") 2018年為數(shù)據(jù)科學(xué)領(lǐng)域中豐富的Python庫(kù)集合
2018年為數(shù)據(jù)科學(xué)領(lǐng)域中豐富的Python庫(kù)集合
Python 在解決數(shù)據(jù)科學(xué)任務(wù)和挑戰(zhàn)方面繼續(xù)處于領(lǐng)先地位。去年,我們?cè)l(fā)表一篇博客文章Top 15 Python Libraries for Data Science in 2017,概述了當(dāng)時(shí)業(yè)已證明最有幫助的Python庫(kù)。今年,我們擴(kuò)展了這個(gè)清單,增加了新的 Python 庫(kù),并重新審視了去年已經(jīng)討論過(guò)的 Python 庫(kù),重點(diǎn)關(guān)注了這一年來(lái)的更新。
我們的選擇實(shí)際上包含了 20 多個(gè)庫(kù),因?yàn)槠渲幸恍?kù)是相互替代的,可以解決相同的問(wèn)題。因此,我們將它們放在同一個(gè)分組。
▌核心庫(kù)和統(tǒng)計(jì)數(shù)據(jù)
1. NumPy (Commits: 17911, Contributors: 641)
官網(wǎng):http://www.numpy.org/
NumPy 是科學(xué)應(yīng)用程序庫(kù)的主要軟件包之一,用于處理大型多維數(shù)組和矩陣,它大量的高級(jí)數(shù)學(xué)函數(shù)集合和實(shí)現(xiàn)方法使得這些對(duì)象執(zhí)行操作成為可能。
2. SciPy (Commits: 19150, Contributors: 608)
官網(wǎng):https://scipy.org/scipylib/
科學(xué)計(jì)算的另一個(gè)核心庫(kù)是 SciPy。它基于 NumPy,其功能也因此得到了擴(kuò)展。SciPy 主數(shù)據(jù)結(jié)構(gòu)又是一個(gè)多維數(shù)組,由 Numpy 實(shí)現(xiàn)。這個(gè)軟件包包含了幫助解決線性代數(shù)、概率論、積分計(jì)算和許多其他任務(wù)的工具。此外,SciPy 還封裝了許多新的 BLAS 和 LAPACK 函數(shù)。
3. Pandas (Commits: 17144, Contributors: 1165)
官網(wǎng):https://pandas.pydata.org/
Pandas 是一個(gè) Python 庫(kù),提供高級(jí)的數(shù)據(jù)結(jié)構(gòu)和各種各樣的分析工具。這個(gè)軟件包的主要特點(diǎn)是能夠?qū)⑾喈?dāng)復(fù)雜的數(shù)據(jù)操作轉(zhuǎn)換為一兩個(gè)命令。Pandas包含許多用于分組、過(guò)濾和組合數(shù)據(jù)的內(nèi)置方法,以及時(shí)間序列功能。
4. StatsModels (Commits: 10067, Contributors: 153)
官網(wǎng):http://www.statsmodels.org/devel/
Statsmodels 是一個(gè) Python 模塊,它為統(tǒng)計(jì)數(shù)據(jù)分析提供了許多機(jī)會(huì),例如統(tǒng)計(jì)模型估計(jì)、執(zhí)行統(tǒng)計(jì)測(cè)試等。在它的幫助下,你可以實(shí)現(xiàn)許多機(jī)器學(xué)習(xí)方法并探索不同的繪圖可能性。
Python 庫(kù)不斷發(fā)展,不斷豐富新的機(jī)遇。因此,今年出現(xiàn)了時(shí)間序列的改進(jìn)和新的計(jì)數(shù)模型,即 GeneralizedPoisson、零膨脹模型(zero inflated models)和 NegativeBinomialP,以及新的多元方法:因子分析、多元方差分析以及方差分析中的重復(fù)測(cè)量。
▌可視化
5. Matplotlib (Commits: 25747, Contributors: 725)
官網(wǎng):https://matplotlib.org/index.html
Matplotlib 是一個(gè)用于創(chuàng)建二維圖和圖形的底層庫(kù)。藉由它的幫助,你可以構(gòu)建各種不同的圖標(biāo),從直方圖和散點(diǎn)圖到費(fèi)笛卡爾坐標(biāo)圖。此外,有許多流行的繪圖庫(kù)被設(shè)計(jì)為與matplotlib結(jié)合使用。
