") NVIDIA recsys-examples在生成式推薦系統(tǒng)中的高效實踐
NVIDIA recsys-examples在生成式推薦系統(tǒng)中的高效實踐

引言
在生成式 AI 浪潮的推動下,推薦系統(tǒng)領(lǐng)域正經(jīng)歷深刻變革。傳統(tǒng)的深度學習推薦模型 (DLRMs) 雖已展現(xiàn)出一定效果,但在捕捉用戶興趣偏好和動態(tài)行為序列變化時,常面臨可擴展性挑戰(zhàn)。生成式推薦系統(tǒng) (Generative Recommenders, GRs) 的出現(xiàn),為這一領(lǐng)域帶來了全新思路與機遇。
本文將介紹NVIDIA recsys-examples中針對生成式推薦場景設(shè)計的高效實踐參考。博客內(nèi)容共分為上下兩篇,本篇將整體介紹 recsys-examples 的設(shè)計和功能,下篇將對核心模塊進行深入的解析。
GitHub repo:https://github.com/NVIDIA/recsys-examples
生成式推薦系統(tǒng)的崛起
Meta Research 的最新研究表明,生成式推薦系統(tǒng)通過將推薦問題重構(gòu)為生成式建模框架下的序列 transduction 任務(wù),展現(xiàn)出顯著優(yōu)勢:
更個性化的推薦:能夠深入挖掘用戶獨特的行為模式與偏好。
更強的上下文感知能力:能夠更好地捕捉上下文序列信號,滿足序列建模的模型需求
以 Meta 提出的 HSTU (Hierarchical Sequential Transduction Units) 為例,其在推薦場景中性能超越傳統(tǒng) Transformer 模型,且推理速度更快。
大規(guī)模訓練的挑戰(zhàn)與應(yīng)對方案
然而,基于類 Transformer 架構(gòu)的生成式推薦系統(tǒng),因上下文長度增加和計算需求提升,在大規(guī)模訓練與部署時面臨嚴峻的計算和架構(gòu)挑戰(zhàn)。為解決這些難題,NVIDIA 開發(fā)了 recsys-examples 參考實現(xiàn),旨在展示大規(guī)模生成式推薦系統(tǒng)中訓練和推理的最優(yōu)實踐。
NVIDIA recsys-examples 中的深度優(yōu)化
NVIDIA recsys-examples 目前主要包含以下特性:
