") 簡(jiǎn)單介紹了強(qiáng)化學(xué)習(xí)的基本概念
簡(jiǎn)單介紹了強(qiáng)化學(xué)習(xí)的基本概念

由于Alpha Go的成功,強(qiáng)化學(xué)習(xí)始終是人們談?wù)摰慕裹c(diǎn)。現(xiàn)在Thomas Simonini在國(guó)外blog網(wǎng)站上發(fā)布了系列強(qiáng)化學(xué)習(xí)教程,以下是本系列的第一篇,簡(jiǎn)單介紹了強(qiáng)化學(xué)習(xí)的基本概念。
An introduction to Reinforcement Learning
我們基于TensorFlow制作了一門深度強(qiáng)化學(xué)習(xí)的視頻課程【1】,主要介紹了如何使用TensorFlow實(shí)現(xiàn)強(qiáng)化學(xué)習(xí)問題求解。
強(qiáng)化學(xué)習(xí)是機(jī)器學(xué)習(xí)的一種重要分支,通過“agent ”學(xué)習(xí)的方式,得出在當(dāng)前環(huán)境下所應(yīng)該采取的動(dòng)作,并觀察得到的結(jié)果。
最近幾年,我們見證了了許多研究領(lǐng)域的巨大進(jìn)展,例如包括2014年的“DeepMind and the Deep Q learning architecture”【2】,2016年的“beating the champion of the game of Go with AlphaGo”【3】,2017年的“OpenAI and the PPO”【4】
在這個(gè)系列文章中,我們將關(guān)注于深度學(xué)習(xí)問題中各類不同的求解方法。包括Q-learning,DeepQ-learning,策略梯度,ActorCritic,以及PPO。
在第一篇文章中,你將會(huì)學(xué)到:
強(qiáng)化學(xué)習(xí)是什么,為什么說“獎(jiǎng)勵(lì)”是最重要的思想。
強(qiáng)化學(xué)習(xí)的三個(gè)方法。
深度強(qiáng)化學(xué)習(xí)中的“深度”是什么意思?
在進(jìn)入深度學(xué)習(xí)實(shí)現(xiàn)的主題之前,一定要把這些元素弄清楚。
強(qiáng)化學(xué)習(xí)背后的思想是,代理(agent)將通過與環(huán)境(environment)的動(dòng)作(action)交互,進(jìn)而獲得獎(jiǎng)勵(lì)(reward)。
從與環(huán)境的交互中進(jìn)行學(xué)習(xí),這一思想來自于我們的自然經(jīng)驗(yàn),想象一下當(dāng)你是個(gè)孩子的時(shí)候,看到一團(tuán)火,并嘗試接觸它。
火很溫暖,你感覺很開心(獎(jiǎng)勵(lì)+1)。你就會(huì)覺得火是個(gè)好東西。
可一旦你嘗試去觸摸它。哎呦!火把你的手燒傷了(懲罰-1).你才明白只有與火保持一定距離,才會(huì)產(chǎn)生溫暖,才是個(gè)好東西,但如果太過靠近的話,就會(huì)燒傷自己。
這一過程是人類通過交互進(jìn)行學(xué)習(xí)的方式。強(qiáng)化學(xué)習(xí)是一種可以根據(jù)行為進(jìn)行計(jì)算的學(xué)習(xí)方法。
強(qiáng)化學(xué)習(xí)的過程
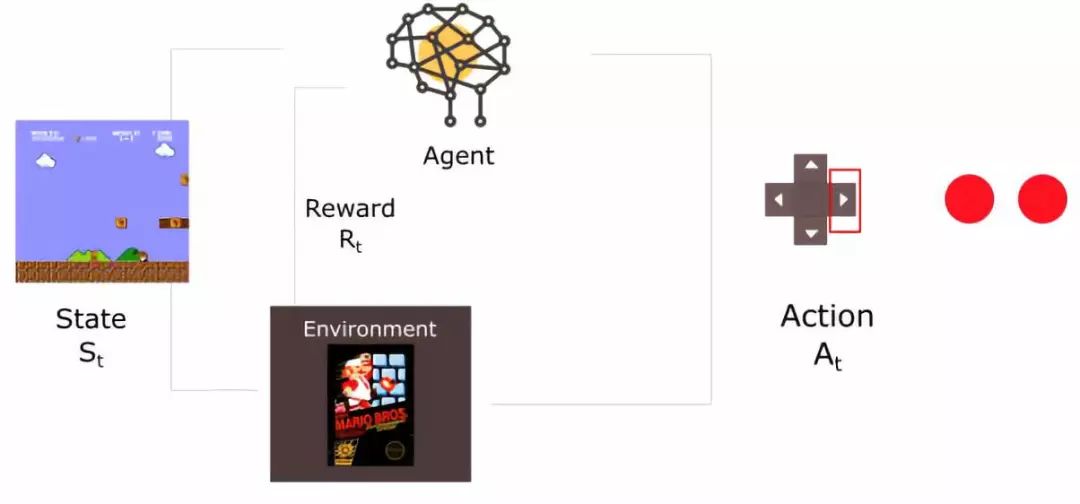
舉個(gè)例子,思考如何訓(xùn)練agent 學(xué)會(huì)玩超級(jí)瑪麗游戲。這一強(qiáng)化學(xué)習(xí)過程可以被建模為如下的一組循環(huán)過程。
agent從環(huán)境中接收到狀態(tài)S0。(此案例中,這句話意思是從超級(jí)瑪麗游戲中得到的第一幀信息)
基于狀態(tài)S0,agent執(zhí)行A0操作。(右移)
環(huán)境轉(zhuǎn)移至新狀態(tài)S1。(新一幀)
環(huán)境給予R1獎(jiǎng)勵(lì)。(沒死:+1)
強(qiáng)化學(xué)習(xí)循環(huán)輸出狀態(tài)、行為、獎(jiǎng)勵(lì)的序列。整體的目標(biāo)是最大化全局reward的期望。
獎(jiǎng)勵(lì)假設(shè)是核心思想
在強(qiáng)化學(xué)習(xí)中,為了得到最好的行為序列,我們需要最大化累積reward期望。
每個(gè)時(shí)間步的累積reward可以寫作:
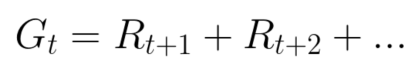
等價(jià)于:
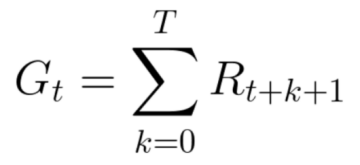
然而,在現(xiàn)實(shí)世界中,我們不能僅僅加入獎(jiǎng)勵(lì)。這種獎(jiǎng)勵(lì)來的太快,且發(fā)生的概率非常大,因此比起長(zhǎng)期獎(jiǎng)勵(lì)來說,更容易預(yù)測(cè)。

