 可以將深度學習圖像分類器用于目標檢測嗎?
可以將深度學習圖像分類器用于目標檢測嗎?
本文編譯自 Adrian Rosebrock 發表在PyImageSearch 上的一篇博文。該博文緣起于一位網友向原作者請教的兩個關于目標檢測的問題:
如何過濾或忽略我不感興趣的類?
如何在目標檢測模型中添加新的類?這是否可行?
Adrian Rosebrock 認為這兩個問題是學習目標檢測的同學經常問到的問題,于是創作了本篇文章統一回答。
具體來說,在這篇文章中你會了解到:
圖像分類和目標檢測的區別;
深度學習目標檢測模型的構成,包括目標檢測框架和基本模型框架的不同;
如何將訓練好的深度網絡模型用于目標檢測;
如何過濾和忽略深度學習模型所檢測的類別;
在深度神經網絡中,添加或刪除檢測類別時常見誤區。
想要了解更多的關于深度學習目標檢測方面的知識,或者想要解開關于深度學習目標檢測的相關疑惑,請繼續閱讀。
▌深度學習目標檢測指南
今天的博客旨在簡單介紹基于深度學習的目標檢測。
我已經盡量提供關于深度學習目標檢測模型構成的內容,包括提供使用預先訓練的目標檢測模型實現深度學習的 OpenCV + Python 的源代碼。
使用這個指南能夠幫助你初步了解深度學習目標檢測,但同時你也會意識到,涉及目標檢測的很多技術細節,我無法在這篇博客中講得面面俱到。
也就是說,我們將通過討論圖像分類和目標檢測的本質區別來引出今天的博客內容,包括圖像分類訓練好的模型能否用于目標檢測(以及在什么情況下)。
我們一旦理解了什么是目標檢測后,我們將會回顧深度學習目標檢測模型的核心部分,包括目標檢測框架和基礎模型,這是初次接觸目標檢測的讀者感到疑惑的兩個關鍵部分。
在這基礎上,我們將會使用 OpenCV 運行實時深度學習目標檢測模型。
在不改動網絡結構和重新訓練模型的前提下,我將會演示如何能夠忽略和過濾你不感興趣的目標類別。
最后,我們將討論在深度學習目標檢測中如何添加或刪減類別,我們將以此結束今天的博客,包括我推薦的資源來幫助你入門。
讓我們開始深入了解深度學習目標檢測吧!
▌圖像分類和目標檢測的區別

圖1:分類(左邊)和目標檢測(右邊)的直觀區別。對于圖像分類,是將整張圖片進行分類,并且是單一標簽。對于目標檢測的情況,我們的神經網絡會對圖片中的(潛在的多個)目標進行定位。
當進行標準圖像分類時,指定一個輸入圖像,我們將它輸入到我們的神經網絡中,我們會獲得一個類標簽,或者是相應被分類標簽的概率。
這個類標簽旨在描述整張圖像的內容,或至少是圖像中最主要的可視內容。
舉例子來說,如圖1中指定的輸入圖像(左邊),我們的卷積神經網絡把圖像標記為“比格犬”。
因此,我們可以將圖像分類視為:
一張圖片輸入;
一個類標簽輸出。
目標檢測,無論是通過深度學習還是其他計算機視覺技術實現,目標檢測均基于圖像分類,同時試圖精準定位圖像中每個目標的位置。
在執行目標檢測時,給定一個輸入圖像,我們希望能夠獲得:
邊框列表,或者圖像中每個目標的 (x, y) 坐標;
每個邊框所對應的類標簽;
每個邊框和類標簽相應的概率和置信度分數。
圖 1(右邊)給出了一個運用深度學習進行目標檢測的例子。注意,用邊界框對人和狗進行定位,并給出預測類標簽。
因此,目標檢測讓我們能夠:
向網絡輸入一張圖像;
獲得多個邊框和類標簽作為輸出。
▌可以將深度學習圖像分類器用于目標檢測嗎?

圖 2:使用滑動窗口的非端到端深度學習目標檢測模型(左邊)+ 結合分類的圖像金字塔(右邊)方法
好的,所以此時你理解了圖像分類和目標檢測最重要的區別:
當實行圖像分類時,我們向網絡中輸入一張圖像,并獲得一個類標簽作為輸出;
但是,當實行目標檢測時,我們輸入一張圖像,將獲得多個邊界框和類標簽輸出。
引出了這個問題:
對于已經訓練好的用于分類的網絡,我們是否能將它用于目標檢測?
