 IO請求在block layer的來龍去脈
IO請求在block layer的來龍去脈

所謂請求合并就是將進程內或者進程間產生的在物理地址上連續的多個IO請求合并成單個IO請求一并處理,從而提升IO請求的處理效率。在前面有關通用塊層介紹的系列文章當中我們或多或少地提及了IO請求合并的概念,本篇我們從頭集中梳理IO請求在block layer的來龍去脈,以此來增強對IO請求合并的理解。首先來看一張圖,下面的圖展示了IO請求數據由用戶進程產生,到最終持久化存儲到物理存儲介質,其間在內核空間所經歷的數據流以及IO請求合并可能的觸發點。
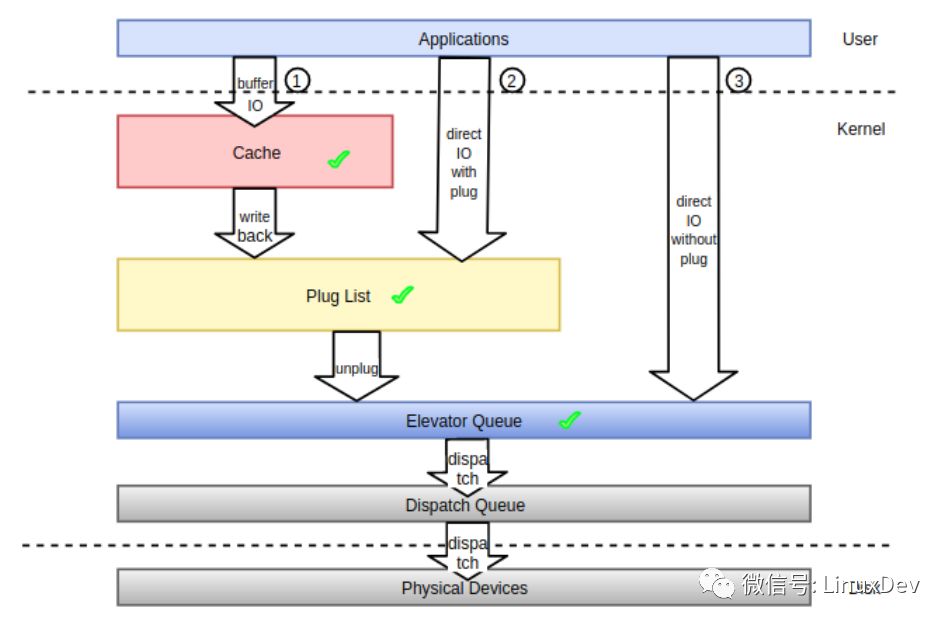
從內核的角度而言,進程產生的IO路徑主要有圖中①②③所示的三條:
①緩存IO, 對應圖中的路徑①,系統中絕大部分IO走的這種形式,充分利用filesystem 層的page cache所帶來的優勢, 應用程序產生的IO經系統調用落入page cache之后便可以直接返回,page cache中的緩存數據由內核回寫線程在適當時機負責同步到底層的存儲介質之上,當然應用程序也可以主動發起回寫過程(如fsync系統調用)來確保數據盡快同步到存儲介質上,從而避免系統崩潰或者掉電帶來的數據不一致性。緩存IO可以帶來很多好處,首先應用程序將IO丟給page cache之后就直接返回了,避免了每次IO都將整個IO協議棧走一遍,從而減少了IO的延遲。其次,page cache中的緩存最后以頁或塊為單位進行回寫,并非應用程序向page cache中提交了幾次IO, 回寫的時候就需要往通用塊層提交幾次IO, 這樣在提交時間上不連續但在空間上連續的小塊IO請求就可以合并到同一個緩存頁中一并處理。再次,如果應用程序之前產生的IO已經在page cache中,后續又產生了相同的IO,那么只需要將后到的IO覆蓋page cache中的舊IO,這樣一來如果應用程序頻繁的操作文件的同一個位置,我們只需要向底層存儲設備提交最后一次IO就可以了。最后,應用程序寫入到page cache中的緩存數據可以為后續的讀操作服務,讀取數據的時候先搜索page cache,如果命中了則直接返回,如果沒命中則從底層讀取并保存到page cache中,下次再讀的時候便可以從page cache中命中。
②非緩存IO(帶蓄流),對應圖中的路徑②,這種IO繞過文件系統層的cache。用戶在打開要讀寫的文件的時候需要加上“O_DIRECT”標志,意為直接IO,不讓文件系統的page cache介入。從用戶角度而言,應用程序能直接控制的IO形式除了上面提到的“緩存IO”,剩下的IO都走的這種形式,就算文件打開時加上了 ”O_SYNC” 標志,最終產生的IO也會進入蓄流鏈表(圖中的Plug List)。如果應用程序在用戶空間自己做了緩存,那么就可以使用這種IO方式,常見的如數據庫應用。