另一個(gè)例子中,agent 是老鼠,對(duì)手是貓,目標(biāo)是在被貓吃掉之前,先吃掉最多的奶酪。
從圖中可以看到,吃掉身邊的奶酪要比吃掉貓旁邊的奶酪,要容易許多。
由于一旦被貓抓住,游戲即將結(jié)束,因此,貓身邊的奶酪獎(jiǎng)勵(lì)會(huì)有衰減。
我們對(duì)折扣的處理如下所示(定義gamma為衰減比例,在0-1之間):
Gamma越大,衰減越小。這意味著agent 的學(xué)習(xí)過程更關(guān)注于長(zhǎng)期的回報(bào)。
另一方面,更小的gamma,會(huì)帶來更大的衰減。這意味著我們的agent 關(guān)心于短期的回報(bào)。
衰減后的累計(jì)獎(jiǎng)勵(lì)期望為:
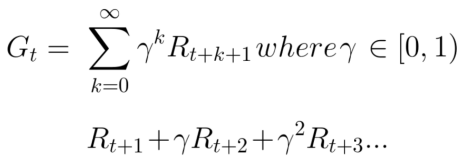
每個(gè)時(shí)間步間的獎(jiǎng)勵(lì)將與gamma參數(shù)相乘,獲得衰減后的獎(jiǎng)勵(lì)值。隨著時(shí)間步驟的增加,貓距離我們更近,因此為未來的獎(jiǎng)勵(lì)概率將變得越來越小。
事件型或者持續(xù)型任務(wù)
任務(wù)是強(qiáng)化學(xué)習(xí)問題中的基礎(chǔ)單元,我們可以有兩類任務(wù):事件型與持續(xù)型。
事件型任務(wù)
在這一情況中,我們有一個(gè)起始點(diǎn)和終止點(diǎn)(終止?fàn)顟B(tài))。這會(huì)創(chuàng)建一個(gè)事件:一組狀態(tài)、行為、獎(jiǎng)勵(lì)以及新獎(jiǎng)勵(lì)。
對(duì)于超級(jí)瑪麗的情況來說,一個(gè)事件從游戲開始進(jìn)行記錄,直到角色被殺結(jié)束。
持續(xù)型任務(wù)
持續(xù)型任務(wù)意味著任務(wù)不存在終止?fàn)顟B(tài)。在這一案例中,agent 將學(xué)習(xí)如何選擇最好的動(dòng)作,并與環(huán)境同步交互。
例如,通過agent 進(jìn)行自動(dòng)股票交易。在這個(gè)任務(wù)中,并不存在起始點(diǎn)和終止?fàn)顟B(tài),直到我們主動(dòng)終止之前,agent 將一直運(yùn)行下去。
蒙特卡洛與時(shí)間差分學(xué)習(xí)方法
接下來將學(xué)習(xí)兩種方法:
蒙特卡洛方法:在事件結(jié)束后收集獎(jiǎng)勵(lì),進(jìn)而計(jì)算未來獎(jiǎng)勵(lì)的最大期望。
時(shí)間差分學(xué)習(xí):在每一個(gè)時(shí)間步進(jìn)行估計(jì)計(jì)算。
蒙特卡洛方法
當(dāng)時(shí)間結(jié)束時(shí)(agent 達(dá)到“終止?fàn)顟B(tài)”),agent 將看到全部累積獎(jiǎng)勵(lì),進(jìn)而計(jì)算它將如何去做。在蒙特卡洛方法中,獎(jiǎng)勵(lì)只會(huì)在游戲結(jié)束時(shí)進(jìn)行收集。
從一個(gè)新游戲開始,agent 將會(huì)隨著迭代的進(jìn)行,完成更好的決策。

