") 虛擬到現(xiàn)實(shí)的翻譯網(wǎng)絡(luò)如何滿足自動(dòng)駕駛要求?
虛擬到現(xiàn)實(shí)的翻譯網(wǎng)絡(luò)如何滿足自動(dòng)駕駛要求?

加州大學(xué)伯克利分校的Xinlei Pan等人提出了一種虛擬到現(xiàn)實(shí)(Virtual to Real)的翻譯網(wǎng)絡(luò),可以將虛擬駕駛模擬器中生成的虛擬場(chǎng)景翻譯成真實(shí)場(chǎng)景,來(lái)進(jìn)行強(qiáng)化學(xué)習(xí)訓(xùn)練,取得了更好的泛化能力,并可以遷移學(xué)習(xí)應(yīng)用到真實(shí)世界中的實(shí)際車輛,滿足真實(shí)世界的自動(dòng)駕駛要求。
1.前言
強(qiáng)化學(xué)習(xí)(Reinforcement Learning)是機(jī)器學(xué)習(xí)的一個(gè)熱門研究方向。強(qiáng)化學(xué)習(xí)較多的研究情景主要在機(jī)器人、游戲與棋牌等方面,自動(dòng)駕駛的強(qiáng)化學(xué)習(xí)研究中一大問(wèn)題是很難在現(xiàn)實(shí)場(chǎng)景中進(jìn)行實(shí)車訓(xùn)練。因?yàn)閺?qiáng)化學(xué)習(xí)模型需要成千上萬(wàn)次的試錯(cuò)來(lái)迭代訓(xùn)練,而真實(shí)車輛在路面上很難承受如此多的試錯(cuò)。所以目前主流的關(guān)于自動(dòng)駕駛的強(qiáng)化學(xué)習(xí)研究都集中在使用虛擬駕駛模擬器來(lái)進(jìn)行代理(Agent)的仿真訓(xùn)練,但這種仿真場(chǎng)景和真實(shí)場(chǎng)景有一定的差別,訓(xùn)練出來(lái)的模型不能很好地泛化到真實(shí)場(chǎng)景中,也不能滿足實(shí)際的駕駛要求。加州大學(xué)伯克利分校的Xinlei Pan等人提出了一種虛擬到現(xiàn)實(shí)(Virtual to Real)的翻譯網(wǎng)絡(luò),可以將虛擬駕駛模擬器中生成的虛擬場(chǎng)景翻譯成真實(shí)場(chǎng)景,來(lái)進(jìn)行強(qiáng)化學(xué)習(xí)訓(xùn)練,取得了更好的泛化能力,并可以遷移學(xué)習(xí)應(yīng)用到真實(shí)世界中的實(shí)際車輛,滿足真實(shí)世界的自動(dòng)駕駛要求。下面為本文的翻譯,編者對(duì)文章有一定的概括與刪改。
2.簡(jiǎn)介
強(qiáng)化學(xué)習(xí)被認(rèn)為是推動(dòng)策略學(xué)習(xí)的一個(gè)有前途的方向。然而,在實(shí)際環(huán)境中進(jìn)行自動(dòng)駕駛車輛的強(qiáng)化學(xué)習(xí)訓(xùn)練涉及到難以負(fù)擔(dān)的試錯(cuò)。更可取的做法是先在虛擬環(huán)境中訓(xùn)練,然后再遷移到真實(shí)環(huán)境中。本文提出了一種新穎的現(xiàn)實(shí)翻譯網(wǎng)絡(luò)(Realistic Translation Network),使虛擬環(huán)境下訓(xùn)練的模型在真實(shí)世界中變得切實(shí)可行。提出的網(wǎng)絡(luò)可以將非真實(shí)的虛擬圖像輸入轉(zhuǎn)換到有相似場(chǎng)景結(jié)構(gòu)的真實(shí)圖像。以現(xiàn)實(shí)的框架為輸入,通過(guò)強(qiáng)化學(xué)習(xí)訓(xùn)練的駕駛策略能夠很好地適應(yīng)真實(shí)世界的駕駛。實(shí)驗(yàn)表明,我們提出的虛擬到現(xiàn)實(shí)的強(qiáng)化學(xué)習(xí)效果很好。據(jù)我們所知,這是首次通過(guò)強(qiáng)化學(xué)習(xí)訓(xùn)練的駕駛策略可以適應(yīng)真實(shí)世界駕駛數(shù)據(jù)的成功案例。
圖1 自動(dòng)駕駛虛擬到現(xiàn)實(shí)強(qiáng)化學(xué)習(xí)的框架。由模擬器(環(huán)境)渲染的虛擬圖像首先被分割成場(chǎng)景解析的表現(xiàn)形式,然后通過(guò)提出的圖像翻譯網(wǎng)絡(luò)(VISRI)將其翻譯為合成的真實(shí)圖像。代理(Agent)觀察合成的真實(shí)圖像并執(zhí)行動(dòng)作。環(huán)境會(huì)給Agent獎(jiǎng)勵(lì)。由于Agent是使用可見(jiàn)的近似于真實(shí)世界的圖像來(lái)訓(xùn)練,所以它可以很好地適應(yīng)現(xiàn)實(shí)世界的駕駛。
