 如何簡單快速的來打造MCU性能分析利器的詳細資料概述
如何簡單快速的來打造MCU性能分析利器的詳細資料概述
說出來不確定大家信不信,實現起來也就70來行算上大括號的代碼,是不是很激動人心?
言歸正傳,再小的程序,也是數據結構+代碼。咱們先來由表及里地看看核心數據結構的樣子。
首先,既然要從Cortex-M核在響應中斷時自動入棧的信息采集PC,就必須了解自動入棧了些啥東東:

這里可以看出Cortex-M內核自動壓入了8個寄存器,右二那個不起眼的pc,正是一號主角。對自動入棧不太了解的小伙伴,可以查看《Cortex-M3權威指南》第9章的介紹
(https://github.com/RockySong/cm3_def_guide_cn)
理論上pc可以是任何指令位置。不幸的是一般工程生成的指令數常常在幾萬甚至幾十萬條,難道都要記錄下來?估計天價的開發工具也不會這么做。常言說“首惡必辦,協從不問”,咱們做profiling,也沒必要統計出PC在所有指令上的分布密度,只要抓幾個大頭就夠了。還有個麻煩的,是一個函數可以有多個指令,函數長度可以相差巨大,而且在一個大函數里不同區域的覆蓋密度也不同。過日子還需要精打細算呀,咱們權衡打擊精度與彈藥消耗量,使用2個宏來決定配置,比如:

第1個宏PROF_CNT決定了抓多少個大頭,第2個宏PROF_ERR決定了網眼的大小——抓取的地址范圍(也就是最大誤差),在這個范圍內的地址都計作同一個地址塊。顯然,PROF_CNT越多,PROF_ERR越小,抓取的就越多越精確,也就更接近高檔的分析工具。值得一表的是,如果PROF_ERR夠小,可以在較大的函數中抓出更消耗性能的位置。
第3個宏PROF_MASK又是什么鬼?這其實是個工具宏,用來把地址向下對齊到誤差范圍的邊界,這也意味著PROF_ERR必須是2的整數次冪,這么做是避免消耗性能的取模運算。
下面請出關鍵的數據結構:性能分析的PC統計單元:

很顯然,PROF_CNT是多少,就應該有多少個ProfUnit_t實例。結構中,hitCnt是關鍵的參數,它統計了這個對齊后的PC地址”baseAddr”被采集到了多少次,”hitRatio”則是一個對人類友好的輔助變量,提供千分數(其實是1024級)精度的CPU占用率。
此外,還有個非常有用的小細節。比如,小伙伴們可能也注意到了,CPU占用率也是有時效性的。就像一個漫長的初始化可能讓一些查詢等待的函數紅極一時,但在之前越是弄得滿城風雨,程序主體運行后往往越是無聲無息,甚至都沒機會再運行一遍。
而即使在正常運行期間,不同時段開啟的功能不同,常常出現“皇帝輪流做,明年到我家”。因此,咱們可以加一點衰減處理,也就是定期對于非0的hitCnt進行扣除一格,如果沒有后續源源不斷的再次命中,就會漸漸走下神壇直至跌出排行榜。這樣可以提高統計結果的實時性。衰減機制的思路也很簡單,就是輪流從hitCnt非0的各個PC樣本點去扣。
綜合上面的如意算盤,定義了如下統領全局的結構體:
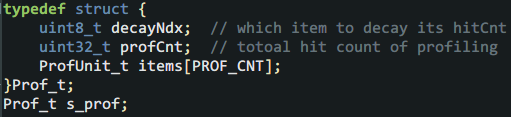
這個結構里decayNdx表示下次統計時從誰身上扣除hitCnt,每一次扣除后就輪轉到后面的item上,以公平公正。profCnt則表示已經做了多少次profiling統計,用于計算命中率,而items則是上文介紹的PC樣本統計單元。這里也有個小細節,就是在應用衰減來扣除每個item的hitCnt時,profCnt也需要扣除。
好了,有了完整的數據結構,該寫代碼了。從易到難,咱們可以先處理命中時的動作。
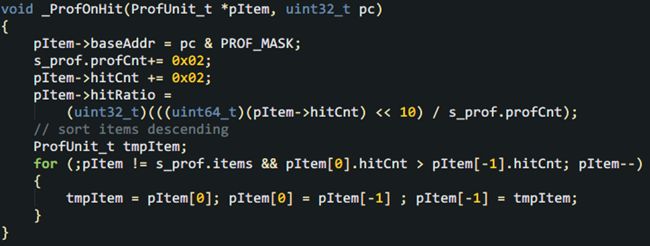
代碼很簡單,記錄地址,增加hitCnt,計算hitRate,再實時地“冒泡”,把最多hitCnt的item頂上去,排序的目的也是為了便于突出重點,對人類查看友好。這里每次hitCnt加2,是為了讓衰減得沒有增加的快,“過氣”得緩慢點,小伙伴們可以根據需要調節增加量。
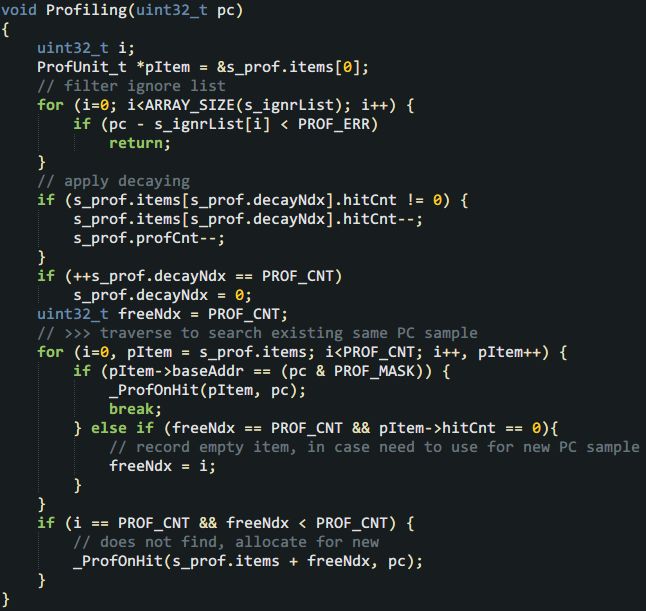
再剩下的就是最復雜的主函數了——說是復雜也就不到40行的代碼。要在主函數里先應用衰減,然后檢查這次的PC樣本是否已有記錄。如有記錄就調用上面的_ProfOnHit(),如無記錄則在一個hitCnt為0的item上記錄這個新PC樣本,也是調用_ProfOnHit()。此外,為了避免把idle函數和一些不想關心的函數也記錄下來,程序還支持一個“忽略列表”,凡是位于忽略列表地址范圍的PC樣本都不理會。
大功告成!接下來就是要使用了。使用非常簡單,只需在定時器中斷服務程序的主體中調用Profiling()并告訴它進入定時器中斷時pc寄存器的值。為了獲取入棧的PC,這個需要一點Cortex-M的基礎知識和手寫匯編。下面給出KEIL下的匯編入口:
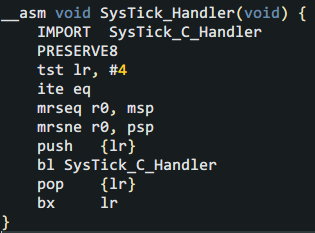
這個小程序先查出中斷前使用的棧指針并以作為參數傳遞給C語言主體“SysTick_C_Handler”。如果小伙伴們對這段匯編看不明白,就直接用就可以。
C語言主體的使用方式如下:

在使用的時候,咱們就進入開發工具的調試會話,讓程序跑一會,再停下來。如果是在KEIL或IAR中,可以使用memory窗口或watch窗口觀察s_prof.items。如果使用了GDB,可以輸入命令p/a s_prof.items。查看排名靠前的item,對照map文件即可估計出函數的名字和大致位置。值得一表的是,GDB下會自動解析出地址所對應的函數名,不用再讓咱們手動查map,非常貼心!
回顧理論篇介紹的幾個小坑,當查到一個不合理的地址時,先別激動,看看是不是小坑中的之一。如果確定不是,就有必要深入處理了。
到了這里,這期性能分析的話題的理論和實踐的故事就講完了。
等等,似乎還有什么沒交待完。試想,當我們一一找出最耗CPU資源的函數后,倘若束手無策,那也是徒勞無功,我們必須有對付他們的辦法。其中一項省力而又見效快的辦法就是把它們放在執行性能更高的位置中去,也就是前面說的VIP區。下次,咱們就介紹一下各種VIP區的特點,以及升V的方法!敬請繼續關注!
-
mcu
+關注
關注
146文章
17883瀏覽量
361495 -
分析器
+關注
關注
0文章
93瀏覽量
12685 -
數據結構
+關注
關注
3文章
573瀏覽量
40641
原文標題:70行代碼來打造MCU性能分析利器!
文章出處:【微信號:mcuworld,微信公眾號:嵌入式資訊精選】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄

如何修改Muto軟件來運行自己的StaseSimo Foc板的詳細資料概述
如何利用LM3447來進行非隔離調光GU10電源的詳細資料圖解概述
如何運用TI的LM3447來設計7W可調光LED球泡燈Demo的詳細資料概述
SV601187的詳細資料合集包括了電路圖,原理圖和介紹等詳細資料概述
逆變器的原理和詳細資料概述
CAN總線基礎的詳細資料概述







 工商網監
工商網監
評論