 自動攝影仍是未攻克的一道難題,相機能自動捕捉不平凡的瞬間嗎?
自動攝影仍是未攻克的一道難題,相機能自動捕捉不平凡的瞬間嗎?

發布人:Clips 內容團隊負責人兼研究員 Aseem Agarwala
在我看來,攝影就是在一瞬間內認識到某個事件的重要性,同時通過精準的形態組合完整記錄其面貌。
-Henri Cartier-Bresson
在過去幾年中,人工智能經歷了一場類似寒武紀的大爆發,借助深度學習方法,計算機視覺算法已能夠識別出優質照片的許多元素,包括人、微笑、寵物、日落和著名地標,等等。然而,盡管近期取得了一系列進展,自動攝影仍是未攻克的一道難題。相機能自動捕捉不平凡的瞬間嗎?
前些日子,我們發布了 Google Clips,這是一款全新的免持相機,可自動捕捉生活中的有趣瞬間。我們在設計 Google Clips 時遵循了下面三個重要原則:
我們希望所有計算都在設備端執行。除了延長電池壽命和縮短延遲時間之外,設備端處理還意味著,除非保存或共享短片,否則任何短片都不會離開設備,這是一項重要的隱私控制措施。
我們希望設備能夠拍攝短視頻,而不是單張照片。因為動作能更好地記錄瞬間的形態,留下更真實的記憶,而且,為一個重要瞬間拍攝視頻往往比即時捕捉一個完美瞬間更容易。
我們希望專注于捕捉人和寵物的真實瞬間,而不是將精力放在捕捉藝術圖像這種更抽象、更主觀的問題上。也就是說,我們并未試圖教 Clips 思考構圖、色彩平衡和燈光等問題,而是專注于如何選取包含人和動物進行有趣活動的瞬間。
學習識別不平凡的瞬間
如何訓練算法來識別有趣的瞬間?與大多數機器學習問題一樣,我們首先從數據集入手。先設想 Clips 的各種應用場景,在此基礎上創建出一個由數千個視頻組成的數據集。同時,我們還確保這些數據集涵蓋廣泛的種族、性別和年齡群體。然后我們聘請了專業攝影師和視頻剪輯師仔細檢查視頻,從中選出最佳的短視頻片段。這些前期處理方式為我們的算法提供了可以模仿的實例。然而,僅僅依據專業人士的主觀選擇來訓練算法并不容易,我們需要平滑的標簽梯度來教會算法識別內容的質量(從"完美"到"糟糕")。
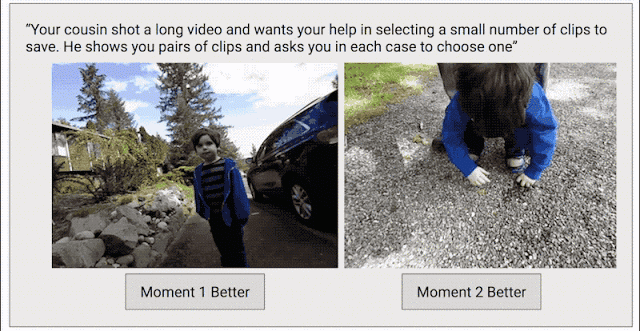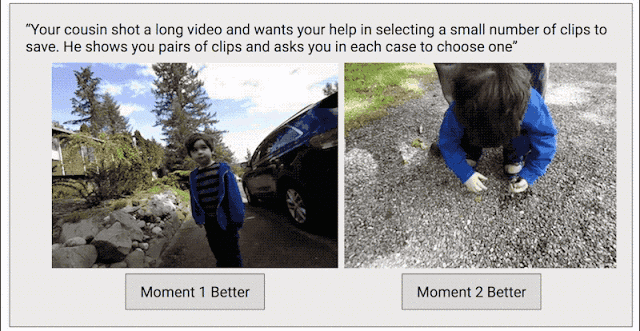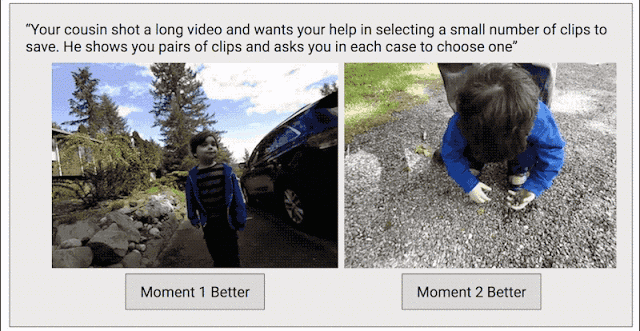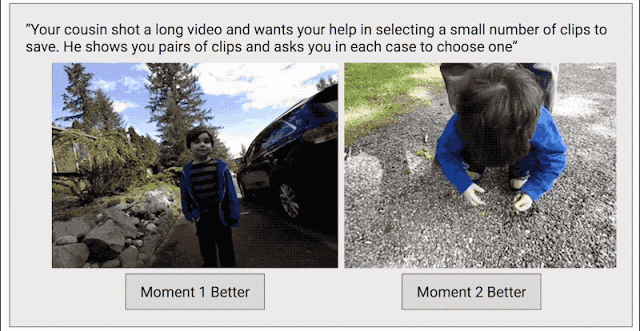
