") 在強(qiáng)化學(xué)習(xí)的表示空間中引入規(guī)劃能力的思路
在強(qiáng)化學(xué)習(xí)的表示空間中引入規(guī)劃能力的思路
編者按:Microsoft Semantic Machines資深研究科學(xué)家、UC Berkeley計(jì)算機(jī)科學(xué)博士Jacob Andreas以控制問題為例,討論了在強(qiáng)化學(xué)習(xí)的表示空間中引入規(guī)劃能力的思路。
以神經(jīng)網(wǎng)絡(luò)為參數(shù)的智能體(例如Atari玩家智能體)看起來普遍缺乏規(guī)劃的能力。蒙特卡洛反應(yīng)式智能體(例如原始深度Q學(xué)習(xí)者)明顯是個(gè)例子,甚至于具備一定隱藏狀態(tài)的智能體(比如NIPS的MemN2N論文)看上去也是這樣。盡管如此,類似規(guī)劃的行為已成功應(yīng)用于其他深度模型,尤其是在文本生成上——集束解碼,乃至集束訓(xùn)練,看上去對(duì)機(jī)器翻譯和圖像描述而言不可或缺。當(dāng)然,對(duì)處理并非玩具級(jí)別的控制問題的人而言,真實(shí)的規(guī)劃問題無處不在。
任務(wù)和運(yùn)動(dòng)規(guī)劃是一個(gè)好例子。有一次我們需要求解一個(gè)持續(xù)控制問題,但是直接求解(通過通用控制策略或類似TrajOpt的過程)太難了。因此我們轉(zhuǎn)而嘗試高度簡化、手工指定的問題編碼——也許是丟棄了幾何信息的STRIPS表示。我們解決了(相對(duì)簡單的)STRIPS規(guī)劃問題,接著將其投影回運(yùn)動(dòng)規(guī)劃空間。該投影可能不對(duì)應(yīng)可行的策略!(但我們想讓在任務(wù)空間中可行的策略在運(yùn)動(dòng)空間中盡量可行。)我們持續(xù)搜索計(jì)劃空間,直到找到在運(yùn)動(dòng)空間中同時(shí)奏效的解。
其實(shí)這不過是一個(gè)由粗到細(xì)的剪枝計(jì)劃——我們需要可以丟棄明顯不可行的規(guī)劃的低成本方法,這樣我們可以將全部計(jì)算資源集中到確實(shí)需要模擬的情形上。
如圖所示:
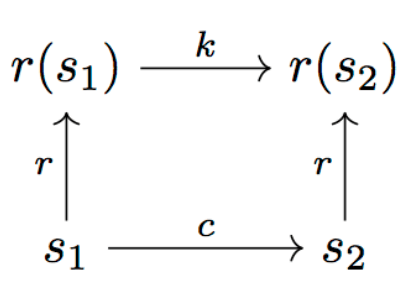
上圖中,r為表示函數(shù),c為成本函數(shù)(我們可以將其視為用0-1表示可行性判斷的函數(shù)),k為“表示成本”。我們想要確保r在運(yùn)動(dòng)成本和任務(wù)成本上“接近同構(gòu)”,也就是c(s1, s2) ≈ k(r(s1), r(s2))。
就STRIPS版本而言,假定我們手工給出r和k。不過,我們可以學(xué)習(xí)一個(gè)比STRIPS更好的求解任務(wù)和運(yùn)動(dòng)規(guī)劃問題的表示嗎?
從規(guī)劃樣本中學(xué)習(xí)
首先假定我們已經(jīng)有了訓(xùn)練數(shù)據(jù),數(shù)據(jù)為成功的運(yùn)動(dòng)空間路點(diǎn)序列(s1, s2, …, s*)。那么我們可以直接最小化以下目標(biāo)函數(shù):
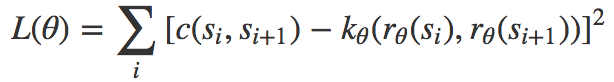
最容易的情形是表示空間(r的對(duì)應(yīng)域)為?d;這時(shí)我們可以操作d以控制表示質(zhì)量和搜索表示空間的成本之間的平衡。
問題:如果我們只觀測到常數(shù)c(如果只看到好的解,可能會(huì)出現(xiàn)這種情形),那就沒有壓力學(xué)習(xí)不那么微不足道的k。所以我們也需要不成功的嘗試。
解碼
給定訓(xùn)練好的模型,我們通過以下步驟求解新實(shí)例:
從表示空間中取樣一個(gè)滿足r(s*) ≈ rn的成本加權(quán)路徑(r1,r2, ..., rn)。
將每個(gè)表示空間轉(zhuǎn)換r1→ r2映射到運(yùn)動(dòng)空間轉(zhuǎn)換s1→ s2,且滿足r(s2) ≈ r2。(如果r是可微的,那么這很容易表達(dá)為一個(gè)優(yōu)化問題,否則需要麻煩一點(diǎn)表達(dá)為策略。)
重復(fù)上述過程,直到其中之一的運(yùn)動(dòng)空間解可行。
