 基于FPGA的壓縮算法設計
基于FPGA的壓縮算法設計

第一部分 設計概述 /Design Introduction
1.1設計目的
本設計中,計劃實現對文件的壓縮及解壓,同時優化壓縮中所涉及的信號處理和計算密集型功能,實現對其的加速處理。本設計的最終目標是證明在充分并行化的硬件體系結構 FPGA 上實現該算法時,可以大大提高該算法的速度。我們將首先使用C語言進行代碼實現,然后在Vivado HLS中綜合實現,并最終在FPGA板(pynq-z2)上進行硬件實現,同時于jupyter notebook中使用python來進行功能驗證。
為使代碼可綜合同時又需要較少的硬件,我們已進行了許多改進,包括以下方面:
將所有浮點變量進行量化處理,量化為Q16.16定點,以簡化算術運算。與定點相反,浮點型變量需要更多的硬件來執行某些操作。
將余弦矩陣實現為8×8查找表,從而消除了對昂貴的CORDIC引擎的需求。
在頂層封裝時選用AXILITE接口,用于將文件從處理器傳輸給FPGA并讀回。這是PS端和PL端進行數據傳輸所必須的功能。
在各個功能函數分別進行流水線化,展開循環和內聯功能,以最大程度地減少延遲并最大程度地提高吞吐量。
1.2 掌握技能
在本項目中,學習到了如下:
學習gzip的文件格式,及deflate壓縮算法。能夠使用deflate算法對文件進行壓縮處理,同時將其封裝為gzip型文件。
學習了hls和python語言的使用。能夠通過hls進行相關的IP核開發,同時能夠使用python語言來對pynq-z2進行調試。