為了解決這個問題,我們采取了另一種數據收集方法,目標是為整個視頻創建連續的質量得分。我們將每個視頻剪輯成短片段(類似于 Clips 捕捉到的內容),然后隨機選擇片段對,并要求人類評分者選擇他們喜歡的片段。
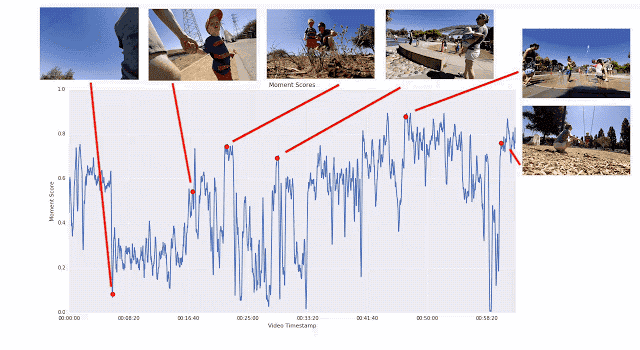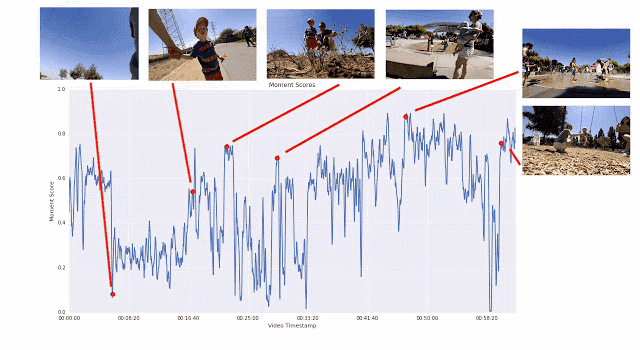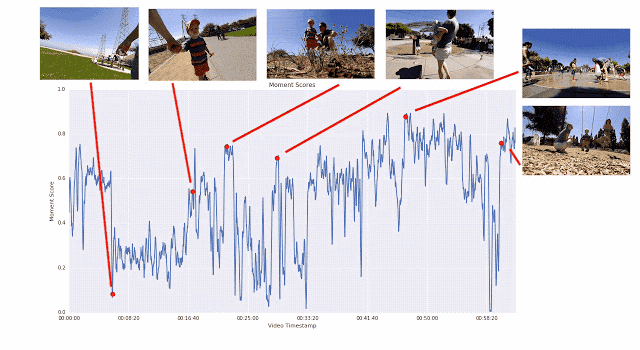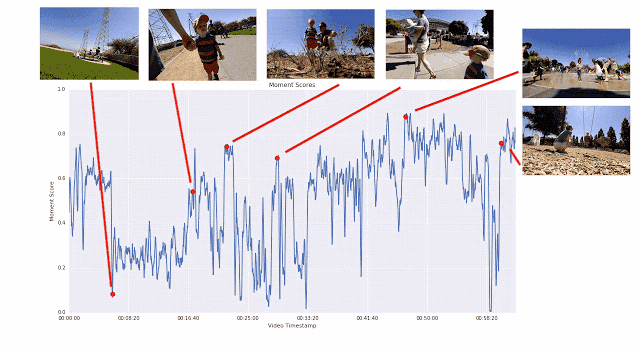
之所以采用這種成對比較的方法,而不是讓評分者直接為視頻打分,是因為兩者擇其優要比給出具體分數容易得多。我們發現評分者在成對比較時的結論非常一致,而在直接評分時則有較大分歧。如果為任意給定視頻提供足夠多的成對比較短片,我們就能計算整個視頻的連續質量得分。通過這一過程,我們從 1000 多個視頻中收集了超過 5000 萬對成對比較短片。如果單純依靠人力,這項工作將異常辛苦。
訓練 Clips 質量模型
掌握質量得分訓練數據后,下一步是訓練一個神經網絡模型來評估設備捕捉到的任意照片的質量。我們首先做了一個基本假設,即了解照片中的內容(例如人、狗和樹等)有助于確定"有趣性"。如果此假設正確,那么我們可以學習一個函數,通過識別到的照片內容來預測其質量得分(如上文所述,得分基于人類的對比評估結果)。
為了確定訓練數據中的內容標簽,我們使用了支持 Google 圖像搜索和 Google 照片的 Google 機器學習技術,這項技術可以識別超過 27000 個描述物體、概念和動作的不同標簽。我們當然不需要所有標簽,也無法在設備上對所有標簽進行計算,因此請專業攝影師從中選擇了幾百個他們認為與預測照片"有趣性"最相關的標簽。我們還添加了與評分者質量得分關聯度最高的標簽。
有了這個標簽子集之后,我們需要設計一個緊湊高效的模型,在電量和發熱嚴格受限的條件下于設備端預測任意給定圖像的標簽。這項工作提出了不小的難題,因為計算機視覺所依托的深度學習技術通常需要強大的桌面 GPU,并且移動設備上運行的算法遠遠落后于桌面設備或云端的最新技術。為了在設備端模型上進行此項訓練,我們首先收集了大量照片,然后再次使用 Google 基于服務器的強大識別模型來預測上述每個"有趣"標簽的置信度。我們隨后訓練了一個 MobileNet 圖像內容模型 (ICM) 來模仿基于服務器的模型的預測。這個緊湊模型能夠識別照片中最有趣的元素,同時忽略不相關的內容。