在涉及計(jì)算路徑的每一個(gè)步驟(不管是在r-空間還是在s-空間),我們都可以使用范圍廣泛的技術(shù),包括基于優(yōu)化的技術(shù)(TrajOpt),基于搜索的技術(shù)(RRT,不過大概不適用于高維情形),或者通過學(xué)習(xí)以目標(biāo)狀態(tài)為參數(shù)的策略。
直接從任務(wù)反饋學(xué)習(xí)
如果我們沒有良好的軌跡可供學(xué)習(xí),怎么辦?只需修改之前的上面兩步——從隨機(jī)初始值開始,展開包含預(yù)測的r和s序列,接著生成由預(yù)測值r和s構(gòu)成的序列,然后將其視作監(jiān)督,同樣更新k以反映觀測到的成本。
提示性搜索
到目前為止,我們假設(shè)可以直接暴力搜索表示空間,直到我們接近目標(biāo)。沒有機(jī)制強(qiáng)制表示空間的接近程度同樣接近于運(yùn)動(dòng)空間(除了r可能帶來的平滑性)。我們可能想要增加額外的限制,如果根據(jù)定義ri距離rn不止3跳,那么||ri? rn||>||ri+1?rn||。這立刻提供了在表示空間中搜索的便利的啟發(fā)式算法。
我們也可以在這一階段引入輔助信息——也許是以語言或視頻形式提供的意見。(接著我們需要學(xué)習(xí)另一個(gè)從意見空間到表示空間的映射。)
模塊化
在STRIPS領(lǐng)域,定義一些不同的原語(如“移動(dòng)”、“抓取”)是很常見的做法。我們也許想給智能體提供類似的不同策略的離散清單,清單上的策略列出了轉(zhuǎn)換成本k1, k2, …。現(xiàn)在搜索問題同時(shí)牽涉(連續(xù)地)選擇一組點(diǎn),和(離散地)選擇用于在點(diǎn)之間移動(dòng)的成本函數(shù)/運(yùn)動(dòng)原語。這些原語對(duì)應(yīng)的運(yùn)動(dòng)可能受限于配置空間中某個(gè)(手工選取)的子流形(比如,僅僅移動(dòng)末端執(zhí)行器,僅僅移動(dòng)第一個(gè)關(guān)節(jié))。
感謝Dylan Hadfield-Menell關(guān)于任務(wù)和運(yùn)動(dòng)規(guī)劃的討論。
-
神經(jīng)網(wǎng)絡(luò)
+關(guān)注
關(guān)注
42文章
4809瀏覽量
102827 -
機(jī)器翻譯
+關(guān)注
關(guān)注
0文章
140瀏覽量
15133 -
強(qiáng)化學(xué)習(xí)
+關(guān)注
關(guān)注
4文章
269瀏覽量
11517
原文標(biāo)題:強(qiáng)化學(xué)習(xí)表示空間中的規(guī)劃
文章出處:【微信號(hào):jqr_AI,微信公眾號(hào):論智】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
深度強(qiáng)化學(xué)習(xí)實(shí)戰(zhàn)
基于強(qiáng)化學(xué)習(xí)的飛行自動(dòng)駕駛儀設(shè)計(jì)
強(qiáng)化學(xué)習(xí)在RoboCup帶球任務(wù)中的應(yīng)用劉飛
將深度學(xué)習(xí)和強(qiáng)化學(xué)習(xí)相結(jié)合的深度強(qiáng)化學(xué)習(xí)DRL
基于分層強(qiáng)化學(xué)習(xí)的多Agent路徑規(guī)劃
人工智能機(jī)器學(xué)習(xí)之強(qiáng)化學(xué)習(xí)
強(qiáng)化學(xué)習(xí)在自動(dòng)駕駛的應(yīng)用
什么是強(qiáng)化學(xué)習(xí)?純強(qiáng)化學(xué)習(xí)有意義嗎?強(qiáng)化學(xué)習(xí)有什么的致命缺陷?

量化深度強(qiáng)化學(xué)習(xí)算法的泛化能力

一文詳談機(jī)器學(xué)習(xí)的強(qiáng)化學(xué)習(xí)
83篇文獻(xiàn)、萬字總結(jié)強(qiáng)化學(xué)習(xí)之路
強(qiáng)化學(xué)習(xí)在智能對(duì)話上的應(yīng)用介紹
《自動(dòng)化學(xué)報(bào)》—多Agent深度強(qiáng)化學(xué)習(xí)綜述






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論