混合并行分布式訓練:基于 TorchRec(處理 sparse 部分的模型并行)和NVIDIA Megatron Core(適用于 dense 部分的數(shù)據(jù)并行與模型并行),優(yōu)化多 GPU 分布式訓練流程,實現(xiàn) sparse 和 dense 部分多種并行的高效協(xié)同。
高效 HSTU 注意力算子:通過NVIDIA CUTLASS實現(xiàn)高性能的 HSTU 注意力算子,提升計算效率。
動態(tài) embedding 功能:結(jié)合NVIDIA Merlin HKV和 TorchRec,支持無沖突哈希、embedding eviction 及 CPU offloading 等動態(tài) embedding 能力,適配大規(guī)模訓練場景。
當前,recsys-examples 中提供了基于 HSTU 排序和召回模型的大規(guī)模訓練示例,方便用戶快速使用和參考。
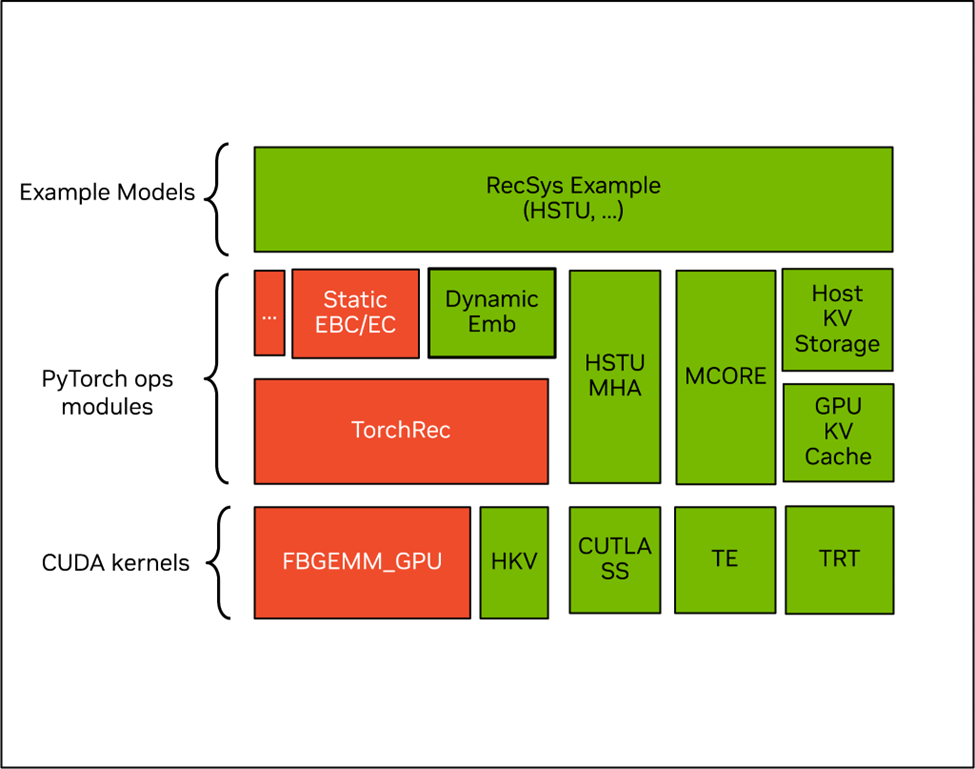
圖 1:NVIDIA recsys-examples 的軟件架構(gòu),其中綠色部分是 NVIDIA 開源組件,紅色部分是社區(qū)開源組件
一、高效的 HSTU 內(nèi)核
HSTU (Hierarchical Sequential Transduction Unit) 注意力結(jié)構(gòu)是論文中提出的一種針對推薦系統(tǒng)優(yōu)化的高效注意力機制。與標準的多頭注意力 (Multi-head Attention) 相比,HSTU 注意力做了以下關(guān)鍵改進:
Normalization改進:用 SiLU 替代 softmax,提升模型表達能力。
引入相對位置偏置:通過 Relative Attention Bias (RAB) 捕獲序列中的相對位置/時間信息。
在 recsys-examples 中,我們基于 NVIDIA CUTLASS 庫實現(xiàn)了高性能的 HSTU 注意力算子,并針對訓練和推理場景分別進行了優(yōu)化。目前實現(xiàn)也已經(jīng)合并到 FBGEMM 中,用戶可以直接通過 FBGEMM 使用。
1、訓練優(yōu)化技術(shù)
Kernel Fusion 計算融合:借鑒 Flash Attention 的思想,將多個連續(xù)操作融合為單個 GPU 內(nèi)核
靈活掩碼和 RAB 機制:支持可定制的 mask tensor 以及 RAB tensor,適應(yīng)不同推薦場景下的序列建模需求
2、推理優(yōu)化技術(shù)
簡化計算邏輯:使用 RAB (Relative Attention Bias) 作為負無窮替代傳統(tǒng)的 mask 操作,減少計算復雜度和內(nèi)存訪問,提升推理速度
