 從數學角度來充分了解神經網絡是如何工作的
從數學角度來充分了解神經網絡是如何工作的
如今,即便是結構非常復雜的神經網絡,只要使用Keras,TensorFlow,MxNet或PyTorch等先進的專業庫和框架,僅需幾行代碼就能輕松實現。而且,你不需要擔心權重矩陣的參數大小,也不需要刻意記住要用到的激活函數公式,這可以極大的避免我們走彎路并大大簡化了建立神經網絡的工作。然而,我們還是需要對神經網絡內部有足夠的了解,這對諸如網絡結構選擇、超參數調整或優化等任務會有很大幫助。本文我們將會從數學角度來充分了解神經網絡是如何工作的。
圖1. 訓練集的可視化
如圖1所示,是一個典型的數據二分類問題,兩類的點分別形成了各自的圓,這種數據分布對于許多傳統的機器學習算法來說很難,但對于輕量級的神經網絡卻很容易勝任。為了解決該問題,我們將使用具有圖2所示結構的神經網絡,包括五個全連接層,每層具有不同數量的單元。對于隱藏層,我們將使用ReLU作為其激活函數,而使用Sigmoid作為輸出層。 這是一個非常簡單的結構,但對于我們要解決的問題而言卻已經擁有足夠的能力了。
圖2. 神經網絡結構
正如之前提到的,只需幾行代碼便足以創建和訓練一個模型,就能實現測試集中的分類結果幾乎達到100%的準確度。而我們的任務,就是為所選的網絡設定超參數,如層數、每層的神經元數、激活函數和迭代次數等。現在讓我們看一個很酷的可視化,來看看學習過程究竟發生了什么。
圖3. 訓練過程可視化
什么是神經網絡?
讓我們首先回答這個關鍵問題:什么是神經網絡? 它是一種在生物學啟發下構建計算機程序的方法,能夠學習并找到數據中的聯系。 如圖2所示,網絡是按層排列的“神經元”的集合,通過權重互聯互通的聯系在了一起形成網絡。
每個神經元接收一組編號從1到n 的x值作為輸入,用來計算預測的y(^)值。向量x實際上包含來自訓練集的m個樣本之一的特征值。比較重要的是,每個神經元都有自己的一組參數,通常稱為w(權重列向量)和b(偏差),它們會學習過程中發生變化。每次迭代中,神經元基于其當前權重向量w來計算輸入向量x加權平均后的值并加上偏置b。最后,該計算結果會通過非線性激活函數g,本文的后面部分會提及一些最常用的激活函數。
圖4. 單個神經元
我們已經對單個神經元的工作有所了解了,下面讓我們再深入學習一下如何對整個神經網絡層進行計算,并將所有圖進行向量化,最后將計算合并到矩陣方程中。 為了統一符號,方程中[l]表示為所選層,下標表示該層中神經元的索引。
圖5 單層
對單個單元而言,我們使用x和y(^)分別表示特征列向量和預測值。然后使用向量a表示相應的層,而向量x對應層0的輸入,即輸入層。層中的每個神經元根據以下等式執行計算:
為了清楚起見,以第2層為例展開:
如您所見,對于每層我們都必須執行類似操作,那么使用for循環效率就會不高。為了加快計算速度,我們將使用向量化的方法。 首先,通過將轉置后的權重w行向量堆疊在一起就 構建得到矩陣W. 類似地,我們將層中的每個神經元的偏置堆疊在一起,從而得到列向量b。 這樣我們就能構建出一個矩陣方程,能夠一次便對層中所有神經元進行計算。下面我們寫下使用的矩陣和向量的維數。
到目前為止,得到的方程只適用于這一個例子。 在神經網絡的學習過程中,您通常使用大量數據,最多可達數百萬條。因此,下一步要做的將是跨多個示例的矢量化。 假設我們的數據集包含m個示例,每個示例都具有nx特征。首先,我們將每層的列向量x,a和z組合在一起,分別創建X,A和Z矩陣,然后我們重寫先前的方程。
