 基于Featuretools Python庫來實現特征工程自動化的實例
基于Featuretools Python庫來實現特征工程自動化的實例

【導讀】如今機器學習正在從人工設計模型更多地轉移到自動優化工作流中,如 H20、TPOT 和 auto-sklearn 等工具已被廣泛使用。這些庫以及隨機搜索等方法都致力于尋找最適合數據集的模型,以此簡化模型篩選與調優過程,而不需要任何人工干預。然而,特征工程作為機器學習過程中最有價值的一個環節,卻幾乎一直由人工來完成。
在本文中,我們通過引用一個數據集作為例子來給大家介紹基礎知識,并給大家介紹一個基于 Featuretools Python 庫來實現特征工程自動化的實例。
前言
特征工程也可以稱作特征構造,是基于現有數據構造新特征來訓練機器學習模型的過程。可以說這個環節比我們具體使用什么模型更重要,因為機器學習算法只會基于我們提供給它的數據進行學習,所以構造與目標任務相關的特征是極其重要的(詳見論文「A Few Useful Things to Know about Machine Learning」)。
論文鏈接:
https://homes.cs.washington.edu/~pedrod/papers/cacm12.pdf
一般來說,特征工程是一個漫長的人工過程,依賴于領域知識、直覺及數據操作。這一過程是極其單調的,而且最終的特征結果會受人的主觀性和時間所限制。自動特征工程旨在幫助數據科學家基于數據集自動地構造候選特征,并從中挑選出最適合于訓練的特征。
特征工程基礎知識
特征工程意味著基于現有數據構造額外的特征,這些待分析的數據往往分布在多張相關聯的表中。特征工程需要從數據中提取信息,然后將其整合成一張單獨的表用來訓練機器學習模型。
特征構造是一個非常耗時的過程,因為每個新特征都需要經過幾個步驟去構造,特別是那些需要用到多張表信息的特征。我們可以把這些特征構造的操作合起來,分成兩個類:“轉換(transformation)”和“聚合(aggregation)”。下面我們通過幾個例子來理解一下這些概念。
“轉換”適用于單張表格,這個環節基于一個或多個現有數據列構造新的特征。例如,現在我們有下面這張客戶數據表:
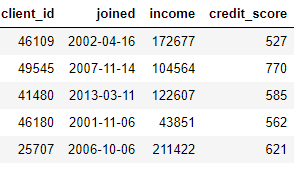
我們可以通過查找 joined 列的月份或對 income 列取自然對數來構造新特征。這些都屬于“轉換”操作,因為它們都只用了來自一張表的信息。
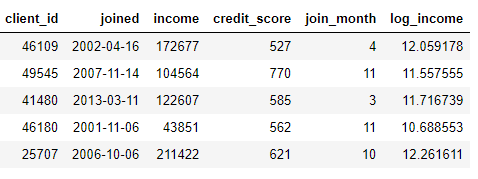
另一方面,“聚合”是需要進行跨表操作的,并且要基于一對多的關系來把觀測值分組,然后進行數據統計。例如,如果我們有另一張關于客戶貸款信息的表格,其中每位客戶可能有多筆貸款,那么我們就可以計算每位客戶貸款額的平均值、最大值和最小值等統計量了。
這一過程包括根據不同用戶對貸款數據表進行分組,計算聚合后的統計量,然后把結果整合到客戶數據中。以下是我們在 Python 中用 Pandas 執行此過程的代碼:
importpandasaspd#Grouploansbyclientidandcalculatemean,max,minofloansstats=loans.groupby('client_id')['loan_amount'].agg(['mean','max','min'])stats.columns=['mean_loan_amount','max_loan_amount','min_loan_amount']#Mergewiththeclientsdataframestats=clients.merge(stats,left_on='client_id',right_index=True,how='left')stats.head(10)
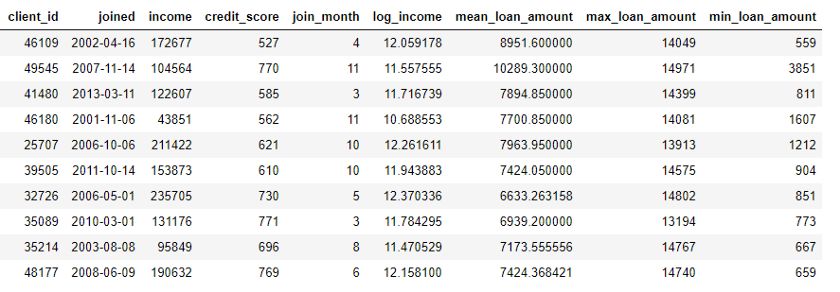
這些操作本身并不難,但如果我們有上百個變量,它們分布在幾十張表中,若要手動完成這一過程就比較困難了。理想情況下,我們想找到一個解決方案,可以自動執行多個表的轉換和聚合,并將結果數據整合到一張表中。雖然 Pandas 是非常棒的資源,但需要我們手動完成的數據操作工作量仍非常巨大!