舉例如下:

如果我們?cè)谌缟檄h(huán)境中:
總是從相同位置開始
當(dāng)被貓抓到或者移動(dòng)超過20步時(shí),事件終止。
在事件的結(jié)尾,我們得到一組狀態(tài)、行為、獎(jiǎng)勵(lì)以及新狀態(tài)。
agent 將對(duì)整體獎(jiǎng)勵(lì)Gt求和。
基于上面的公式對(duì)V(st)求和
根據(jù)更新的認(rèn)知開始新的游戲
隨著執(zhí)行的事件越來越多,agent 學(xué)習(xí)的結(jié)果將越來越好。
時(shí)間查分學(xué)習(xí):每步更新
對(duì)于時(shí)序差分學(xué)習(xí),不需要等到每個(gè)事件終止便可以根據(jù)未來獎(jiǎng)勵(lì)的最大期望估計(jì)進(jìn)行更新。
這種方法叫做TD(0)或者單步TD方法(在每個(gè)步驟間隔進(jìn)行值函數(shù)更新)。
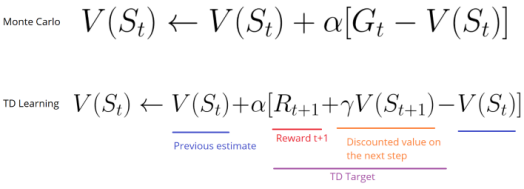
TD方法在每一步進(jìn)行值函數(shù)評(píng)估更新。在t+1時(shí),立刻觀察到獎(jiǎng)勵(lì)Rt+1,并得到當(dāng)前的評(píng)估值V(st+1)。
TD的目標(biāo)是得到評(píng)估值,并根據(jù)單步的估計(jì)值完成前一個(gè)估計(jì)值V(st)更新。
探索/開發(fā)間的平衡
在繼續(xù)了解其他細(xì)節(jié)之前,我們必須介紹一個(gè)非常重要的主題:探索與開發(fā)之間的平衡。
探索是為了發(fā)現(xiàn)環(huán)境的更多信息
開發(fā)是為了根據(jù)已知信息去最大化獎(jiǎng)勵(lì)值。
記住,我們agent 的目標(biāo)是為了最大化累積獎(jiǎng)勵(lì)的期望,然而,我們可能陷入到一個(gè)常見的陷阱中。

