") 一個使用傳統(tǒng)DAS和深度強化學(xué)習(xí)融合的自動駕駛框架
一個使用傳統(tǒng)DAS和深度強化學(xué)習(xí)融合的自動駕駛框架
增強學(xué)習(xí)是最近幾年中機器學(xué)習(xí)領(lǐng)域的最新進(jìn)展。增強學(xué)習(xí)依靠與環(huán)境交互學(xué)習(xí),在相應(yīng)的觀測中采取最優(yōu)行為。行為的好壞可以通過環(huán)境給予的獎勵來確定。不同的環(huán)境有不同的觀測和獎勵。例如,駕駛中環(huán)境觀測是攝像頭和激光雷達(dá)采集到的周圍環(huán)境的圖像和點云,以及其他的傳感器的輸出,例如行駛速度、GPS定位、行駛方向。駕駛中的環(huán)境的獎勵根據(jù)任務(wù)的不同,可以通過到達(dá)終點的速度、舒適度和安全性等指標(biāo)確定。增強學(xué)習(xí)和傳統(tǒng)機器學(xué)習(xí)的最大區(qū)別是增強學(xué)習(xí)是一個閉環(huán)學(xué)習(xí)的系統(tǒng),增強學(xué)習(xí)算法選取的行為會直接影響到環(huán)境,進(jìn)而影響到該算法之后從環(huán)境中得到的觀測。
增強學(xué)習(xí)在無人駕駛中的應(yīng)用
關(guān)于安全自主駕駛的研究可以分為兩種方法:一是傳統(tǒng)的感知,規(guī)劃和控制框架,另一種是基于學(xué)習(xí)的方法。基于學(xué)習(xí)的方法可以成功處理在計算機視覺領(lǐng)域的高維特征(如卷積神經(jīng)網(wǎng)絡(luò)(CNN))而廣受歡迎[5]-[7],強化學(xué)習(xí)算法可以最大化預(yù)期獎勵的總和。