") 一種新穎的基于強化學習的圖像復(fù)原算法—RL-Restore
一種新穎的基于強化學習的圖像復(fù)原算法—RL-Restore

簡介
在底層視覺算法領(lǐng)域,卷積神經(jīng)網(wǎng)絡(luò)(CNN)近年取得了巨大的進展,在諸如去模糊、去噪、去JPEG失真、超分辨率等圖像復(fù)原任務(wù)上已經(jīng)達到了優(yōu)異的性能。但是現(xiàn)實圖像中的失真往往更加復(fù)雜,例如,經(jīng)過多個圖像降質(zhì)過程后,圖像可能包含模糊、噪聲、JPEG壓縮的混合失真。這類混合失真圖像對目前的圖像復(fù)原算法仍然充滿挑戰(zhàn)性。
近期的一些圖像復(fù)原工作(如VDSR、DnCNN等)證實了一個CNN網(wǎng)絡(luò)可以處理多種失真類型或不同失真程度的降質(zhì)圖像,這為解決混合失真問題提供了新的思路。但是,這類算法均選用了復(fù)雜度較高的網(wǎng)絡(luò)模型,帶來了較大的計算開銷。另外,這些算法的網(wǎng)絡(luò)均使用同一結(jié)構(gòu)處理所有圖像,未考慮一些降質(zhì)程度較低的圖像可以使用更小的網(wǎng)絡(luò)進行復(fù)原。
針對現(xiàn)有圖像復(fù)原CNN算法模型復(fù)雜,計算復(fù)雜度高的問題,本文提出的RL-Restore算法彌補了這些不足,以更加高效靈活的方式解決了復(fù)雜的圖像復(fù)原問題。
RL-Restore算法的設(shè)計思想與挑戰(zhàn)
當前流行的圖像復(fù)原理念認為解決復(fù)雜的圖像復(fù)原問題需要一個大型的CNN,而本文提出了一種全新的解決方案,即使用多個小型CNN專家以協(xié)作的方式解決困難的真實圖像復(fù)原任務(wù)。RL-Restore算法的主要思路是設(shè)計一系列基于小型CNN的復(fù)原工具,并根據(jù)訓練數(shù)據(jù)學習如何恰當?shù)亟M合使用它們。這是因為現(xiàn)實圖像或多或少受到多種失真的影響,針對復(fù)雜失真的圖像學習混合使用不同的小型CNN能夠有效的解決現(xiàn)實圖像的復(fù)原問題。不僅如此,因為該算法可以根據(jù)不同的失真程度選取不同大小的工具,相較于現(xiàn)有CNN模型,這一新方法使用的參數(shù)更少,計算復(fù)雜度更低。
RL-Restore算法的目標是對一張失真圖像有針對性地選擇一個工具鏈(即一系列小型CNN工具)進行復(fù)原,因而其該算法包含了兩個基本組件:
一個包含多種圖像復(fù)原小型CNN的工具箱;
一個可以在每一步?jīng)Q定使用何種復(fù)原工具的強化學習算法。
本文提出的工具箱中包含了12個針對不同降質(zhì)類型的CNN(如表1所示)。每一種工具解決一種特定程度的高斯模糊、高斯噪聲、JPEG失真,這些失真在圖像復(fù)原領(lǐng)域中最為常見。針對輕微程度失真的復(fù)原工具CNN僅有3層,而針對嚴重程度失真的工具達到8層。為了增強復(fù)原工具的魯棒性,本文在所有工具的訓練數(shù)據(jù)中均加入了輕微的高斯噪聲及JPEG失真。
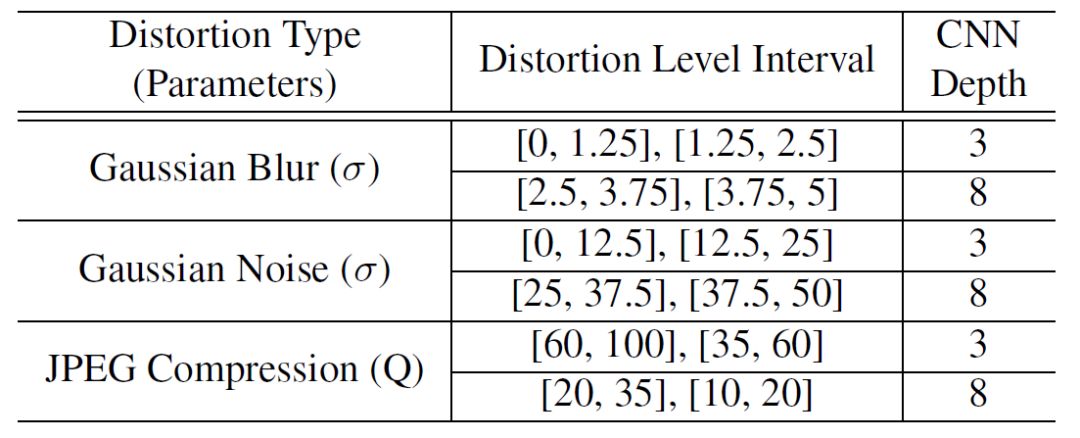
表1:
工具箱中的圖像復(fù)原工具