稀疏目標優(yōu)化:針對推薦系統(tǒng)中常見的稀疏 target 計算模式進行優(yōu)化,減少內(nèi)存占用,并支持大規(guī)模目標的批量推理
在 NVIDIA Hopper 架構(gòu)上,我們的 HSTU 注意力算子相比與 Triton 實現(xiàn)的版本,在各個問題尺寸上都有超過 3.5x 的加速比,并且在序列增長的情況下,加速比進一步提升。
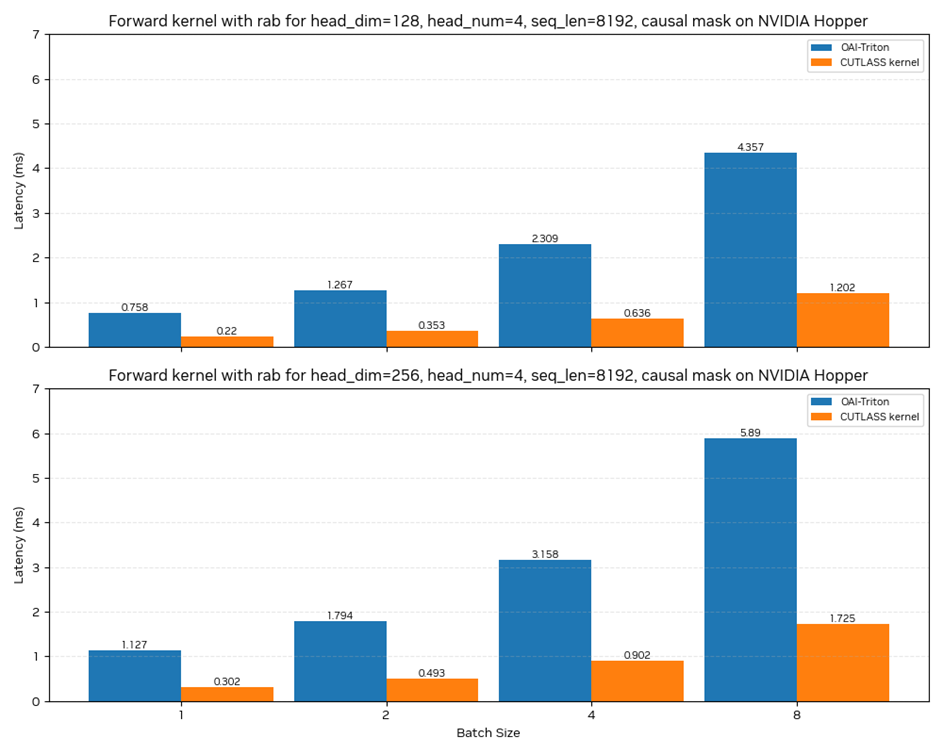
圖 2:CUTLASS Kernel 在 NVIDIA Hopper 架構(gòu)上與 Triton 的前向性能對比
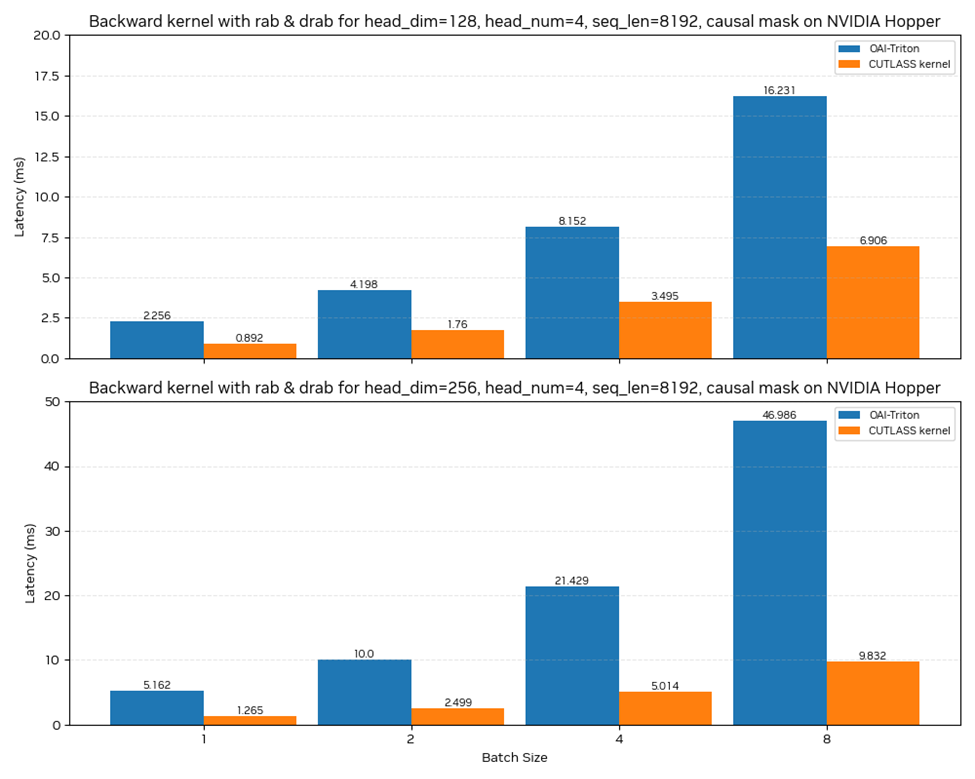
圖 3:CUTLASS Kernel 在 NVIDIA Hopper 架構(gòu)上與 Triton 的后向性能對比
二、動態(tài) embedding 與TorchRec 的無縫集成
TorchRec 目前對動態(tài) embedding 的支持有兩種,分別是 contrib / dynamic_embedding 通過外掛 CPU redis 集群和在 ManagedCollision 模塊中通過額外的排序步驟來支持,兩者都會在原有 TorchRec 訓練流程的基礎(chǔ)上,增加額外的訓練時間開銷。
在 recsys-examples 中,我們引入 NVIDIA Merlin HierarchicalKV 作為底層存儲,并與 TorchRec 團隊合作基于 TorchRec 官方插件接口,直接替換 TorchRec 中原本的 FBGEMM 靜態(tài)存儲,支持了動態(tài) embedding 支持能力。這一方案可在大規(guī)模推薦系統(tǒng)訓練場景中:
支持無沖突哈希映射
支持基于頻率或時間或自定義的 embedding 淘汰策略
提供 CPU offloading 機制來實現(xiàn)超大規(guī)模 embedding 存儲
支持 incremental dump 功能,根據(jù)用戶的需求只 dump 在過去一段時間內(nèi)訓練過的 embedding
保持與原生 TorchRec 分布式訓練流程的無縫集成
相比 contrib / dynamic_embedding 中的實現(xiàn),NVIDIA recsys-examples 能夠大幅度減少 CPU 上的操作開銷,在大規(guī)模訓練中能有超過 20 倍的加速效果。