答案有點復雜,因為技術上“可以”,但是原因并不那么淺顯。
解決方案涉及:
運用傳統基于計算機視覺的目標檢測方法(即非深度學習方法),比如滑動窗口和圖像金字塔,這類方法通常用于基于 HOG 特征和線性支持向量機的目標檢測器中;
獲取預先訓練好的模型,并將它作為深度學習目標檢測框架的基礎網絡。(比如 Faster R-CNN, SSD, YOLO )。
方法 1:傳統目標檢測方法
第一種方法不是純粹的端到端的深度學習目標檢測模型。
我們采用:
固定大小的滑動窗口,這個窗口自左到右,自上到下滑動去定位不同位置的目標;
圖像金字塔,用于檢測不同尺度的目標;
通過預先訓練好的卷積神經網絡(分類器)進行分類。
在滑動窗口和圖像金字塔的每次停頓中,我們找出感興趣的區域,傳輸到卷積神經網絡中,并且輸出這個區域的分類。
如果標簽L的分類概率比某個閾值T高,我們將標記這個感興趣區域的邊框為標簽 L。每次滑動窗口和圖像金字塔停頓都將重復這個過程,我們將會獲得輸出的目標檢測結果。最后,我們對所有的邊框采用非極大值抑制,生成我們最終輸出的檢測結果:

圖 3:應用非極大值抑制將抑制重疊,減少邊框置信度
這個方法可以用于某些特定用例中,但是,一般而言,這種方法很慢,冗長乏味,并且容易出錯。
然而,因為這種方法可以將任意圖像分類網絡轉換成目標檢測模型,如何運用這個方法還是值得好好研究的,從而避免直接訓練端到端的深度學習目標檢測模型。根據你的用例,這種方法能為你節省大量的時間和精力。
如果你對這種目標檢測的方法很感興趣,還想了解更多將滑動窗口、圖像金字塔和圖像分類方法用于目標檢測內容,請請參閱我的書,Deep Learning for Computer Vision with Python
方法 2:目標檢測框架的基礎網絡
深度學習目標檢測中的第二種方法,這種方法將事先訓練好的分類網絡視為深度學習目標檢測框架中的基礎網絡(比如 Faster R-CNN, SSD, or YOLO )。
這樣做的好處是你可以創建一個基于深度學習的完整的端到端的目標檢測模型。
缺點就是這種方法要求對深度學習目標檢測工作原理有一定的了解,下一節將對此加以討論。
▌深度學習目標檢測的組成元素
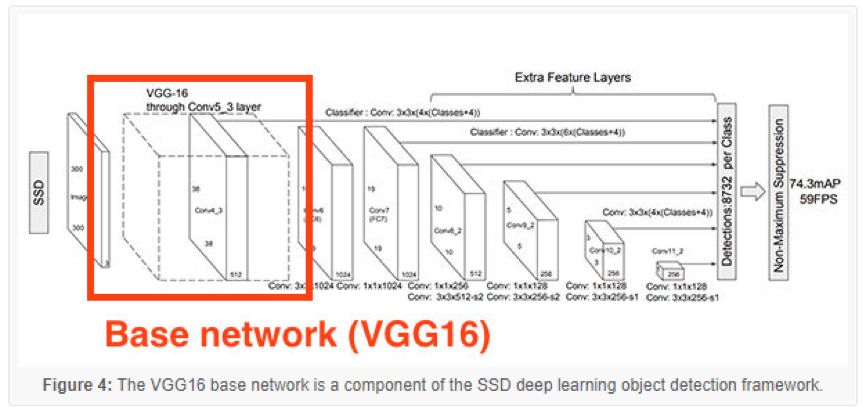
圖 4:VGG16 基礎網絡是 SSD 深度學習目標檢測框架中的一部分
深度學習目標檢測模型有很多組件、子組件和二級子組件,但是,今天我們主要關注兩點,深度學習目標檢測新手經常混淆的兩點:
目標檢測框架(比如 Faster R-CNN, SSD, YOLO);
符合目標檢測框架的基礎網絡。
你可能已經了解基礎網絡,基礎網絡是我們常見的(分類器)卷積神經網絡結構,包括:
VGGNet
ResNet
MobileNet
DenseNet
一般來說,為了學習得到豐富的判別濾波集合,這些用于圖像分類的網絡預先在大型圖像數據集(如 ImageNet)中已經訓練完成。
目標檢測框架由很多組件和子組件構成。
舉例子來說,Faster R-CNN 的框架包括:
候選區域生成網絡 (RPN);