學習了vivado的使用核功能實現。能夠靈活利用HLS和vivado來進行功能開發。
1.3 應用方向
隨著大數據時代來臨,大量信息需要通過互聯網進行傳輸,占用的網絡資源急劇增加,給網絡傳輸帶來極大的壓力。數據壓縮技術能夠節約數據存儲空間、傳輸時間和帶寬,從而緩解傳輸壓力。無損壓縮 Gzip 是目前最常用的一種壓縮工具,被廣泛應用在網絡資料的下載和數據備份等領域。其中開源代碼 zlib 是 Gzip 算法最著名的實現版本,但因其算法本身計算量較大,導致壓縮的數據吞吐率較低。
FPGA 在數據處理速度上有著通用處理器無法比擬的巨大優勢,能夠大大提升Gzip的處理速度,減小CPU的開銷。
1.4 團隊分工
李佩琦負責hls和vivado實現,同時使用python進行功能驗證。
馮一飛負責資料查找,同時負責協助李佩琦進行功能實現和功能測試。
1.5 作品展示
整體功能已經實現,能夠在pynq z2上通過gzip壓縮方式對txt文件或大段字符串進行壓縮。具體展示如圖1,左側是在hls仿真是產生的結果,右側是通過jupyter notebook在pynq z2上進行調試的結果,兩者是一致的,壓縮功能能夠正常運行。圖2是jupyter notebook上部分python代碼。
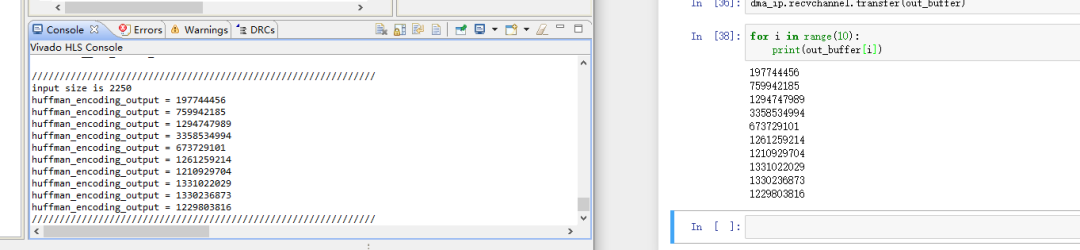
圖 1
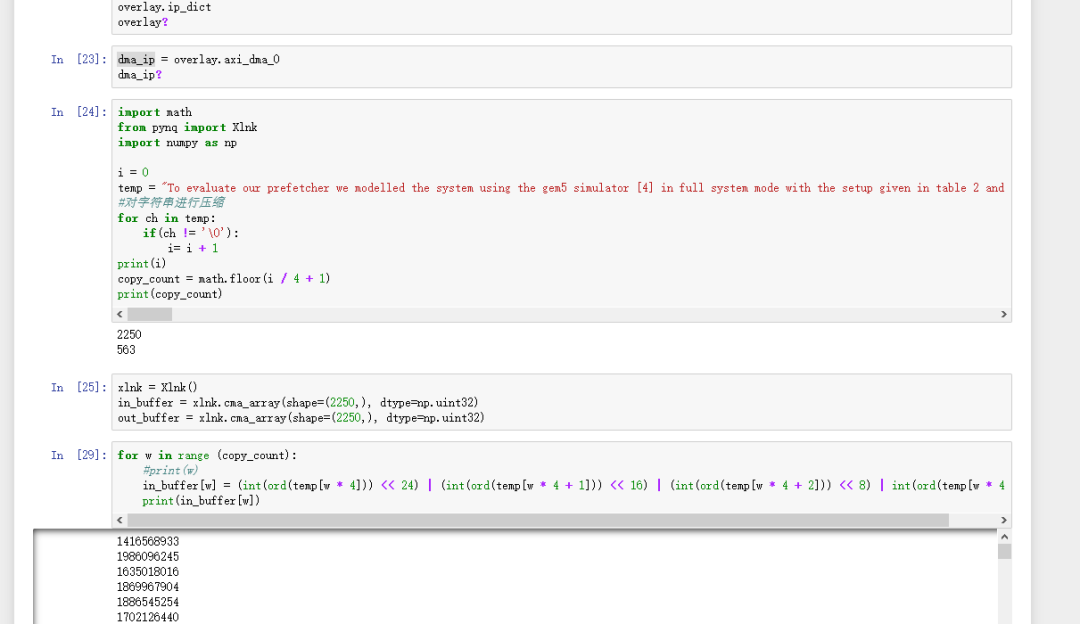
圖2
第二部分 系統組成及功能說明 /System Construction & Function Description
