 采用LZ77算法壓縮數據與實現分析
采用LZ77算法壓縮數據與實現分析

LZ77簡介
Ziv和Lempel于1977年發表題為“順序數據壓縮的一個通用算法(A Universal Algorithm for Sequential Data Compression )”的論文,論文中描述的算法被后人稱為LZ77算法。值得說的是,LZ77嚴格意義上來說不是一種算法,而是一種編碼理論。同Huffman編碼一樣,只定義了原理,并沒有定義如何實現。基于這種理論來實現的算法才稱為LZ77算法,或者人們更愿意稱為LZ77變種。實際上這類算法已經有很多了,比如LZSS、LZB、LZH等。至今,幾乎我們日常使用的所有通用壓縮工具,象ARJ,PKZip,WinZip,LHArc,RAR,GZip,ACE,ZOO,TurboZip,Compress,JAR??甚至許多硬件如網絡設備中內置的壓縮算法,無一例外,都可以最終歸結為這兩個以色列人的杰出貢獻。
LZ77是一種基于字典的算法,它將長字符串(也稱為短語)編碼成短小的標記,用小標記代替字典中的短語,從而達到壓縮的目的。也就是說,它通過用小的標記來代替數據中多次重復出現的長串方法來壓縮數據。其處理的符號不一定是文本字符,可以是任意大小的符號。
短語字典的維護
不同的基于字典的算法使用不同的方法來維護它們的字典。LZ77使用的是一個前向緩沖區和一個滑動窗口。
LZ77首先將一部分數據載入前向緩沖區。為了便于理解前向緩沖區如何存儲短語并形成字典,我們將緩沖區描繪成S1,…,Sn的字符序列,Pb是由字符組成的短語集合。從字符序列S1,…,Sn,組成n個短語,定義如下:
Pb= {(S1),(S1,S2),…,(S1,…,Sn)}
例如,如果前向緩沖區包含字符(A,B,D),那么緩沖區中的短語為{(A),(A,B),(A,B,D)}。
一旦數據中的短語通過前向緩沖區,那么它將移動到滑動窗口中,并變成字典的一部分。為理解短語是如何在滑動窗口中表示的,首先,把窗口想象成S1,…,Sm的字符序列,且Pw是由這些字符組成的短語集合。從序列S1,…,Sm產生短語數據集合的過程如下:
Pw= {P1,P2,…,Pm},其中Pi= {(Si),(Si,Si+1),…,(Si,Si+1,…,Sm)}
例如,如果滑動窗口中包含符號(A,B,C),那么窗口和字典中的短語為{(A),(A,B),(A,B,C),(B),(B,C),(C)}。
LZ77算法的主要思想就是在前向緩沖區中不斷尋找能夠與字典中短語匹配的最長短語。以上面描述的前向緩沖區和滑動窗口為例,其最長的匹配短語為(A,B)。
壓縮和解壓縮數據
前向緩沖區和滑動窗口之間的匹配有兩種情況:要么找到一個匹配短語,要么找不到匹配的短語。當找到最長的匹配時,將其編碼成短語標記。
短語標記包含三個部分:1、滑動窗口中的偏移量(從頭部到匹配開始的前一個字符);2、匹配中的符號個數;3、匹配結束后,前向緩沖區中的第一個符號。
當沒有找到匹配時,將未匹配的符號編碼成符號標記。這個符號標記僅僅包含符號本身,沒有壓縮過程。事實上,我們將看到符號標記實際上比符號多一位,所以會出現輕微的擴展。
一旦把n個符號編碼并生成相應的標記,就將這n個符號從滑動窗口的一端移出,并用前向緩沖區中同樣數量的符號來代替它們。然后,重新填充前向緩沖區。這個過程使滑動窗口中始終有最新的短語。滑動窗口和前向緩沖區具體維護的短語數量由它們自身的容量決定。
下圖(1)展示了用LZ77算法壓縮字符串的過程,其中滑動窗口大小為8個字節,前向緩沖區大小為4個字節。在實際中,滑動窗口典型的大小為4KB(4096字節)。前向緩沖區大小通常小于100字節。
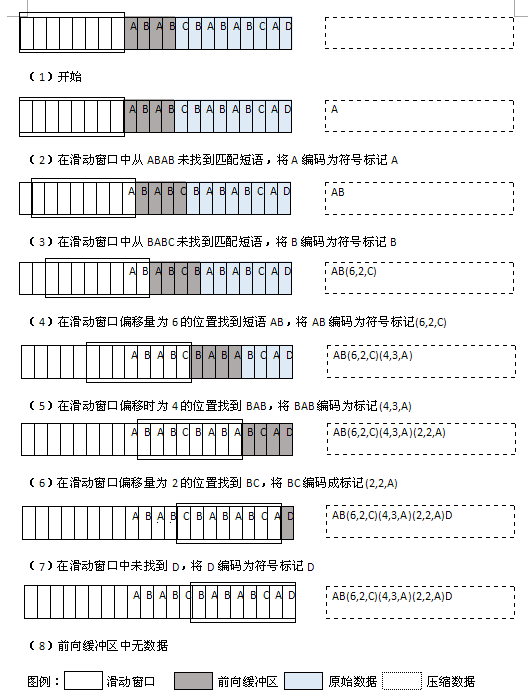
圖(1):使用LZ77算法對字符串ABABCBABABCAD進行壓縮