自動(dòng)駕駛的目標(biāo)是使車輛感知它的環(huán)境和在沒(méi)有人參與下的行駛。實(shí)現(xiàn)這個(gè)目標(biāo)最重要的任務(wù)是學(xué)習(xí)根據(jù)觀察到的環(huán)境自動(dòng)輸出方向盤、油門、剎車等控制信號(hào)的駕駛策略。最直接的想法是端到端的有監(jiān)督學(xué)習(xí),訓(xùn)練一個(gè)神經(jīng)網(wǎng)絡(luò)模型直接映射視覺(jué)輸入到動(dòng)作輸出,訓(xùn)練數(shù)據(jù)被標(biāo)記為圖像-動(dòng)作對(duì)。然而,有監(jiān)督的方法通常需要大量的數(shù)據(jù)來(lái)訓(xùn)練一個(gè)可泛化到不同環(huán)境的模型。獲得如此大量的數(shù)據(jù)非常耗費(fèi)時(shí)間且需要大量的人工參與。相比之下,強(qiáng)化學(xué)習(xí)是通過(guò)一種反復(fù)試錯(cuò)的方式來(lái)學(xué)習(xí)的,不需要人工的明確監(jiān)督。最近,由于其在動(dòng)作規(guī)劃方面的專門技術(shù),強(qiáng)化學(xué)習(xí)被認(rèn)為是一種有前途的學(xué)習(xí)駕駛策略的技術(shù)。
然而,強(qiáng)化學(xué)習(xí)需要代理(Agent)與環(huán)境的相互作用,不符規(guī)則的駕駛行為將會(huì)發(fā)生。在現(xiàn)實(shí)世界中訓(xùn)練自動(dòng)駕駛汽車會(huì)對(duì)車輛和周圍環(huán)境造成破壞。因此目前的自動(dòng)駕駛強(qiáng)化學(xué)習(xí)研究大多集中于仿真,而不是在現(xiàn)實(shí)世界中的訓(xùn)練。一個(gè)受過(guò)強(qiáng)化學(xué)習(xí)訓(xùn)練的代理在虛擬世界中可以達(dá)到近人的駕駛性能,但它可能不適用于現(xiàn)實(shí)世界的駕駛環(huán)境,這是因?yàn)樘摂M仿真環(huán)境的視覺(jué)外觀不同于現(xiàn)實(shí)世界的駕駛場(chǎng)景。
雖然虛擬駕駛場(chǎng)景與真實(shí)駕駛場(chǎng)景相比具有不同的視覺(jué)外觀,但它們具有相似的場(chǎng)景解析結(jié)構(gòu)。例如虛擬和真實(shí)的駕駛場(chǎng)景可能都有道路、樹木、建筑物等,盡管紋理可能有很大的不同。因此將虛擬圖像翻譯成現(xiàn)實(shí)圖像是合理的,我們可以得到一個(gè)在場(chǎng)景解析結(jié)構(gòu)與目標(biāo)形象兩方面都與真實(shí)世界非常相似的仿真環(huán)境。最近,生成對(duì)抗性網(wǎng)絡(luò)(GAN)在圖像生成方面引起了很多關(guān)注。[1]等人的工作提出了一種可以用兩個(gè)域的配對(duì)數(shù)據(jù)將圖像從一個(gè)域翻譯到另一個(gè)域的翻譯網(wǎng)絡(luò)的設(shè)想。然而,很難找到駕駛方向的虛擬現(xiàn)實(shí)世界配對(duì)圖像。這使得我們很難將這種方法應(yīng)用到將虛擬駕駛圖像翻譯成現(xiàn)實(shí)圖像的案例中。
本文提出了一個(gè)現(xiàn)實(shí)翻譯網(wǎng)絡(luò),幫助在虛擬世界中訓(xùn)練自動(dòng)駕駛車輛使其完全適應(yīng)現(xiàn)實(shí)世界的駕駛環(huán)境。我們提出的框架(如圖1所示)將模擬器渲染的虛擬圖像轉(zhuǎn)換為真實(shí)圖像,并用合成的真實(shí)圖像訓(xùn)練強(qiáng)化學(xué)習(xí)代理。雖然虛擬和現(xiàn)實(shí)的圖像有不同的視覺(jué)外觀,但它們有一個(gè)共同的場(chǎng)景解析表現(xiàn)方式(道路、車輛等的分割圖)。因此我們可以用將場(chǎng)景解析的表達(dá)作為過(guò)渡方法將虛擬圖像轉(zhuǎn)化為現(xiàn)實(shí)圖像。這種見(jiàn)解類似于自然語(yǔ)言翻譯,語(yǔ)義是不同語(yǔ)言之間的過(guò)渡。具體來(lái)說(shuō),我們的現(xiàn)實(shí)翻譯網(wǎng)絡(luò)包括兩個(gè)模塊:第一個(gè)是虛擬解析或虛擬分割模塊,產(chǎn)生一個(gè)對(duì)輸入虛擬的圖像進(jìn)行場(chǎng)景解析的表示方式。第二個(gè)是將場(chǎng)景解析表達(dá)方式翻譯為真實(shí)圖像的解析到真實(shí)網(wǎng)絡(luò)。通過(guò)現(xiàn)實(shí)翻譯網(wǎng)絡(luò),在真實(shí)駕駛數(shù)據(jù)上學(xué)習(xí)得到的強(qiáng)化學(xué)習(xí)模型可以很好地適用于現(xiàn)實(shí)世界駕駛。
