") 如何讓多個(gè)智能體學(xué)會(huì)一起完成同一個(gè)任務(wù),學(xué)會(huì)彼此合作和相互競(jìng)爭(zhēng)
如何讓多個(gè)智能體學(xué)會(huì)一起完成同一個(gè)任務(wù),學(xué)會(huì)彼此合作和相互競(jìng)爭(zhēng)

當(dāng)前人工智能最大的挑戰(zhàn)之一,是如何讓多個(gè)智能體學(xué)會(huì)一起完成同一個(gè)任務(wù),學(xué)會(huì)彼此合作和相互競(jìng)爭(zhēng)。在發(fā)表于ICML 2018的一項(xiàng)研究中,倫敦大學(xué)學(xué)院汪軍教授團(tuán)隊(duì)利用平均場(chǎng)論來(lái)理解大規(guī)模多智能體交互,極大地簡(jiǎn)化了交互模式。他們提出的新方法,能夠解決數(shù)量在成百上千甚至更多的智能體的交互,遠(yuǎn)遠(yuǎn)超過(guò)了所有當(dāng)前多智能體強(qiáng)化學(xué)習(xí)算法的能力范圍。
柯潔揮淚烏鎮(zhèn)一周年,AI已經(jīng)重新書寫了圍棋的歷史。而創(chuàng)造出地球上最強(qiáng)棋手AlphaGo系列的DeepMind,早已經(jīng)將目光轉(zhuǎn)向下一個(gè)目標(biāo)——星際爭(zhēng)霸。
玩星際爭(zhēng)霸,需要AI在不確定的情況下進(jìn)行推理與規(guī)劃,涉及多個(gè)智能體協(xié)作完成復(fù)雜的任務(wù),權(quán)衡短中長(zhǎng)期不同的收益。相比下圍棋這樣的確定性問(wèn)題,星際爭(zhēng)霸的搜索空間要高出10個(gè)數(shù)量級(jí)。
從現(xiàn)實(shí)意義上來(lái)說(shuō),研究多智能體協(xié)作也具有廣泛的應(yīng)用場(chǎng)景。例如,股票市場(chǎng)上的交易機(jī)器人博弈,廣告投標(biāo)智能體通過(guò)在線廣告交易平臺(tái)互相競(jìng)爭(zhēng),電子商務(wù)協(xié)同過(guò)濾推薦算法預(yù)測(cè)用戶興趣,等等。
倫敦大學(xué)學(xué)院(UCL)計(jì)算機(jī)科學(xué)系教授汪軍博士及其團(tuán)隊(duì)一直從事多智能體協(xié)作的研究。汪軍教授認(rèn)為,目前通用人工智能(AGI)研究有兩個(gè)大方向,一是大家熟知的AlphaGo,這是單智體,其背后的經(jīng)典算法是深度強(qiáng)化學(xué)習(xí);另一個(gè)就是多智體(Multi-agent),也可以理解為集體智能,這是人工智能的下一個(gè)大方向。
目前,人工智能最大的挑戰(zhàn)之一,就是如何讓多個(gè)智能體學(xué)會(huì)一起完成同一個(gè)任務(wù),學(xué)會(huì)彼此合作和相互競(jìng)爭(zhēng)。如何利用一套統(tǒng)一的增強(qiáng)學(xué)習(xí)框架去描述這個(gè)學(xué)習(xí)過(guò)程。
研究負(fù)責(zé)人、倫敦大學(xué)學(xué)院(UCL)的汪軍教授
在一項(xiàng)最新的研究中,汪軍和他的團(tuán)隊(duì)利用平均場(chǎng)論來(lái)理解大規(guī)模多智能體交互,極大地簡(jiǎn)化了交互模式,讓計(jì)算量大幅降低。他們提出的新方法,能夠解決數(shù)量在成百上千甚至更多的智能體的交互,遠(yuǎn)遠(yuǎn)超過(guò)了所有當(dāng)前多智能體強(qiáng)化學(xué)習(xí)算法的能力范圍。相關(guān)論文已經(jīng)被ICML 2018接收,作者將在7月13日下午5點(diǎn)在ICML會(huì)場(chǎng)做報(bào)告,歡迎大家去現(xiàn)場(chǎng)交流。