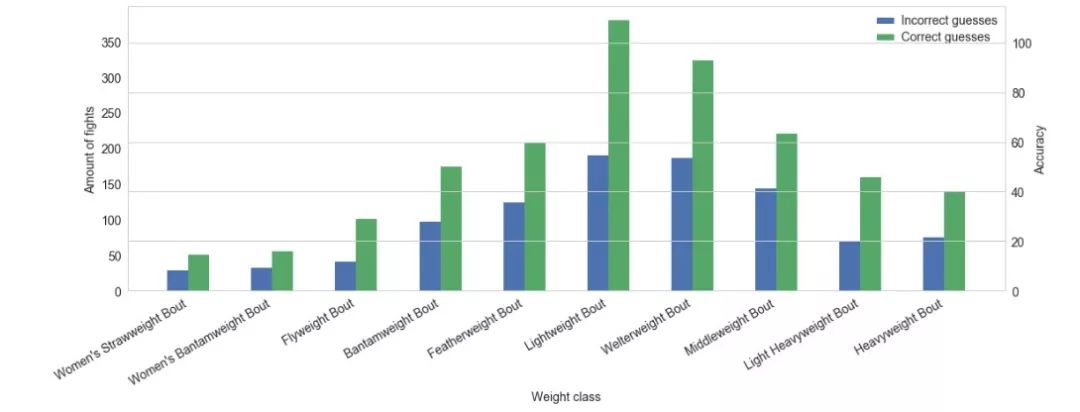
6. Seaborn (Commits: 2044, Contributors: 83)
官網(wǎng):https://seaborn.pydata.org/
Seaborn 本質(zhì)上是一個(gè)基于 matplotlib 庫(kù)的高級(jí) API。它包含更適合處理圖表的默認(rèn)設(shè)置。此外,還有豐富的可視化庫(kù),包括一些復(fù)雜類型,如時(shí)間序列、聯(lián)合分布圖(jointplots)和小提琴圖(violin diagrams)。
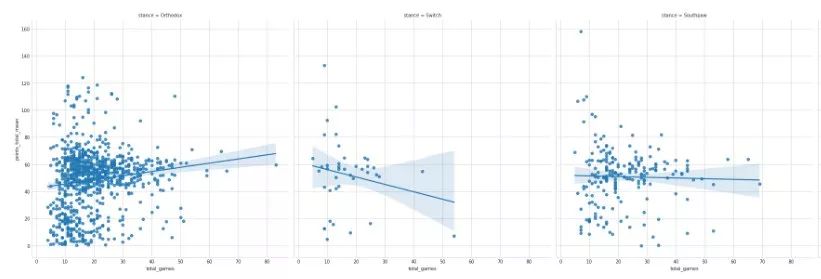
7. Plotly (Commits: 2906, Contributors: 48)
官網(wǎng):https://plot.ly/python/
Plotly 是一個(gè)流行的庫(kù),它可以讓你輕松構(gòu)建復(fù)雜的圖形。該軟件包適用于交互式 Web 應(yīng)用程,可實(shí)現(xiàn)輪廓圖、三元圖和三維圖等視覺(jué)效果。
8. Bokeh (Commits: 16983, Contributors: 294)
官網(wǎng):https://bokeh.pydata.org/en/latest/
Bokeh 庫(kù)使用 JavaScript 小部件在瀏覽器中創(chuàng)建交互式和可縮放的可視化。該庫(kù)提供了多種圖表集合,樣式可能性(styling possibilities),鏈接圖、添加小部件和定義回調(diào)等形式的交互能力,以及許多更有用的特性。
9. Pydot (Commits: 169, Contributors: 12)
官網(wǎng):https://pypi.org/project/pydot/
Pydot 是一個(gè)用于生成復(fù)雜的定向圖和無(wú)向圖的庫(kù)。它是用純 Python 編寫(xiě)的Graphviz 接口。在它的幫助下,可以顯示圖形的結(jié)構(gòu),這在構(gòu)建神經(jīng)網(wǎng)絡(luò)和基于決策樹(shù)的算法時(shí)經(jīng)常用到。
10. Scikit-learn (Commits: 22753, Contributors: 1084)
官網(wǎng):http://scikit-learn.org/stable/
這個(gè)基于 NumPy 和 SciPy 的 Python 模塊是處理數(shù)據(jù)的最佳庫(kù)之一。它為許多標(biāo)準(zhǔn)的機(jī)器學(xué)習(xí)和數(shù)據(jù)挖掘任務(wù)提供算法,如聚類、回歸、分類、降維和模型選擇。
利用 Data Science School 提高你的技能
Data Science School:http://datascience-school.com/
11. XGBoost / LightGBM / CatBoost (Commits: 3277 / 1083 / 1509, Contributors: 280 / 79 / 61)
官網(wǎng):
http://xgboost.readthedocs.io/en/latest/
http://lightgbm.readthedocs.io/en/latest/Python-Intro.html
https://github.com/catboost/catboost
梯度增強(qiáng)算法是最流行的機(jī)器學(xué)習(xí)算法之一,它是建立一個(gè)不斷改進(jìn)的基本模型,即決策樹(shù)。因此,為了快速、方便地實(shí)現(xiàn)這個(gè)方法而設(shè)計(jì)了專門(mén)庫(kù)。就是說(shuō),我們認(rèn)為 XGBoost、LightGBM 和 CatBoost 值得特別關(guān)注。它們都是解決常見(jiàn)問(wèn)題的競(jìng)爭(zhēng)者,并且使用方式幾乎相同。這些庫(kù)提供了高度優(yōu)化的、可擴(kuò)展的、快速的梯度增強(qiáng)實(shí)現(xiàn),這使得它們?cè)跀?shù)據(jù)科學(xué)家和 Kaggle 競(jìng)爭(zhēng)對(duì)手中非常流行,因?yàn)樵谶@些算法的幫助下贏得了許多比賽。