最后一步是使用 5000 萬成對比較短片作為訓練數據,利用 ICM 預測的照片內容預測輸入照片的質量得分。得分通過逐段線性回歸模型進行計算,將 ICM 輸出轉換為幀質量得分。視頻片段中的幀質量得分取平均值即為瞬間得分。給定一組成對比較短片,我們模型計算出的人類偏好的視頻片段的瞬間得分應當更高一些。訓練模型的目的是使其預測結果盡可能與人類的成對比較結果一致。
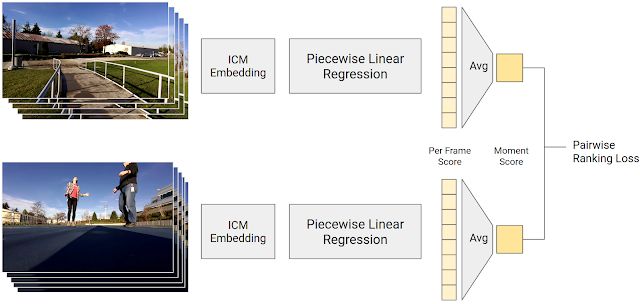
生成幀質量得分的訓練過程圖示。逐段線性回歸模型將 ICM 嵌入映射為幀質量得分,視頻片段中的所有幀質量得分取平均值即為瞬間得分。人類偏好的視頻片段的瞬間得分應當更高。
通過此過程,我們訓練出一個將 Google 圖像識別技術與人類評分者智慧(5000 萬條關于內容有趣性的評估意見)完美融合的模型。
這種基于數據的得分在識別有趣(和無趣)瞬間方面已經做得很好,我們在此基礎上又做了一些補充,針對我們希望 Clips 捕捉的事件的整體質量得分增加了一些獎勵,這些事件包括臉部(特別是因經常出現而比較"熟悉"的臉部)、微笑和寵物。在最新版本中,我們為客戶特別想捕捉的某些活動(如擁抱、親吻、跳躍和跳舞)增加了獎勵。要識別到這些活動,需要擴展 ICM 模型。
拍照控制
基于這款強大的場景"有趣性"預測模型,Clips 相機可以決定哪些瞬間需要實時捕捉。它的拍照控制算法遵循以下三大原則:
重視耗電量和發熱:我們希望 Clips 的電池能夠續航大約三小時,同時不想設備過熱,因此設備不能一直全速運轉。Clips 大部分時間都處于每秒拍攝一幀的低電耗模式。如果這一幀的質量超出根據 Clips 最近拍攝量所設置的閾值,它將進入高電耗模式,以 15 fps 的速度進行拍攝。Clips 隨后會在遇到第一次質量高峰時保存短片。
避免冗余:我們不希望 Clips 一次捕捉所有瞬間,而忽略了其他內容。因此,我們的算法將這些瞬間聚合成視覺相似的組,并限制每一集群中短片的數量。
后見之明的好處:查看拍攝的所有短片之后再選擇最佳短片顯然要簡單得多。因此,Clips 捕捉的瞬間要比預期展示給用戶的多。當短片要傳輸到手機時,Clips 設備會花一秒時間查看其拍攝成果,只把最好和最不冗余的內容傳輸過去。
機器學習的公平性