有越來越多的研究開始將這兩種技術(shù)結(jié)合,用于自動駕駛。對于車道保持,Rausch等人[8]提出了一種訓(xùn)練網(wǎng)絡(luò)的方法,該方法直接根據(jù)從前置攝像頭獲得的圖像預(yù)測轉(zhuǎn)向角。結(jié)果表明,該神經(jīng)網(wǎng)絡(luò)可以通過從前置攝像頭得到的原始圖像,自動學(xué)習(xí)車道等特征,來訓(xùn)練車輛的車道保持的轉(zhuǎn)向角度。 John等人[9]提出了混合框架,通過使用長短期記憶網(wǎng)絡(luò)(LSTM)為每個場景計算適當(dāng)?shù)霓D(zhuǎn)向角。每個網(wǎng)絡(luò)都會在特定道路場景的特定分區(qū)(如直線駕駛,右轉(zhuǎn)彎和左轉(zhuǎn)彎)中,對駕駛行為進(jìn)行建模。在考慮多種駕駛場景時,它在多個駕駛序列中運行良好。 Al-Qizwini等人[10]提出了一種回歸網(wǎng)絡(luò),預(yù)測駕駛的可利用狀態(tài),如前置攝像機圖像中的交叉錯誤,航向誤差和障礙物距離,而不是通過使用GoogLeNet直接從前攝像機圖像預(yù)測轉(zhuǎn)向角[11 ] 。轉(zhuǎn)向角度,油門和制動都是使用基于if-else規(guī)則的算法計算出來的。
Sallab等[12]提出了一種在沒有障礙物的情況下,使用DQN(Deep Q Network)和DDAC(Deep Deterministic Actor Critic)學(xué)習(xí)車道保持駕駛策略的方法。他們直接掌握轉(zhuǎn)向,加速和減速,根據(jù)低維特征(如速度,軌道邊界位置)最大限度地提高預(yù)期的未來回報。因此,使用可應(yīng)用于連續(xù)作用的DDAC而非離散作用空間的DQN可以提高車道保持性能。 