③非緩存IO(不帶蓄流),對應圖中的路徑③,內核通用塊層的蓄流機制只給內核空間提供了接口來控制IO請求是否蓄流,用戶空間進程沒有辦法控制提交的IO請求進入通用塊層的時候是否蓄流。嚴格的說用戶空間直接產生的IO都會走蓄流路徑,哪怕是IO的時候附上了“O_DIRECT” 和 ”O_SYNC”標志(可以參考《Linux通用塊層介紹(part1: bio層)》中的蓄流章節),用戶間接產生的IO,如文件系統日志數據、元數據,有的不會走蓄流路徑而是直接進入調度隊列盡快得到調度。注意一點,通用塊層的蓄流只提供機制和接口而不提供策略,至于需不需要蓄流、何時蓄流完全由內核中的IO派發者決定。
應用程序不管使用圖中哪條IO路徑,內核都會想方設法對IO進行合并。內核為促進這種合并,在IO協議棧上設置了三個最佳狙擊點:
lCache (頁高速緩存)
lPlug List (蓄流鏈表)
lElevator Queue (調度隊列)
cache 合并
IO處在文件系統層的page cache中時只有IO數據,還沒有IO請求(bio 或 request),只有page cache 在讀寫的時候才會產生IO請求。本文主要介紹IO請求在通用塊層的合并,因此對于IO 在cache 層的合并只做現象分析,不深入到內部邏輯和代碼細節。如果是緩存IO,用戶進程提交的寫數據會積聚在page cache 中。cache 保存IO數據的基本單位為page,大小一般為4K, 因此cache 又叫“頁高速緩存”, 用戶進程提交的小塊數據可以緩存到cache中的同一個page中,最后回寫線程將一個page中的數據一次性提交給通用塊層處理。以dd程序寫一個裸設備為例,每次寫1K數據,連續寫16次:
dd if=/dev/zero of=/dev/sdb bs=1k count=16
通過blktrace觀測的結果為:
blktrace -d /dev/sdb -o - | blkparse -i -
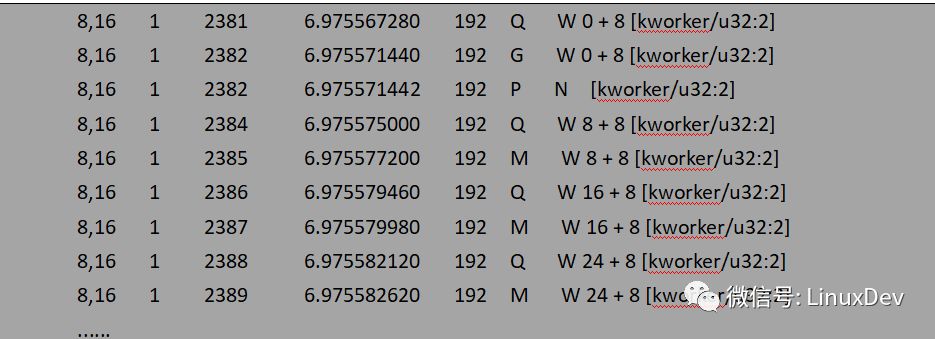
bio請求在通用塊層的處理情況主要是通過第六列反映出來的,如果對blkparse的輸出不太了解,可以 man 一下blktrace。對照每一行的輸出來看看應用程序產生的寫IO經由page cache之后是如何派發到通用塊層的:
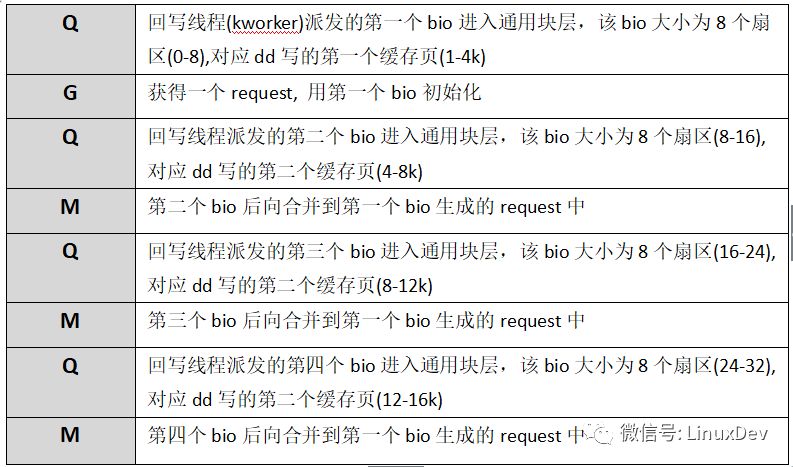
現階段只關注IO是如何從page cache中派發到通用塊層的,所以后面的瀉流、派發過程沒有貼出來。回寫線程–kworker以8個扇區(扇區大小為512B, 8個扇區為4K對應一個page大小)為單位將dd程序讀寫的1K數據塊派發給通用塊層處理。dd程序寫了16次,回寫線程只寫了4次(對應四次Q),page cache的緩存功能有效的合并了應用程序直接產生的IO數據。文件系統層的page cache對讀IO也有一定的作用,帶緩存的讀IO會觸發文件系統層的預讀機制,所謂預讀有專門的預讀算法,通過判斷用戶進程IO趨勢,提前將存儲介質上的數據塊讀入page cache中,下次讀操作來時可以直接從page cache中命中,而不需要每次都發起對塊設備的讀請求。還是以dd程序讀一個裸設備為例,每次讀1K數據,連續讀16次:
dd if=/dev/sdb of=/dev/zero bs=1K count=16
通過blktrace觀測的結果為:
blktrace -d /dev/sdb -o - | blkparse -i -
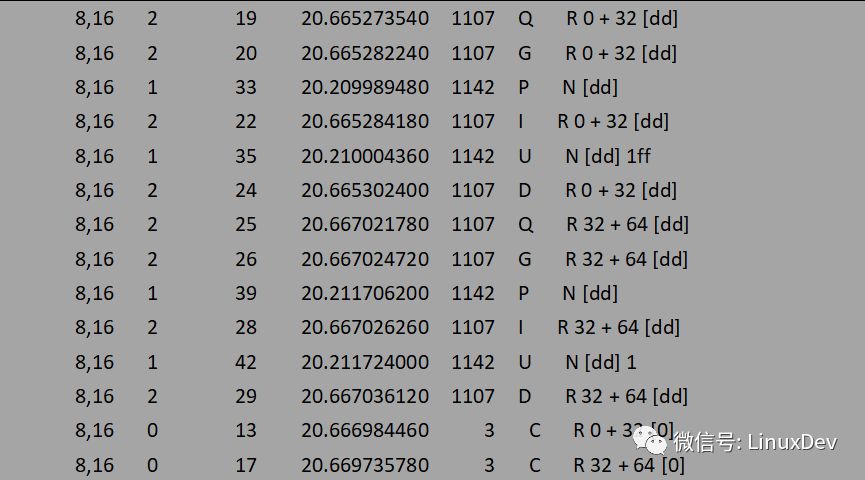
同樣只關注IO是如何從上層派發到通用塊層的,不關注IO在通用塊層的具體情況,先不考慮P,I,U,D,C等操作,那么上面的輸出可以簡單解析為:
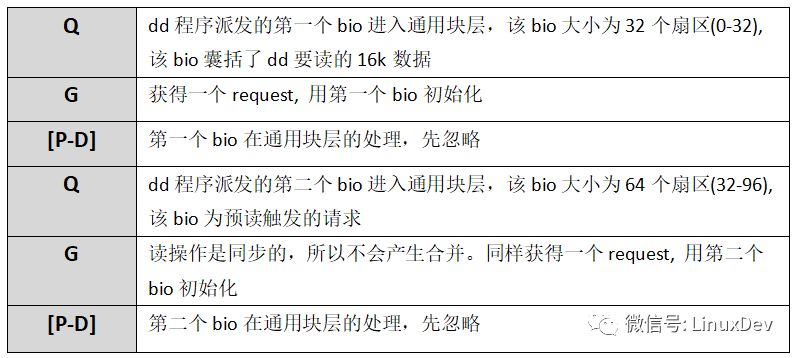
讀操作是同步的,所以觸發讀請求的是dd進程本身。dd進程發起了16次讀操作,總共讀取16K數據,但是預讀機制只向底層發送了兩次讀請求,分別為0+32(16K), 32+64(32K),總共預讀了16 + 32 = 48K數據,并保存到cache中,多預讀的數據可以為后續的讀操作服務。
plug 合并
在閱讀本節之前可以先回顧下linuxer公眾號中介紹bio和request的系列文章,熟悉IO請求在通用塊層的處理,以及蓄流(plug)機制的原理和接口。特別推薦宋寶華老師寫的《文件讀寫(BIO)波瀾壯闊的一生》,通俗易懂地介紹了一個文件io的生命周期。
每個進程都有一個私有的蓄流鏈表,進程在往通用塊層派發IO之前如果開啟了蓄流功能,那么IO請求在被發送給IO調度器之前都保存在蓄流鏈表中,直到泄流(unplug)的時候才批量交給調度器。蓄流的主要目的就是為了增加請求合并的機會,bio在進入蓄流鏈表之前會嘗試與蓄流鏈表中保存的request進行合并,使用的接口為blk_attempt_plug_merge(). 本文是基于內核4.17分析的,源碼來源于4.17-rc1。

代碼遍歷蓄流鏈表中的request,使用blk_try_merge找到一個能與bio合并的request并判斷合并類型,蓄流鏈表中的合并類型有三種:ELEVATOR_BACK_MERGE,ELEVATOR_FRONT_MERGE,ELEVATOR_DISCARD_MERGE。普通文件IO操作只會進行前兩種合并,第三種是丟棄操作的合并,不是普通的IO的合并,故不討論。
bio后向合并 (ELEVATOR_BACK_MERGE)
為了驗證IO請求在通用塊層的各種合并形式,準備了以下測試程序,該測試程序使用內核原生支持的異步IO引擎,可異步地向內核一次提交多個IO請求。為了減少page cache和文件系統的干擾,使用O_DIRECT的方式直接向裸設備派發IO。
iotc.c
...