我們通過解碼標記和保持滑動窗口中符號的更新來解壓縮數據,其過程類似于壓縮過程。當解碼每個標記時,將標記編碼成字符拷貝到滑動窗口中。每當遇到一個短語標記時,就在滑動窗口中查找相應的偏移量,同時查找在那里發現的指定長度的短語。每當遇到一個符號標記時,就生成標記中保存的一個符號。下圖(2)展示了解壓縮圖(1)中數據的過程。
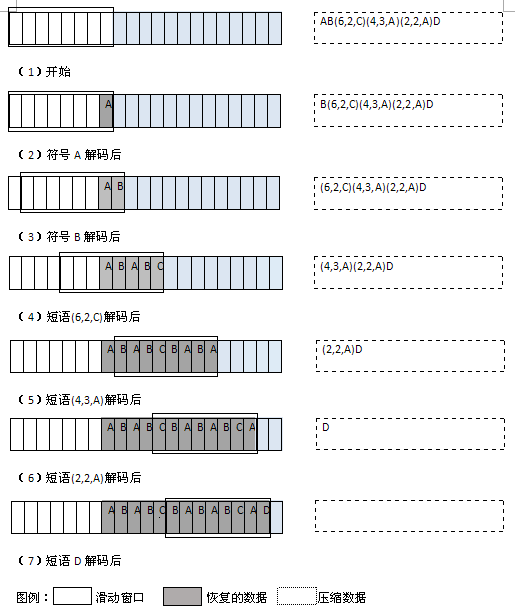
圖(2):使用LZ77算法對圖(1)中壓縮的字符串進行解壓縮
LZ77的效率
用LZ77算法壓縮的程度取決于很多因素,例如,選擇滑動窗口的大小,為前向緩沖區設置的大小,以及數據本身的熵。最終,壓縮的程度取決于能匹配的短語的數量和短語的長度。大多數情況下,LZ77比霍夫曼編碼有著更高的壓縮比,但是其壓縮過程相對較慢。
用LZ77算法壓縮數據是非常耗時的,國為要花很多時間尋找窗口中的匹配短語。然而在通常情況下,LZ77的解壓縮過程要比霍夫曼編碼的解壓縮過程耗時要少。LZ77的解壓縮過程非常快是因為每個標記都明確地告訴我們在緩沖區中哪個位置可以讀取到所需要的符號。事實上,我們最終只從滑動窗口中讀取了與原始數據數量相等的符號而已。
LZ77的接口定義
lz77_compress
int lz77_compress(const unsigned char *original, unsigned char **compressed, int size);
返回值:如果數據壓縮成功,返回壓縮后數據的字節數;否則返回-1;
描述: 用LZ77算法壓縮緩沖區original中的數據,original包含size個字節的空間。壓縮后的數據存入緩沖區compressed中。lz77_compress需要調用malloc來動態的為compressed分配存儲空間,當這塊空間不再使用時,由調用者調用函數free來釋放空間。
復雜度:O(n),其中n是原始數據中符號的個數。
lz77_uncompress
int lz77_uncompress(const unsigned char *compressed, unsigned char **original);
返回值:如果解壓縮數據成功,返回恢復后數據的字節數;否則返回-1;
描述: 用LZ77算法解壓縮緩沖區compressed中的數據。假定緩沖區包含的數據之前由lz77_compress壓縮。恢復后的數據存入緩沖區original中。lz77_uncompress函數調用malloc來動態的為original分配存儲空間。當這塊存儲空間不再使用時,由調用者調用函數free來釋放空間。
復雜度:O(n)其中n是原始數據中符號的個數。
LZ77的實現與分析
LZ77算法,通過一個滑動窗口將前向緩沖區中的短語編碼成相應的標記,從而達到壓縮的目的。在解壓縮的過程中,將每個標記解碼成短語或符號本身。要做到這些,必須要不斷地更新窗口,這樣,在壓縮過程中的任何時刻,窗口都能按照規則進行編碼。在本節所有的示例中,原始數據中的一個符號占一個字節。
lz77_compress
lz77_compress操作使用LZ77算法來壓縮數據。首先,它將數據中的符號寫入壓縮數據的緩沖區中,并同時初始化滑動窗口和前向緩沖區。隨后,前向緩沖區將用來加載符號。
壓縮發生在一個循環中,循環會持續迭代直到處理完所有符號。使用ipos來保存原始數據中正在處理的當前字節,并用opos來保存向壓縮數據緩沖區寫入的當前位。在循環的每次迭代中,調用compare_win來確定前向緩沖區與滑動窗口中匹配的最長短語。函數compare_win返回最長匹配串的長度。
當找到一個匹配串時,compare_win設置offset為滑動窗口中匹配串的位置,同時設置next為前向緩沖區中匹配串后一位的符號。在這種情況下,向壓縮數據中寫入一個短語標記(如圖3-a)。在本節展示的實現中,對于偏移量offset短語標記需要12位,這是因為滑動窗口的大小為4KB(4096字節)。此時短語標志需要5位來表示長度,因為在一個32字節的前向緩沖區中,不會有匹配串超過這個長度。當沒有找到匹配串時,compare_win返回,并且設置next為前向緩沖區起始處未匹配的符號。在這種情況下,向壓縮數據中寫入一個符號(如圖3-b)。無論向壓縮數據中寫入的是一個短語還是一個符號,在實際寫入標記之前,都需要調用網絡函數htonl來轉換串,以保證標記是大端格式。這種格式是在實際壓縮數據和解壓縮數據時所要求的。