為了證明我們方法的有效性,我們通過(guò)使用現(xiàn)實(shí)翻譯網(wǎng)絡(luò)將虛擬圖像轉(zhuǎn)化成合成的真實(shí)圖像并將這些真實(shí)圖像作為狀態(tài)輸入來(lái)訓(xùn)練我們的強(qiáng)化學(xué)習(xí)模型。我們進(jìn)一步比較了利用領(lǐng)域隨機(jī)化(Domain Randomization)的有監(jiān)督學(xué)習(xí)和其他強(qiáng)化學(xué)習(xí)方法。實(shí)驗(yàn)結(jié)果表明,用翻譯的真實(shí)圖像訓(xùn)練的強(qiáng)化學(xué)習(xí)模型比只用虛擬輸入和使用領(lǐng)域隨機(jī)化的強(qiáng)化學(xué)習(xí)模型效果都要更好。
3.自然環(huán)境下的強(qiáng)化學(xué)習(xí)
我們的目標(biāo)是成功地將一個(gè)完全在虛擬環(huán)境中訓(xùn)練的駕駛模型應(yīng)用于真實(shí)世界的駕駛挑戰(zhàn)。其中一個(gè)主要的空白是,代理所觀察到的是由模擬器渲染的幀,它們?cè)谕庥^上與真實(shí)世界幀不同。因此提出了一種將虛擬幀轉(zhuǎn)換為現(xiàn)實(shí)幀的現(xiàn)實(shí)翻譯網(wǎng)絡(luò)。受圖像-圖像翻譯網(wǎng)絡(luò)工作的啟發(fā),我們的網(wǎng)絡(luò)包括兩個(gè)模塊:即虛擬-解析和解析-現(xiàn)實(shí)網(wǎng)絡(luò)。第一個(gè)模塊將虛擬幀映射到場(chǎng)景解析圖像。第二個(gè)模塊將場(chǎng)景解析轉(zhuǎn)換為與輸入虛擬幀具有相似的場(chǎng)景結(jié)構(gòu)的真實(shí)幀。這兩個(gè)模塊可以產(chǎn)生保持輸入虛擬幀場(chǎng)景解析結(jié)構(gòu)的真實(shí)幀。最后我們?cè)谕ㄟ^(guò)現(xiàn)實(shí)翻譯網(wǎng)絡(luò)獲得的真實(shí)幀上,運(yùn)用強(qiáng)化學(xué)習(xí)的方法,訓(xùn)練了一個(gè)自動(dòng)駕駛代理。我們所采用了[2]等人提出的方法,使用異步的actor-critic強(qiáng)化學(xué)習(xí)算法在賽車模擬器TORCS[3]中訓(xùn)練了一輛自動(dòng)駕駛汽車。在這部分,我們首先展現(xiàn)了現(xiàn)實(shí)翻譯網(wǎng)絡(luò),然后討論了如何在強(qiáng)化學(xué)習(xí)框架下對(duì)駕駛代理進(jìn)行訓(xùn)練。
圖2:虛擬世界圖像(左1和左2)和真實(shí)世界圖像(右1和右2)的圖像分割實(shí)例
3.1 現(xiàn)實(shí)翻譯網(wǎng)絡(luò):
由于沒(méi)有配對(duì)過(guò)的虛擬和真實(shí)世界圖像,使用[1]的直接映射虛擬世界圖像到真實(shí)世界圖像將是尷尬的。然而由于這兩種類型的圖像都表達(dá)了駕駛場(chǎng)景,我們可以通過(guò)場(chǎng)景分析來(lái)翻譯它們。受[1]的啟發(fā),我們的現(xiàn)實(shí)翻譯網(wǎng)絡(luò)由兩個(gè)圖像翻譯網(wǎng)絡(luò)組成,第一個(gè)圖像翻譯網(wǎng)絡(luò)將虛擬圖像轉(zhuǎn)化為圖像的分割。第二個(gè)圖像翻譯網(wǎng)絡(luò)將分割后圖像轉(zhuǎn)化為現(xiàn)實(shí)世界中的對(duì)應(yīng)圖像。
由[1]等人提出的圖像至圖像的翻譯網(wǎng)絡(luò)基本上是一個(gè)有條件的生成對(duì)抗網(wǎng)絡(luò)(GAN)。傳統(tǒng)的GAN網(wǎng)絡(luò)和有條件的GAN網(wǎng)絡(luò)的區(qū)別在于,傳統(tǒng)GAN網(wǎng)絡(luò)是學(xué)習(xí)一種從隨機(jī)噪聲矢量z到輸出圖像s的映射:G:z → s,而有條件的GAN網(wǎng)絡(luò)是同時(shí)吸收了圖像x和噪聲向量z,生成另一個(gè)圖像s:G:{x, z} → s,且s通常與x屬于不同的領(lǐng)域(例如將圖像翻譯成其分割)。