除了確保視頻數據集展現人口群體多樣性之外,我們還構建了多項測試來評估我們算法的公平性。我們通過從不同性別和膚色中均勻采樣,同時保持內容類型、時長和環境條件等變量恒定,來創建可控的數據集。然后,我們使用此數據集測試算法在應用到其他群體時是否具備類似性能。為了幫助檢測提升瞬間質量模型時可能發生的任何公平性回歸,我們為自動系統增加了公平性測試。對軟件進行的任何變更都要進行這些測試,并且要求必須通過。但需要注意的是,由于我們無法針對每一個可能的場景和結果進行測試,因此,這種方法并不能確保公平性。但實現機器學習算法的公平性畢竟任重而道遠,無法一蹴而就,而這些測試將有助于促進目標的最終實現。
結論
大多數機器學習算法都是圍繞客觀特性評估而設計,例如,判斷照片中是否有貓咪。在我們的用例中,我們的目標是捕捉一個更難捉摸、更主觀的特性,即判斷個人照片是否有趣。因此,我們將照片的客觀、語義內容與主觀人類偏好相結合,在 Google Clips 中實現了人工智能。此外,Clips 的設計目標是與人協同,而不是自主工作;為了獲得良好的拍攝效果,拍攝人仍要具備取景意識并確保相機對準有趣的拍攝內容。我們對 Google Clips 的出色表現感到欣慰,期待繼續改進算法來捕捉"完美"瞬間!
致謝
本文介紹的算法由眾多 Google 工程師、研究員和其他人共同構想并實現。圖片由 Lior Shapira 制作。同時感謝 Lior 和 Juston Payne 提供視頻內容。
-
神經網絡
+關注
關注
42文章
4814瀏覽量
103467 -
計算機視覺
+關注
關注
9文章
1708瀏覽量
46754 -
機器學習
+關注
關注
66文章
8501瀏覽量
134526
原文標題:機器學習案例:Google Clips 自動攝影
文章出處:【微信號:tensorflowers,微信公眾號:Tensorflowers】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
麥科信MHO1系列:示波器捕捉瞬間波形的高效方法
[轉帖]紀念不平凡的2008,超印速免費為您印制10本博客書
[轉帖]紀念不平凡的2008,超印速免費為您印制10本博客書
[分享]紀念不平凡的2008,超印速免費為您印制10本博客書
[原創]紀念不平凡的2008,超印速免費為您印制10本博客書
自動對焦在智能手機的應用
FPGA是ASIC設計者的一道普通難題?
業余攝影師巧捉鷺鷥捕捉地鼠精彩瞬間
屏下攝像頭從幕后到臺前 攻克100%全面屏前的最后一道關卡
泰克示波器如何捕捉瞬間波形?
深圳18650電池焊接機廠家:攻克自動點焊機虛焊難題






 工商網監
工商網監
評論