2.1 系統的功能實現
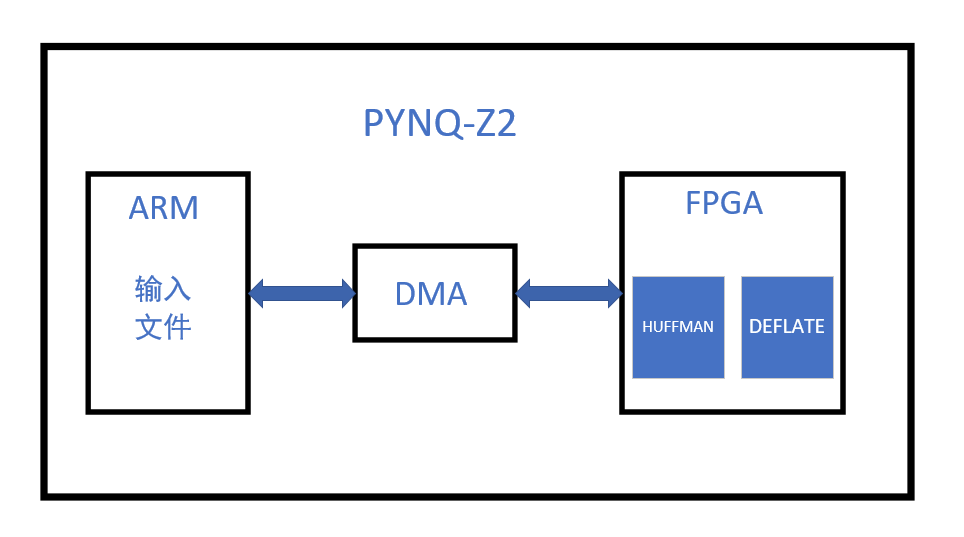
本設計中,在pynq-z2 FPGA平臺上使用Gzip對文件進行了壓縮算法的加速實現。整體分為兩部分,硬件部分采用靜態霍夫曼編碼,使用deflate對文件進行壓縮操作。Python模塊將FPGA硬件的deflate輸出進行封裝,將其封裝為gzip格式。
2.2 項目系統框圖
系統結構框圖如圖3所示。
圖3
2.3 gzip的基本組成
Gzip 壓縮是廣泛使用的數據壓縮方案,核心是 Deflate算法,主要包括 LZ77 編碼和哈夫曼編碼兩大部分。
2.3.1 gzip文件頭的基本組成
文件頭部分結構如圖4:

圖4
上面兩個“+”之間的內容代表一個字節,所以上面除了MTIME使用四個字節之外,其他只占用一個字節。
ID1 和ID2(IDentification) :這兩個字節用于標識gzip文件,其中,ID1 = 31(0x1f,?37),ID2 = 139(0x8b,213),如果判斷某文件以這兩個字節開頭,那么可以初步認為這是gzip文件,但具體是不是,必須該文件格式完全符合gzip文件格式才行;
CM (CompressionMethod):該字段用于標識當前gzip壓縮文件內部的壓縮結果所使用的壓縮方法,取值范圍[0,8],其中,[0,7]保留,目前只用8,即gzip使用deflate壓縮方法;
FLG (FLaGs):標記位,該標記位中的每一比特分別代表后面對應擴展位是否存在,各比特位含義不在此處列舉;