在游戲中,老鼠可以獲得無限的小奶酪(1次獲得1個(gè)),但在迷宮的上部,有一個(gè)超大的奶酪包裹(1次可獲得1000個(gè))。
然而,如果我們只關(guān)注于獎(jiǎng)勵(lì),agent 將永遠(yuǎn)無法達(dá)到奶酪包裹處。并且,它將會(huì)僅去探索最近的獎(jiǎng)勵(lì)來源,即使這個(gè)獎(jiǎng)勵(lì)特別小(開發(fā),exploitation)。
但如果agent 進(jìn)行一點(diǎn)小小的探索工作,就有可能獲得更大的獎(jiǎng)勵(lì)。
這就是探索與開發(fā)的平衡問題。我們必須定義出一個(gè)規(guī)則,幫助agent 去解決這個(gè)平衡。我們將在未來文章中通過不同策略去解決這一問題。
強(qiáng)化學(xué)習(xí)的三種方法
現(xiàn)在我們定義了強(qiáng)化學(xué)習(xí)的主要元素,接下來將介紹三種解決強(qiáng)化學(xué)習(xí)問題的方法,包括基于值的方法、基于策略的方法與基于模型的方法。
基于值的方法
在基于值的強(qiáng)化學(xué)習(xí)方法中,目標(biāo)是優(yōu)化值函數(shù)V(s)。
值函數(shù)的作用是,告訴我們?cè)诿總€(gè)狀態(tài)下,未來最大化的獎(jiǎng)勵(lì)期望。
值是每個(gè)狀態(tài)條件下,從當(dāng)前開始,在未來所能取得的最大總回報(bào)的值。
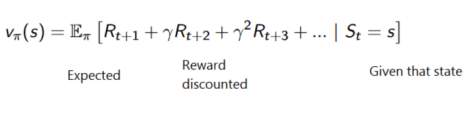
agent 將使用值函數(shù)去在每一步選擇采用哪個(gè)狀態(tài)。
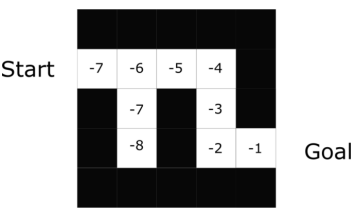
在迷宮問題中,在每一步將選擇最大值:-7,-6,-5等等。
基于策略的方法
在基于策略的強(qiáng)化學(xué)習(xí)方法中,我們希望能直接優(yōu)化策略函數(shù)π(s)。
策略的定義是,在給定時(shí)間的agent 行為。