Zong等[13]提出了一種應(yīng)用DDPG [14]來躲避障礙物,學(xué)習(xí)轉(zhuǎn)向角和加速度值的方法。上述方法可以直接獲得控制車輛所需的合適的轉(zhuǎn)向角度、油門和制動量。然而,在這些情況下,每當(dāng)車輛的參數(shù)改變時,最佳策略就會改變。因此存在很大限制,即為了最佳策略要不斷進(jìn)行學(xué)習(xí)。
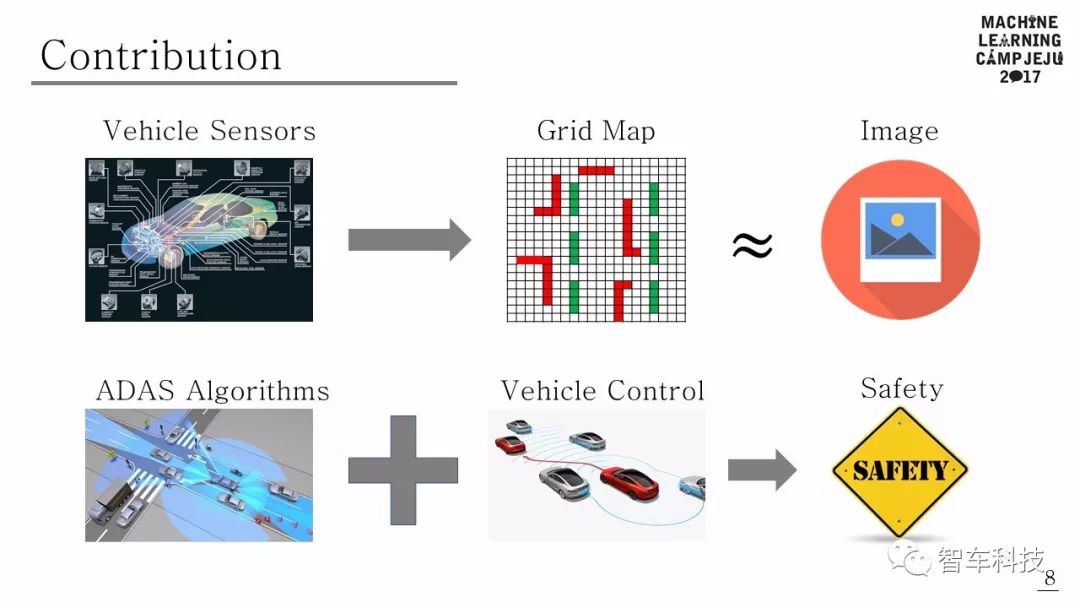
本文提出了一個使用傳統(tǒng)DAS和深度強化學(xué)習(xí)融合的自動駕駛框架。該框架在DAS功能(例如車道變換,巡航控制和車道保持等)下,以最大限度地提高平均速度和最少車道變化為規(guī)則,來確定超車次數(shù)。可行駛空間是根據(jù)行為水平定義的,利用駕駛策略可以學(xué)習(xí)車道保持,車道變更和巡航控制等行為。為了驗證所提出的算法,該算法在密集交通狀況的模擬中進(jìn)行了測試,并證明了隨著駕駛期間的學(xué)習(xí)進(jìn)展,平均速度,超車次數(shù)和車道變換次數(shù)方面性能得到改善。
Deep Q Learning Based High Level Driving Policy Determination
Kyushik Min,
Hayoung Kim and Kunsoo Huh, Member, IEEE
作者Kyushik Min,韓國漢陽大學(xué)機器監(jiān)測和控制實驗室博士生,研究方向為高級駕駛輔助系統(tǒng)(ADAS)和自動駕駛。
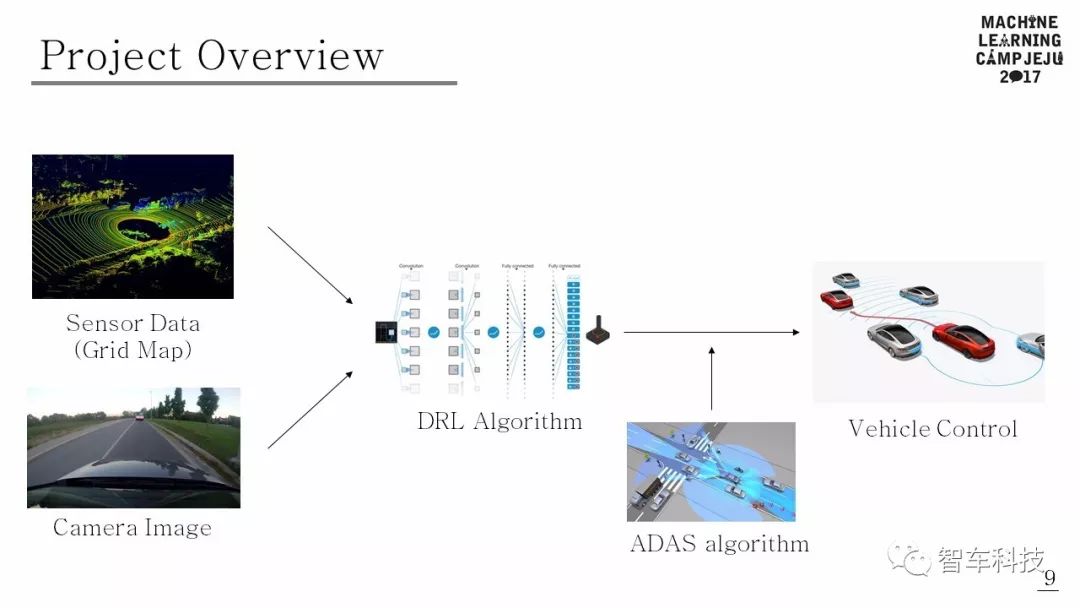
項目概述