候選窗口集合;
感興趣區域 ROI pooling 層;
最終基于區域的卷積神經網絡。
當使用 Single Shot Detectors (SSDs) 時,SSD 會包括如下的組件和子組件:
MultiBox,邊框回歸技術;
Priors,預先計算的固定大小的邊框(像 Faster-R-CNN terminology 候選窗口);
Fixed priors,每個特征圖單元都與不同維度和尺寸默認邊框的集合相關聯。
記住了,基礎網絡只是其中一個符合總體深度學習目標檢測框架的組件,在這一節頂部的圖3中,它描述了 SSD 框架中的作為基礎網絡的 VGG16。
通常情況下,在基礎網絡上進行修改,這個修改包括:
將基礎網絡編排成全卷積形式(即能夠接受任意維度的輸入);
移除基礎網絡結構中更深的 CONV 和 POOL 層,將它們替換成一系列新的層(SSD)、新的模型(Faster R-CNN)或是兩者的結合。
術語“網絡手術”是一種口語化的表達,用來說明我們刪減了一些基礎網絡中的原始層,并插入一些新的層來取代它們。
你可能看過低預算的恐怖電影,電影中的兇手也許攜帶斧子或大刀,攻擊他們的受害者,毫不手軟地攻擊他們。
網絡手術比典型的 B 級恐怖電影中的殺手更加精確和嚴格。
網絡手術很有戰略意義,我們刪除了網絡中我們不需要的部分,將它替換成一組新的組件。
然后,當我們去訓練框架用于目標檢測時,以下兩項的權重均已修改(1)新的層和模塊;(2)基本網絡。
重復一下,針對各種深度學習目標檢測框架工作原理的完整的回顧(包括基礎網絡所扮演的角色)已經超出了本博客的范圍。如果想深入了解深度學習目標檢測的內容,包括原理和實 現,請參考我的書籍,Deep Learning for Computer Vision with Python。
▌如何評估深度學習目標檢測模型的精度?
當評估目標檢測模型的性能時,我們使用的評價指標是平均精度均值(mAP),mAP是基于我們數據集中所有類別的交并比(IoU)計算得到的。
交并比(IoU)

圖 5:在這個交并比 IoU 的直觀例子中,將真實值的邊框(綠色)與預測的邊框(紅色)進行對比。IoU 與平均精度均值 mAP 一起被用于深度學習目標檢測的精度評估。右邊為用于計算 IoU 的等式
也許你會發現 IoU 和 mAP 通常用于評價 HOG 特征 +線性 SVM 檢測模型,Haar特征級聯分類器和基于深度學習模型的性能; 然而,記住,實際上用于生成預測邊框的算法并不重要。
任何用來提供預測邊框(以及供參考的類標簽)作為輸出的算法,這些算法均能是用 IoU 進行評估。更正式地說,為了使用 IoU 來評價任意一種目標檢測模型,我們需要:
1.真實值的邊框(也就是,在測試集中,通過我們手動標記的,目標對象所處位置的邊框);
2.來自我們模型的預測邊框;
3.如果你想要計算召回率和精確率,你還需要真實值的類標簽和預測值的類標簽。
在圖 4(左邊)中,我給出了一個直觀的例子,真實值的邊框(綠色)與預測邊框(紅色)對比。通過圖 4(右邊)的等式來計算IoU。
