 自動神經結構搜索方法實現高效率卷積神經網絡設計
自動神經結構搜索方法實現高效率卷積神經網絡設計
為移動設備設計卷積神經網絡(CNN)模型是很具挑戰性的,因為移動設備的模型需要小,要快,而且仍然要求準確性。盡管在這三個維度上設計和改進模型已經有很多研究,但由于需要考慮如此多的結構可能性,手動去權衡這些維度是很有挑戰性的。
在這篇論文中,谷歌大腦AutoML組的研究人員提出一種自動神經結構搜索方法,用于設計資源有限的移動端CNN模型(mobile CNN)。
Jeff Dean在推特推薦了這篇論文:這項工作提出將模型的計算損失合并到神經結構搜索的獎勵函數中,以自動找到滿足推理速度目標的高準確率的模型。
在以前的工作中,移動延遲(mobile latency)通常是通過另一個代理(例如FLOPS)來考慮的,這些代理經常不準確。與之前的工作不同,在我們的實驗中,我們通過在特定平臺(如Pixel phone)上執行模型,從而直接測量實際的推理延遲(inference latency)。
為了進一步在靈活性和搜索空間大小之間取得平衡,我們提出了一種新的分解分層搜索空間(factorized hierarchical search space),允許在整個網絡中的層存在多樣性。
實驗結果表明,我們的方法在多個視覺任務中始終優于state-of-the-art的移動端CNN模型。在ImageNet圖像分類任務中,我們的模型在Pixel phone上達到74.0%的top-1 精度(延遲為76ms)。達到相同的top-1精度的條件下,我們的模型比MobileNetV2快1.5倍,比NASNet快2.4倍。在COCO對象檢測任務中,我們的模型實現了比MobileNets更高的mAP質量和更低的延遲。
Platform-Aware神經結構搜索
具體來說,我們提出一種用于設計移動端的CNN模型的自動神經結構搜索方法,稱之為Platform-Aware神經結構搜索。圖1是Platform-Aware神經結構搜索方法的總體視圖,它與以前的方法的主要區別在于延遲感知多目標獎勵(latency aware multi-objective reward)和新的搜索空間。
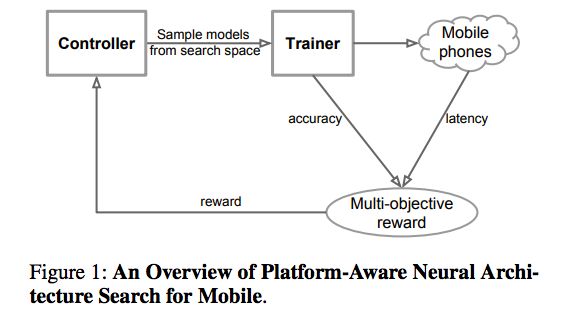
圖1:Platform-Aware神經結構搜索的概覽
這一方法主要受到兩個想法的啟發:
首先,我們將設計神經網絡的問題表述為一個多目標優化問題,這個問題要考慮CNN模型的準確性和推理延遲。然后,我們使用基于強化學習的結構搜索來找到在準確性和延遲之間實現最佳權衡的模型。
其次,我們觀察到先前的自動化結構搜索方法主要是搜索幾種類型的cells,然后通過CNN網絡反復堆疊相同的cell。這樣搜索到的模型沒有考慮由于模型的具體形狀不同,卷積之類的操作在延遲上有很大差異:例如,2個3x3的卷積具有同樣的理論FLOPS,但形狀不同的情況下,可能 runtime latency是不同的。
在此基礎上,我們提出一個分解的分層搜索空間(factorized hierarchical search space),它由很多分解后的塊(factorized blocks)組成,每個block包含由分層子搜索空間定義的層的list,其中包含不同的卷積運算和連接。
圖3:Factorized Hierarchical搜索空間
我們證明了,在一個架構的不同深度應該使用不同的操作,并且可以使用利用已測量的推理延遲作為獎勵信號一部分的架構搜索方法來在這個巨大的選擇空間中進行搜索。
總結而言,這一研究的主要貢獻有:
我們提出一種基于強化學習的多目標神經結構搜索方法,該方法能夠在低推理延遲的條件下找到高精度的CNN模型。
我們提出一種新的分解分層搜索空間(factorized hierarchical search space),通過在靈活性和搜索空間大小之間取得適當的平衡,最大限度地提高移動設備上模型的資源效率。
我們在ImageNet圖像分類和COCO對象檢測兩個任務上,證明了我們的模型相對state-of-the-art的mobile CNN模型有顯著改進。
MnasNet的結構
圖7:MnasNet的結構
圖7的(a)描繪了表1所示的baseline MnasNet的神經網絡結構。它由一系列線性連接的blocks組成,每個block由不同類型的layer組成,如圖7(b) - (f)所示。此外,我們還觀察到一些有趣的發現:
MnasNet有什么特別之處呢?