/* dispatch 3 4k-size ios using the io_type specified by user */
#define NUM_EVENTS 3
#define ALIGN_SIZE 4096
#define WR_SIZE 4096
enum io_type {
SEQUENCE_IO,/* dispatch 3 ios: 0-4k(0+8), 4-8k(8+8), 8-12k(16+8) */
REVERSE_IO,/* dispatch 3 ios: 8-12k(16+8), 4-8k(8+8),0-4k(0+8) */
INTERLEAVE_IO, /* dispatch 3 ios: 8-12k(16+8), 0-4k(0+8),4-8k(8+8) */ ,
IO_TYPE_END
};
int io_units[IO_TYPE_END][NUM_EVENTS] = {
{0, 1, 2},/* corresponding to SEQUENCE_IO */
{2, 1, 0},/* corresponding to REVERSE_IO */
{2, 0, 1}/* corresponding to INTERLEAVE_IO */
};
char *io_opt = "srid:";/* acceptable options */
int main(int argc, char *argv[])
{
int fd;
io_context_t ctx;
struct timespec tms;
struct io_event events[NUM_EVENTS];
struct iocb iocbs[NUM_EVENTS],
*iocbp[NUM_EVENTS];
int i, io_flag = -1;;
void *buf;
bool hit = false;
char *dev = NULL, opt;
/* io_flag and dev got set according the options passedby user , don’t paste the code of parsing here to shrink space */
fd = open(dev, O_RDWR | __O_DIRECT);
/* we can dispatch 32 IOs at 1 systemcall */
ctx = 0;
io_setup(32, &ctx);
posix_memalign(&buf,ALIGN_SIZE,WR_SIZE);
/* prepare IO request according to io_type */
for (i = 0; i < NUM_EVENTS; iocbp[i] = iocbs + i, ++i)
io_prep_pwrite(&iocbs[i], fd, buf, WR_SIZE,io_units[io_flag][i] * WR_SIZE);
/* submit IOs using io_submit systemcall */
io_submit(ctx, NUM_EVENTS, iocbp);
/* get the IO result with a timeout of 1S*/
tms.tv_sec = 1;
tms.tv_nsec = 0;
io_getevents(ctx, 1, NUM_EVENTS, events, &tms);
return 0;
}
測試程序接收兩個參數,第一個為作用的設備,第二個為IO類型,定義了三種IO類型:SEQUENCE_IO(順序),REVERSE_IO(逆序),INTERLEAVE_IO(交替)分別用來驗證蓄流階段的bio后向合并、前向合并和泄流階段的request合并。為了減少篇幅,此處貼出的源碼刪除了選項解析和容錯處理,只保留主干,原版位于:https://github.com/liuzhengyuan/iotc。