審視這個等式,你會發現 IoU 是一個簡單的比值。
在分子部分,我們計算的是預測邊框與真實值邊框之間的重疊面積。
分母是并集區域面積,或者更簡單地說,分母是被預測邊框和實際邊框兩者包含的面積。
交集區域除以并集區域將得到最終的分數,交并比得分。
平均精度均值(mAP)
為了在我們的數據集中評估目標檢測模型的性能,我們需要計算基于 IoU 的mAP:
基于每個類(也就是每個類的平均精度);
基于數據集中的所有類別(也就是所有類別的平均精度值的平均值,術語為平均精度均值)
為了計算每個類的平均精度,對指定類中所有數據點計算它的 IoU。
一旦我們得到了這個類別中用全部數據計算的 IoU,我們就可以計算該類的平均精度(初次均值)。
為了計算 mAP,我們要計算所有N個類別中的平均 IoU,然后就可到了 N 個平均精度的均值(平均精度的均值)。
通常情況下,我們使用 mAP@0.5,mAP@0.5 的意思是在測試集中,為了使目標能夠標記為“正檢測樣本”,這個目標與真實值的 IoU 值至少必須達到 0.5(并且被正確標記類別)。這個 0.5 值是可以調整的,但是在大多數的目標檢測數據集和挑戰中,0.5 是標準值。
▌基于 OpenCV 的深度學習目標檢測
在以前的博客中,我們已經討論了深度學習目標檢測,完整起見,讓我們先來回顧一下實際運用中的源代碼。
我們的例子中包括 SSD 檢測器和 MobileNet 基礎網絡模型。GitHub 用戶 chuanqi305 在 COCO 數據集上訓練了這個模型。
讓我們先來回顧 Ezekiel 的第一個問題,在本文開頭就提到的問題:
如何過濾或忽略不感興趣的類?
這是個很好的問題,我將用以下樣例腳本來回答。
但是,首先,需要準備以下系統:
你需要至少在你的 Python 虛擬環境中安裝 OpenCV 3.3 版本(假設你使用的是 Python 虛擬環境)。運行以下的代碼需要 OpenCV 3.3 或 3.3 以上的版本中的 DNN 模塊。請選擇下頁中其中一種 OpenCV 的安裝教程,同時特別注意你所下載和安裝的 OpenCV 的版本。
同時,你還應該安裝我的 imutils 包。想在你的 Python 虛擬環境中安裝或更新 imutils 包,可以簡單地使用
pip: pip install --upgrade imutils
準備好了之后,繼續創建命名為 filter_object_detection.py 的新文件,然后開始:
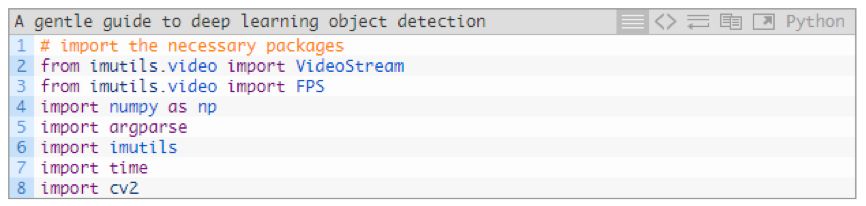
在 2~8 行中,我們導入了必須的附加包和模塊,特別是 imutils 和 OpenCV 。我將會用 VideoStream 類來處理從攝像頭捕獲的幀圖像。
我們配備了必須的工具,然后繼續解析命令行參數:
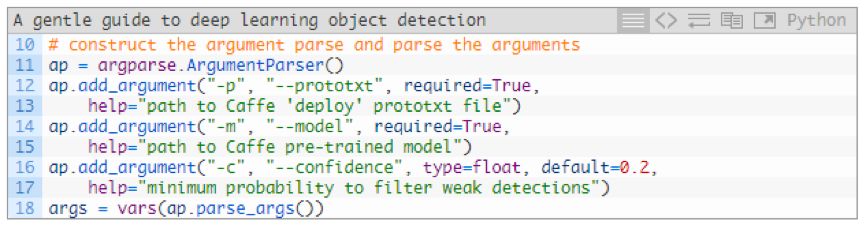
在運行時,我們的腳本需要兩個命令行參數:
--prototxt:Caffe原型文件的路徑,這個明確了模型定義;
--model:我們的CNN模型的權重文件路徑。
.