有條件的GAN網(wǎng)絡(luò)的任務(wù)目標(biāo)可以表達(dá)為:
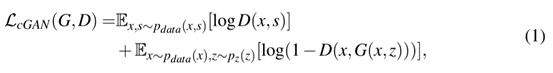
G是試圖最小化目標(biāo)的生成器,D是與G相違背的試圖最大化目標(biāo)的對(duì)抗判別器。換句話說(shuō),=argmima(G,D),為了抑制模糊,添加了L1的損失正則化,可以表達(dá)為
:
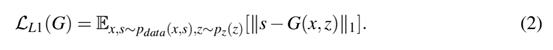
因此,圖像-圖像翻譯網(wǎng)絡(luò)的總體目標(biāo)是:
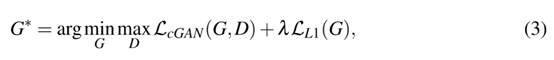
λ是正則化的權(quán)重。
我們的網(wǎng)絡(luò)由兩個(gè)圖像-圖像的轉(zhuǎn)換網(wǎng)絡(luò)組成,這兩個(gè)網(wǎng)絡(luò)使用公式(3)作為相同的損失函數(shù)。第一個(gè)網(wǎng)絡(luò)將虛擬圖像x翻譯成它們的分割 s:G1:{x,} → S,第二個(gè)網(wǎng)絡(luò)將分割的圖像s轉(zhuǎn)換成它們的現(xiàn)實(shí)對(duì)應(yīng)的y: G2:{ s,} → y,,是噪聲,以避免確定性的輸出。對(duì)于GAN神經(jīng)網(wǎng)絡(luò)的結(jié)構(gòu),我們使用的是與[1]相同的生成器和判別器結(jié)構(gòu)。
3.2 訓(xùn)練自主駕駛汽車的強(qiáng)化學(xué)習(xí):
我們使用傳統(tǒng)的強(qiáng)化學(xué)習(xí)解決方案異步優(yōu)勢(shì)Actor-Arbitor(A3C)來(lái)訓(xùn)練自動(dòng)駕駛汽車,這種方法在多種機(jī)器學(xué)習(xí)任務(wù)中表現(xiàn)的很出色。A3C算法是將幾種經(jīng)典的強(qiáng)化學(xué)習(xí)算法與異步并行線程思想相結(jié)合的一種基本的行動(dòng)Actor-Critic。多個(gè)線程與環(huán)境的無(wú)關(guān)副本同時(shí)運(yùn)行,生成它們自己的訓(xùn)練樣本序列。這些Actor-learners繼續(xù)運(yùn)行,好像他們正在探索未知空間的不同部分。對(duì)于一個(gè)線程,參數(shù)在學(xué)習(xí)迭代之前同步,完成后更新。A3C算法實(shí)現(xiàn)的細(xì)節(jié)見(jiàn)[2]。為了鼓勵(lì)代理更快地駕駛和避免碰撞,我們定義了獎(jiǎng)勵(lì)函數(shù)為:
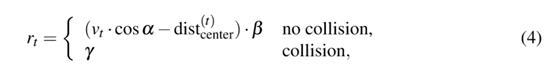
Vt是在第t步時(shí)代理的速度(m/s),α是代理的速度方向與軌跡切線之間的輪廓(紅色部分),是代理中心和軌跡中點(diǎn)之間的距離,β、γ是常數(shù)并在訓(xùn)練的一開始就被定義。我們?cè)谟?xùn)練時(shí)設(shè)置β=0.006,γ=-0.025。
我們做了兩組實(shí)驗(yàn)來(lái)比較我們的方法和其他強(qiáng)化學(xué)習(xí)方法以及有監(jiān)督學(xué)習(xí)方法的性能。第一組實(shí)驗(yàn)涉及真實(shí)世界駕駛數(shù)據(jù)的虛擬到現(xiàn)實(shí)的強(qiáng)化學(xué)習(xí),第二組實(shí)驗(yàn)涉及不同虛擬駕駛環(huán)境下的遷移學(xué)習(xí)。我們實(shí)驗(yàn)中使用的虛擬模擬器是TORCS。
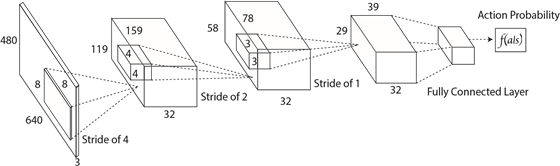
圖3:強(qiáng)化學(xué)習(xí)網(wǎng)絡(luò)結(jié)構(gòu)。該網(wǎng)絡(luò)是一個(gè)端到端的將狀態(tài)表示映射到動(dòng)作概率輸出的網(wǎng)絡(luò)
圖4:虛擬到真實(shí)圖像翻譯的例子。奇數(shù)列是從TORCS截取的虛擬圖像。偶數(shù)列是根據(jù)左邊的虛擬圖像相對(duì)應(yīng)合成的真實(shí)世界圖像。
3.3 真實(shí)世界駕駛數(shù)據(jù)下的虛擬到現(xiàn)實(shí)強(qiáng)化學(xué)習(xí):