圖1:
不同圖像復(fù)原的工具鏈對最終結(jié)果產(chǎn)生不同影響
(c, d) 適用于這兩張失真圖像的CNN工具鏈
(b, e) 改變工具使用順序的圖像復(fù)原結(jié)果
(a, f) 改變工具強度的圖像復(fù)原結(jié)果
有了工具箱,如何選擇工具成為本文解決的主要挑戰(zhàn)之一。圖1展示了不同工具鏈的圖像復(fù)原結(jié)果,可以看到對工具鏈的微小調(diào)整可能導(dǎo)致復(fù)原結(jié)果的劇烈變化。本文解決的第二個挑戰(zhàn)在于,沒有一個已有的工具可以恰當?shù)奶幚怼爸虚g結(jié)果”。例如,去模糊的工具可能也會放大噪聲,導(dǎo)致后面已有的去噪工具無法有效處理新引入的未知失真。針對這些挑戰(zhàn),本文使用強化學習算法訓練得到有效的工具選擇策略,同時還提出聯(lián)合訓練算法對所有工具進行端到端的訓練以解決有效復(fù)原“中間結(jié)果”的挑戰(zhàn)。
基于強化學習的普適圖像復(fù)原
RL-Restore算法的框架(如圖2所示)。對于一張輸入圖像,agent首先從工具箱中選擇一個工具對它進行恢復(fù)。然后agent根據(jù)當前的狀態(tài)(包括復(fù)原中間結(jié)果和之前工具的選擇)來選取下一個動作(使用復(fù)原工具或停止),直到算法決定終止復(fù)原過程。

圖2:
RL-Restore算法框架,虛線框內(nèi)為Agent結(jié)構(gòu)
動作(action):在每一個復(fù)原步驟 t,算法會輸出一個估值向量vt選擇一個動作at。除了停止動作以外,其余每一個動作均代表使用某個復(fù)原工具。在本文中,工具箱內(nèi)共包含12個工具,因而算法總共包含13個動作。
狀態(tài)(state):狀態(tài)是算法可以觀測到的信息,在步驟t的狀態(tài)記為St={It,v ?t},其中It是當前步驟的輸入圖像,v ?t=vt-1是前一步驟的動作估值向量,包含了前一步驟的決策信息。
回報(reward):在強化學習中,算法的學習目標是最大化所有步驟的累積回報,因而回報是驅(qū)動算法學習的關(guān)鍵。本文希望確保圖像質(zhì)量在每一步驟都得到提升,因此設(shè)計了一個逐步的回報函數(shù)rt=Pt+1-Pt,其中Pt+1和Pt分別代表步驟t的輸入圖像和輸出圖像的PSNR,度量每個步驟中圖像PSNR的變化。
結(jié)構(gòu):虛線框內(nèi)的agent包含了三個模塊(如圖2所示):
特征提取器(Feature Extractor),包含了4個卷積層和1個全連接層,將輸入圖像轉(zhuǎn)化為32維特征向量;
One-hot編碼器(One-hot Encoder),其輸入是前一步驟的動作估值向量,輸出將其轉(zhuǎn)換為對應(yīng)的特征向量;
LSTM,其以前兩個模塊輸出作為輸入,這個模塊不僅觀測當前步驟的狀態(tài)特征,還存儲了歷史狀態(tài)的信息,該模塊最后輸出當前步驟的估值向量,用于復(fù)原工具的選取。
訓練:每一個復(fù)原工具的訓練均使用MSE損失函數(shù),而agent的訓練則使用deep Q-learning算法。由于LSTM具有記憶性,每一個訓練樣本均包含一條完整的工具鏈。
聯(lián)合訓練算法
至此,RL-Restore算法已經(jīng)擁有了較好的工具選取策略,還需要解決對“中間結(jié)果”進行復(fù)原的挑戰(zhàn)。前文已經(jīng)提到,由于前面的復(fù)原步驟可能引入新的未知失真,沒有一個已有工具能對這類復(fù)雜的“中間結(jié)果”進行有效處理。因此,本文提出了聯(lián)合訓練算法,將所有的工具以及工具的選擇進行端到端地訓練,從而解決“中間結(jié)果”的復(fù)原問題。具體而言,對于每一張輸入圖像,先通過所選取的工具鏈前向傳播得到最后的復(fù)原圖像,通過與清晰參考圖像對比得到MSE損失,然后通過工具鏈對誤差進行反向傳播,根據(jù)平均的梯度值更新工具網(wǎng)絡(luò)的參數(shù)。