或者,你可以指定--confidence,過濾弱檢測器的閾值。
我們的模型能夠預測 21 個目標類別:

CLASSES 列表中包括了網絡訓練的所有類別( COCO 數據集中的標簽)
關于 CLASSES 列表常見的困惑是:
1.在列表中添加新的類別;
2.或者,從列表中刪除類別。
并能自動的讓網絡“知道”你正在努力完成什么任務。
事實并非如此。
你不能通過對文本標簽簡單的修改,從而使網絡通過自動修正后再去學習、添加和刪除未經過訓練的數據模式。神經網絡不是這樣工作的。
這里有一個快速的竅門,你可以用來過濾和忽略你不感興趣的預測標簽。
解決方案是:
1.定義 IGNORE 標簽的集合(用于訓練網絡的標簽列表,你想要過濾和忽略的列表);
2.對輸入的圖像和視頻幀圖片進行預測;
3.忽略任何包含在 IGNORE 集合中類標簽的預測。
在 Python 中運行,IGNORE 集合如下:

在這里,我們將會忽略所有標簽為“人”的預測目標(用于過濾的if語句稍后講解)。
在集合中,添加附加的元素(CLASSES 列表中的類標簽)是很容易的。
接下來,我們將生成隨機標簽和邊框顏色,加載我們的模型,并開始 VideoStream:
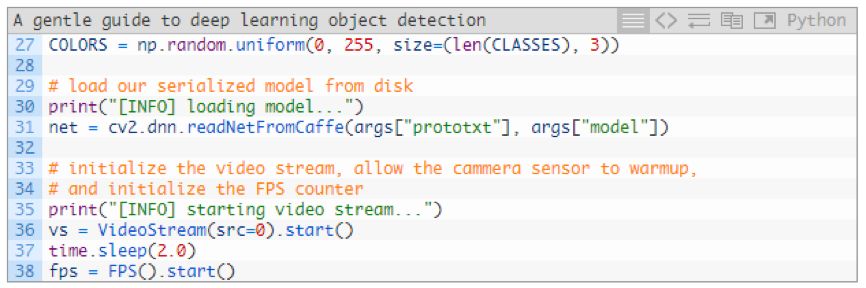
在第 27 行,生成的 COLORS 的隨機數組,被用于對應 21 個 CLASSES。我們將會用這些顏色進行后續的展示。
在 31 行,我們使用 cv2.dnn.readNetFromCaffe 函數和我們所需的兩個命令行參數作為參數傳遞加載了的 Caffe 模型。
然后,我們將 VideoStream 目標實例化為 vs,并開始我們的 fps 計數(第 36~38 行)。2 秒的休眠讓我們的攝像機有足夠的時間準備。
此時,我們準備好了接收來自攝像機的循環輸入幀圖像,并將這些圖像輸入到 CNN 目標檢測模型中:
在第 44 行,我們讀取圖像并調整圖片大小,同時保留顯示的縱橫比(第 45 行)。
在這里,由于后期需要,我們提取了高度和寬度值。
第 48 和 49 行,從幀圖像中生成了 blob。
接下來,我們將 blob 輸入到神經 net 中,用于目標檢測。(第 54 和 55 行)
讓我們來循環遍歷檢測模型:
在 58 行,我們將開始檢測器的循環。
在每次檢測中,我們提取了 confidence(61 行),將它與我們的置信度閾值對比(第 65 行)。
如果我們的 confidence 大于最小值(默認值是 0.2,能夠通過命令行參數修改)這個檢測結果將會被視為正檢測結果,有效的檢測并繼續進一步的處理。
首先,我們提取從檢測模型中提取了類標簽的索引(第 68 行)。
然后,回顧 Ezekiel 的第一個問題,我們可以忽略在 IGNORE 集合中的列表,在 72 和 73 行。如果這是屬于被忽略的類別,我們將簡單的繼續回到檢測模型的初始循環階段(我們并不展示這個類別的標簽或邊框)。這實現了“快速破解”解決方案。
否則,我們我們在白名單中檢測到目標時,我們需要在幀圖片中顯示這個目標的類標簽和矩形框:
在這個代碼模塊中,我們提取邊框坐標(第 77 和 78 行),然后,在幀圖片上繪制了類標簽和矩形框(第 81~87 行)。
同一個類中標簽的顏色和矩形框相同,相同類別中的目標將使用相同的顏色(也就是,視頻中的“船”,都將使用相同顏色標簽和邊框)
最后,仍然在 while 循環中,我們將在屏幕上展示我們努力工作的結果:
在第 90 和 91 行中,我們顯示了幀圖片,并捕獲按鍵輸入。
如果按下“q”鍵,我們停止并推出循環(第 94 和 95 行)
否則,我們繼續更新 fps 計數器(98 行),并繼續提取和處理幀圖片。
在剩下的代碼行中,當循環停止時,我們將顯示時間和每秒幀數量度,并清除。
▌運行你的深度學習目標檢測模型
運行腳本,打開終端并進入到代碼和模型目錄,從那里運行接下來的命令:

圖6:使用相同的模型進行實時深度學習目標檢測演示,在右邊的視頻中,我編程忽略了特定的目標類別。
在上面的 GIF 中,從左側你可以看到“人”類別被檢測,這是由于我的 IGNORE 集合是空的。在右側,你會發現我沒有被檢測到,這是因為將 “person” 類添加到 IGNORE 集合。
雖然我們的深度學習目標檢測器從技術上仍然檢測“人”的類別,但我們后期處理代碼能夠將這個類別過濾掉。
在運行深度學習目標檢測模型時你遇到了錯誤?