在本實(shí)驗(yàn)中,我們用現(xiàn)實(shí)翻譯網(wǎng)絡(luò)訓(xùn)練了我們所提出的強(qiáng)化學(xué)習(xí)模型。我們首先訓(xùn)練虛擬到真實(shí)的圖像翻譯網(wǎng)絡(luò)然后利用受過(guò)訓(xùn)練的網(wǎng)絡(luò)對(duì)模擬器中的虛擬圖像進(jìn)行濾波。這些真實(shí)的圖像隨后被輸入A3C算法,以訓(xùn)練駕駛策略。最后經(jīng)過(guò)訓(xùn)練的策略在真實(shí)世界駕駛數(shù)據(jù)上進(jìn)行了測(cè)試,以評(píng)估其轉(zhuǎn)向角度預(yù)測(cè)精度。
為便于比較,我們還訓(xùn)練了一個(gè)有監(jiān)督學(xué)習(xí)模型來(lái)預(yù)測(cè)每個(gè)駕駛測(cè)試視頻框架的轉(zhuǎn)向角度。該模型是一種具有我們的強(qiáng)化學(xué)習(xí)模型中相同的策略網(wǎng)絡(luò)設(shè)計(jì)結(jié)構(gòu)的深度神經(jīng)網(wǎng)絡(luò)(DNN)。網(wǎng)絡(luò)輸入是四個(gè)連續(xù)框架的序列,網(wǎng)絡(luò)輸出的是動(dòng)作概率向量,向量中的元素表示直行、左轉(zhuǎn)、右轉(zhuǎn)的概率。有監(jiān)督學(xué)習(xí)模型的訓(xùn)練數(shù)據(jù)不同于用于評(píng)價(jià)模型性能的測(cè)試數(shù)據(jù)。另外,另一個(gè)基線強(qiáng)化學(xué)習(xí)模型(B-RL))也被訓(xùn)練。B-RL和我們的方法的唯一區(qū)別是虛擬世界圖像是由代理直接作為狀態(tài)輸入的。B-RL模型也在相同的真實(shí)世界駕駛數(shù)據(jù)上被測(cè)試。
數(shù)據(jù)集:真實(shí)世界駕駛視頻數(shù)據(jù)來(lái)自[4],這是一個(gè)在晴天收集的每一幀都有詳細(xì)的轉(zhuǎn)角標(biāo)注的數(shù)據(jù)集。這個(gè)數(shù)據(jù)集大概有45000張圖片,其中15000張被用作訓(xùn)練有監(jiān)督學(xué)習(xí),另外15000張被選出來(lái)進(jìn)行測(cè)試。為了訓(xùn)練我們的現(xiàn)實(shí)翻譯網(wǎng)絡(luò),我們從TORCS中的Aalborg環(huán)境收集了虛擬圖像以及他們的分割。共收集了1673張涵蓋了整個(gè)Aalborg環(huán)境的駕駛照片。
圖5:不同環(huán)境間的遷移學(xué)習(xí)。Orcle曾在CGTrac2中接受過(guò)訓(xùn)練和測(cè)試,所以它的性能是最好的。我們的模型比領(lǐng)域隨機(jī)化RL方法更有效。領(lǐng)域隨機(jī)化方法需要在多個(gè)虛擬環(huán)境中進(jìn)行培訓(xùn),這就需要大量的人工的工程工作。
場(chǎng)景分割:我們使用了[5]中的圖像語(yǔ)義分割網(wǎng)絡(luò)設(shè)計(jì)及其在CityScape圖像分割數(shù)據(jù)集[6]上經(jīng)過(guò)訓(xùn)練的分割網(wǎng)絡(luò),從[5]中分割45000張真實(shí)世界的駕駛圖像。該網(wǎng)絡(luò)在11個(gè)類別的CityScape數(shù)據(jù)集上訓(xùn)練并迭代了30000次。
圖像翻譯網(wǎng)絡(luò)訓(xùn)練:我們使用收集的虛擬-分割圖像對(duì)和分割-真實(shí)圖像對(duì)訓(xùn)練了虛擬-解析和解析-真實(shí)兩個(gè)網(wǎng)絡(luò)。如圖1所示,翻譯網(wǎng)絡(luò)采用編碼-解碼器的方式。在圖像翻譯網(wǎng)絡(luò)中,我們使用了可以從編碼器到解碼器跳躍連接兩個(gè)獨(dú)立分開層的U-Net體系結(jié)構(gòu),具有相同的輸出特征圖形狀。生成器的輸入尺寸是256×256。每個(gè)卷積層有4×4大小的卷積核,步長(zhǎng)為2。每一卷積層后都有一個(gè)slope為0.2 的LeakyReLU層,每一個(gè)反卷積層后都應(yīng)用一個(gè)Relu層。此外,在每一個(gè)卷積層與反卷積層后,都應(yīng)用一個(gè)BatchNormalization層。編碼器的最終輸出與輸出尺寸為3×256×256并接著tanh激活函數(shù)的卷積層連接。我們用了全部的1673個(gè)虛擬-分割圖像對(duì)來(lái)訓(xùn)練一個(gè)虛擬-分割網(wǎng)絡(luò)。因?yàn)?5000張真實(shí)圖像有所冗余,我們從45000張圖像中選擇了1762張圖像和它們的分割來(lái)訓(xùn)練解析-真實(shí)的圖像翻譯網(wǎng)絡(luò)。為了訓(xùn)練這個(gè)圖像翻譯模型,我們使用了Adam優(yōu)化器,初始學(xué)習(xí)率為0.0002,沖量設(shè)為0.5,batchsize設(shè)為16,訓(xùn)練了200次迭代直到收斂。