“我們發(fā)現(xiàn)在處理大規(guī)模智能體學(xué)習(xí)時(shí),把多體問(wèn)題抽象成二體問(wèn)題是一種有效的方法,”論文作者Yaodong Yang告訴新智元:“這個(gè)想法的初衷異常簡(jiǎn)單,就是把環(huán)境中所有領(lǐng)域內(nèi)其他智能體對(duì)中心個(gè)體的影響,僅僅用一個(gè)它們的均值來(lái)抽象,而不用一一分別考慮建模。”
他們?cè)O(shè)計(jì)的平均場(chǎng)Q-learning算法成功模擬并求解了物理領(lǐng)域的伊辛模型(ising model)。Yaodong表示:“用強(qiáng)化學(xué)習(xí)的框架可以解決物理學(xué)中的伊辛模型,這一發(fā)現(xiàn)非常令人振奮。”
上海交通大學(xué)張偉楠助理教授團(tuán)隊(duì)也積極參與了此次工作,張偉楠認(rèn)為:“使用平均場(chǎng)計(jì)算領(lǐng)域智能體的行動(dòng)分布,并整合于強(qiáng)化學(xué)習(xí)中在計(jì)算上十分高效,在不同算法互相對(duì)戰(zhàn)的實(shí)驗(yàn)中,平均場(chǎng)Q-learning算法能穩(wěn)定提高群體智能的效果,在battle中碾壓傳統(tǒng)多智能體強(qiáng)化學(xué)習(xí)的算法。”

在一個(gè)混合式的合作競(jìng)爭(zhēng)性戰(zhàn)斗游戲中,研究人員證明了平均場(chǎng)MARL相對(duì)其他多智能體系統(tǒng)的基線獲得了更高的勝率。其中,藍(lán)方是平均場(chǎng)Q-learning算法,紅方是傳統(tǒng)的強(qiáng)化學(xué)習(xí)算法DQN。
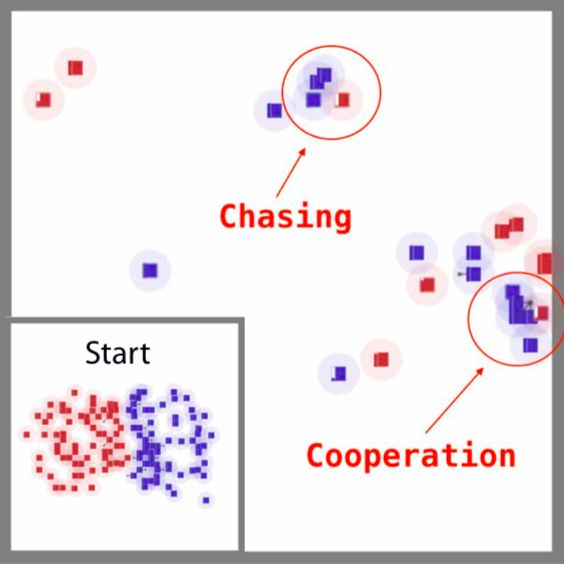
對(duì)戰(zhàn)局部,agent彼此間的合作與競(jìng)爭(zhēng)。
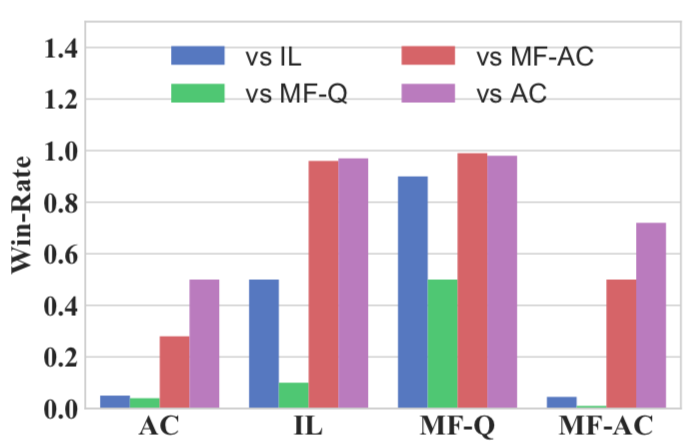
對(duì)戰(zhàn)結(jié)果:經(jīng)過(guò)2000多輪比較實(shí)驗(yàn),新提出的平均場(chǎng)Q-learning算法(MF-Q)相對(duì)于其他傳統(tǒng)強(qiáng)化學(xué)習(xí)算法的勝率(綠色)。很明顯,在所有的指標(biāo)中,MF-Q的勝率都高出一大截。
由于大幅降低了計(jì)算量,他們的方法可以推廣用于很多實(shí)際場(chǎng)景,比如終端通訊設(shè)備流量分配,互聯(lián)網(wǎng)廣告競(jìng)價(jià)排名,智能派單等大規(guī)模分布式優(yōu)化場(chǎng)景中。
用平均場(chǎng)論解決大規(guī)模多智能體交互,大幅簡(jiǎn)化計(jì)算
多智體強(qiáng)化學(xué)習(xí)(Multi-agent reinforcement learning, MARL)假設(shè)有一組處在相同環(huán)境下的自主智能體。在MARL中學(xué)習(xí)非常困難,因?yàn)閍gent不僅與環(huán)境交互,而且還會(huì)相互作用:一個(gè)agent的策略變化會(huì)影響其他agent的策略,反之亦然。
例如,在星際爭(zhēng)霸中,讓一組20個(gè)agent去攻擊另外一組的20個(gè)agent,每個(gè)agent就要考慮周圍39個(gè)agents的行為從而做出最優(yōu)決策。對(duì)于每個(gè)個(gè)體來(lái)說(shuō),要學(xué)會(huì)理解的狀態(tài)空間是很龐大的,這還不包括其他智能體在探索環(huán)境時(shí)產(chǎn)生的噪聲。當(dāng)agent增多到1000乃至上萬(wàn)個(gè)時(shí),情況就變得超級(jí)復(fù)雜,現(xiàn)有的多智能體強(qiáng)化學(xué)習(xí)算法有很大局限性,也沒(méi)有那么大的計(jì)算力。