該項目為Tensorflow Korea 主辦的2017濟州學(xué)習(xí)營項目。使用傳感器數(shù)據(jù)和相機圖像作為DRL算法的輸入。DRL算法根據(jù)輸入決定行駛動作。如果行動可能導(dǎo)致危險情況,ADAS可以控制車輛以避免碰撞。
高層自動駕駛決策的實現(xiàn)
1.馬爾科夫決策過程(MDP)
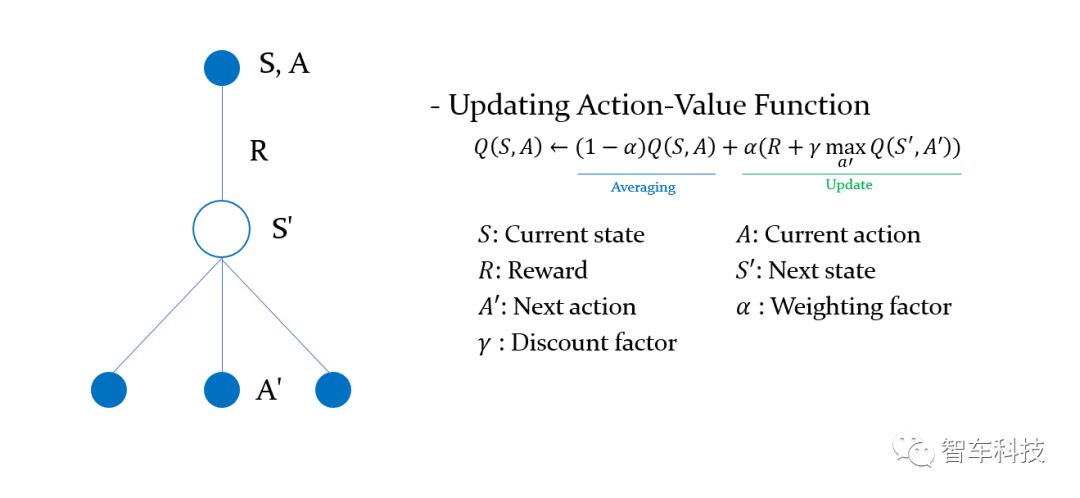
馬爾可夫決策過程(MDP)是決策的數(shù)學(xué)框架,它由元組
2.感知
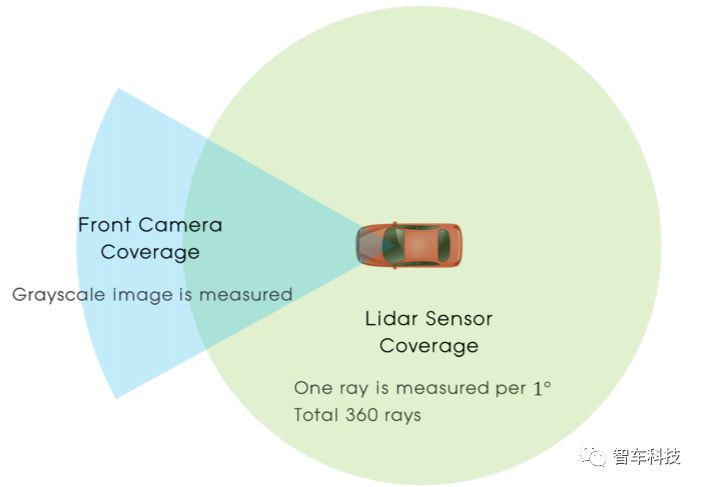
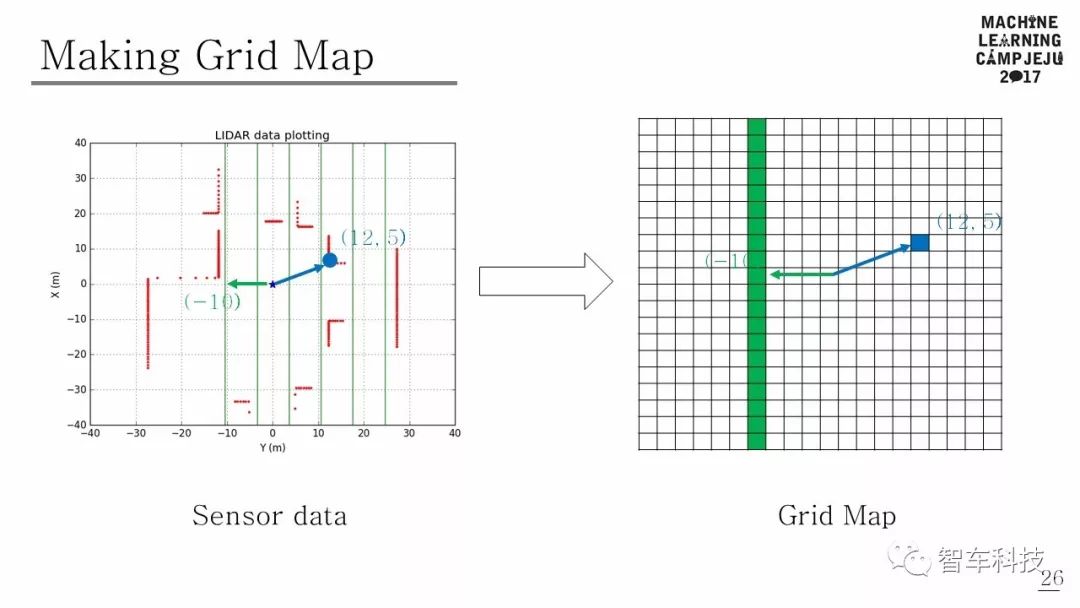
使用LIDAR傳感器數(shù)據(jù)和相機圖像數(shù)據(jù)構(gòu)建感知狀態(tài)。傳感器配置的總覆蓋范圍可以在上圖中看到。
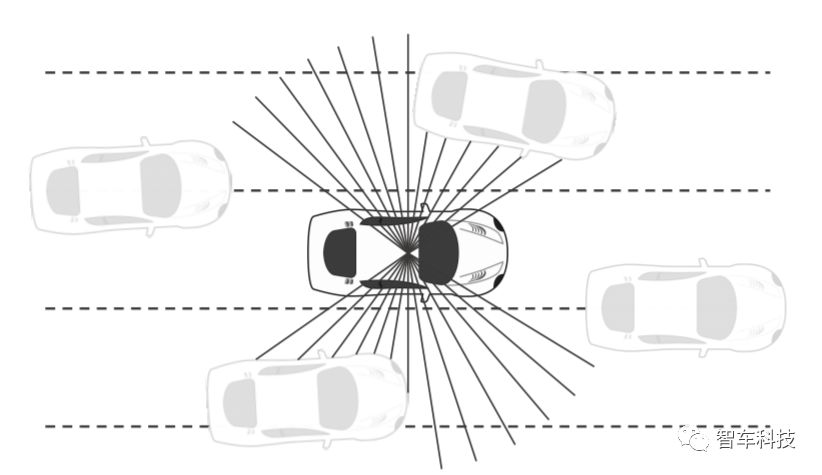
障礙物距離可以從LIDAR傳感器獲得,也可以從前端攝像頭中獲得原始圖像來輔助感知。由于激光雷達(dá)的距離數(shù)據(jù)和來自相機的圖像數(shù)據(jù)具有完全不同的特點,因此本研究采用多模態(tài)輸入方案。
3.行動
駕駛決策的行動空間是在離散行動空間中定義的。當(dāng)我們利用傳統(tǒng)DAS的優(yōu)勢時,這個系統(tǒng)的每個動作都可能激活對應(yīng)的DAS功能。在縱向方向上,有三種動作:1.速度為V + Vcc的巡航控制,其中Vcc為額外目標(biāo)速度,設(shè)定為5km / h,2.當(dāng)前速度為V的巡航控制,3.速度為巡航控制 V - Vcc。這些縱向行動將觸發(fā)自主緊急制動(AEB)和自適應(yīng)巡航控制(ACC)。