MTIME (ModificationTIME):該字段給出了被壓縮的原始文件最近被修改的時間。該時間使用Unix格式,即,自1970年1月1日0時起到現在的秒數。
XFL (eXtraFLags):該字段是用來記錄gzip文件中所使用的壓縮方法,由于當前gzip只使用一種壓縮算法,即deflate,所以針對deflate,該字段有如下含義,
XFL= 2 – 壓縮率最大但是壓縮速度最慢(的那個壓縮級別);
XFL= 4 – 最快的壓縮(級別);
OS (OperatingSystem):該字段表示執行壓縮操作的文件系統。該字段用于識別和確定確定文本文件的行結束標志。
2.3.2 gzip文件尾和文件體的基本組成
相比gzip文件頭,gzip文件尾較簡單,只由四個字節構成,結構如圖5:
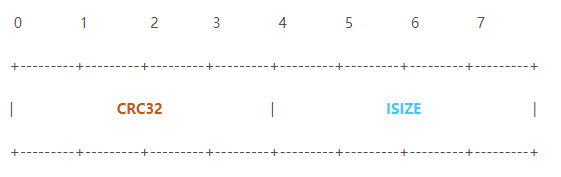
圖 5
CRC32 (Cyclic Redundancy Check):用標準循環冗余校驗算法對原始數據進行計算的結果。
ISIZE (InputSIZE):將原始數據大小對2^32取模的結果。
上面已經將整個gzip文件的基本文件格式分析完畢,下面簡單介紹gzip文件的文件體。該文件體主要與壓縮算法deflate相關。因為只要用到deflate的文件格式,該部分都是一樣的,比如gzip的文件體和PKzip的文件體“基本”是一樣的,因為它們都使用deflate進行壓縮。
2.4 DEFLATE 算法原理