但是,推測(cè)其他agent的策略來(lái)計(jì)算額外的信息,對(duì)每個(gè)agent自身是有好處的。研究表明,一個(gè)學(xué)習(xí)了聯(lián)合行動(dòng)效應(yīng)的agent,比那些沒(méi)有學(xué)習(xí)的agent表現(xiàn)更好,無(wú)論是在合作博弈、零和隨機(jī)博弈和一般和隨機(jī)博弈中,情況都是如此。這也很好理解,知彼知己,才能百戰(zhàn)不殆。
因此,結(jié)果就是,現(xiàn)有的均衡求解方法雖然可行,但只能解決少數(shù)agent的問(wèn)題,大部分的實(shí)驗(yàn)還局限于兩個(gè)agent之間的博弈。而在實(shí)踐當(dāng)中,卻常常會(huì)需要有大量agent之間的策略互動(dòng)。
如何解決這個(gè)問(wèn)題?UCL的研究者想到了平均場(chǎng)論。
平均場(chǎng)論(Mean Field Theory,MFT)是一種研究復(fù)雜多體問(wèn)題的方法。在物理學(xué)場(chǎng)論和機(jī)器學(xué)習(xí)的變分推斷中,平均場(chǎng)論是對(duì)大且復(fù)雜的隨機(jī)模型的一種簡(jiǎn)化。未簡(jiǎn)化前的模型通常包含巨大數(shù)目的含相互作用的小個(gè)體。平均場(chǎng)理論則做了這樣的近似:對(duì)某個(gè)獨(dú)立的小個(gè)體,所有其他個(gè)體對(duì)它產(chǎn)生的作用可以用一個(gè)平均的量給出,這樣,簡(jiǎn)化后的模型對(duì)于每個(gè)個(gè)體就成了一個(gè)單體問(wèn)題。
在他們的研究中,UCL團(tuán)隊(duì)沒(méi)有去分別考慮單個(gè)智能體對(duì)其他個(gè)體產(chǎn)生的不同影響,而是將領(lǐng)域內(nèi)所有其他個(gè)體的影響用一個(gè)均值來(lái)代替。這樣,對(duì)于每個(gè)個(gè)體,只需要考慮個(gè)體和這個(gè)均值的交互作用就行了。這種抽象的方法,當(dāng)研究對(duì)象大到無(wú)法表達(dá)的時(shí)候尤其有用。
平均場(chǎng)論的方法能快速收斂,用強(qiáng)化學(xué)習(xí)解決伊辛模型
應(yīng)用平均場(chǎng)論后,學(xué)習(xí)在兩個(gè)智能體之間是相互促進(jìn)的:?jiǎn)蝹€(gè)智能體的最優(yōu)策略的學(xué)習(xí)是基于智能體群體的動(dòng)態(tài);同時(shí),集體的動(dòng)態(tài)也根據(jù)個(gè)體的策略進(jìn)行更新。
在此基礎(chǔ)上,研究人員提出了平均場(chǎng)Q-learning算法(MF-Q)和平均場(chǎng)Actor-Critic算法(MF-AC),并通過(guò)伊辛模型驗(yàn)證了它們的解是否能夠快速收斂。
易辛模型(Ising model),是一個(gè)以物理學(xué)家恩斯特·易辛為名的數(shù)學(xué)模型,用于描述物質(zhì)的鐵磁性。該模型中包含了可以用來(lái)描述單個(gè)原子磁矩的參數(shù),其值只能為+1或-1,分別代表自旋向上或向下(在多智能體的情況下,就是向上或者向下移動(dòng))。這些磁矩通常會(huì)按照某種規(guī)則排列,形成晶格,并在模型中引入特定交互作用的參數(shù),使得相鄰的自旋互相影響。
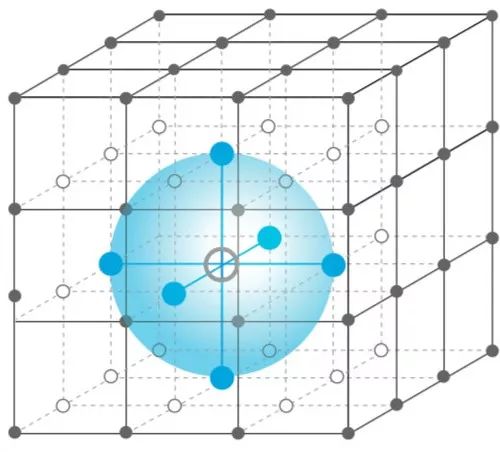
平均場(chǎng)近似。每個(gè)agent都表示為網(wǎng)格中的一個(gè)節(jié)點(diǎn),它只受鄰居(藍(lán)色區(qū)域)的平均效果影響。多個(gè)agents相互作用被有效地轉(zhuǎn)換為兩個(gè)代理的相互作用。