強(qiáng)化訓(xùn)練:我們訓(xùn)練中使用的RL網(wǎng)絡(luò)結(jié)構(gòu)類似于[2]中的actor網(wǎng)絡(luò),是有4個(gè)層并且每層間使用Relu激活函數(shù)的卷積神經(jīng)網(wǎng)絡(luò)(如圖3所示)。該網(wǎng)絡(luò)將4個(gè)連續(xù)RGB幀作為狀態(tài)輸入并輸出9個(gè)離散動(dòng)作,這些動(dòng)作對(duì)應(yīng)于“直線加速”,“加速向左”、“加速向右”、“直走和剎車”、“向左和剎車”、“向右和剎車”、“向左走”和“向右走”。我們用0.01個(gè)異步線程和RMSPop優(yōu)化器對(duì)強(qiáng)化學(xué)習(xí)代理進(jìn)行了訓(xùn)練,初始學(xué)習(xí)率為0.01,γ=0.9,ε=0.1。
評(píng)估:真實(shí)的駕駛數(shù)據(jù)集提供了每幀的轉(zhuǎn)向角度注釋。然而,在TORCS虛擬環(huán)境中執(zhí)行的動(dòng)作只包含“左轉(zhuǎn)”,“向右走”,“直走”或它們與“加速”“剎車”的組合。因此我們定義了一個(gè)標(biāo)簽映射策略,將轉(zhuǎn)向角度標(biāo)簽翻譯成虛擬模擬器中的動(dòng)作標(biāo)簽。我們把(-10,10)中的轉(zhuǎn)向角度與“直走”的動(dòng)作聯(lián)系起來(lái)。(由于小轉(zhuǎn)向角度不能在短時(shí)間內(nèi)導(dǎo)致明顯的轉(zhuǎn)彎),轉(zhuǎn)向角度小于-10度映射到動(dòng)作“向左”,轉(zhuǎn)向角度超過(guò)10度映射到動(dòng)作“向右”。通過(guò)將我們的方法產(chǎn)生的輸出動(dòng)作與地面真實(shí)情況相比較,我們可以獲得駕駛動(dòng)作預(yù)測(cè)的準(zhǔn)確率。
虛擬駕駛環(huán)境下的遷移學(xué)習(xí):我們進(jìn)一步進(jìn)行了另一組實(shí)驗(yàn),并獲得了不同虛擬駕駛環(huán)境之間的遷移學(xué)習(xí)的結(jié)果。在這個(gè)實(shí)驗(yàn)中,我們訓(xùn)練了三名強(qiáng)化學(xué)習(xí)代理。第一個(gè)代理在TORCS中的Cg-Track2環(huán)境中接受了標(biāo)準(zhǔn)的A3C算法訓(xùn)練,并頻繁地在相同的環(huán)境中評(píng)估其性能。我們有理由認(rèn)為這種代理的性能是最好,所以我們稱之為“Oracle”。第二個(gè)代理用我們提出現(xiàn)實(shí)翻譯網(wǎng)絡(luò)的強(qiáng)化學(xué)習(xí)方法來(lái)訓(xùn)練。但是,它在TORCS的E-track1環(huán)境中接受訓(xùn)練,然后在Cg-track2中進(jìn)行評(píng)估。需要注意的是,E-track1的視覺(jué)外觀不同于Cg-Track2。第三個(gè)代理是用類似于[22]的領(lǐng)域隨機(jī)化方法訓(xùn)練的,在Cg-track2中,該代理接受了10種不同的虛擬環(huán)境的訓(xùn)練,并進(jìn)行了評(píng)估。為了使用我們的方法訓(xùn)練,我們得到了15000張分割圖像給E-track1和Cg-track2去訓(xùn)練虛擬-解析和解析-真實(shí)的圖像翻譯網(wǎng)絡(luò)。圖像翻譯訓(xùn)練的細(xì)節(jié)和強(qiáng)化學(xué)習(xí)的細(xì)節(jié)與第3.1部分相同。
3.4 結(jié)果
