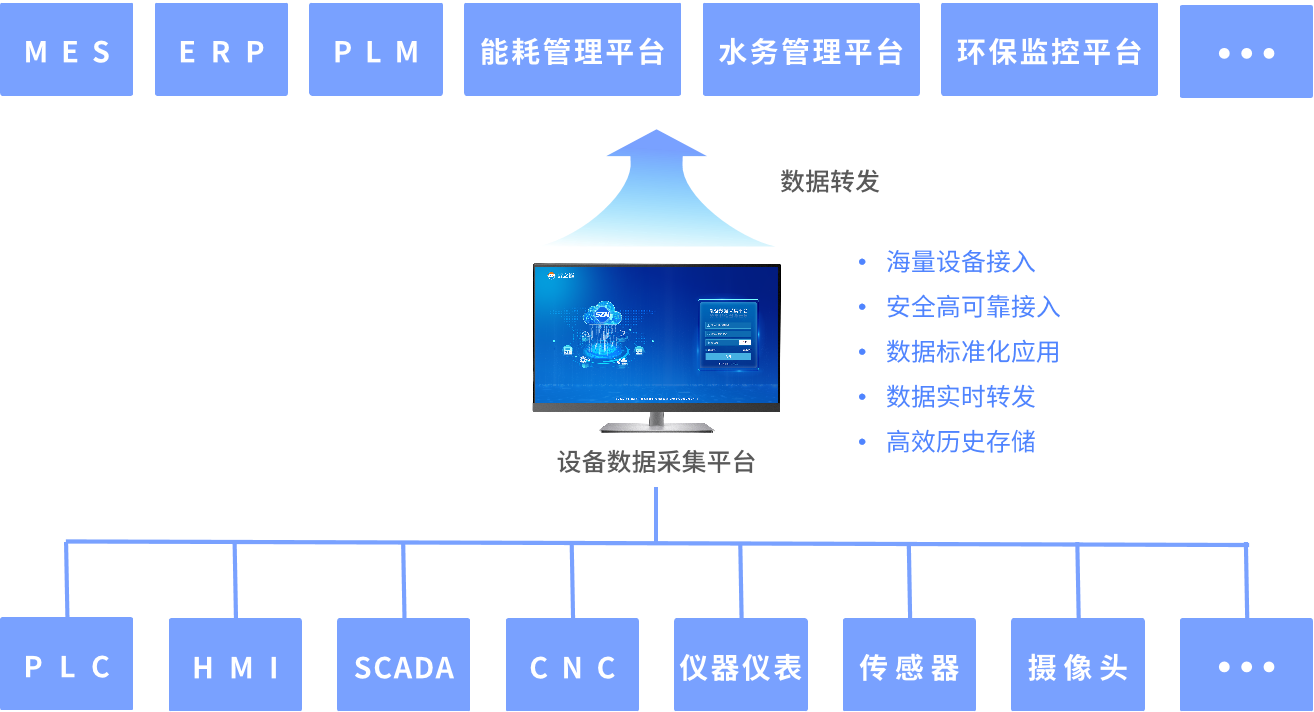
基于數據中臺的工業物聯網系統有哪些功能
工業數據中臺如何實現 CNC 機床數據采集
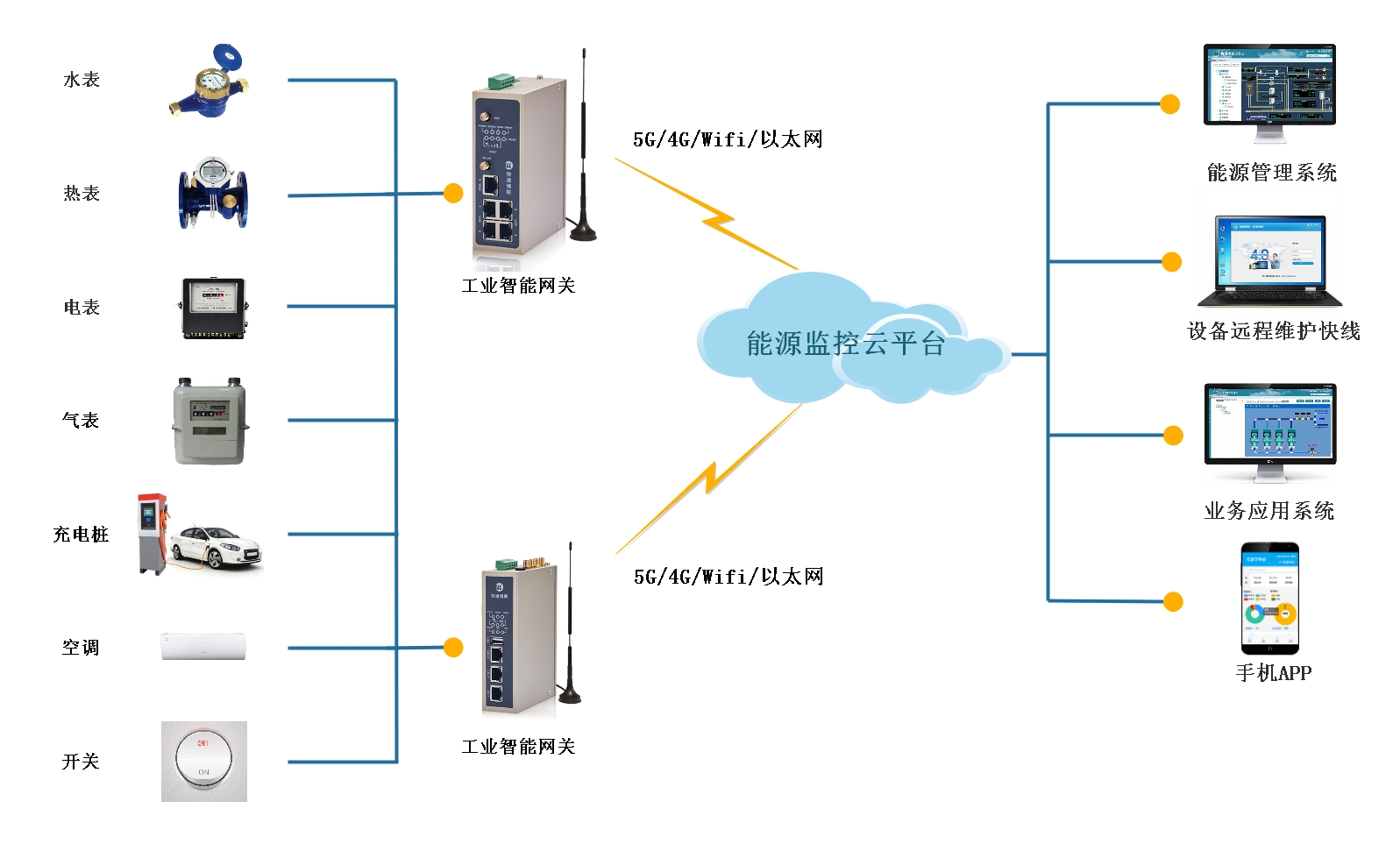
工業智能網關采集能耗數據對接到MySQL數據庫





 工商網監
工商網監
評論