 AI耳機變身翻譯官+會議總結大師?涂鴉AI音頻開發方案,讓耳機升級到下一個level
AI耳機變身翻譯官+會議總結大師?涂鴉AI音頻開發方案,讓耳機升級到下一個level

在接入 AI 能力后,耳機這種日常化的產品,能有多大的想象空間?它不僅能幫你輕松聽懂全球外語和地方方言,還能將語音轉化為文字、翻譯成不同語言,甚至自動總結會議要點、生成思維導圖,適配辦公、學習、跨語言交流及日常生活等多類場景,妥妥的人類新型“智能聽覺中樞”!
為了助力開發者/品牌商快速開發能聽會說的 AI 音頻類設備,涂鴉重磅發布 AI 音頻轉錄總結方案,覆蓋耳機、錄音設備、眼鏡、音箱等硬件形態。通過簡單易用的涂鴉 API,開發者只需在涂鴉的面板小程序中少量配置,就能實現 App 收聲,并支持語音識別、翻譯、摘要、思維導圖生成等功能;搭配強大的 AI 引擎,開發者開箱即用,開發門檻更低。
目前,開發者可通過涂鴉云接入 DeepSeek、豆包、通義千問、Kimi、元寶等國內模型,海外則兼容 ChatGPT、Claude、Gemini 等先進 AI 大模型。
一、落地應用案例
1、AI 耳機:錄音翻譯大師
涂鴉賦能 AI 耳機,支持將音頻數據傳輸到 App 上,并通過 VAD(語音活動檢測)+ ASR(語音轉錄文字)能力,實時處理數據。語音轉錄為文字后,就可將識別結果即時反饋給App。此外,依托 AI 大模型技術,涂鴉可進一步總結轉換后的文字內容,并精準翻譯,通過耳機語音播報給用戶。這不僅提升了用戶的使用體驗,還能夠滿足線上或面對面的多語言交流需求。
2、AI 會議錄音卡片:辦公神助攻