更多詳細內(nèi)容您可觀看 "RecSys Examples 中的訓練與推理優(yōu)化實踐——以 HSTU 模型為例":
美團應(yīng)用
NVIDIA recsys-examples 實踐
在過去幾個月中,我們與美團緊密合作,助力其加速基于 HSTU 架構(gòu)的推薦模型在離線和在線試驗中的應(yīng)用。在美團外賣場景下,通過引入 GR 模型結(jié)構(gòu),CTR 和 CTCVR 指標均實現(xiàn)了顯著提升(詳情參考 MTGR 博客)。
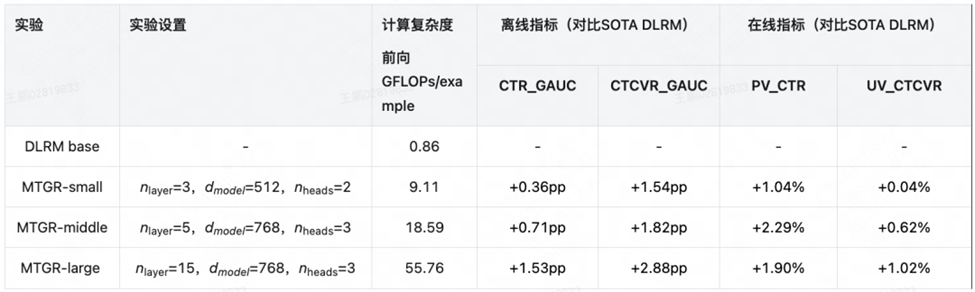
圖 4:美團業(yè)務(wù)引入 GR 后的收益。
該圖片來源于 MTGR:美團外賣生成式推薦 Scaling Law 落地實踐一文,若您有任何疑問或需要使用該圖片,請聯(lián)系美團
我們的優(yōu)化版 HSTU 算子,在訓練中,端對端吞吐提升 85%;在推理中,通過 TRT plugin 封裝,在 TRT 中引入了 HSTU fp16 算子,相比 TRT fp32 算子時延降低 50%,端對端耗時減少 30%。
總結(jié)與展望
NVIDIA recsys-examples 將生成式推薦(如 “Actions Speak Louder than Words” 論文中提出的技術(shù))與分布式訓練(借由 TorchRec 增強)及優(yōu)化訓練推理相結(jié)合,助力開發(fā)和部署能夠提供高度個性化用戶體驗的復雜推薦模型。我們誠摯邀請研究人員和從業(yè)者試用該工具,并期待與您共同推動生成式推薦系統(tǒng)的技術(shù)演進。
作者
劉仕杰
2020 年加入 NVIDIA DevTech 團隊,專注于 NVIDIA GPU 的性能優(yōu)化及推薦系統(tǒng)加速領(lǐng)域。
張俊杰
來自 NVIDIA DevTech 團隊,從事企業(yè)用戶 GPU 加速計算支持工作,目前主要負責推薦系統(tǒng)訓練端到端優(yōu)化工作。
姚家樹
來自 NVIDIA DevTech 團隊,從事企業(yè)用戶 GPU 加速計算支持工作,目前主要負責推薦系統(tǒng) Embedding 存儲的開發(fā)和性能優(yōu)化工作。
康暉
2022 年加入 NVIDIA DevTech 工程師團隊,目前從事機器人仿真加速相關(guān)工作,之前參加過 HugeCTR,SOK,recsys example 等項目開發(fā)和優(yōu)化。
柴斌