在橫向方向上,還有三種動作:1.保持車道,2.將車道變到左側(cè),3.將車道變到右側(cè)。由于自動駕駛車輛同時在縱向和橫向兩個方向上駕駛,我們定義了5個離散行為。(靜止,加速,減速,車道改變到左側(cè),車道改變到右側(cè))
4.獎勵
根據(jù)強化學(xué)習(xí)選擇不同的行動,將收到行動結(jié)果的獎勵。在MDP上解決的問題是找到一個能夠最大化未來預(yù)期價值獎勵的驅(qū)動策略。這意味著最佳駕駛策略可以完全不同,具體取決于獎勵的設(shè)計方式。因此,設(shè)計適當(dāng)?shù)莫剟顧C制對學(xué)習(xí)正確的駕駛策略非常重要。當(dāng)車輛在密集的交通情況下行駛時,應(yīng)該滿足以下三個條件:1.找到使車輛高速行駛的策略,2.以無碰撞的軌跡行駛,3.不頻繁地改變車道。 基于這三個條件來設(shè)計獎勵機制。
用于決策學(xué)習(xí)的DEEP RL算法
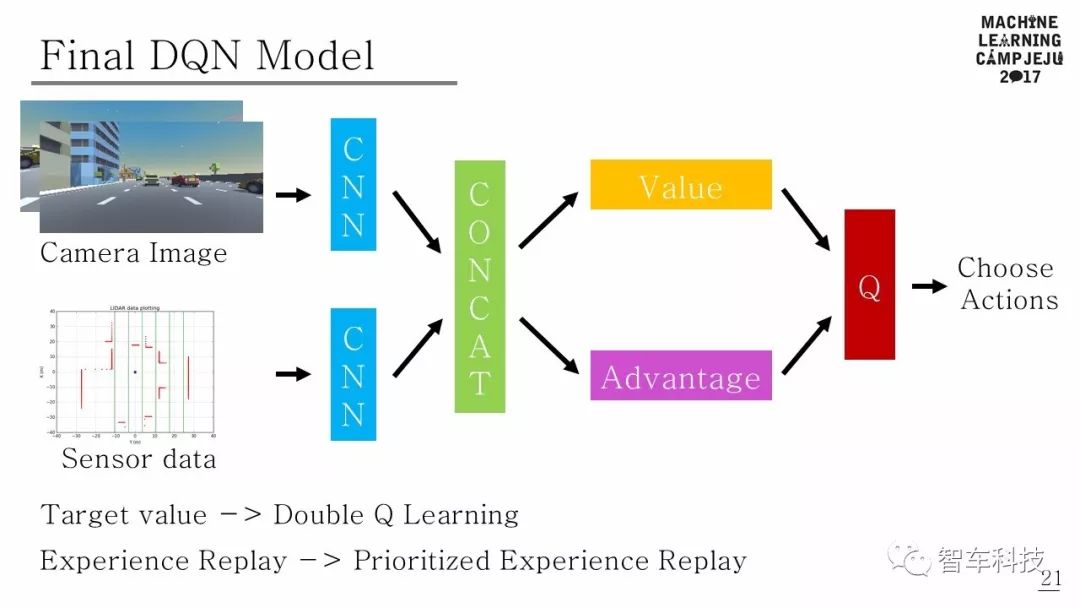
DQN在強化學(xué)習(xí)和神經(jīng)網(wǎng)絡(luò)相結(jié)合的游戲領(lǐng)域取得巨大成功之后,對深度強化學(xué)習(xí)進(jìn)行了各種研究[16]。尤其是,在基于DQN價值的深層強化學(xué)習(xí)[17] - [22]中進(jìn)行了大量研究。在此項研究中,深層增強學(xué)習(xí)算法由DQN [1],Double DQN [17]和Dueling DQN [19]組合得到最近的算法模型,其中的算法參考了Human-level Control Through Deep Reinforcement Learning[1],Deep