涂鴉賦能AI 會議錄音卡片,不僅是一個錄音工具,更能夠與會議紀要功能結合:它支持實時總結會議音頻內容,并智能生成文字摘要和詳細的會議紀要。這一解決方案有效地簡化了會議記錄+總結過程,高效率推動后續工作,幫助上班族節省時間與精力。
二、App 界面功能演示
下方是涂鴉賦能App 界面的展示,連接 AI 音頻設備后(接下來將以涂鴉賦能 AI 耳機為例,進行具體介紹),即可擁有現場錄音、同聲傳譯和面對面翻譯功能。功能將持續迭代,敬請期待!
1、音頻實時轉錄成文字
用戶在通話、會議講座或收聽廣播場景下,AI 耳機都會實時采集語音。App 接收音頻數據后,會及時轉寫成文字,非常適合語言學習者、聽障人群或需要文字記錄的場景。識別結果會同步展示在屏幕上,便于查看、復制與保存。
下面是該功能的動態示意圖:
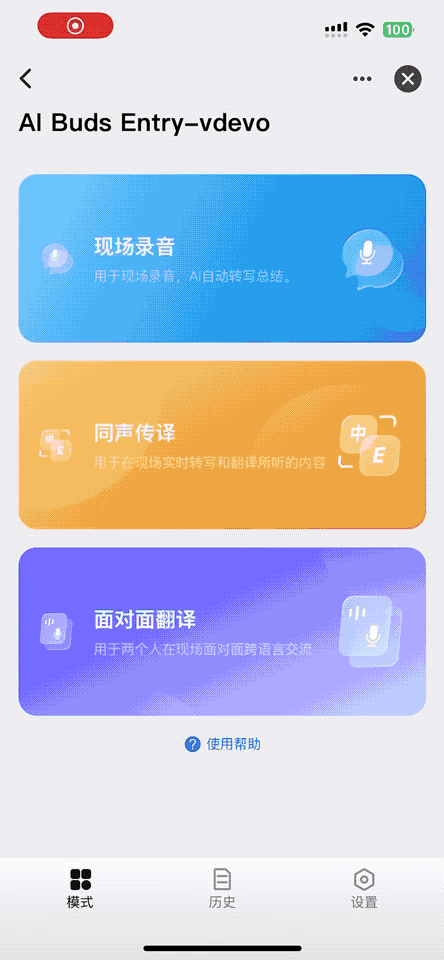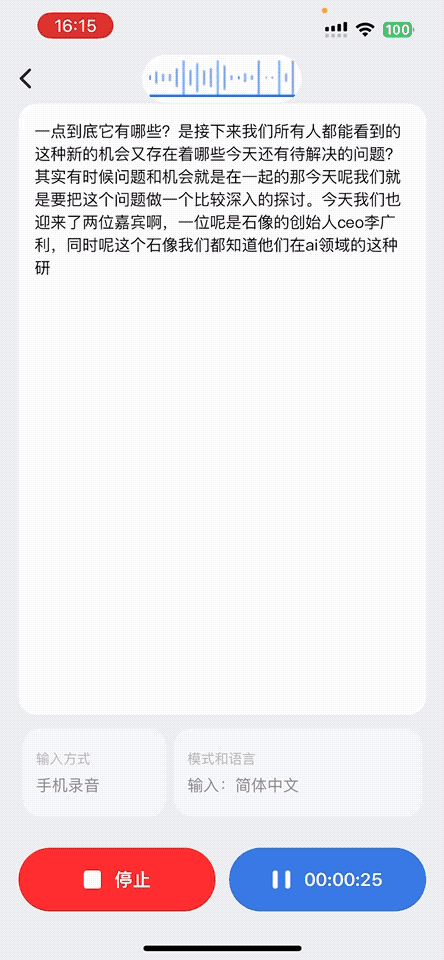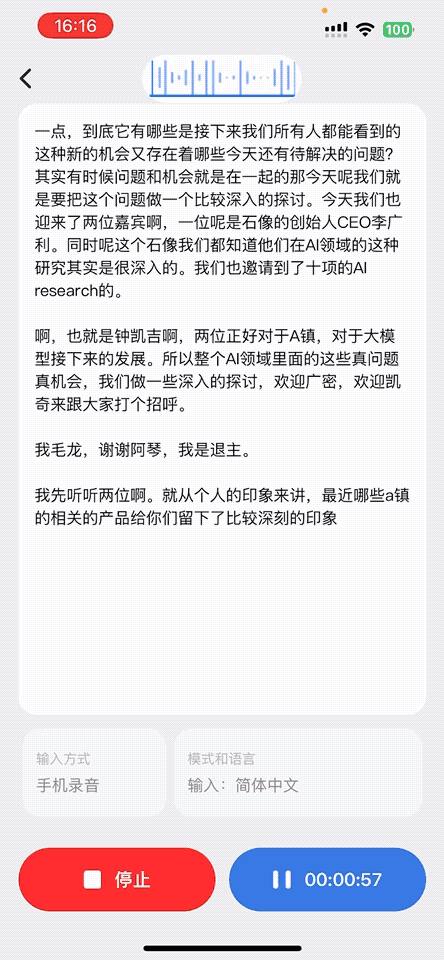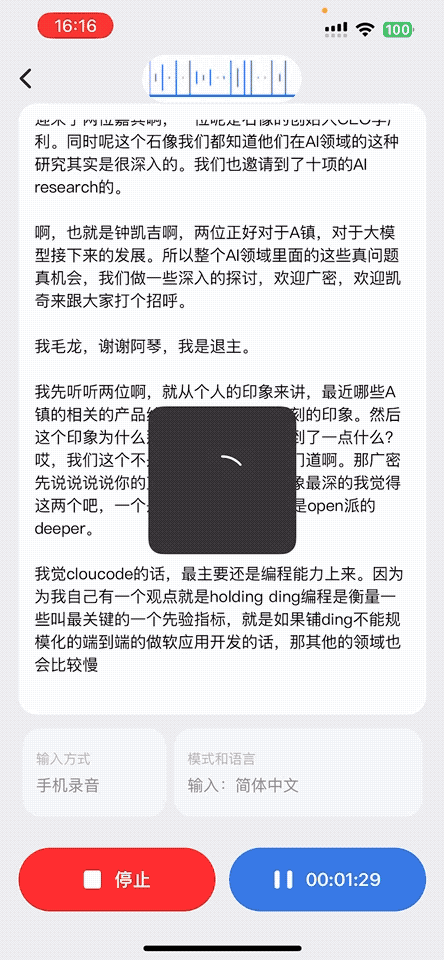
2、面對面翻譯
在跨語言交流場景中,兩人都佩戴 AI 耳機或一人一只耳機,就可實現“你說我譯”的雙向語音翻譯功能。語音通過耳機傳入 App,App 實時轉寫、翻譯并播報結果,大幅降低語言溝通門檻,適用于出境旅行、商務接待、跨境會談等多語種場景。

3、會議錄音
在多人會議或訪談場景中,AI 耳機可用作便捷的拾音設備,實時采集多方語音內容。App 端實現同步語音轉寫,并可生成完整的會議紀要和思維導圖,支持后續查詢、存檔處理,有效提升會議效率與內容管理能力。