▌特征工具(Featuretools)
幸運的是,特征工具正是我們在找的解決方案。這個開源的 Python 庫可以基于一組相關的表自動創建特征。特征工具以“深度特征合成(Deep Feature Synthesis,簡稱 DFS)”為基礎,這個方法聽起來比它本身要高級很多(之所以叫“深度特征合成”,不是因為使用了深度學習,而是疊加了多重特征)。
深度特征合成疊加了多重轉換和聚合操作,這在特征工具詞庫中被稱作特征基元 (feature primitives),用于通過多張表的數據來構造特征。和機器學習中的大多數方法一樣,這是一個以簡單概念為基礎的復雜方法。通過每次學習一個構造塊,我們就可以很好地理解這個強大的方法。
首先,我們來看一下例子中的數據。我們已經看到上面提到的部分數據集,全部的表如下所示:
clients:關于一家信用社客戶的基本信息。每位客戶只對應表中的一行數據。
loans:客戶名下的貸款。每筆貸款只對應表中的一行數據,但每位客戶名下可能有多筆貸款。
payments:還貸金額。每筆支付只對應一行數據,但每項貸款可能分多次支付。
如果我們有一個機器學習任務,比如預測某位客戶是否會還清未來的一筆貸款,我們需要把有關客戶的所有信息都整合到一張表中。這些表通過變量 client_id 和 loan_id 相互關聯,我們可以用一系列轉換和聚合來手動完成這一過程。然而我們很快就會發現,我們可以使用特征工具來將這個過程自動化。
▌實體與實體集
首先要介紹特征工具的兩個概念:實體 (entity) 和實體集 (entityset)。簡單來說,一個實體就是一張表(即 Pandas 中的一個 DataFrame)。一個實體集是指多個表的集合以及它們之間的相互關系。我們可以把實體集看作一種 Python 的數據結構,且有其專屬的方法和屬性。
我們可以在特征工具中創建一個空的實體集,如下所示:
importfeaturetoolsasft#Createnewentitysetes=ft.EntitySet(id='clients')
現在我們要把多個實體進行合并。每個實體必須帶有一個索引,即所有元素都唯一的數據列。也就是說,索引列中的每個值在表中只能出現一次。
clients 數據框(dataframe)的索引是 client_id,因為每位客戶都只對應表中的一行數據。我們可以通過如下語法把一個帶有索引的實體加入一個實體集:
#Createanentityfromtheclientdataframe#Thisdataframealreadyhasanindexandatimeindexes=es.entity_from_dataframe(entity_id='clients',dataframe=clients,index='client_id',time_index='joined')
loans 數據框也有唯一索引 loan_id,將其加入實體集的語法和處理 clients 的語法相同。然而,payments 數據框中沒有唯一的索引。若我們想把這個實體加入實體集,則需要讓 make_index = True,并指定一個索引名。雖然特征工具可以自動推斷實體中每一列的數據類型,但我們也可以通過把數據類型字典傳入參數 variable_types 來將其覆蓋。
#Createanentityfromthepaymentsdataframe#Thisdoesnotyethaveauniqueindexes=es.entity_from_dataframe(entity_id='payments',dataframe=payments,variable_types={'missed':ft.variable_types.Categorical},make_index=True,index='payment_id',time_index='payment_date')
對于這個數據框,雖然 missed 是整數,但并不是數值變量,因為它只能取兩個離散值,所以我們讓特征工具將其當作一個類別變量處理。將數據框全部加入實體集后,我們看到:
根據我們指定的修正方案,這些列的類型都被正確識別了。下一步,我們需要指定實體集中各個表之間的關聯。
▌表之間的關聯