Reinforcement Learning with Double Q-Learning[17],Prioritized Experience Replay[18],Dueling Network Architecture for Deep Reinforcement Learning[19]四篇論文中的算法。
項目代碼可以在Github上查找:
https://github.com/MLJejuCamp2017/DRL_based_SelfDrivingCarControl
下圖為最終的DQN模型。
仿真模擬
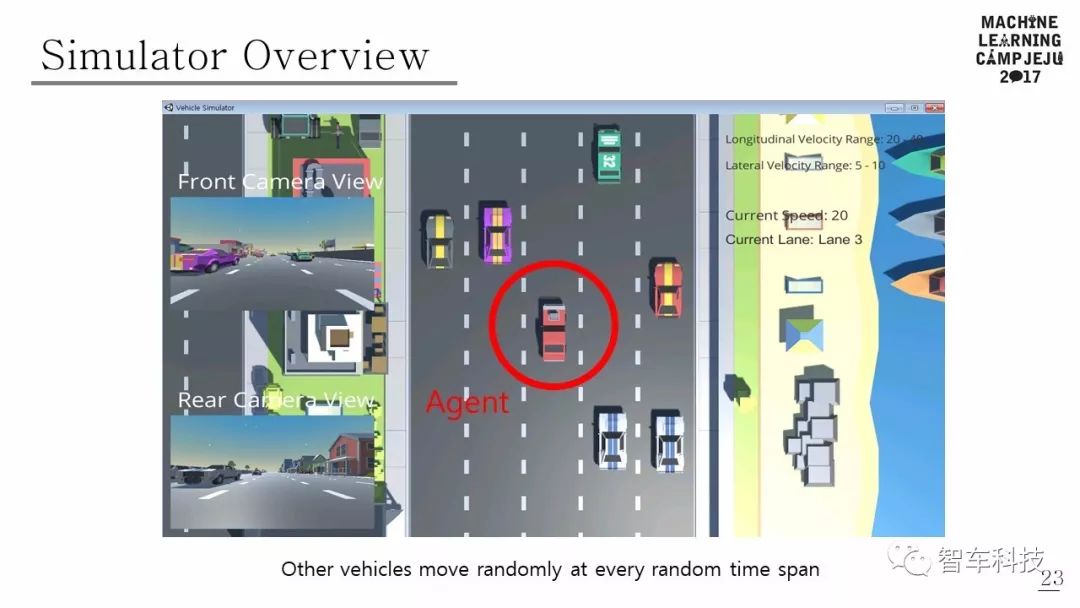
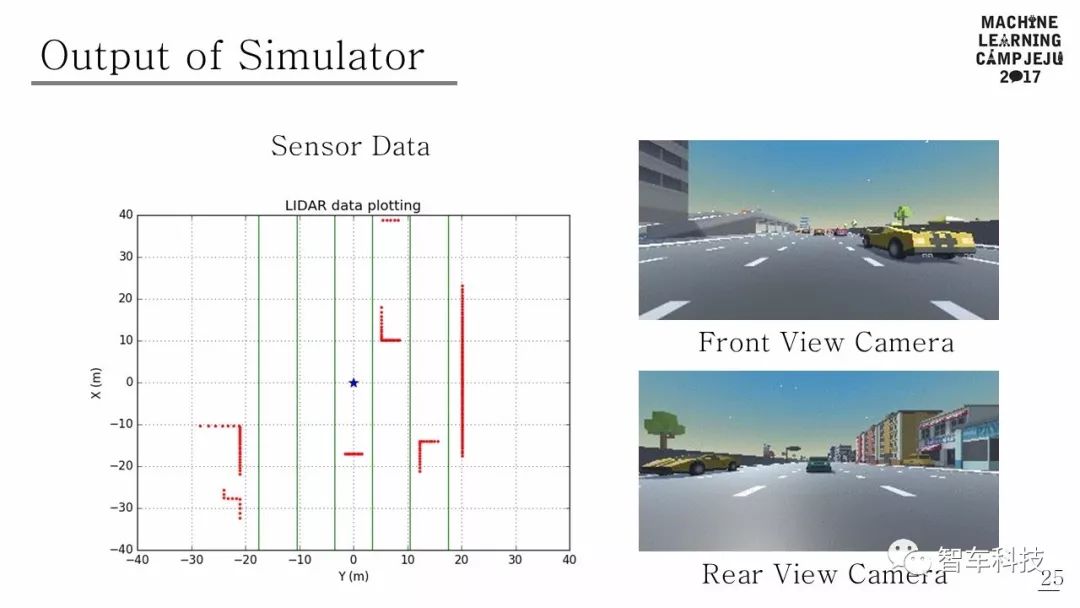
本文使用的模擬器是由 Unity 和 Unity ML-Agents 構(gòu)建的。模擬道路環(huán)境是由五車道組成的高速公路行車道。其他車輛在距離主車輛一定距離內(nèi)的隨機車道中心產(chǎn)生。另外,假定其他車輛在大多數(shù)情況下不會彼此碰撞,并且可以執(zhí)行五個動作(加速,減速,車道改變到右車道,車道改變到左車道,保持當(dāng)前狀態(tài))。其他車輛的各種行動以多種隨機方式出現(xiàn),改變了模擬環(huán)境,因此Agent 可以體驗許多不同的情況。模擬器的觀測結(jié)果有兩種類型:一種是圖像,另一種是激光雷達(dá)范圍陣列。由于前面有攝像頭,因此每一步都會觀察到原始像素圖像。 LIDAR傳感器檢測有一個360度的射線范圍,如果光線掃描到物體,它會返回主車輛和物體之間的距離。如果沒有障礙物,則返回模擬器每一步的最大感應(yīng)距離。
結(jié)果與結(jié)論