三、涂鴉 AI 音頻技術的獨特之處
涂鴉 AI 音頻開發方案,由三大核心模塊構成,即:設備端、App 端、云端AI,整體架構圖可參考下方示意圖:
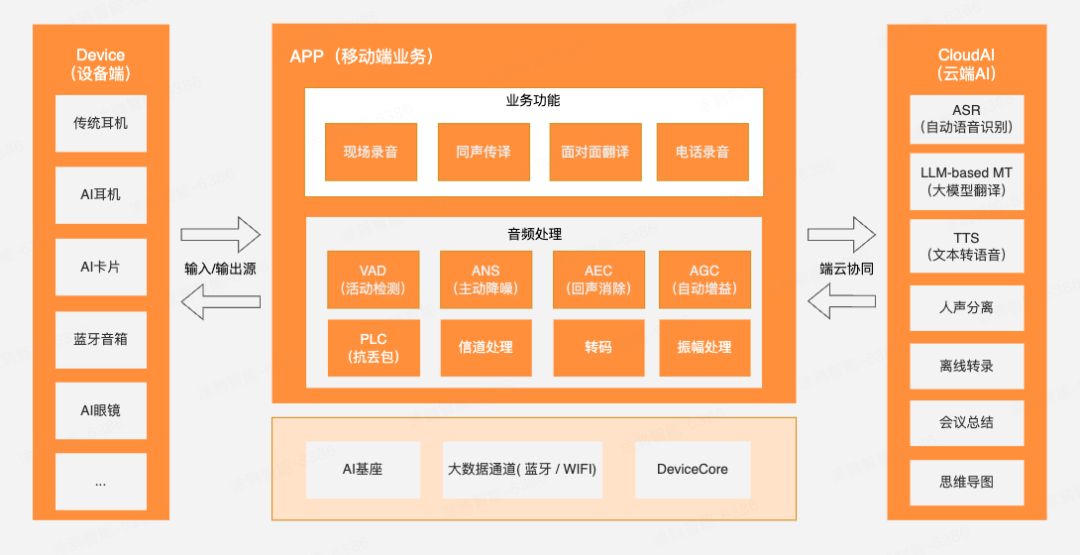
1、設備端
設備作為音頻輸入輸出的載體,支持通過傳統 BT 配對和 Bluetooth LE 的方式連接 App。相比普通藍牙耳機,涂鴉賦能 AI Pro 耳機可以通過特定的 DP 點下發指令,實現更豐富的雙向控制,如:
App 與 AI 耳機能夠雙向傳輸指令、同步狀態
開始/暫停錄音
控制單耳收音和播放
支持雙耳一對一的同聲翻譯功能(即左右耳可同時播放不同內容,兩個人分別佩戴一只耳機即可實現同聲翻譯)
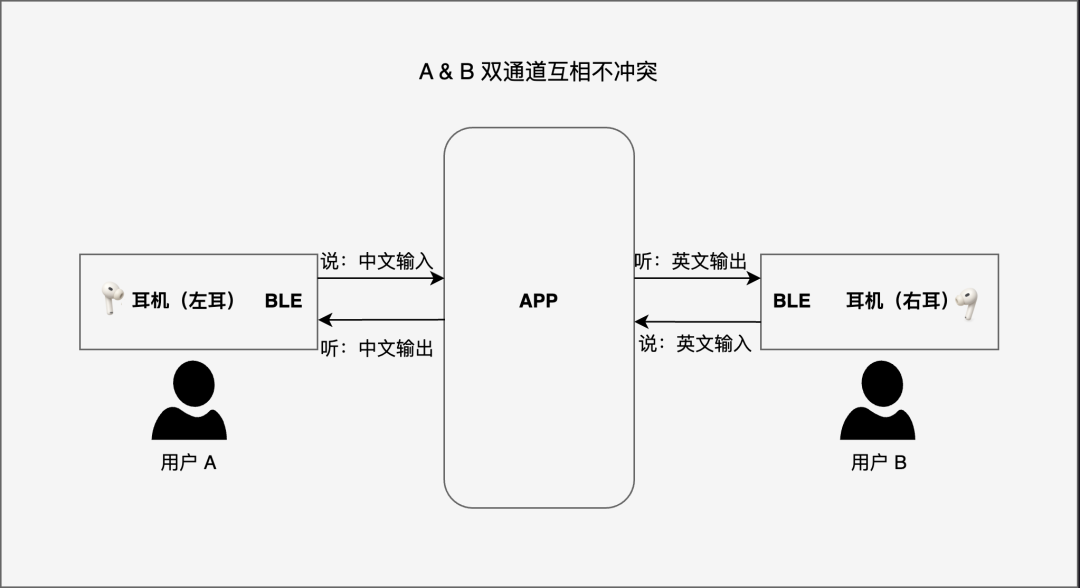
(左右耳雙道獨立運行流程圖)
2、App 端
App 主要承擔 AI 音頻的數據處理與業務邏輯運行:
業務功能:支持現場錄音、同聲傳譯、面對面翻譯、電話錄音等功能模塊;
音頻處理:本地進行 VAD、AEC、ANS、AGC、PLC、振幅處理、轉碼、信道管理等技術處理,能夠讓音質的輸出清晰無雜音、更穩定,并保持音頻連續性;
基礎能力:支持 AI 基座協議、設備通信協議、大數據通道(藍牙/Wi-Fi)。
3、云端 AI 能力
涂鴉在云端AI集成了多個模型與能力,包括:
ASR:搭載高精度的語音自動識別,讓 AI 秒懂人類語言,準確無誤地將音頻中的語音內容轉寫為文本;