DEFLATE 算法標準是由兩個壓縮算法聯合構成的,壓縮流程如6圖所示,其中主要包含 LZ77 和哈夫曼編碼。首先利用 LZ77 算法進行字典查找替代,消除重復信息,然后進行哈夫曼編碼構造平均長度最短的壓縮碼流。
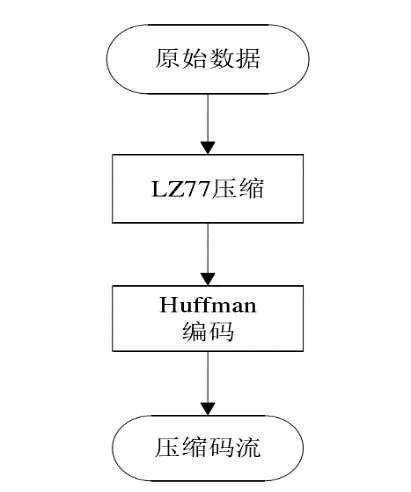
圖6
2.5 LZ77 算法
LZ77 算法是一種基于字典模型的壓縮算法。DEFLATE 算法中用到的 LZ77 算法是在原始 LZ77 算法的基礎上略加改進得到的,但算法基本思想保持不變。其基本原理為:將先輸入的數據作為字典信息進行保存,利用數據中存在字符串重復帶來的數據冗余性,根據字典中存儲的歷史數據對后續數據進行替換達到壓縮的目的。
具體在 Gzip 壓縮的參考軟件代碼 zlib 中實現 LZ77 算法的流程為:首先讀入緩存窗口大小 CHUNK 的數據,其中窗口的大小與匹配最大距離 MAX_MATCH 有關;依次計算輸入字符串的哈希值,將哈希值的作為字典地址的索引值,將字符串的位置信息依次存放在由哈希鏈表組成的字典中其哈希值對應的位置上;然后對當前的字符串根據索引值查找可能匹配的歷史字符串并進行最長匹配查找,判斷是否滿足匹配條件,若滿足則進行匹配對的替換;若不滿足則按照原始字符串輸出。對于 LZ77 壓縮算法的實現關鍵點在于歷史字符串的存儲、當前字符串的匹配查找、以及最長匹配選擇。
2.6 Huffman 編碼