激活函數
激活函數是神經網絡的關鍵元素之一。沒有它們,我們的神經網絡只能成為線性函數的組合,就只能具備有限的擴展性,也不會擁有超越邏輯回歸的強大能力。引入非線性元素則會使得學習過程中擁有更大的靈活性和創建復雜表示的功能。 激活函數也會對學習速度產生重大影響,這也是主要的選擇標準之一。下圖6中,顯示了一些常用的激活函數。目前,最受歡迎的隱藏層可能是ReLU。但如果我們要處理二分類問題時,尤其是我們希望從模型返回的值在0到1的范圍內時,我們有時仍然使用sigmoid激活函數。
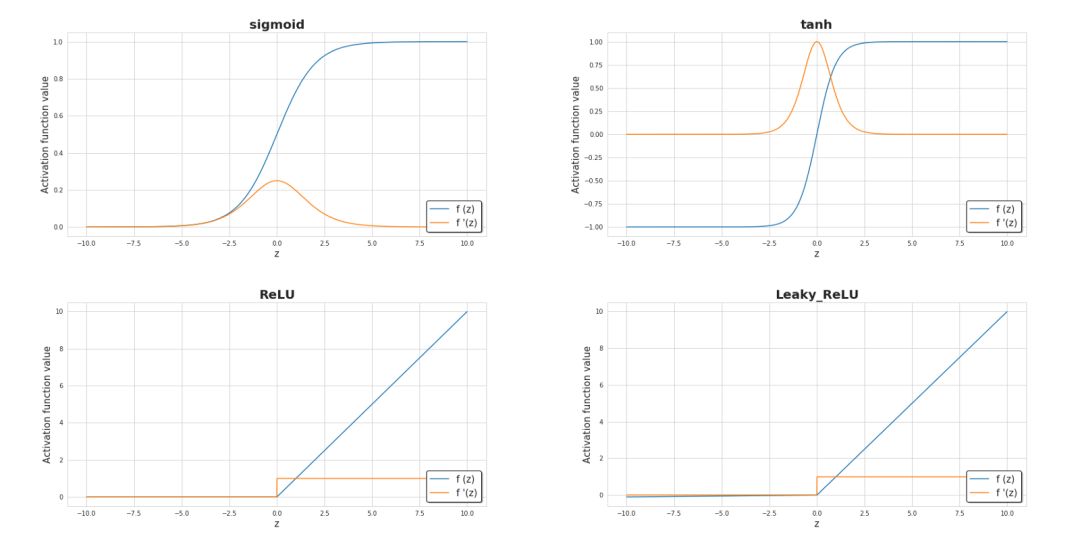
圖6.目前最流行的激活函數及其衍生的圖解
損失函數
我們主要通過損失函數的值來觀察學習過程的進展。一般來說,損失函數旨在顯示我們與“理想”解決方案的距離。在本文的例子中,我們使用二進制交叉熵作為損失函數,但根據不同的問題可以應用不同的函數。本文使用的函數由下列公式描述,并且在學習過程中其值的變化過程可視化顯示在圖7中,顯示了損失函數如何隨迭代次數而準確度逐漸提高。
圖7.學習過程中準確度和損失函數值的變化
神經網絡是如何學習的?
整個學習過程是圍繞如何調整參數W和b使得損失函數最小化進行的。為了實現這一目標,我們將結合微積分并使用梯度下降法來找到函數最小值。在每次迭代中,相對于神經網絡的每個參數計算損失函數對應的偏導數值。導數具備很好的描述函數斜率的能力。通過可視化,我們可以清楚地看到梯度下降是如何改變參數變量使得目標函數的值在圖中向下移動。如圖8所示,可以看到每次成功的迭代都朝著最小值點方向進行。在我們的神經網絡中,它以相同的方式工作,每次迭代時計算的梯度代表應該移動的方向。主要區別在于,在我們的神經網絡范例中,我們有更多的參數需要操作。因此變得更為復雜,那么究竟怎樣才能計算出最優參數呢?
圖8. 模型訓練中的梯度下降
這時候我們就需要引入計算最優參數的算法——反向傳播(BP),它允許我們計算一個非常復雜的梯度,也正是我們需要的。根據以下公式來調整神經網絡的參數。
在上面的等式中,α表示學習率,這個超參數可以自定義調整。選擇合適的學習率是至關重要的,如果我們將其設置得太低,那么我們的神經網絡會學習得非常慢,如果設置得太高那么損失函數就不會到達最小值了。 dW和db分別是W和b相對于損失函數的偏導數,可以上述公式推導而的。 dW和db的尺寸也是分別和W和b對應的。圖9顯示了神經網絡中的操作順序,我們可以清楚地看到前向傳播和反向傳播是如何協同工作以優化損失函數的。
圖9. 前向傳播和反向傳播
通過前向傳播的預測和反向傳播糾正信號,就能不斷的根據數據來調整網絡,最終實現了神經網絡從數據中學習的能力。
在使用神經網絡時,至少要了解內部運行過程的基礎知識才能得心應手。盡管在本文中提到了一些比較重要的知識,但這僅僅是冰山一角。 如果希望深入理解神經網絡的運行機理,請使用像Numpy一樣的基礎工具來編寫一個自己的小型神經網絡吧!你會得到想不到的收獲!
-
神經網絡
+關注
關注
42文章
4810瀏覽量
102894 -
函數
+關注
關注
3文章
4371瀏覽量
64277 -
神經元
+關注
關注
1文章
368瀏覽量
18767
原文標題:從數學角度看神經網絡是如何工作的?
文章出處:【微信號:thejiangmen,微信公眾號:將門創投】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄





 工商網監
工商網監
評論