為了更好地理解MnasNet模型與之前的 mobile CNN模型有何不同,我們注意到這些模型包含的5x5 depthwise的卷積比以前的工作(Zhang et al.1188; Huang et al.1188; Sandler et al.1188)的更多,以前的工作一般只使用3x3 的kernels。實際上,對于depthwise可分離的卷積來說,5×5 kernels 確實比3×3 kernels更具資源效率。
layer的多樣性重要嗎?
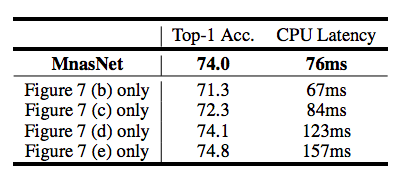
表3
我們將MnasNet與它的在整個網絡中重復單一類型的層的變體進行了比較。如表3所示,MnasNet比這些變體在精度和延遲之間的權衡表現更好,這表明在資源有限的CNN模型中,layer的多樣性相當重要。
實驗結果
ImageNet分類性能
我們將所提出的方法應用于ImageNet圖像分類和COCO對象檢測任務。
表1展示了本模型在ImageNet上的性能。
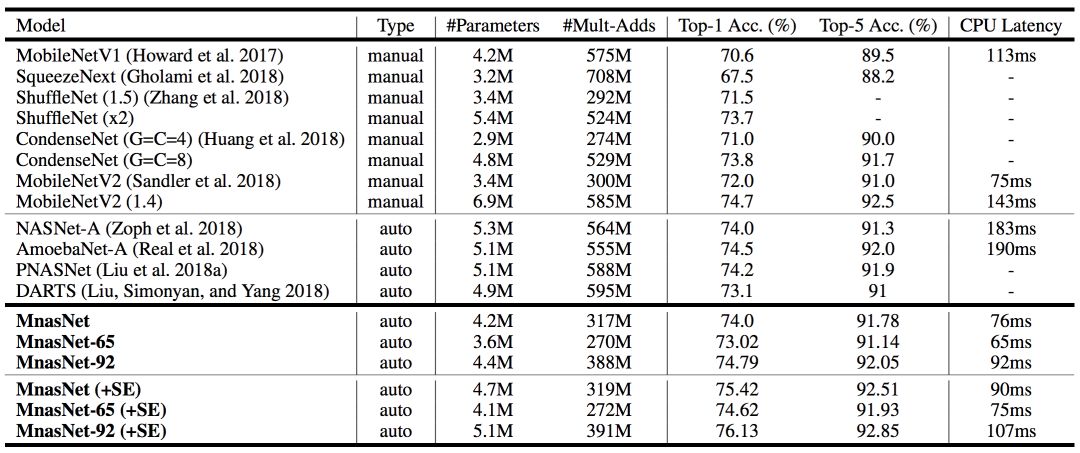
表1:在ImageNet上進行分類的性能結果
本文將MnasNet模型與手動設計的移動模型以及其它自動化方法做了比較,其中MnasNet是基準模型。MnasNet-65和MnasNet-92是同一體系結構搜索實驗中不同延遲的兩種模型(用于比較)。