哈夫曼編碼( Huffman coding )在數據壓縮的分類中提到,是一種基于統計模型的壓縮算法。其編碼理論依據是統計符號出現的概率,對符號按照概率從小到大進行排序,將其中出現概率最小的符號分配最長的編碼長度,按照這樣的規則進行變長編碼,達到平均編碼長度最小。具體編碼過程為:首先統計不同符號出現的概率,然后根據概率構建哈夫曼樹,最后根據哈夫曼樹得到每個符號的哈夫曼編碼。具體步驟如下:
步驟 1:統計 n 個不同信源符號出現的概率;
步驟 2:將概率按照從大到小的順序進行排列,并將其作為節點數為 1的子樹;
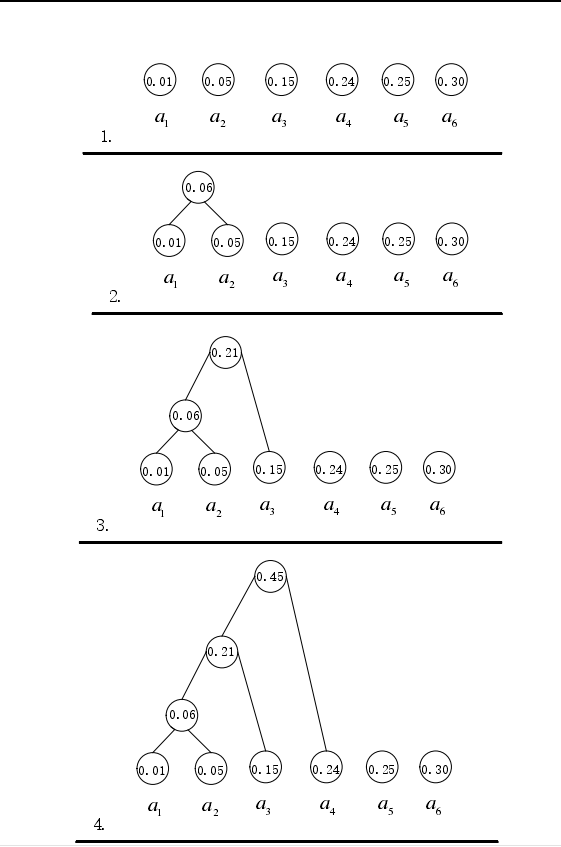
圖7
步驟 3:選出概率最小的兩個信源符號所在的子樹構成新的子樹,并且新合成的子樹概率為這兩個信源符號的概率相加;
步驟 4:重復步驟 3,直到所有信源符號的所在子樹均被加入到同一樹中;
步驟 5. 對構建的樹所有父節點的左結點標記為 0,右結點標記為 1;
步驟 6. 統計根節點到每個子節點的路徑,按照步驟 5 中 0-1 標記的路徑就是對應葉節點信源的哈夫曼編碼。
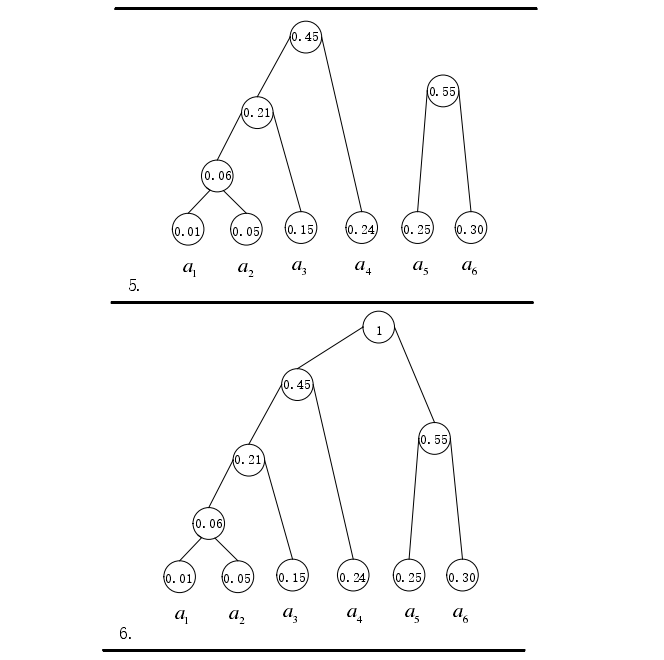
圖8
另外,在 Gzip 壓縮中,哈夫曼編碼的實現有兩種:分別為靜態哈夫曼編碼和動態哈夫曼編碼。其中靜態哈夫曼編碼不需要對編碼的字符做頻率統計,而是直接根據預先定義的編碼規范表查找進行編碼;似的,在解碼的過程中也不需要統計頻率而直接使用與編碼一致的編碼規范表進行解碼。對于動態哈夫曼編碼則遵循哈夫曼編碼的原理,需要對出現的字符進行頻率統計,生成哈夫曼樹,再據此生成編碼表進行編碼。
在本設計中,我們采用靜態哈夫曼編碼來進行實現。