LLM-based MT:支持用大語言模型做翻譯,語境理解能力更強,告別從前死記硬背的機械式翻譯(涂鴉目前可支持 65+ 地區語言,并不斷擴展中);
TTS:支持文字轉語音,能成熟模仿不同人物的音色,并搭配不同情緒的語氣,讓 AI 發音更擬人化(用戶可自定義配置音色);
其他拓展能力:涂鴉還支持語音分離、離線轉錄、會議總結、思維導圖生成等功能。
通過統一協議協同處理,端云一體可實現低延遲、高效率、高智商的 AI 語音服務。
四、AI 音頻技術的流程處理
涂鴉 AI 音頻技術的流程處理,總共分為三個階段:
拾音+3A處理+轉碼:即聲音采集與預處理
VAD+音頻切片:即有效語音檢測與切片處理
ASR+翻譯+TTS:即智能識別、翻譯與語音合成
整體流程圖可參考: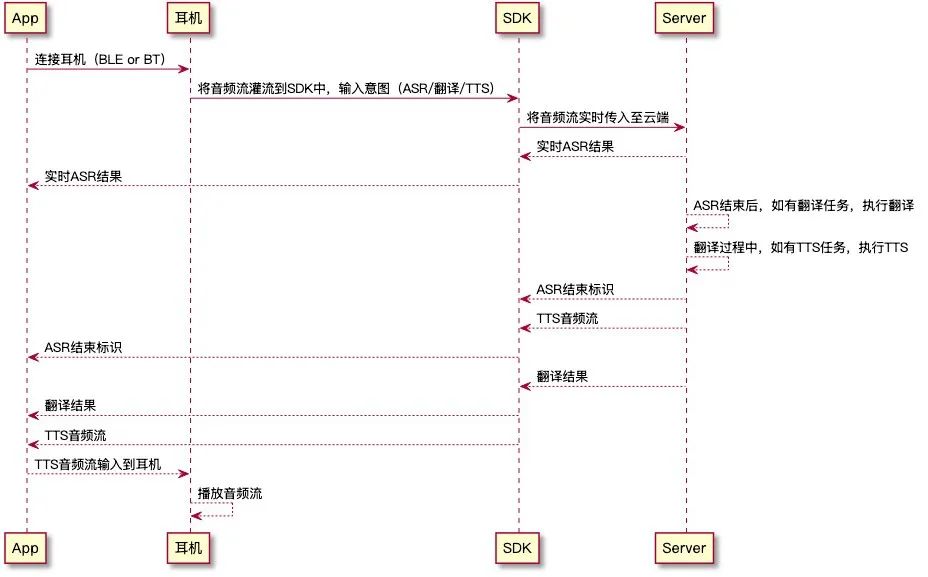
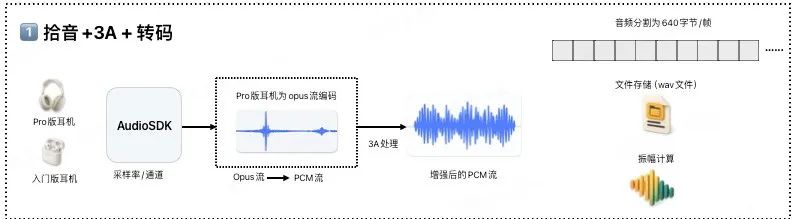
1、拾音+3A處理+轉碼
首先,由耳機或 App 采集原始語音,并降噪、消除回聲后統一加工成 PCM 流后,交給 3A 模塊進行預處理。處理后的音頻會自動保存為 wav 文件,便于進行振幅計算(即計算聲音強度);為了后續高效處理,涂鴉將音頻數據分割為 640b/幀的數據塊。
2、VAD+音頻切片
涂鴉會對連續 PCM 音頻流進行精準的 VAD 語音識別檢測,并整合出有效的語音片段,智能區分哪里是人在說話、哪里是靜音或背景噪音。然后按規則(如 100ms/段)進行切片,緩存發送到待識別的 ASR(語音轉換為文本)隊列。