其中,“+SE”表示附加的squeeze-and-excitation優化;“#Parameters”表示可訓練參數的數量;“#Mult-Adds”表示每張圖片multiply-add操作的數量;“Top-1/5 Acc.”表示在ImageNet驗證集上排名第一或前五的精度;“CPU延遲”表示在Pixel1手機上批量大小為1的推斷延遲。
如表1所示,與當前最優的MobileNetV2相比,我們的MnasNet模型在Pixel phone平臺上,在同樣的延遲下,將ImageNet top-1的準確率提高了2%。
此外,限制目標top-1準確率的條件下,我們的方法得到同樣精度的速度比MobileNetV2快1.5倍,比NASNet快2.4倍。
結構搜索方法
多目標搜索方法通過在方程2中對α和β設置不同的值來設置硬性或軟性延遲約束。下圖展示了在典型α和β下多目標搜索的結果:
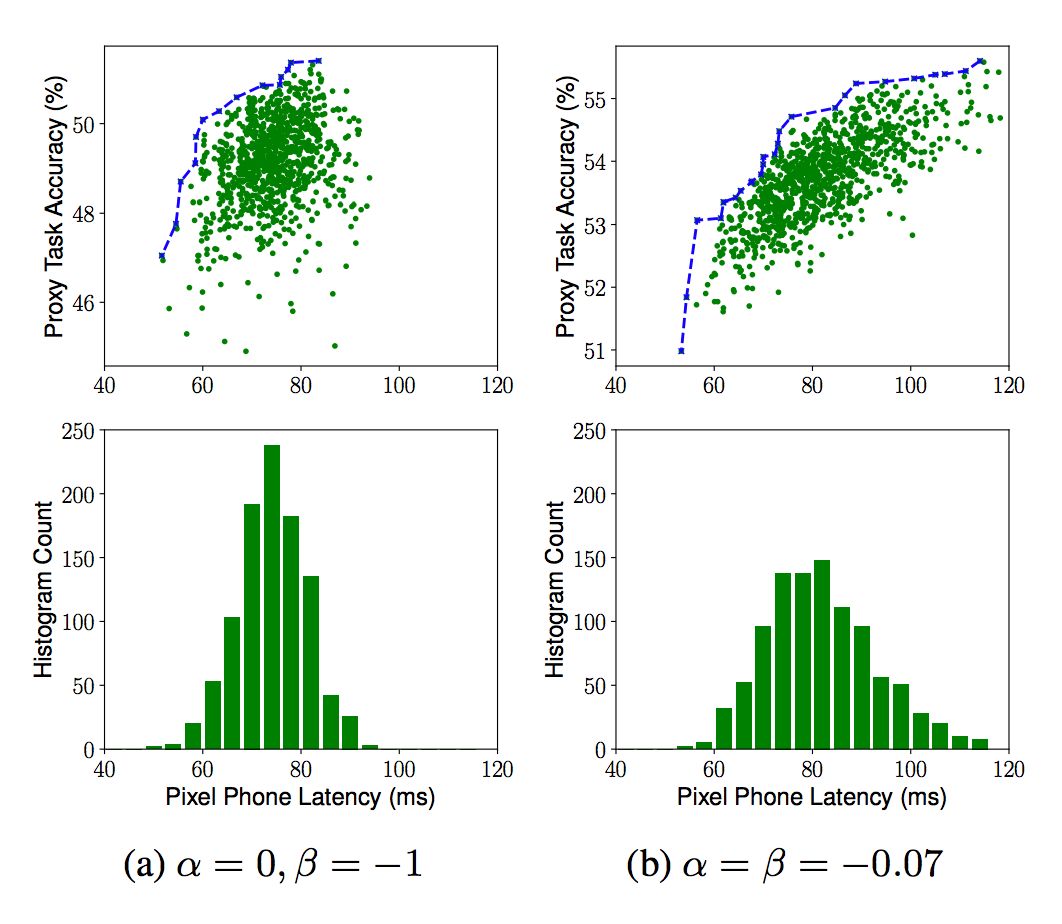
多目標搜索結果
其中,目標延遲(target latency)為T=80ms。上方圖片展示了對1000個樣本模型(綠色點)的柏拉圖曲線(藍色線);下方圖片展示了模型延遲的直方圖。
模型擴展的靈敏度
現實世界中,各式各樣的應用程序有著許多不同的需求,并且移動設備也不是統一的,所以開發人員通常會做一些擴展性方面的工作。下圖便展示了不同模型擴展技術的結果:
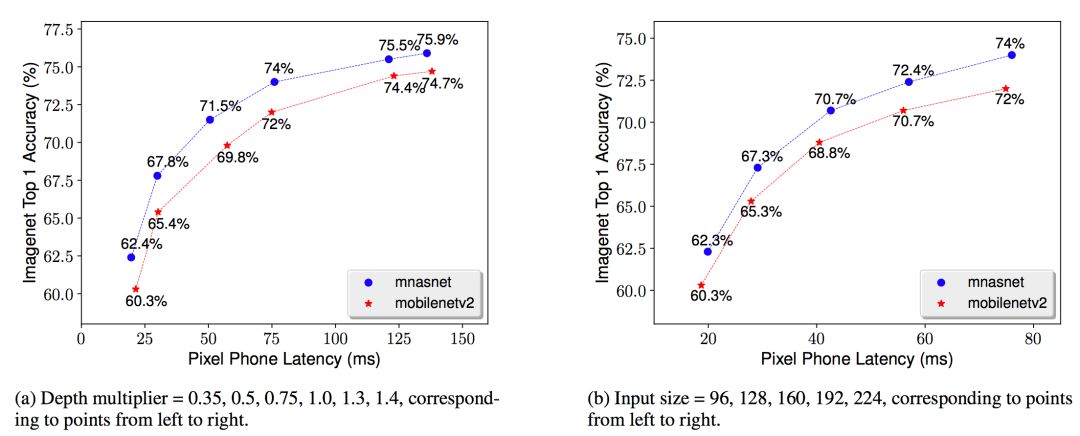