為驗證bio在蓄流階段的后向合并,用上面的測試程序iotc順序派發三個寫io:
# ./iotc-d/dev/sdb-s
-d 指定作用的設備sdb, -s 指定IO方式為SEQUENCE_IO(順序),表示順序發起三個寫請求: bio0(0 + 8), bio1(8 + 8), bio2(16 + 8)。通過blktrace來觀察iotc派發的bio請求在通用塊層蓄流鏈表中的合并情況:
blktrace -d /dev/sdb -o - | blkparse -i -
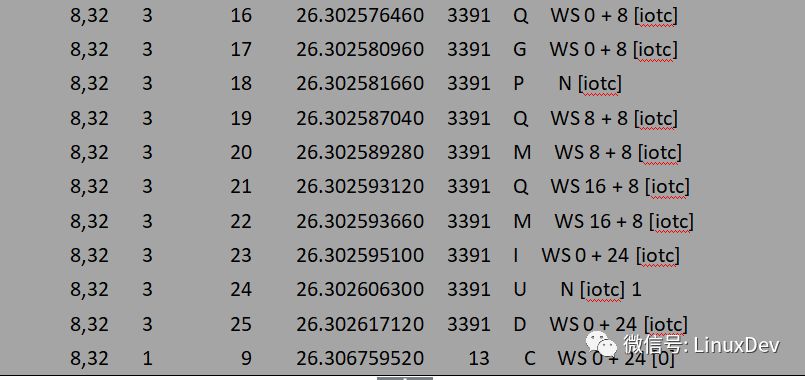
上面的輸出可以簡單解析為:

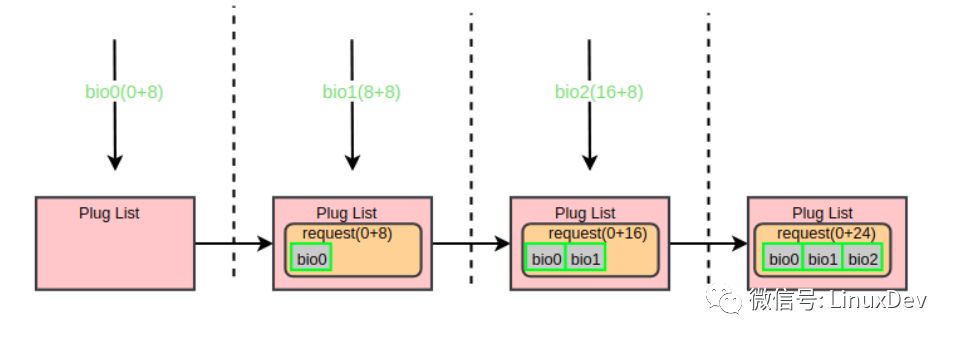
第一個bio(bio0)進入通用塊層時,此時蓄流鏈表為空,于是申請一個request并用bio0初始化,再將request添加進蓄流鏈表,同時告訴blktrace蓄流已正式工作。第二個bio(bio1)到來的時候會走blk_attempt_plug_merge的邏輯,嘗試調用bio_attempt_back_merge與蓄流鏈表中的request合并,發現正好能合并到第一個bio所在的request尾部,于是直接返回。第三個bio(bio2)的處理與第二個同理。通過蓄流合并之后,三個IO請求最終合并成了一個request(0 + 24)。用一副圖來展示整個合并過程:
bio前向合并 (ELEVATOR_FRONT_MERGE)
為驗證bio在蓄流階段的前向合并,使用iotc逆序派發三個寫io:
# ./iotc-d/dev/sdb-r
-r 指定IO方式為REVERSE_IO(逆序),表示逆序發起三個寫請求: bio0(16 + 8),bio1(8 + 8), bio2(0 + 8)。blktrace的觀察結果為:
blktrace -d /dev/sdb -o - | blkparse -i -
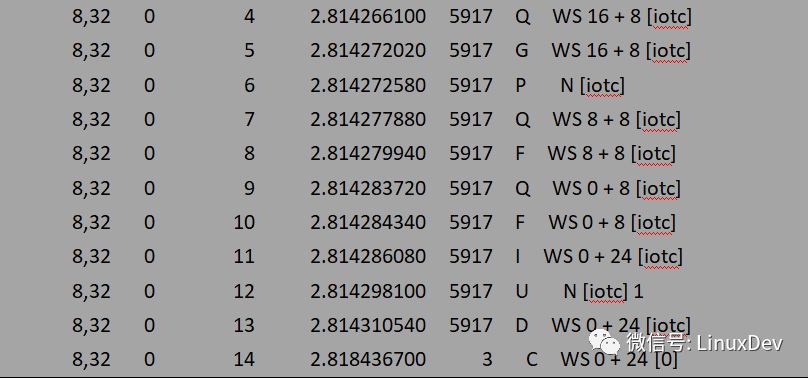
上面的輸出可以簡單解析為:

與前面的后向合并相比,唯一的區別是合并方式由之前的”M”變成了現在的”F”,即在blk_attempt_plug_merge中走的是bio_attempt_front_merge分支。通過下面的圖來展示前向合并過程:
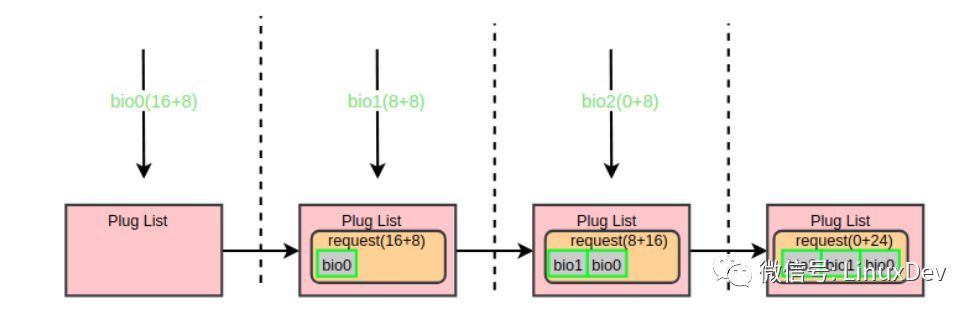
“plug 合并”不會做request與request的進階合并,蓄流鏈表中的request之間的合并會在泄流的時候做,即在下面介紹的“elevator 合并”中做。
elevator 合并
上面講到的蓄流鏈表合并是為進程內的IO請求服務的,每個進程只往自己的蓄流鏈表中提交IO請求,進程間的蓄流鏈表相互獨立,互不干涉。但是,多個進程可以同時對一個設備發起IO請求,那么通用塊層還需要提供一個節點,讓進程間的IO請求有機會進行合并。一個塊設備有且僅有一個請求隊列(調度隊列),所有對塊設備的IO請求都需要經過這個公共節點,因此調度隊列(Elevator Queue)是IO請求合并的另一個節點。先回顧一下通用塊層處理IO請求的核心函數:blk_queue_bio(), 上層派發的bio請求都會流經該函數,或將bio蓄流到Plug List,或將bio合并到Elevator Queue, 或將bio生成request直接插入到Elevator Queue。blk_queue_bio()的主要處理流程為:
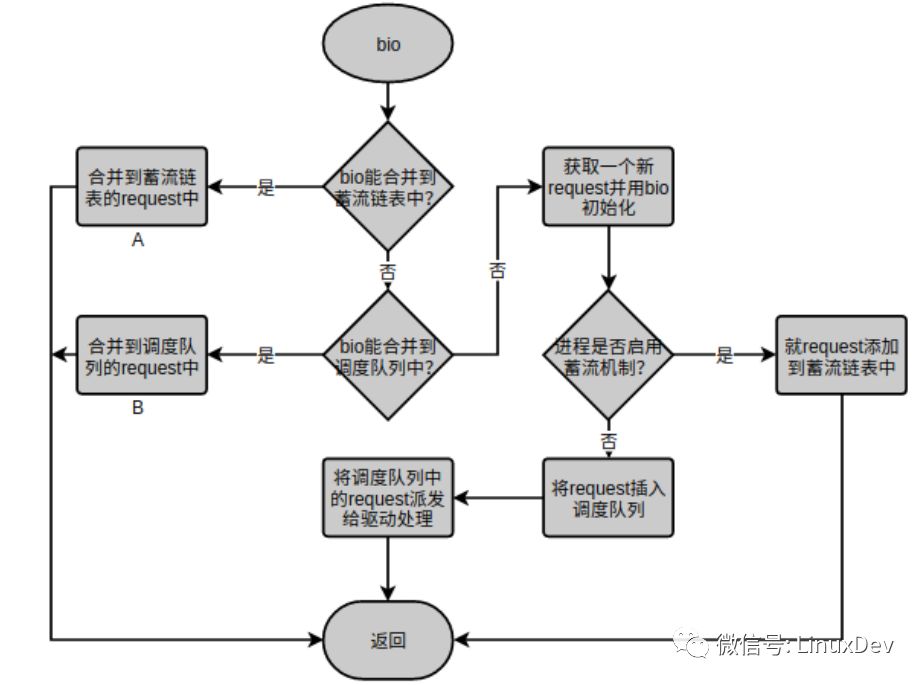
其中”A”標識的“合并到蓄流鏈表的request中”就是上一章介紹的“plug 合并”。bio如果不能合并到蓄流鏈表中接下來會嘗試合并到“B”標識的”合并到調度隊列的request中”。”合并到調度隊列的request中”只是“elevator 合并”的第一個點。你可能已經發現了blk_queue_bio()將bio合并到蓄流鏈表或者將request添加進蓄流鏈表之后就沒管了,從路徑①可以發現蓄流鏈表中的request最終都是要交給電梯調度隊列的,這正是”elevator 合并”的第二個點,關于泄流的時機請參考我之前寫的《Linux通用塊層介紹(part1: bio層)》。下面分別介紹這兩個合并點:
bio合并到elevator
先看B表示的代碼段:
blk_queue_bio:
switch (elv_merge(q, &req, bio)) {
case ELEVATOR_BACK_MERGE:
if (!bio_attempt_back_merge(q, req, bio))
break;
elv_bio_merged(q, req, bio);
free = attempt_back_merge(q, req);
if (free)
__blk_put_request(q, free);
else
elv_merged_request(q, req, ELEVATOR_BACK_MERGE);
goto out_unlock;
case ELEVATOR_FRONT_MERGE:
if (!bio_attempt_front_merge(q, req, bio))
break;
elv_bio_merged(q, req, bio);
free = attempt_front_merge(q, req);
if (free)
__blk_put_request(q, free);
else
elv_merged_request(q, req, ELEVATOR_FRONT_MERGE);
goto out_unlock;
default:
break;
}
合并邏輯基本與”plug 合并”相似,先調用elv_merge接口判斷合并類型,然后根據是后向合并或是前向合并分別調用bio_attempt_back_merge和bio_attempt_front_merge進行合并操作,由于操作對象從蓄流鏈表變成了電梯調度隊列,bio合并完了之后還需額外干幾件事:
1.調用elv_bio_merged, 該函數會調用電梯調度器注冊的elevator_bio_merged_fn接口來通知調度器做相應的處理,對于deadline調度器而言該接口為NULL。
2.尋找進階合并,參考我之前寫的《Linux通用塊層介紹(part2: request層)》中對進階合并的描述,如果bio產生了后向合并,則調用attempt_back_merge試圖進行后向進階合并,如果bio產生了前向合并,則調用attempt_front_merge企圖進行前向進階合并。deadline的進階合并接口為deadline_merged_requests, 被合并的request會從調度隊列中刪除。通過下面的圖示來展示后向進階合并過程,前向進階合并同理。
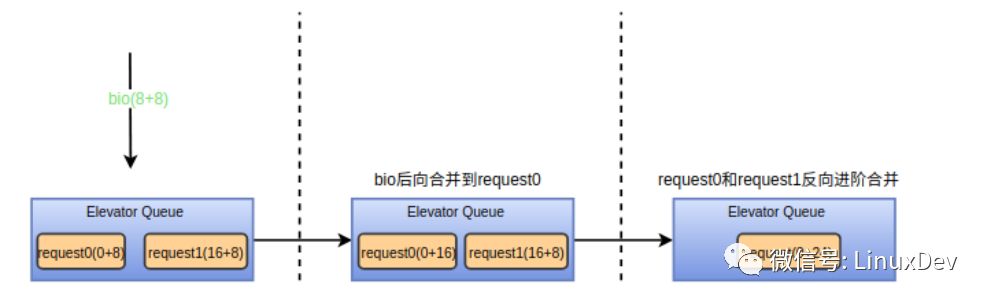
3.如果產生了進階合并,則被合并的request可以釋放了,參考上圖,可調用blk_put_request進行回收。如果只產生了bio合并,合并后的request的長度和扇區地址都會發生變化,需要調用elv_merged_request->elevator_merged_fn來更新合并后的請求在調度隊列的位置。deadline對應的接口為deadline_merged_request,其相應的操作為將合并的request先從調度隊列移出再重新插進去。
“bio合并到elevator”的合并形式只會發生在進程間,即只有一個進程在IO的時候不會產生這種合并形式,原因在于進程在向調度隊列派發IO請求或者試圖與將bio與調度隊列中的請求合并的時候是持有設備的隊列鎖得,其他進程是不能往調度隊列派發請求,這也是通用塊層單隊列通道窄需要發展多隊列的主要原因之一,只有進程在將調度隊列中的request逐個派發給驅動層的時候才會將設備隊列鎖重新打開,即只有當一個進程在將調度隊列中request派發給驅動的時候其他進程才有機會將bio合并到還未派發完的request中。所以想通過簡單的IO測試程序來捕捉這種形式的合并比較困難,這對兩個IO進程的IO產生時序有非常高的要求,故不演示。有興趣的可以參考上面的github倉庫,里面有patch對內核特定的請求派發位置加上延時來改變IO請求本來的時序,從而讓測試程序人為的達到這種碰撞效果。