排除錯誤的第一步是檢查你是否連接了攝像頭。如果不是這個問題,也許你會在終端中看到以下錯誤信息:

如果你看到這個信息,那么是你沒有將“命令行參數”傳遞到程序中。如果 PyImageSearch 讀者對 Python、argparse 和命令行參數不熟悉,這將是他們普遍會遇到的問題。
▌我如何在深度學習目標檢測模型中添加和移除類?
圖 7:深度學習目標檢測模型的微調和遷移學習
正如我在本篇指南中提到的,你不能簡單的修改 CLASSES 列表來進行類標簽的添加和刪除,底層網絡本身并沒有發生變化。
你所做的,充其量只是修改一個類標簽的文本文件。
反之,如果你想從神經網絡中添加或刪除類,你需要:
1.重新訓練;
2.進行微調。
重新訓練往往是耗時、成本高的操作,所以,我們盡可能的避免重新訓練,但在某些情況下,從頭開始訓練是無法避免的。
另一種方式是對網絡進行微調。
微調是遷移學習的一種形式,微調可以通過以下的過程來完成:
1.將用于分類和標記的全連接層移除;
2.將其替換成全新的、隨機初始化的全連接層。
我們也可以修改網絡中的其他層(包括凍結某些層的權重,在訓練過程中再解凍它們)。
具體如何訓練你自定義的深度學習目標檢測模型(包括微調和重新訓練),本文不涉及這樣的高級主題,但是,可以參考以下部分來幫助你入門。
▌總結
在今天的博客中,我大致介紹了涉及深度學習目標檢測的復雜問題。我們首先回顧了圖像分類和目標檢測的本質區別,包括我們如何將圖像分類訓練的網絡用于目標檢測。
然后,我們回顧了深度學習目標檢測的核心部分:
框架
基礎模型
基礎模型通常是預先訓練好的網絡(分類器),通常是在大型圖像數據集中完成訓練的,比如 ImageNet ,為的是讓網絡去學習魯棒性的判別過濾器集合。
我們也可以重新訓練基礎網絡,不過這通常需要訓練很長的時間,目標檢測模型才能達到合理的精度。
在大多數情況下,你應該從預先訓練好的基礎模型入手,而不是重新訓練。
一旦我們深入了解深度學習目標檢測模型之后,我們就可以在 OpenCV 中在運行實時目標檢測模型。
我還演示了怎樣做才能過濾或忽略你不感興趣的類標簽。
最后我們了解到,從深度學習目標檢測模型中添加或刪減類并不像從硬編碼中的類標簽列表中添加或刪減類標簽那么容易。
神經網絡本身并不關心你是否修改了類標簽列表,相反,你將需要:
修改網絡結構本身,移除全連接的類預測層,并進行微調;
或者重新訓練目標檢測框架。
對于大多數深度學習目標檢測項目,你將從預先已在目標檢測任務(如 COCO )中訓練完成的深度學習目標檢測模型開始,然后,通過對模型進行微調獲取你自己的檢測模型。
-
神經網絡
+關注
關注
42文章
4811瀏覽量
103018 -
深度學習
+關注
關注
73文章
5557瀏覽量
122576
原文標題:深度學習目標檢測指南:如何過濾不感興趣的分類及添加新分類?
文章出處:【微信號:AI_Thinker,微信公眾號:人工智能頭條】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄





 工商網監
工商網監
評論