不同模型擴展技術的性能比較
MnasNet表1中的基準模型。將該基準模型與MobileNet V2的深度倍增器(depth multiplier)和輸入保持一致。
除了模型擴展之外,本文提出的方法還能為任何新的資源約束搜索新的結構。例如,一些視頻應用程序可能需要低至25ms的模型延遲。為了滿足這些約束,可以使用更小的輸入規模和深度倍增器來擴展一個基準模型,也可以搜索更適合這個新延遲約束的模型。圖6就展示了上述兩個方法的性能比較。
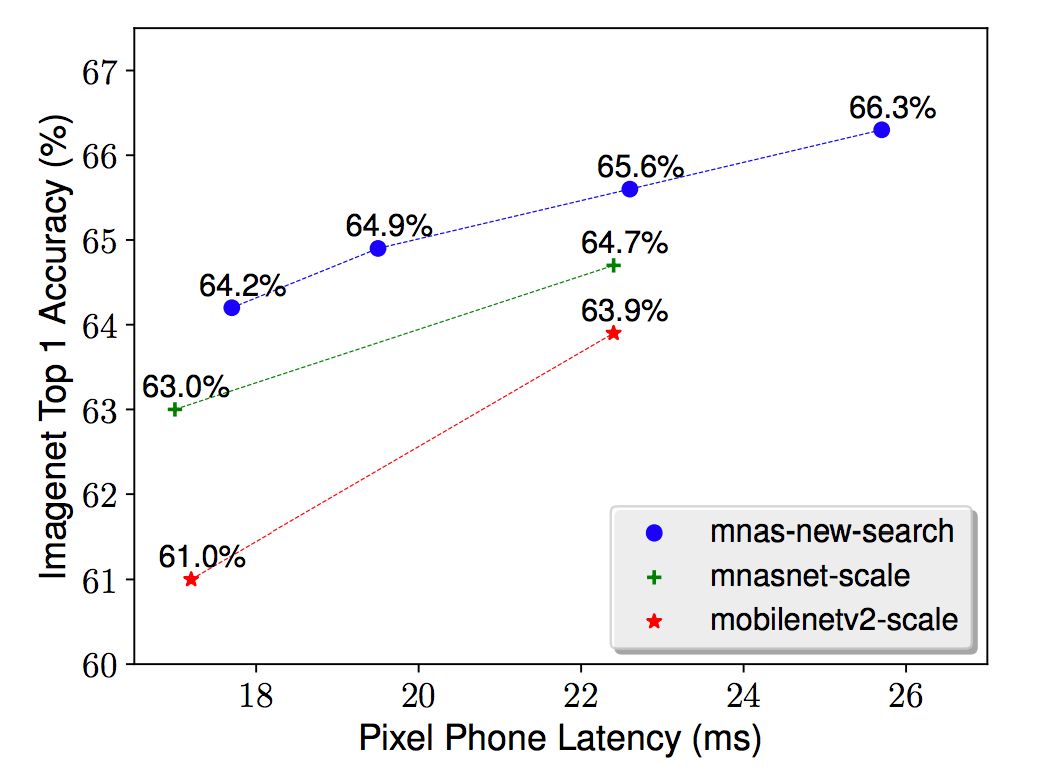
模型擴展 vs. 模型搜索
COCO目標檢測性能
對于COCO目標檢測,選擇與表1相同的MnasNet模型作為SSDLite的特征提取器。根據其他研究人員的建議,只用本文提出的模型與其他SSD或YOLO探測器進行比較。表2展示了在COCO上MnasNet模型的性能。
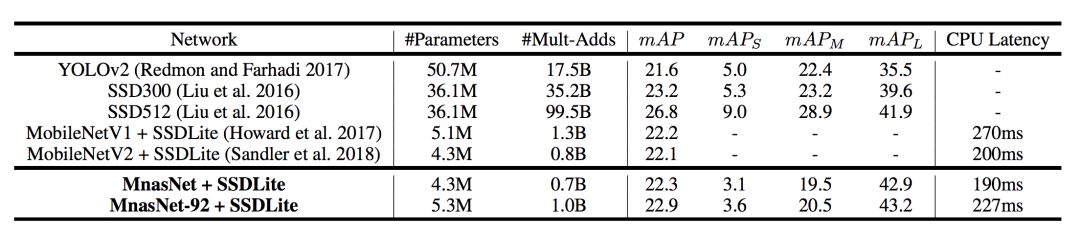
表2:在COCO上進行目標檢測的性能結果
其中,“#Parameters”表示可訓練參數的數量;“#Mult-Adds”表示每張圖片multiply-add操作的數量;mAP表示在test-dev2017上的標準MAP值;mAPS、mAPM、mAPL表示在小型、中等、大型目標中的MAP值;“CPU延遲”表示在Pixel1手機上批量大小為1的推斷延遲。