12. Eli5 (Commits: 922, Contributors: 6)
官網(wǎng):https://eli5.readthedocs.io/en/latest/
通常情況下,機(jī)器學(xué)習(xí)模型預(yù)測(cè)的結(jié)果并不完全清楚,這正是 Eli5 幫助應(yīng)對(duì)的挑戰(zhàn)。它是一個(gè)用于可視化和調(diào)試機(jī)器學(xué)習(xí)模型并逐步跟蹤算法工作的軟件包,為 scikit-learn、XGBoost、LightGBM、lightning 和 sklearn-crfsuite 庫(kù)提供支持,并為每個(gè)庫(kù)執(zhí)行不同的任務(wù)。
13. TensorFlow (Commits: 33339, Contributors: 1469)
官網(wǎng):https://www.tensorflow.org/
TensorFlow 是一個(gè)流行的深度學(xué)習(xí)和機(jī)器學(xué)習(xí)框架,由 Google Brain 開(kāi)發(fā)。它提供了使用具有多個(gè)數(shù)據(jù)集的人工神經(jīng)網(wǎng)絡(luò)的能力。在最流行的 TensorFlow應(yīng)用中有目標(biāo)識(shí)別、語(yǔ)音識(shí)別等。在常規(guī)的 TensorFlow 上也有不同的 leyer-helper,如 tflearn、tf-slim、skflow 等。
14. PyTorch (Commits: 11306, Contributors: 635)
官網(wǎng):https://pytorch.org/
PyTorch 是一個(gè)大型框架,它允許使用 GPU 加速執(zhí)行張量計(jì)算,創(chuàng)建動(dòng)態(tài)計(jì)算圖并自動(dòng)計(jì)算梯度。在此之上,PyTorch 為解決與神經(jīng)網(wǎng)絡(luò)相關(guān)的應(yīng)用程序提供了豐富的 API。該庫(kù)基于 Torch,是用 C 實(shí)現(xiàn)的開(kāi)源深度學(xué)習(xí)庫(kù)。
15. Keras (Commits: 4539, Contributors: 671)
官網(wǎng):https://keras.io/
Keras 是一個(gè)用于處理神經(jīng)網(wǎng)絡(luò)的高級(jí)庫(kù),運(yùn)行在 TensorFlow、Theano 之上,現(xiàn)在由于新版本的發(fā)布,還可以使用 CNTK 和 MxNet 作為后端。它簡(jiǎn)化了許多特定的任務(wù),并且大大減少了單調(diào)代碼的數(shù)量。然而,它可能不適合某些復(fù)雜的任務(wù)。
▌分布式深度學(xué)習(xí)
16. Dist-keras / elephas / spark-deep-learning (Commits: 1125 / 170 / 67, Contributors: 5 / 13 / 11)
官網(wǎng):
http://joerihermans.com/work/distributed-keras/
https://pypi.org/project/elephas/
https://databricks.github.io/spark-deep-learning/site/index.html
隨著越來(lái)越多的用例需要花費(fèi)大量的精力和時(shí)間,深度學(xué)習(xí)問(wèn)題變得越來(lái)越重要。然而,使用像 Apache Spark 這樣的分布式計(jì)算系統(tǒng),處理如此多的數(shù)據(jù)要容易得多,這再次擴(kuò)展了深入學(xué)習(xí)的可能性。因此,dist-keras、elephas 和 spark-deep-learning 都在迅速流行和發(fā)展,而且很難挑出一個(gè)庫(kù),因?yàn)樗鼈兌际菫榻鉀Q共同的任務(wù)而設(shè)計(jì)的。這些包允許你在 Apache Spark 的幫助下直接訓(xùn)練基于 Keras 庫(kù)的神經(jīng)網(wǎng)絡(luò)。Spark-deep-learning 還提供了使用 Python 神經(jīng)網(wǎng)絡(luò)創(chuàng)建管道的工具。
▌自然語(yǔ)言處理