第三部分 完成情況及性能參數 /Final Design & Performance Parameters
整體功能已經實現。并具備一定的加速效果,相比純arm進行壓縮速度提高了1.6倍。Vivado硬件工程能夠通過綜合、應用、生成比特流。最后通過Jupyter Notebook在pynq z2平臺上進行功能驗證。具體展示如圖9,左側是在hls仿真是產生的結果,右側是通過jupyter notebook在pynq z2上進行調試的結果,兩者是一致的,壓縮功能能夠正常運行。
圖9
圖10,圖11中,hls正常進行仿真,首先通過壓縮算法對txt文件或字符串進行壓縮,接著進行解壓操作,將解壓后的代碼與源代碼進行比較,如果結果一致,則能夠驗證壓縮算法本身功能的準確性。
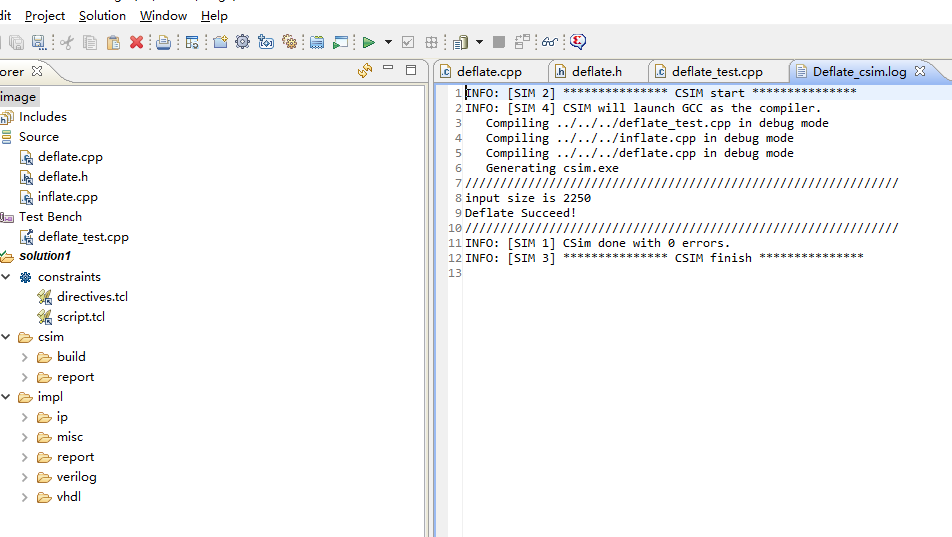
圖10
圖11
在圖12,圖13中,我們展示了部分壓縮算法代碼及優化指令,整體設計的源代碼為github上的開源代碼,在優化后我們外部的接口采用hls::stream的形式,內部使用到了pipeline,unroll等。
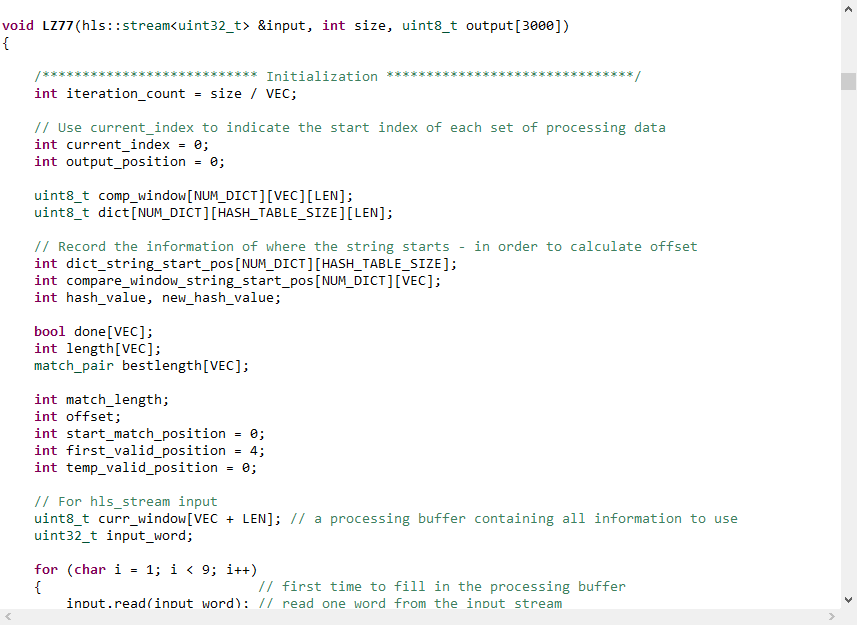
圖12
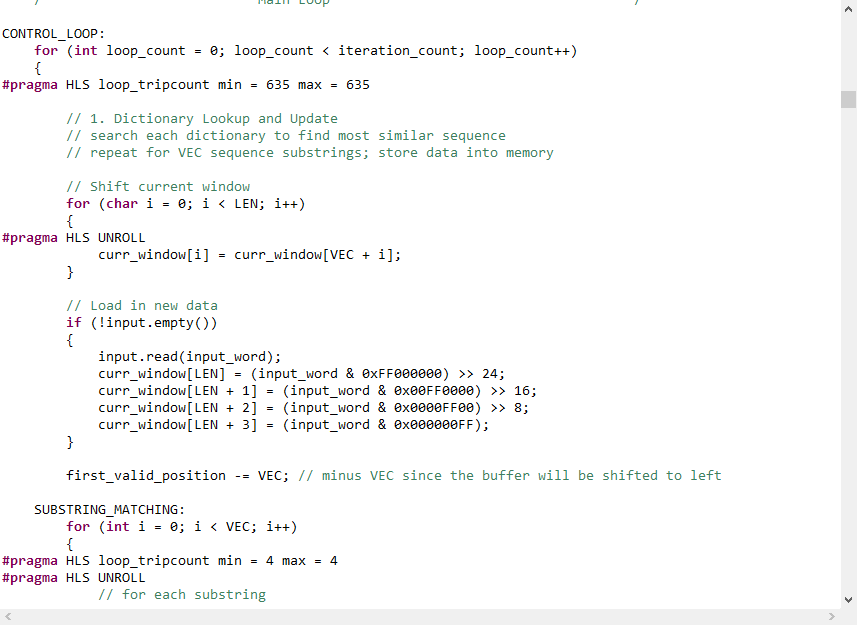
圖 13
在圖14,15中我們展示資源占比情況和時序分析,進行優化后實現了部分流水。
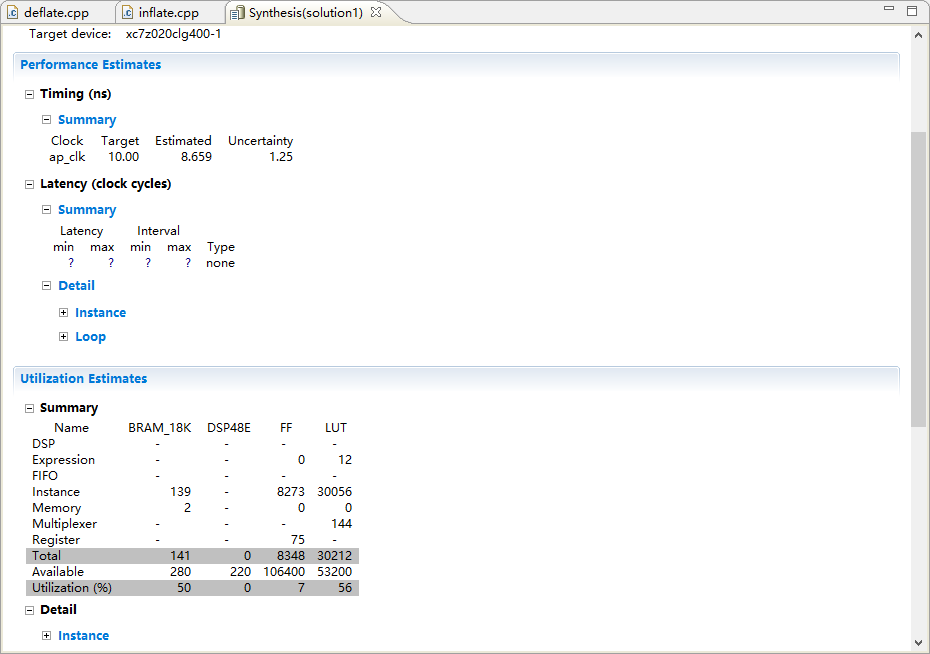
圖14