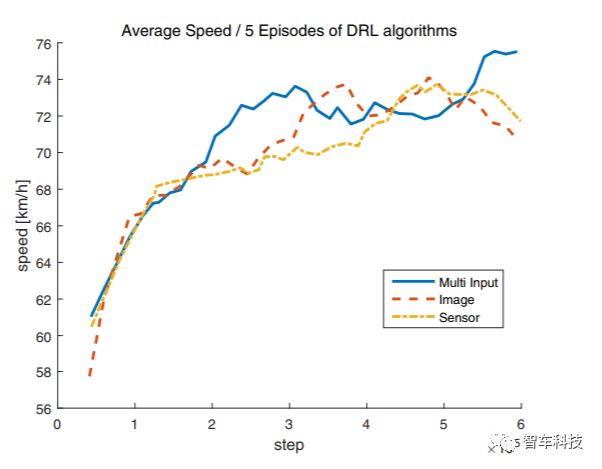
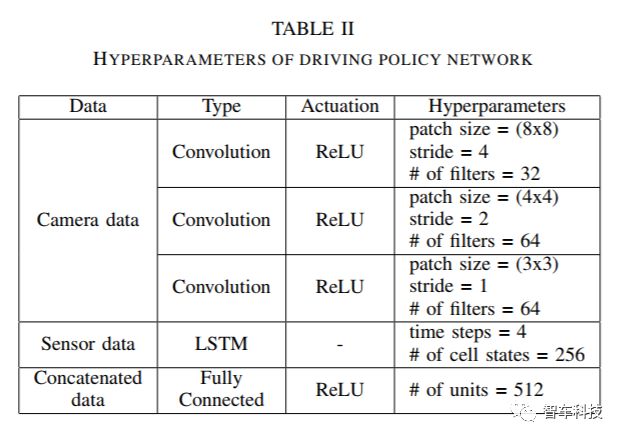
本文提出的駕駛策略算法使用Tensorflow 架構(gòu)[25]實現(xiàn)的,平均速度,車道變化次數(shù)和超車次數(shù)等數(shù)據(jù)都可以從中讀出。為驗證多輸入體系結(jié)構(gòu)的優(yōu)勢,該體系結(jié)構(gòu)分別將來自攝像機和LIDAR的數(shù)據(jù)通過CNN和LSTM相結(jié)合,另外還使用了兩個僅用攝像機輸入和LIDAR輸入的策略網(wǎng)絡(luò)作為對比。
比較三種不同的不同輸入的網(wǎng)絡(luò)架構(gòu):攝像頭,LIDAR,攝像頭和激光雷達(dá)。隨著訓(xùn)練的進(jìn)行,自動駕駛車輛會超越更多的車輛并以更快的速度行駛,而不會在每個輸入車輛的環(huán)境中,出現(xiàn)不必要的車道變化。結(jié)果顯示,多輸入架構(gòu)在平均速度和平均超車次數(shù)方面表現(xiàn)出最佳性能,分別為73.54km / h和42.2。但是,當(dāng)使用多輸入架構(gòu)時,車道變化的數(shù)量最多,其平均值為30.2。盡管所提出的算法的目標(biāo)是減少不必要的車道變化的數(shù)量,但多輸入架構(gòu)的結(jié)果在車道變化的數(shù)量方面是最高的。對于LIDAR和攝像頭架構(gòu)中,即使前車速度較慢,它們有時也會顯示跟隨前方車輛而不更改車道。因此,研究車道變化的數(shù)量是尋找最優(yōu)策略的關(guān)鍵。