圖像分割結(jié)果:我們使用在Cityscape數(shù)據(jù)集上訓(xùn)練的圖像分割模型來(lái)分割虛擬和真實(shí)的圖像。例子如圖2所示。圖中表示,盡管原始的虛擬圖像和真實(shí)的圖像看起來(lái)很不一樣,但它們的場(chǎng)景解析結(jié)果非常相似。因此將場(chǎng)景解析作為連接虛擬圖像和真實(shí)圖像的過(guò)渡過(guò)程是合理的。
現(xiàn)實(shí)翻譯網(wǎng)絡(luò)的定性結(jié)果:圖4顯示了我們的圖像翻譯網(wǎng)絡(luò)的一些有代表性的結(jié)果。奇數(shù)列是TORCS中的虛擬圖像,偶數(shù)列則被翻譯成真實(shí)的圖像。虛擬環(huán)境中的圖像似乎比被翻譯的圖像更暗,因?yàn)橛?xùn)練翻譯網(wǎng)絡(luò)的真實(shí)圖像是在晴天截取的。因此我們的模型成功地合成了與原始地面真實(shí)圖像相類似的真實(shí)圖像。
強(qiáng)化訓(xùn)練結(jié)果:在真實(shí)世界駕駛數(shù)據(jù)上學(xué)習(xí)到的虛擬-現(xiàn)實(shí)的強(qiáng)化學(xué)習(xí)結(jié)果見(jiàn)表1。結(jié)果表明,我們提出的方法總體性能優(yōu)于基線(B-RL)方法,強(qiáng)化學(xué)習(xí)代理在虛擬環(huán)境中接受訓(xùn)練,看不到任何現(xiàn)實(shí)的數(shù)據(jù)。有監(jiān)督學(xué)習(xí)方法的整體性能最好。然而,需要用大量的有監(jiān)督標(biāo)記數(shù)據(jù)訓(xùn)練。
表1 三種方法的動(dòng)作預(yù)測(cè)準(zhǔn)確率

不同虛擬環(huán)境下的遷移學(xué)習(xí)結(jié)果見(jiàn)圖5。顯然,標(biāo)準(zhǔn)A3C(Oracle)在同一環(huán)境中訓(xùn)練和測(cè)試的性能最好。然而,我們的模型比需要在多個(gè)環(huán)境中進(jìn)行訓(xùn)練才能進(jìn)行泛化的域隨機(jī)化方法更好。如[7]所述,領(lǐng)域隨機(jī)化需要大量的工程工作來(lái)使其泛化。我們的模型成功地觀察了從E-track1到Cg-Track2的翻譯圖像,這意味著,該模型已經(jīng)在一個(gè)看起來(lái)與測(cè)試環(huán)境非常相似的環(huán)境中進(jìn)行了訓(xùn)練,從而性能有所提高。
4總結(jié)
我們通過(guò)實(shí)驗(yàn)證明,利用合成圖像作為強(qiáng)化學(xué)習(xí)的訓(xùn)練數(shù)據(jù),代理在真實(shí)環(huán)境中的泛化能力比單純的虛擬數(shù)據(jù)訓(xùn)練或領(lǐng)域隨機(jī)化訓(xùn)練更好。下一步將是設(shè)計(jì)一個(gè)更好的圖像-圖像翻譯網(wǎng)絡(luò)和一個(gè)更好的強(qiáng)化學(xué)習(xí)框架,以超越有監(jiān)督學(xué)習(xí)的表現(xiàn)。
由于場(chǎng)景解析的橋梁,虛擬圖像可以在保持圖像結(jié)構(gòu)的同時(shí)被翻譯為真實(shí)的圖像。在現(xiàn)實(shí)框架上學(xué)習(xí)的強(qiáng)化學(xué)習(xí)模型可以很容易地應(yīng)用于現(xiàn)實(shí)環(huán)境中。我們同時(shí)注意到分割圖的翻譯結(jié)果不是唯一的。例如,分割圖指示一輛汽車,但它不指定該汽車的顏色。因此,我們未來(lái)的工作之一是讓解析-真實(shí)網(wǎng)絡(luò)的輸出呈現(xiàn)多種可能的外觀(比如顏色,質(zhì)地等)。這樣,強(qiáng)化學(xué)習(xí)訓(xùn)練中的偏差會(huì)大幅度減少。
我們第一個(gè)提供了例子,通過(guò)與我們提出的圖像-分割-圖像框架合成的真實(shí)環(huán)境交互,訓(xùn)練駕駛汽車強(qiáng)化學(xué)習(xí)算法。通過(guò)使用強(qiáng)化學(xué)習(xí)訓(xùn)練方法,我們可以得到一輛能置身于現(xiàn)實(shí)世界中的自動(dòng)駕駛車輛。
5.參考文獻(xiàn)
[1]Phillip Isola, Jun-Yan Zhu, Tinghui Zhou, and Alexei A. Efros. Image-to-imagetranslation with conditional adversarial networks. CoRR, abs/1611.07004, 2016.URL http://arxiv.org/abs/1611.07004.