算法1:
聯(lián)合訓練算法
實驗結(jié)果
本文使用DIV2K訓練集的前750張圖像用于訓練,后50張圖像用于測試。通過摳取分辨率為63x63的子圖像,共得到25萬張訓練圖像和3,584張測試圖像。本文在每一張圖像上隨機加上不同程度的高斯模糊、高斯噪聲和JPEG壓縮。算法在訓練樣本中排除一些極度輕微或嚴重的失真,使用中度失真的圖像進行訓練(如圖3所示),而在輕度、中度和重度失真的圖像上進行測試。

圖3:
不同程度的失真圖像
本文與現(xiàn)有的VDSR和DnCNN圖像復(fù)原算法相比,模型復(fù)雜度更低而復(fù)原性能更加優(yōu)異(如表2、3所示)。其中VDSR-s是與VDSR結(jié)構(gòu)相似的小參數(shù)模型,其參數(shù)量與RL-Restore算法相當。表2展示了RL-Restore算法具有最小的參數(shù)量和計算復(fù)雜度,表3展示了RL-Restore算法與VDSR和DnCNN等大模型在輕度和中度失真測試集上具有類似的性能,而在重度失真測試集上則表現(xiàn)得更加優(yōu)異。在參數(shù)量相當?shù)那闆r下,RL-Restore算法在各個測試集上均比VDSR-s算法擁有更加優(yōu)異的復(fù)原性能。圖4展示了不同算法和本文算法在不同步驟復(fù)原結(jié)果的對比。

表2:
模型復(fù)雜度對比

表3:
復(fù)原結(jié)果對比

圖4:
可視化復(fù)原結(jié)果對比
本文也使用實際場景圖像對RL-Restore算法進行了進一步測試。如圖5所示,測試圖像由智能手機采集,其中包含了模糊、噪聲和壓縮等失真,直接使用訓練好的RL-Restore和VDSR模型在這些真實場景圖像進行測試。由結(jié)果可以看到,RL-Restore算法取得了明顯更加優(yōu)異的復(fù)原結(jié)果,圖5(a, c) 展示了RL-Restore算法成功修復(fù)由曝光噪聲和壓縮帶來的嚴重失真;圖5(b, d, e) 展示了本文方法可以有效地處理混合的模糊與噪聲。

圖5:
RL-Restore算法對實際場景圖像的復(fù)原結(jié)果
結(jié)論
本文提出了一種新穎的基于強化學習的圖像復(fù)原算法—RL-Restore。與現(xiàn)有的深度學習方法不同,RL-Restore算法通過學習動態(tài)地選取工具鏈從而對帶有復(fù)雜混合失真的圖像進行高效的逐步復(fù)原。基于合成數(shù)據(jù)與現(xiàn)實數(shù)據(jù)的大量實驗結(jié)果證實了該算法的有效性和魯棒性。由于算法框架的靈活性,通過設(shè)計不同的工具箱和回報函數(shù),RL-Restore算法為解決其他富有挑戰(zhàn)性的底層視覺問題也提供了新穎的解決思路。
-
神經(jīng)網(wǎng)絡(luò)
+關(guān)注
關(guān)注
42文章
4814瀏覽量
103506 -
圖像
+關(guān)注
關(guān)注
2文章
1094瀏覽量
41221 -
cnn
+關(guān)注
關(guān)注
3文章
354瀏覽量
22727
原文標題:CVPR 2018 | 商湯科技Spotlight論文詳解:RL-Restore普適圖像復(fù)原算法
文章出處:【微信號:SenseTime2017,微信公眾號:商湯科技SenseTime】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
深度強化學習實戰(zhàn)
一種張量總變分的模糊圖像盲復(fù)原算法
一種新型的強化學習算法,能夠教導(dǎo)算法如何在沒有人類協(xié)助的情況下解開魔方
基于強化學習的MADDPG算法原理及實現(xiàn)
深度強化學習的概念和工作原理的詳細資料說明
深度強化學習到底是什么?它的工作原理是怎么樣的
機器學習中的無模型強化學習算法及研究綜述

強化學習的基礎(chǔ)知識和6種基本算法解釋
徹底改變算法交易:強化學習的力量
強化學習的基礎(chǔ)知識和6種基本算法解釋






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論