雖然伊辛模型相對(duì)于物理現(xiàn)實(shí)是一個(gè)相當(dāng)簡(jiǎn)化的模型,但它卻和鐵磁性物質(zhì)一樣,在不同溫度下會(huì)產(chǎn)生相變。事實(shí)上,一個(gè)二維的方晶格易辛模型是已知最簡(jiǎn)單而且會(huì)產(chǎn)生相變的物理系統(tǒng)。在這個(gè)場(chǎng)景下, 雖然每一個(gè)磁矩對(duì)整個(gè)磁體的性質(zhì)的影響非常有限, 但是通過(guò)微觀的相互作用, 磁矩之間卻會(huì)形成宏觀的趨勢(shì), 而這種趨勢(shì)能夠決定我們所關(guān)心的整體磁場(chǎng)的性質(zhì)。
在多智體強(qiáng)化學(xué)習(xí)這個(gè)領(lǐng)域,特定的任務(wù)可以被有效的抽象為同質(zhì)智能體(homogeneous agent)之間的相互學(xué)習(xí)以及博弈的過(guò)程。
在平均場(chǎng)多智體伊辛模型中,網(wǎng)格中的每個(gè)agent向上和向下的獎(jiǎng)勵(lì)是不同的,如果最終能讓所有agent都朝同一個(gè)方向移動(dòng)(都變?yōu)楹谏簿捅砻髁似骄鶊?chǎng)方法能夠比較快速的收斂。通過(guò)下面的動(dòng)圖,可以更直觀地看到這種快速收斂的效果。
研究難點(diǎn)及未來(lái)方向
研究人員表示,這項(xiàng)工作有兩方面的難點(diǎn)。首先是理論部分,只有一套嚴(yán)格自洽的理論才能作為后續(xù)實(shí)驗(yàn)以及分析的基礎(chǔ)。在將平均場(chǎng)論融入多智體強(qiáng)化學(xué)習(xí)的過(guò)程中,他們利用了不同領(lǐng)域里的多項(xiàng)理論,包括平均場(chǎng)論的近似化方法,在stochastic games中的納什均衡學(xué)習(xí)理論(nash q learning),不動(dòng)點(diǎn)分析,以及最優(yōu)化理論中的壓縮映射(contraction mapping)。最后,理論證明了他們所提出的平均場(chǎng)強(qiáng)化學(xué)習(xí)在一些溫和條件的收斂性,并且提供了近似化中誤差的上下界 。
另一方面的難點(diǎn)在于實(shí)驗(yàn),由于目前沒(méi)有良好的針對(duì)多智體強(qiáng)化學(xué)習(xí)的測(cè)試平臺(tái),團(tuán)隊(duì)設(shè)計(jì)構(gòu)建了一個(gè)實(shí)驗(yàn)環(huán)境,用于提供必要的測(cè)試條件。
研究人員表示,據(jù)他們所知,某些大廠已經(jīng)在實(shí)驗(yàn)室階段實(shí)現(xiàn)了他們的算法,用于大規(guī)模派單和通訊設(shè)備流量分配。因?yàn)檫@個(gè)算法適合處理的特定問(wèn)題是大規(guī)模智能體,并且每個(gè)智能體都有相同程度的相似性,實(shí)際應(yīng)用的場(chǎng)景會(huì)非常廣闊,例如廣告競(jìng)價(jià)、智能城市等等。
目前,關(guān)于多智能體的深度強(qiáng)化學(xué)習(xí)上,理論層面還是沒(méi)有看到太多的發(fā)展。這個(gè)領(lǐng)域缺乏一個(gè)大家都認(rèn)可的理論框架。例如,多智能體在學(xué)習(xí)的時(shí)候目標(biāo)函數(shù)到底應(yīng)該是什么,是否應(yīng)該是納什均衡,還有很多爭(zhēng)論。
更有學(xué)者認(rèn)為,多智能體學(xué)習(xí)不應(yīng)該專注個(gè)體的決策,反而應(yīng)該從種群的角度去理解,也就是演化博弈論(evolutionary game theory)的理論框架。演化博弈論認(rèn)為,關(guān)注的重心應(yīng)該是一個(gè)種群里選擇某些行動(dòng)的agent的比例是不是在進(jìn)化意義上是穩(wěn)定的,也就是evolutionary stable strategies的想法。