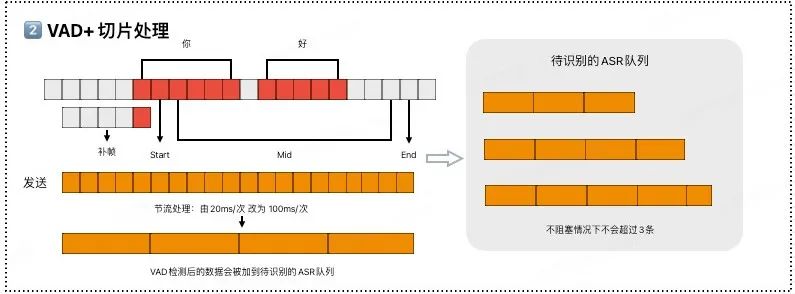
3、ASR+翻譯+TTS
收到語音片段后,系統會自動發送到云端完成 ASR 識別
如果用戶開啟了翻譯功能,就會在完成語音轉文字后,同步調用大模型進行語言翻譯;
翻譯后的文字,可通過 TTS,合成目標語言播放給用戶聽;
最終,所有識別或翻譯結果,都會通過 AI 基座與業務層進行通信,并回調至面板小程序中。
-
音頻
+關注
關注
29文章
3039瀏覽量
83385 -
AI
+關注
關注
88文章
35041瀏覽量
279094 -
涂鴉智能
+關注
關注
7文章
262瀏覽量
20023
發布評論請先 登錄
水表界的“翻譯官”:讓CCLinkIE和Modbus TCP“無障礙聊天”!
CC-Link IE 轉 Modbus TCP,閥門通訊的“雙語翻譯官”
廣州郵科通信逆變器:12V直流輸入的“能量翻譯官”,讓通信永不斷線
CAN收發器:總線信號的“翻譯官”

制藥廠里的“翻譯官”:DeviceNet轉Modbus RTU協議轉換網關如何助力生產
工業通信的“超級翻譯官”Modbus轉Profinet如何讓稱重設備實現語言自由
EtherCAT轉Profinet網關:紡織業設備互聯的“翻譯官”

【「零基礎開發AI Agent」閱讀體驗】+初品Agent
首創開源架構,天璣AI開發套件讓端側AI模型接入得心應手
《零基礎開發AI Agent——手把手教你用扣子做智能體》
涂鴉AI玩具2.0解決方案發布!連續對話×聲音克隆,打造更懂孩子的智慧伙伴

AI助力實時翻譯耳機






 工商網監
工商網監
評論