在本文中,駕駛策略網(wǎng)絡(luò)充分利用傳統(tǒng)的DAS功能,在大多數(shù)情況下保證了車輛行駛的安全性。使用深度強化學(xué)習(xí)算法訓(xùn)練的自主車輛,在模擬高速公路場景中成功駕駛,所提出的策略網(wǎng)絡(luò)使用多模式輸入,不會造成不必要的車道變化,在平均速度,車道變化次數(shù)和超車次數(shù)方面,車輛比具有單輸入的車輛更好地駕駛。這項研究的結(jié)果表明,自主車輛可以由受過深度強化學(xué)習(xí)訓(xùn)練的主管來控制。
-
DAS
+關(guān)注
關(guān)注
1文章
115瀏覽量
31713 -
自動駕駛
+關(guān)注
關(guān)注
788文章
14242瀏覽量
169909 -
強化學(xué)習(xí)
+關(guān)注
關(guān)注
4文章
269瀏覽量
11534
原文標(biāo)題:IEEE IV 2018:基于深度增強學(xué)習(xí)的高層駕駛決策研究
文章出處:【微信號:IV_Technology,微信公眾號:智車科技】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
新能源車軟件單元測試深度解析:自動駕駛系統(tǒng)視角
AI將如何改變自動駕駛?
自動駕駛大模型中常提的Token是個啥?對自動駕駛有何影響?
一文聊聊自動駕駛測試技術(shù)的挑戰(zhàn)與創(chuàng)新

自動駕駛中一直說的BEV+Transformer到底是個啥?

如何使用 PyTorch 進(jìn)行強化學(xué)習(xí)
人工智能的應(yīng)用領(lǐng)域有自動駕駛嗎
Mobileye端到端自動駕駛解決方案的深度解析






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論