request在泄流的時候合并到elevator
通用塊層的泄流接口為:blk_flush_plug_list(), 該接口主要的處理邏輯如下圖所示
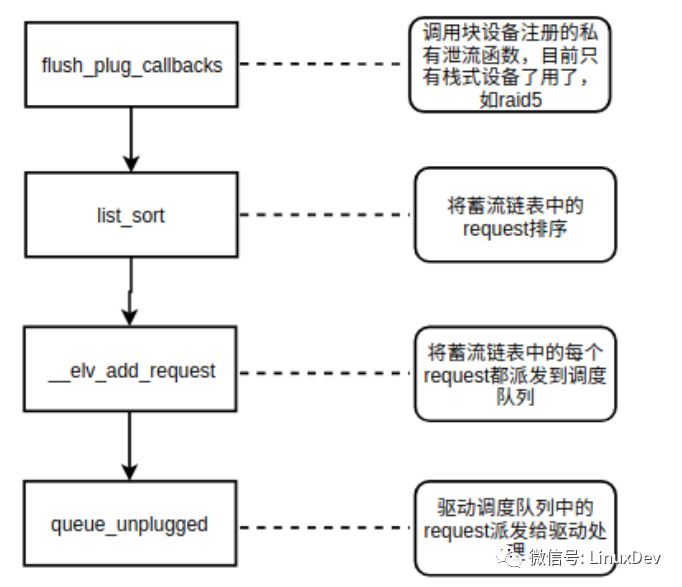
其中請求合并發生的點在__elv_add_request()。blk_flush_plug_list會遍歷蓄流鏈表中的每個request,然后將每個request通過 _elv_add_request接口添加到調度隊列中,添加的過程中會嘗試與調度隊列中已有的request進行合并。
__elv_add_request:
case ELEVATOR_INSERT_SORT_MERGE:
/*
* If we succeed in merging this request with one in the
* queue already, we are done - rq has now been freed,
* so no need to do anything further.
*/
if (elv_attempt_insert_merge(q, rq))
break;
/* fall through */
case ELEVATOR_INSERT_SORT:
BUG_ON(blk_rq_is_passthrough(rq));
rq->rq_flags |= RQF_SORTED;
q->nr_sorted++;
if (rq_mergeable(rq)) {
elv_rqhash_add(q, rq);
if (!q->last_merge)
q->last_merge = rq;
}
q->elevator->type->ops.sq.elevator_add_req_fn(q, rq);
break;
泄流時走的是ELEVATOR_INSERT_SORT_MERGE分支,正如注釋所說的先讓蓄流的request調用elv_attempt_insert_merge嘗試與調度隊列中的request合并,如果不能合并則落入到ELEVATOR_INSERT_SORT分支,該分支直接調用電梯調度器注冊的elevator_add_req_fn接口將新來的request插入到調度隊列合適的位置。其中elv_rqhash_add是將新加入到調度隊列的request做hash索引,這樣做的好處是加快從調度隊列尋找可合并的request的索引速度。在泄流的時候調度隊列中既有其他進程產生的request,也有當前進程從蓄流鏈表中派發的request(blk_flush_plug_list是先將所有request派發到調度隊列再一次性queue_unplugged,而不是派發一個request就queue_unplugged)。所以“request在泄流的時候合并到elevator”既是進程內的,也可以是進程間的。elv_attempt_insert_merge的實現只做request間的后向合并,即只會將一個request合并到調度隊列中的request的尾部。這對于單進程IO而言足夠了,因為blk_flush_plug_list在泄流的時候已經將蓄流鏈表中的request進行了list_sort(按扇區排序)。筆者曾經提交過促進進程間request的前向合并的patch(見github),但沒被接收,maintainer–Jens的解析是這種IO場景很難發生,如果產生這種IO場景基本是應用程序設計不合理。通過增加時間和空間來優化一個并不常見的場景并不可取。最后通過一個例子來驗證進程內“request在泄流的時候合并到elevator”,進程間的合并同樣對請求派發時序有很強的要求,在此不演示,github中有相應的測試patch和測試方法。iotc使用下面的方式派發三個寫io:
# ./iotc-d/dev/sdb-i
-i指定IO方式為INTERLEAVE_IO(交替),表示按扇區交替的方式發起三個寫請求: bio0(16 + 8),bio1(8 + 8), bio2(0 + 8)。blktrace的觀察結果為:
blktrace -d /dev/sdb -o - | blkparse -i -
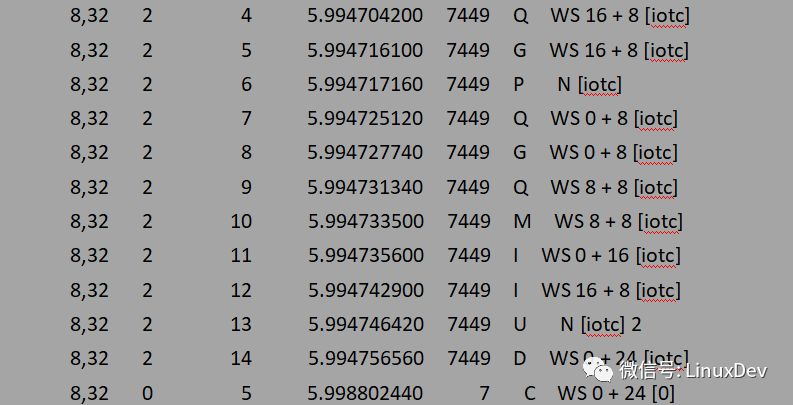
上面的輸出可以簡單解析為:

bio0(16 + 8)先到達plug list,bio1(0+8)到達時發現不能與plug list中的request合并,于是申請一個request添加到plug list。bio2(8+8)到達時首先與bio1進行后向合并。之后進程觸發泄流,泄流接口函數會將plug list中的request排序,因此request(0+16)先派發到調度隊列,此時調度隊列為空不能進行合并。然后派發request(16+8),派發時調用elv_attempt_insert_merge接口嘗試與調度隊列中的其他request進行合并,發現可以與request(0+16)進行后向合并,于是兩個request合并成一個,最后向設備驅動派發的只有一個request(0+24)。整個過程可以用下面的圖來展示:
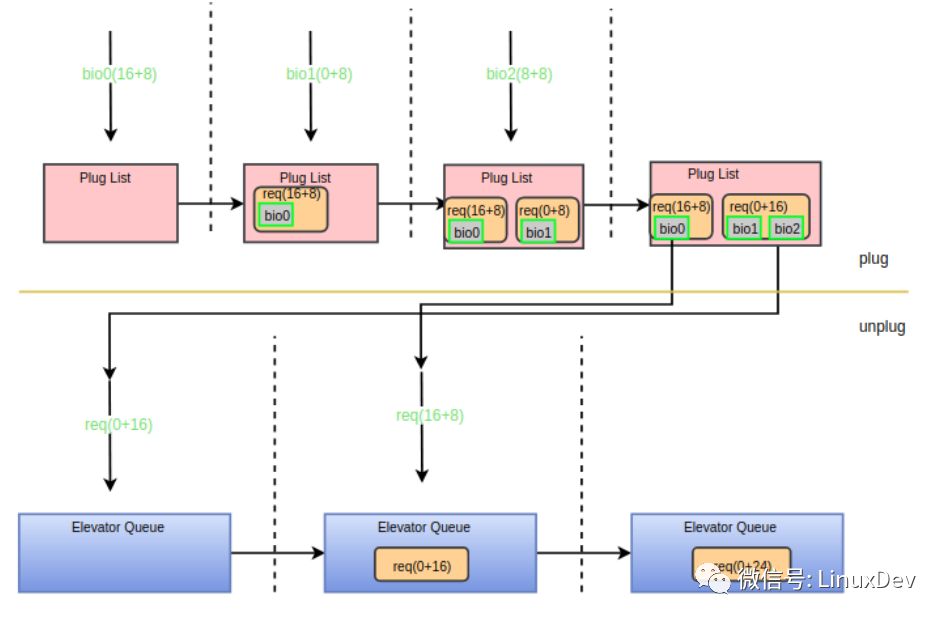
小結
通過cache 、plug和elevator自上而下的三層狙擊,應用程序產生的IO能最大限度的進行合并,從而提升IO帶寬,降低IO延遲,延長設備壽命。page cache打頭陣,既做數據緩存又做IO合并,主要是針對小塊IO進行合并,因為使用內存頁做緩存,所以合并后的最大IO單元為頁大小,當然對于大塊IO,page cache也會將它拆分成以頁為單位下發,這不影響最終的效果,因為后面還有plug 和 elevator補刀。plug list竭盡全力合并進程內產生的IO, 從設備的角度而言進程內產生的IO相關性更強,合并的可能性更大,plug list設計位于elevator queue之上而且又是每個進程私有的,因此plug list既有利于IO合并,又減輕了elevator queue的負擔。elevator queue更多的是承擔進程間IO的合并,用來彌補plug list對進程間合并的不足,如果是帶緩存的IO,這種IO合并基本上不會出現。從實際應用角度出發,IO合并更多的是發生在page cache和plug list中。
-
IO
+關注
關注
0文章
491瀏覽量
40586 -
Cache
+關注
關注
0文章
130瀏覽量
29090
原文標題:劉正元: Linux 通用塊層之IO合并
文章出處:【微信號:LinuxDev,微信公眾號:Linux閱碼場】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
for always可以在block中合成的嗎?
在Vivado 2015.2塊設計上打開子層次結構彈出一個新的Block Design窗口
請問AD09如何為top layer 和bottom layer單獨設置keep out layer的大小?
CAN Physical Layer for Industr
A CAN Physical Layer Discussio
什么是Transport Layer Security
MAX14820 IO-Link設備收發器

http請求 get post
PCIe的Spec中明確規定只有Root有權限發起配置請求

layer是什么?解析ad9中的plane與layer
ACIS內核和parasolid內核的來龍去脈與比較






 工商網監
工商網監
評論