[2]Volodymyr Mnih, Adrià Puigdomènech Badia, Mehdi Mirza, AlexGraves, Timothy P. Lillicrap, Tim Harley, David Silver, and Koray Kavukcuoglu.Asynchronous methods for deep reinforcement learning. CoRR, abs/1602.01783,2016. URL http: //arxiv.org/abs/1602.01783.
[3]Bernhard Wymann, Eric Espié, Christophe Guionneau, ChristosDimitrakakis, Rémi Coulom,and Andrew Sumner. Torcs, the open racing car simulator.Software available at http://torcs. sourceforge. net, 2000.
[4]Sully Chen. Autopilot-tensor?ow,2016. URL https://github.com/ SullyChen/Autopilot-TensorFlow.
[5] VijayBadrinarayanan, Alex Kendall, and Roberto Cipolla. Segnet: A deep convolutionalencoder-decoder architecture for image segmentation. arXiv preprintarXiv:1511.00561, 2015.
[6]MariusCordts,Mohamed Omran,Sebastian Ramos,Timo Rehfeld,Markus Enzweiler, RodrigoBenenson, Uwe Franke, Stefan Roth, and Bernt Schiele. The cityscapes datasetfor semantic urban scene understanding. CoRR, abs/1604.01685, 2016. URL http://arxiv.org/abs/1604.01685.
[7]Fereshteh Sadeghi and Sergey Levine. (cad)$?2$rl: Real single-image flightwithout a single real image. CoRR,abs/1611.04201, 2016. URL http://arxiv.org/abs/1611.04201.
-
自動(dòng)駕駛
+關(guān)注
關(guān)注
789文章
14320瀏覽量
170626 -
強(qiáng)化學(xué)習(xí)
+關(guān)注
關(guān)注
4文章
269瀏覽量
11600
原文標(biāo)題:自動(dòng)駕駛中虛擬到現(xiàn)實(shí)的強(qiáng)化學(xué)習(xí)
文章出處:【微信號(hào):IV_Technology,微信公眾號(hào):智車科技】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
低速自動(dòng)駕駛與乘用車自動(dòng)駕駛在技術(shù)要求上有何不同?

為什么自動(dòng)駕駛端到端大模型有黑盒特性?

卡車、礦車的自動(dòng)駕駛和乘用車的自動(dòng)駕駛在技術(shù)要求上有何不同?
新能源車軟件單元測(cè)試深度解析:自動(dòng)駕駛系統(tǒng)視角

劉強(qiáng)東,進(jìn)軍汽車領(lǐng)域# 京東# 自動(dòng)駕駛# 自動(dòng)駕駛出租車# 京東自動(dòng)駕駛快遞車
自動(dòng)駕駛的未來(lái) - 了解如何無(wú)縫、可靠地完成駕駛

2024年自動(dòng)駕駛行業(yè)熱點(diǎn)技術(shù)盤點(diǎn)
端到端自動(dòng)駕駛技術(shù)研究與分析
自動(dòng)駕駛汽車安全嗎?


自動(dòng)駕駛HiL測(cè)試方案案例分析--ADS HiL測(cè)試系統(tǒng)#ADAS #自動(dòng)駕駛 #VTHiL
自動(dòng)駕駛技術(shù)的典型應(yīng)用 自動(dòng)駕駛技術(shù)涉及到哪些技術(shù)

自動(dòng)駕駛HiL測(cè)試方案介紹#ADAS #自動(dòng)駕駛 #VTHiL
實(shí)現(xiàn)自動(dòng)駕駛,唯有端到端?






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論