17. NLTK (Commits: 13041, Contributors: 236)
官網(wǎng):https://www.nltk.org/
NLTK 是一組庫(kù),一個(gè)用于自然語(yǔ)言處理的完整平臺(tái)。在 NLTK 的幫助下,你可以以各種方式處理和分析文本,對(duì)文本進(jìn)行標(biāo)記和標(biāo)記,提取信息等。NLTK 也用于原型設(shè)計(jì)和建立研究系統(tǒng)。
18. SpaCy (Commits: 8623, Contributors: 215)
官網(wǎng):https://spacy.io/
SpaCy 是一個(gè)具有優(yōu)秀示例、API 文檔和演示應(yīng)用程序的自然語(yǔ)言處理庫(kù)。這個(gè)庫(kù)是用 Cython 語(yǔ)言編寫(xiě)的,Cython 是 Python 的 C 擴(kuò)展。它支持近 30 種語(yǔ)言,提供了簡(jiǎn)單的深度學(xué)習(xí)集成,保證了健壯性和高準(zhǔn)確率。SpaCy 的另一個(gè)重要特性是專為整個(gè)文檔處理設(shè)計(jì)的體系結(jié)構(gòu),無(wú)須將文檔分解成短語(yǔ)。
19. Gensim (Commits: 3603, Contributors: 273)
官網(wǎng):https://radimrehurek.com/gensim/
Gensim 是一個(gè)用于健壯語(yǔ)義分析、主題建模和向量空間建模的 Python 庫(kù),構(gòu)建在Numpy和Scipy之上。它提供了流行的NLP算法的實(shí)現(xiàn),如 word2vec。盡管 gensim 有自己的 models.wrappers.fasttext實(shí)現(xiàn),但 fasttext 庫(kù)也可以用來(lái)高效學(xué)習(xí)詞語(yǔ)表示。
▌數(shù)據(jù)采集
20. Scrapy (Commits: 6625, Contributors: 281)
官網(wǎng):https://scrapy.org/
Scrapy 是一個(gè)用來(lái)創(chuàng)建網(wǎng)絡(luò)爬蟲(chóng),掃描網(wǎng)頁(yè)和收集結(jié)構(gòu)化數(shù)據(jù)的庫(kù)。此外,Scrapy 可以從 API 中提取數(shù)據(jù)。由于該庫(kù)的可擴(kuò)展性和可移植性,使得它用起來(lái)非常方便。
▌結(jié)論
本文上述所列就是我們?cè)?2018 年為數(shù)據(jù)科學(xué)領(lǐng)域中豐富的 Python 庫(kù)集合。與上一年相比,一些新的現(xiàn)代庫(kù)越來(lái)越受歡迎,而那些已經(jīng)成為經(jīng)典的數(shù)據(jù)科學(xué)任務(wù)的庫(kù)也在不斷改進(jìn)。
下表顯示了 GitHub 活動(dòng)的詳細(xì)統(tǒng)計(jì)數(shù)據(jù):
-
機(jī)器學(xué)習(xí)
+關(guān)注
關(guān)注
66文章
8453瀏覽量
133154 -
python
+關(guān)注
關(guān)注
56文章
4811瀏覽量
85099 -
數(shù)據(jù)科學(xué)
+關(guān)注
關(guān)注
0文章
168瀏覽量
10116
原文標(biāo)題:2018:數(shù)據(jù)科學(xué)20個(gè)最好的Python庫(kù)
文章出處:【微信號(hào):rgznai100,微信公眾號(hào):rgznai100】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
五大Python Web框架詳解
學(xué)python有哪些方向?
直擊DTCC2018 阿里數(shù)據(jù)庫(kù)技術(shù)干貨全面解析
python數(shù)據(jù)分析的類庫(kù)
Python就業(yè)狀況分析
Python十大應(yīng)用領(lǐng)域和就業(yè)方向
2021年最受工程師歡迎的技能:Python第一

了解數(shù)據(jù)科學(xué)Python庫(kù)
Python成為2018年度編程語(yǔ)言,理由如下





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論