通過學(xué)習(xí)到策略函數(shù),可以讓我們對(duì)每個(gè)狀態(tài)映射出最好的相關(guān)動(dòng)作。
兩種策略:
確定策略:在給定狀態(tài)下總是返回相同動(dòng)作。
隨機(jī)策略:輸出一個(gè)動(dòng)作的概率分布。
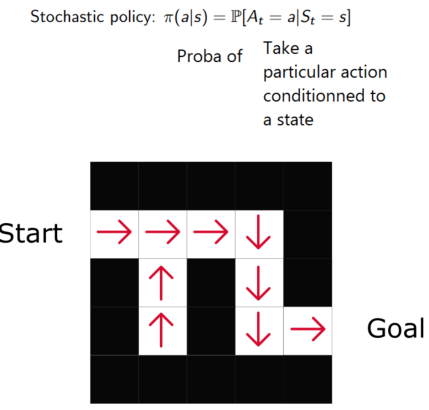
如同我們看到的,策略直接指出了每一步的最優(yōu)行為。
基于模型的方法
在基于模型的強(qiáng)化學(xué)習(xí)中,我們對(duì)環(huán)境建模,這意味著我們創(chuàng)造了環(huán)境的模型。
問題是,每種行為都需要不同的模型表示,這就是為什么在接下來的文章中并沒有提及此類方法的原因。
深度強(qiáng)化學(xué)習(xí)的介紹
深度強(qiáng)化學(xué)習(xí)采用深度神經(jīng)網(wǎng)絡(luò)以解決強(qiáng)化學(xué)習(xí)問題。
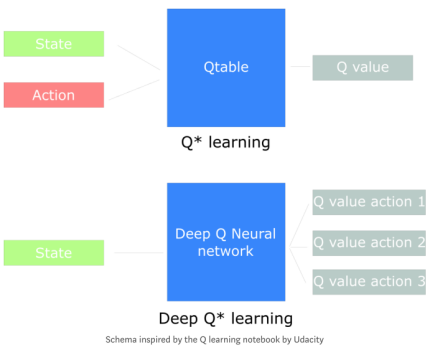
在例子中,在下一篇文章我們將采用Q-learning與深度Q-learning。
你將會(huì)看到顯著地不同,在第一種方法中,我們將使用一個(gè)傳統(tǒng)算法那去創(chuàng)建Q值表,以幫助我們找到每種狀態(tài)下應(yīng)采用的行為。第二種方法中,我們將使用神經(jīng)網(wǎng)絡(luò)(得到某狀態(tài)下的近似獎(jiǎng)勵(lì):Q值)。
這篇文章里有很多信息,在繼續(xù)進(jìn)行之前,一定要真正掌握住基礎(chǔ)知識(shí)。
重點(diǎn):這篇文章是這一免費(fèi)的強(qiáng)化學(xué)習(xí)博文專欄的第一部分。關(guān)于更多的資源,見此鏈接【5】.
下一次我們將基于Q-learning訓(xùn)練agent 去玩FrozenLake游戲。
-
深度學(xué)習(xí)
+關(guān)注
關(guān)注
73文章
5561瀏覽量
122805 -
強(qiáng)化學(xué)習(xí)
+關(guān)注
關(guān)注
4文章
269瀏覽量
11604 -
tensorflow
+關(guān)注
關(guān)注
13文章
330瀏覽量
61186
原文標(biāo)題:【干貨】強(qiáng)化學(xué)習(xí)介紹
文章出處:【微信號(hào):AItists,微信公眾號(hào):人工智能學(xué)家】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
NVIDIA Isaac Lab可用環(huán)境與強(qiáng)化學(xué)習(xí)腳本使用指南

18個(gè)常用的強(qiáng)化學(xué)習(xí)算法整理:從基礎(chǔ)方法到高級(jí)模型的理論技術(shù)與代碼實(shí)現(xiàn)

詳解RAD端到端強(qiáng)化學(xué)習(xí)后訓(xùn)練范式

WIFI的基本概念介紹
自然語言處理與機(jī)器學(xué)習(xí)的關(guān)系 自然語言處理的基本概念及步驟
多芯片封裝的基本概念和關(guān)鍵技術(shù)
螞蟻集團(tuán)收購(gòu)邊塞科技,吳翼出任強(qiáng)化學(xué)習(xí)實(shí)驗(yàn)室首席科學(xué)家
如何使用 PyTorch 進(jìn)行強(qiáng)化學(xué)習(xí)
Linux應(yīng)用編程的基本概念
X電容和Y電容的基本概念
谷歌AlphaChip強(qiáng)化學(xué)習(xí)工具發(fā)布,聯(lián)發(fā)科天璣芯片率先采用
集電極開路的基本概念與原理





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論