來自 NVIDIA DevTech 團隊,從事企業(yè)用戶 GPU 加速計算支持工作。目前主要負責搜廣推鏈路的性能調(diào)優(yōu)和 kernel 開發(fā)。
陳喬瑞
來自 NVIDIA DevTech 團隊,從事企業(yè)用戶 GPU 加速計算支持工作,目前主要負責 HPC 程序的開發(fā)和 kernel 性能優(yōu)化。
孫佳鈺
來自 NVIDIA DevTech 團隊,從事企業(yè)用戶 GPU 加速計算支持工作。
張琪
來自 NVIDIA DevTech 團隊,從事企業(yè)用戶 GPU 加速計算支持工作,目前主要負責 CUTLASS 在推薦系統(tǒng)、LLM 等相關(guān)應(yīng)用場景的性能優(yōu)化與開發(fā)工作。
-
NVIDIA
+關(guān)注
關(guān)注
14文章
5292瀏覽量
106190 -
AI
+關(guān)注
關(guān)注
88文章
34918瀏覽量
278148 -
模型
+關(guān)注
關(guān)注
1文章
3512瀏覽量
50302
原文標題:NVIDIA recsys-examples: 生成式推薦系統(tǒng)大規(guī)模訓練推理的高效實踐(上篇)
文章出處:【微信號:NVIDIA-Enterprise,微信公眾號:NVIDIA英偉達企業(yè)解決方案】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
嵌入式系統(tǒng)在生活中有哪些應(yīng)用
嵌入式語音識別系統(tǒng)在生活中的應(yīng)用有哪些呢
Adobe 攜手 NVIDIA 釋放生成式 AI 的力量

GTC23 | Adobe 攜手 NVIDIA 釋放生成式 AI 的力量
NVIDIA 攜手微軟,在生成式 AI 的新時代推動 Windows PC 創(chuàng)新
COMPUTEX2023 | 為加速生成式 AI 而設(shè)計的 NVIDIA Grace Hopper 超級芯片全面投產(chǎn)

VMware 與 NVIDIA 為企業(yè)開啟生成式 AI 時代

NVIDIA 擴展機器人平臺,迎接生成式 AI 的崛起

NVIDIA 擴展機器人平臺,迎接生成式 AI 的崛起
利用 NVIDIA Jetson 實現(xiàn)生成式 AI
生成式AI通過NVIDIA Isaac平臺提高機器人的智能化水平

NVIDIA生成式AI開啟藥物研發(fā)與設(shè)計的新紀元






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論