圖3:LZ77中的短語標記(A)和符號標記(B)的結構
一旦將相應的標記寫入壓縮數據的緩沖區中,就調整滑動窗口和前向緩沖區。要使數據通過滑動窗口,將數據從右邊滑入窗口,從左邊滑出窗口。同樣,在前向緩沖區中也是相同的滑動過程。移動的字節數與標記中編碼的字符數相等。
lz77_compress的時間復雜度為O(n),其中n是原始數據中符號的個數。這是因為,對于數據中每個n/c個編碼的標記,其中1/c是一個代表編碼效率的常量因素,調用一次compare_win。函數compare_win運行一段固定的時間,因為滑動窗口和前向緩沖區的大小均為常數。然而,這些常量比較大,會對lz77_compress的總體運行時間產生較大的影響。所以,lz77_compress的時間復雜度是O(n),但其實際的復雜度會受其常量因子的影響。這就解釋了為什么在用lz77進行數據壓縮時速度非常慢。
lz77_uncompress
lz77_uncompress操作解壓縮由lz77_compress壓縮的數據。首先,該函數從壓縮數據中讀取字符,并初始化滑動窗口和前向緩沖區。
解壓縮過程在一個循環中執行,此循環會持續迭代執行直到所有的符號處理完。使用ipos來保存向壓縮數據中寫入的當前位,并用opos來保存寫入恢復數據緩沖區中當前字節。在循環的每次迭代過程中,首先從壓縮數據讀取一位來確定要解碼的標記類型。
在解析一個標記時,如果讀取的首位是1,說明遇到了一個短語標記。此時讀取它的每個成員,查找滑動窗口中的短語,然后將短語寫入恢復數據緩沖區中。當查找每個短語時,調用網絡函數ntohl來保證窗口中的偏移量和長度的字節順序是與操作系統匹配的。這個轉換過程是必要的,因為從壓縮數據中讀取出來的偏移量和長度是大端格式的。在數據被拷貝到滑動窗口之前,前向緩沖區被用做一個臨時轉換區來保存數據。最后,寫入該標記編碼的匹配的符號。如果讀取的標記的首位是0,說明遇到了一個符號標記。在這種情況下,將該標記編碼的匹配符號寫入恢復數據緩沖區中。
一旦將解碼的數據寫入恢復數據的緩沖區中,就調整滑動窗口。要將數據通過滑動窗口,將數據從右邊滑入窗口,從左邊滑出窗口。移動的字節數與從標記中解碼的字符數相等。
lz77_uncompress的時間復雜度為O(n),其中n是原始數據中符號的個數。
-
數據
+關注
關注
8文章
7256瀏覽量
91888
原文標題:數據壓縮算法:LZ77 算法的分析與實現
文章出處:【微信號:TheAlgorithm,微信公眾號:算法與數據結構】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
FPGA實現滑動平均濾波算法和LZW壓縮算法
labview 數據壓縮傳輸 各種壓縮算法實現?
【學習打卡】OpenHarmony啃論文俱樂部——綜述視角解讀壓縮編碼
【學習打卡】【ELT.ZIP】OpenHarmony啃論文俱樂部——綜述視角解讀壓縮編碼
【學習打卡】【ELT.ZIP】OpenHarmony啃論文俱樂部——多維探秘通用無損壓縮
【ELT.ZIP】OpenHarmony啃論文俱樂部—數據密集型應用內存壓縮
【學習打卡】【ELT.ZIP】OpenHarmony啃論文俱樂部—硬件加速的快速無損壓縮
【學習打卡】【ELT.ZIP】OpenHarmony啃論文俱樂部—數據密集型應用內存壓縮
SAR雷達原始數據BAVQ壓縮算法的硬件實現
Linux 5.7將支持Zstd壓縮算法
PostgreSQL 14中TOAST的新壓縮算法LZ4,它能有多快?






 工商網監
工商網監
評論