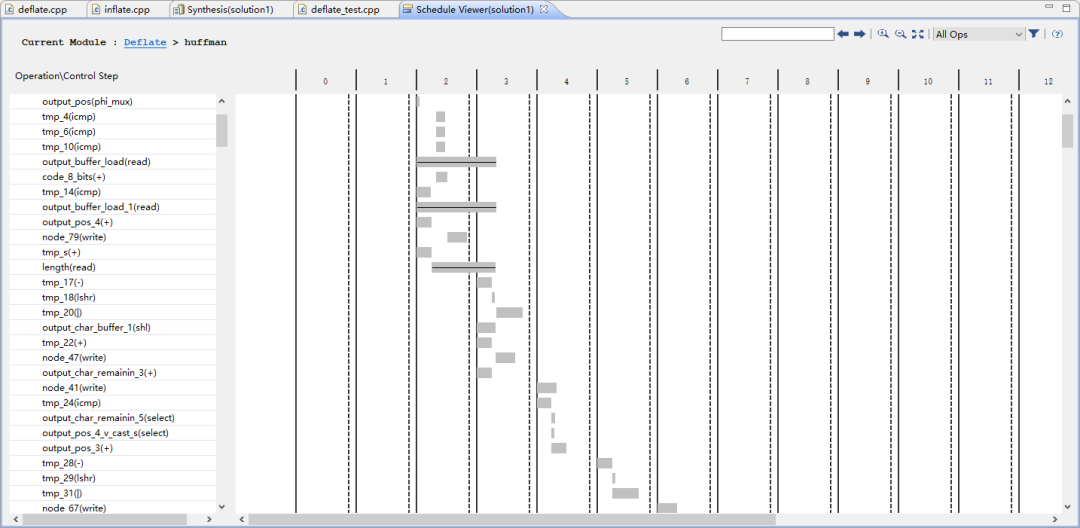
圖15
圖16中,vivado電路設計圖中hls生成的gzip ip核通過dma與ps端進行數據交互。
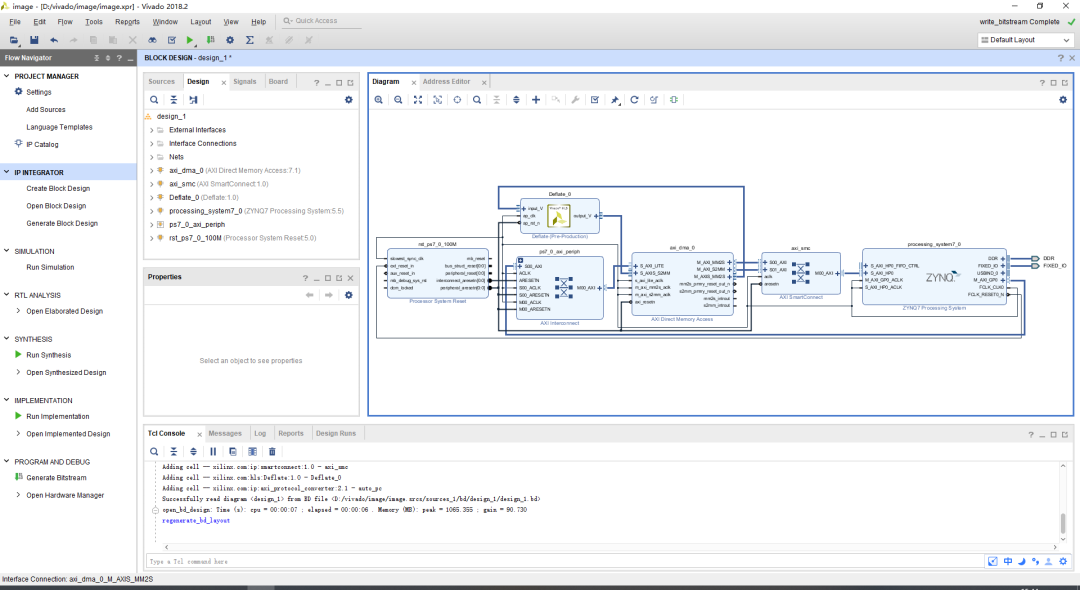
圖16
圖17中,我們展示notebook部分調試代碼,為了方便查看對部分輸出結果進行輸出,與HLS仿真結果進行對比發現結果正確,達到了最初的設計要求。
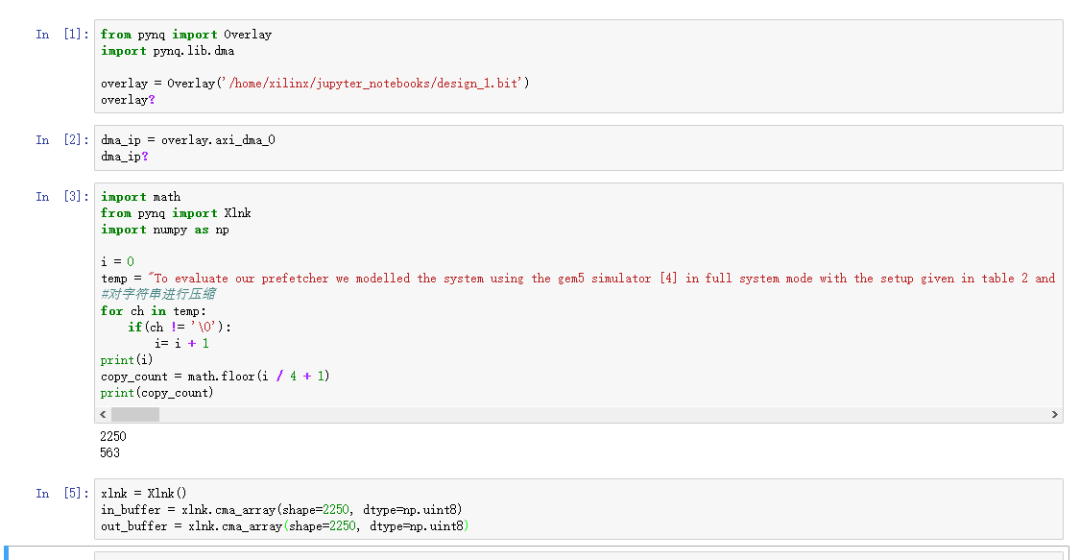
圖17
完
-
處理器
+關注
關注
68文章
19882瀏覽量
234950 -
FPGA
+關注
關注
1645文章
22034瀏覽量
617979 -
C語言
+關注
關注
180文章
7632瀏覽量
141527 -
壓縮算法
+關注
關注
1文章
22瀏覽量
10630
原文標題:基于 FPGA 的壓縮算法加速實現
文章出處:【微信號:HXSLH1010101010,微信公眾號:FPGA技術江湖】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
FPGA實現滑動平均濾波算法和LZW壓縮算法
語音壓縮算法研究
什么是壓縮算法呢?壓縮算法又是怎么定義的呢?
FPGA實現滑動平均濾波算法和LZW壓縮算法的論文資料說明
如何使用FPGA實現空間圖像CCSDS壓縮算法的設計
如何使用FPGA實現圖像動態范圍壓縮算法

FPGA壓縮算法有哪些






 工商網監
工商網監
評論