如表2所示,將我們的模型作為特征提取器插入SSD對象檢測框架,在COCO數據集上我們的模型在推理延遲和mAP質量上都比MobileNetV1和MobileNetV2有提升,并且達到與 SSD300差不多的mAP質量時(22.9 vs 23.2)計算成本降低了35倍。
結論
本文提出了一種利用強化學習來設計mobile CNN模型的自動神經結構搜索方法。這種方法背后的關鍵想法是將platform-aware的真實的延遲信息集成到搜索過程中,并利用新的分解分層搜索空間來搜索移動模型,在準確性和延遲之間進行最佳的權衡。我們證明了這一方法可以比現有方法更好地自動地找到移動模型,并在典型的移動推理延遲約束下,在ImageNet圖像分類和COCO對象檢測任務上獲得新的最優結果。由此產生的MnasNet架構還提供了一些有趣的發現,將指導我們設計下一代的mobile CNN模型。
-
谷歌
+關注
關注
27文章
6223瀏覽量
107576 -
Layer
+關注
關注
0文章
17瀏覽量
6787 -
卷積神經網絡
+關注
關注
4文章
369瀏覽量
12199
原文標題:計算成本降低35倍!谷歌發布手機端自動設計神經網絡MnasNet
文章出處:【微信號:AI_era,微信公眾號:新智元】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄





 工商網監
工商網監
評論