對(duì)此,UCL團(tuán)隊(duì)的研究人員認(rèn)為,他們接下來(lái)將進(jìn)一步完善理論和實(shí)驗(yàn)方法,探索潛在的實(shí)際應(yīng)用。
論文:平均場(chǎng)多智體強(qiáng)化學(xué)習(xí)
摘要
現(xiàn)有的多智體(multi-agent)強(qiáng)化學(xué)習(xí)方法通常限制于少數(shù)的智能體(agent)。當(dāng)agent的數(shù)量增加很多時(shí),由于維數(shù)以及agent之間交互的指數(shù)級(jí)的增長(zhǎng),學(xué)習(xí)變得很困難。
在這篇論文中,我們提出平均場(chǎng)強(qiáng)化學(xué)習(xí)(Mean FieldReinforcement Learning),其中,agent群體內(nèi)的交互以單個(gè)agent和總體或相鄰agent的平均效應(yīng)之間的交互來(lái)近似;兩個(gè)實(shí)體之間的相互作用是相互加強(qiáng)的:個(gè)體agent的最佳策略的學(xué)習(xí)取決于總體的動(dòng)態(tài),而總體的動(dòng)態(tài)則根據(jù)個(gè)體策略的集體模式而變化。
我們提出了使用的平均場(chǎng) Q-learning 算法和平均場(chǎng) Actor-Critic算法,并分析了納什均衡解的收斂性。Gaussian squeeze、伊辛模型(Ising model)和戰(zhàn)斗游戲的實(shí)驗(yàn),證明了我們的平均場(chǎng)方法的學(xué)習(xí)有效性。此外,我們還通過(guò)無(wú)模型強(qiáng)化學(xué)習(xí)方法報(bào)告了解決伊辛模型的第一個(gè)結(jié)果。
-
人工智能
+關(guān)注
關(guān)注
1805文章
48899瀏覽量
247987 -
智能體
+關(guān)注
關(guān)注
1文章
288瀏覽量
11022 -
強(qiáng)化學(xué)習(xí)
+關(guān)注
關(guān)注
4文章
269瀏覽量
11553
原文標(biāo)題:UCL汪軍團(tuán)隊(duì)新方法提高群體智能,解決大規(guī)模AI合作競(jìng)爭(zhēng)
文章出處:【微信號(hào):AI_era,微信公眾號(hào):新智元】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
請(qǐng)問(wèn)怎么在同一個(gè)PCB文件中設(shè)計(jì)多個(gè)PCB板?
一個(gè)APP如何控制多個(gè)智能硬件
請(qǐng)問(wèn)ucosIII多個(gè)任務(wù)等待同一個(gè)信號(hào)量該怎么辦?
多個(gè)任務(wù)一起創(chuàng)建時(shí)使用同一個(gè)err會(huì)不會(huì)有問(wèn)題?
UCOSii多個(gè)任務(wù)能不能使用同一個(gè)互斥信號(hào)量?
四大科技巨頭都如何利用AI來(lái)相互競(jìng)爭(zhēng)
未來(lái)機(jī)器人將和人們一起工作一起學(xué)習(xí)
如何讓RTOS多任務(wù)訪問(wèn)同一個(gè)UART?
SS-431 使多個(gè) Modbus 設(shè)備如同一個(gè)設(shè)備被訪問(wèn)

FPGA中電源管腳在同一個(gè)BANK為何需要多個(gè)引腳?

兩個(gè)網(wǎng)絡(luò)IP地址是否在同一個(gè)段中的判斷方法





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論