 一種基于深度學習的系統教會機器人僅通過觀察人類行為就能完成任務
一種基于深度學習的系統教會機器人僅通過觀察人類行為就能完成任務
近日,NVIDIA研究團隊率先開發出了一種基于深度學習的系統,該系統可教會機器人僅通過觀察人類行為就能夠完成任務。該方法旨在增強人類與機器人之間的溝通,同時推進人類與機器人無縫協同工作的研究進程。
在其論文中,研究人員表示:“為了讓機器人在現實世界中執行有用的任務,必須簡單地將任務傳達給機器人;這包括預期結果以及任何與實現該結果的最佳方法有關的提示。借助演示,用戶可以向機器人傳達任務,并提供線索,以幫助機器人更好地完成任務。”
通過NVIDIA TITAN X GPU,研究人員訓練了一系列神經網絡,用于執行與感知、程序生成及程序執行相關的任務。結果顯示,機器人能夠通過現實世界內的單次演示而學習任務。
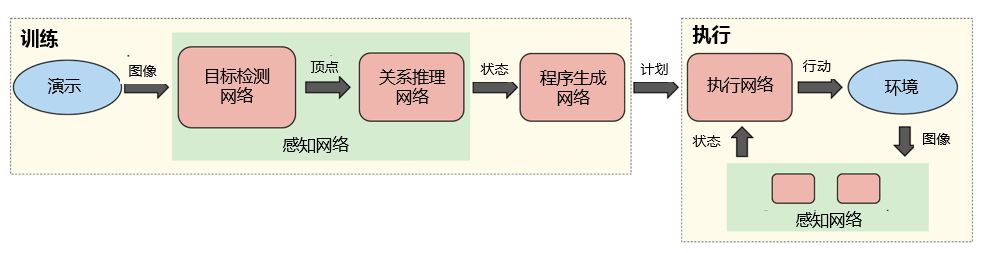
該方法的工作方式具體為:
通過攝像頭來獲取某場景的實時視頻流,隨后由一對神經網絡實時推理該場景內目標的位置與關系。
由此生成的感知被傳輸到另一個網絡,并生成用于解釋如何重建這些感知的計劃。
最后,執行網絡讀取該計劃,并為機器人生成動作;同時會考慮到當前場景的狀態,以確保應對外部干擾的穩健性。
機器人看到任務后,即生成人類可讀的步驟描述,這是重新執行任務所必需的環節。該描述能夠讓用戶在機器人執行之前快速辨別并糾正機器人對人類演示解讀所出現的任何問題。
獲得此項能力的關鍵在于充分利用合成數據來訓練神經網絡。現有的神經網絡訓練方法需要大量帶有標記的訓練數據,對這些系統而言是一個瓶頸。通過合成數據生成,可以輕松地生成幾乎無限量的標記訓練數據。
這也是第一次將以圖像為中心的域隨機化 (image-centric domain randomization)方法用于機器人。域隨機化技術用于生成具有大量多樣性的合成數據,并誘使感知網絡相信所看到的真實數據只是其訓練數據的另一種變體。研究人員選擇以圖像為中心的方式來處理數據,以確保網絡不依賴于攝像頭或環境。
研究人員表示:“這種感知網絡適用于任何固態的現實世界物體,它們可以通過其3D邊界立方體(bounding cuboid)來進行合理模擬。盡管在訓練期間從未觀察到真實圖像,但即使在被嚴重遮擋的情況下,感知網絡仍能可靠地檢測到真實圖像內的目標邊界立方體。”
在其演示中,該團隊使用多個彩色方塊和一輛玩具車來訓練目標檢測器。該系統學會了方塊之間的物理關系,比如方塊堆疊在一起,或者是相鄰放置。
在上述演示視頻中,人類操作員向機器人展示了一組立方體。隨后該系統對其程序進行了推理,并按照正確的順序將立方體放置好。由于其在執行過程中考慮到了當前的狀態,因此該系統能夠實時從錯誤中恢復過來。
本周,在澳大利亞布里斯班舉辦的世界機器人與自動化大會(ICRA)上,研究人員將展示其研究論文與成果。
該團隊表示將繼續探索合成訓練數據在機器人操控領域內的應用,并研究出將該方法應用于更多場景的能力。
-
機器人
+關注
關注
213文章
29568瀏覽量
211961 -
NVIDIA
+關注
關注
14文章
5274瀏覽量
105941 -
深度學習
+關注
關注
73文章
5557瀏覽量
122583
原文標題:NVIDIA最新研究成果出爐!機器人僅通過觀察人類行為就能完成任務
文章出處:【微信號:NVIDIA_China,微信公眾號:NVIDIA英偉達】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄





 工商網監
工商網監
評論