研究兩表之間關系的最好方法是與父子關系進行類比。這是一種一對多的關系:每位父親可能有多個孩子。從表的角度來看,父表中的每一行對應一位父親,但子表可能有多行數據,就像同一位父親的多個孩子。
例如,在我們的數據集中,clients 是 loans 的父表。每位客戶只對應 clients 表中的一行數據,但可能對應 loans 表中的多行數據。同樣,loans 是 payments 的父表,因為每筆貸款可能包含多筆支付。父表通過共有的變量與子表相連接。當執行聚合操作時,我們根據父表的變量對子表進行歸類,并計算每個子表的統計量。
若要標明特征工具中的關聯,我們只需指定連接兩張表的變量。表 clients 和表 loans 是通過變量 client_id 相關聯的,表 loans 和表 payments 通過 loan_id 相關聯。可通過如下語法創建關聯并將其加入實體集:
#Relationshipbetweenclientsandpreviousloansr_client_previous=ft.Relationship(es['clients']['client_id'],es['loans']['client_id'])#Addtherelationshiptotheentitysetes=es.add_relationship(r_client_previous)#Relationshipbetweenpreviousloansandpreviouspaymentsr_payments=ft.Relationship(es['loans']['loan_id'],es['payments']['loan_id'])#Addtherelationshiptotheentitysetes=es.add_relationship(r_payments)es
該實體集現在包括三個實體以及連接這些實體之間的關系。加入實體并標明關聯后,我們的實體集就完整了,并做好了構造新特征的準備。
▌特征基元
在正式進行深度特征合成之前,我們需要理解特征基元這個概念。我們已經知道了特征基元是什么,但也只是了解用什么名字來稱呼它們。下面是我們構造新特征時的基本操作:
聚合:基于父表與子表的關聯(一對多)完成的系列操作,即根據父表對子表進行分組并計算其統計量。例如,根據 client_id 對 loan 表進行分組,并找到每位客戶最大的貸款數額。
轉換:對一張表中一列或多列進行的操作。例如,計算一張表中兩列的差值或計算一列的絕對值。
在特征工具中,我們可以通過單個基元或者疊加多個基元來構造新特征。下面是特征工具中一些特征基元的列表(我們也可以自定義基元):
▌特征基元
這些基元可以拿來單獨使用或者結合起來構造新的特征。根據特定的基元,我們可以使用 ft.dfs 函數(即深度特征合成)來構造特征。我們將所選的 trans_primitives(轉換)和 agg_primitives(聚合)傳入 entityset(實體集)和 target_entity(目標實體),即我們想要添加特征的表:
#Createnewfeaturesusingspecifiedprimitivesfeatures,feature_names=ft.dfs(entityset=es,target_entity='clients',agg_primitives=['mean','max','percent_true','last'],trans_primitives=['years','month','subtract','divide'])
得到的結果是一個含有新特征的客戶數據框(因為我們把用戶當作了 target_entity)。例如,若我們知道每位用戶加入的月份,這可以作為一個轉換特征基元:
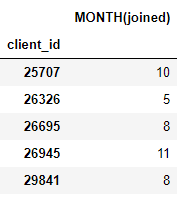
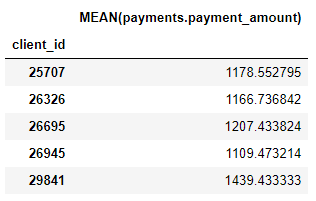
我們也有許多聚合基元,如每位客戶的平均支付額:
雖然我們只列舉了一部分特征基元,但實際上特征工具通過結合與疊加這些基元構造了許多新的特征。
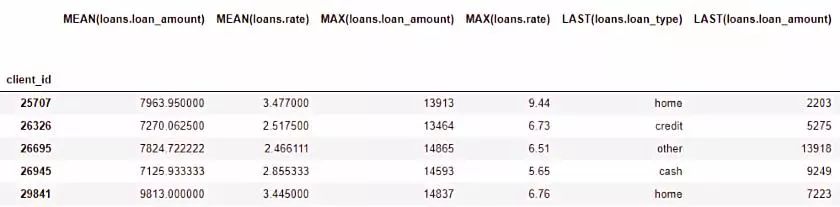
完整的數據框包含了793個新特征!
▌深度特征合成
現在我們已經做好理解深度特征合成的全部準備了。實際上,我們在之前執行函數時已經使用過深度特征合成了!深度特征是指通過疊加多個基元得到的特征,深度特征合成是指構造這些特征的過程。一個深度特征的深度是為構造這個特征所使用的基元數目。
例如,MEAN(payments.payment_amount)列是一個深度為 1 的深度特征,因為它在構造過程中只使用了一個聚合基元。LAST(loans(MEAN(payments.payment_amount)) 是一個深度為 2 的特征,它由兩個聚合基元疊加構成:將 LAST 疊加在了 MEAN 上。這個特征代表客戶最近一筆支付額的平均值。
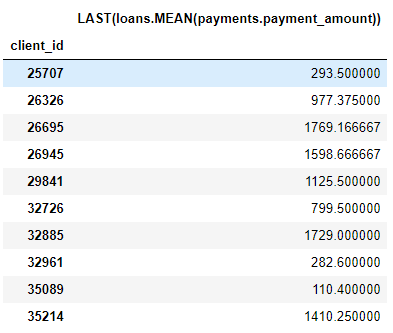
我們可以疊加特征到任何想達到的深度,但事實上,我從來沒有用過深度超過 2 的特征。關于這一點很難解釋清楚,但我鼓勵感興趣的人嘗試更進一步的探索。
我們無需手動指定特征基元,特征工具可以幫助我們自動選擇特征。為此,我們同樣使用 ft.dfs 函數來調用但無需傳入任何特征基元:
#Performdeepfeaturesynthesiswithoutspecifyingprimitivesfeatures,feature_names=ft.dfs(entityset=es,target_entity='clients',max_depth=2)features.head()
特征工具構造了許多供我們使用的新特征。雖然這一過程可以自動構造新特征,但它不會取代數據科學家的位置,因為我們還要清楚如何使用這些特征。例如,如果我們的目標是預測某位客戶是否會償還貸款,那么我們要找出與指定結果相關度最高的特征。此外,如果我們有領域知識,則可以利用領域知識來選出特定的特征基元,或通過深度特征合成從候選特征中得到種子特征。
▌下一步
自動特征工程解決了一個問題,但也制造了另一個問題:特征過多。雖然在擬合模型前我們很難說哪些特征是重要的,但肯定不是所有特征都與目標任務相關。而且,特征過多可能會導致模型性能很差,因為不那么重要的特征會影響到那些更重要的特征。
由特征過多導致的問題又被公認為“維度的詛咒”。對于模型來說,特征數量上升了(即數據維度增加了),學習特征和目標之間的映射規則也會變得更加困難。實際上,使模型有良好表現所需的數據量與特征數目呈指數關系。
“維度的詛咒”可以通過特征降維(也被稱為特征選擇)來減輕:這是一個剔除不相關特征的過程。我們可以通過多種途徑實現:主成分分析 (PCA)、SelectKBest、使用模型的特征重要性或使用深度神經網絡來自動編碼。和今天要探討的內容相比,特征降維應該另起一篇文章來單獨討論更合適。到現在為止,我們已經知道如何使用特征工具,從諸多數據表中輕松構造大量的特征了!
總結
同機器學習中的許多主題一樣,基于特征工具的自動特征工程是一個以簡單概念為基礎的復雜方法。基于實體集、實體和關聯等概念,特征工具可以通過深度特征合成來構造新的特征。深度特征合成將包含了表間一對多關聯的“聚合”特征基元依次疊加,“轉換”函數被用于單張表中的一列或多列數據,以此來從多張表中構造新的特征。
在之后的文章中,AI科技大本營也會介紹在實際應用(如 Kaggle 競賽)中如何使用這項技術。模型的好壞取決于我們為它提供的數據,而自動特征工程有助于使特征構造過程的效率更高。希望本文介紹的自動特征工程可以幫到大家。
關于特征工具的更多信息,包括更高級的應用方法,可以查看在線文檔。
-
自動化
+關注
關注
29文章
5784瀏覽量
84873 -
機器學習
+關注
關注
66文章
8503瀏覽量
134618 -
python
+關注
關注
56文章
4827瀏覽量
86750
原文標題:基于Python的自動特征工程——教你如何自動創建機器學習特征
文章出處:【微信號:rgznai100,微信公眾號:rgznai100】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
招聘自動化、電氣自動化、自動化控制工程師
【上海】獵頭推薦職位-自動化測試工程師(java/python)
python自動化控制設備 精選資料分享
電子設計自動化(EDA)是什么
Python成為軟件工程師的最愛
自動化立體庫結構是如何組成的
分享10個實用的Python自動化腳本
使用Python腳本實現自動化運維任務
使用Python實現功能測試自動化

Python 模擬鍵盤鼠標的方式實現自動化





 工商網監
工商網監
評論