 細數華為海思芯片和ARM內核
細數華為海思芯片和ARM內核

很多人對于華為海思芯片非常感興趣,相關的討論爭論自然也不會少,在論壇上有時候也會看到。有人把它吹上天,也有人說它毫無技術含量。我看完之后痛心疾首,覺得很多人說的很多方面都是不對的。所以獻上此文,客觀介紹一下芯片的設計制造流程。
賣弄前先自我介紹順便聲明一下,本人海思新員工,但不從事芯片設計類崗位,只是最近聽過一個關于芯片的培訓,再加上本人對芯片如何實現等問題也比較好奇,所以搜集過一些非官方、不科學資料,發表一下淺鄙之見。
一、工藝制程并不是越小越好
OK,廢話不多說,對于芯片,先說一些自己感興趣的,可能涉及海思的不多。經常能聽到有人爭論40nm工藝、28nm工藝,14nm工藝,那么這個多少nm指得是什么呢?
它指的是mos管在硅片上的大小,mos管就是晶體管,它是組成芯片的最小單位,一個與非門需要4個mos管組成,一般一個ARM四核芯片上有5億個左右的mos管。世界上第一臺計算機用個是真空管,效果和mos管一樣,但是真空管的大小有兩個拇指大,而現在最先進工藝蝕刻的mos管只有7nm大。
說到這里,大家一定和我一樣,非常好奇如何在一個15mm*15mm的正方形硅片上制作出5億個大小僅為40nm的mos管。如果要用機械的方法完成這一過程,世界上很難有這么精密的儀器,可以雕刻出nm級的mos管,就算有,要雕刻出5億個,所需要的成本、時間也是難以估計的。
借助光可以在硅片上蝕刻下痕跡,掩膜就可以控制硅片上哪些部分會被蝕刻。掩膜覆蓋的地方,光照不到,硅片不會被蝕刻。硅片被蝕刻后,再涂上氧化層和金屬層,再蝕刻,反復多次,硅片就制造好了。一般來說,制作硅片需要蝕刻十幾次,每次用的工藝、掩膜都不一樣。幾次蝕刻之間,蝕刻的位置可能會有偏差,如果偏差過大,出來的芯片就不能用了,偏差需要控制在幾個nm以內才能保證良品率,所以說制作硅片用的技術是人類目前發明的最精密的技術。
芯片可以靠掩膜蝕刻,批量生產,但是掩膜必須用更高精度的機器慢慢加工制作,成本非常高,一塊掩膜造價十萬美元。制造一顆芯片需要十幾塊不同的掩膜,所以芯片制造初期投入非常大,動輒幾百萬美元。芯片試生產過程,叫做流片,流片也需要掩膜,投入很大,流片之前,誰都不知道芯片設計是否成功,有可能流片多次不成功。所以國內能做高端芯片的公司真沒幾家,光是掩膜成本就沒幾個公司支付得起。
芯片量產后,成本相對來說就比較低了,好的掩膜非常大,直徑30厘米,可以同時生產上百塊芯片。芯片如果出貨量很大,利潤還是非常高的,像英特爾的芯片,賣1000多一塊,可能平均制造成本100不到。但如果出貨量很少,那芯片平均制造成本就高得嚇人,幾百萬美元打水漂是很正常的。
海思芯片價格有沒有競爭力,還得看華為手機出貨量大不大。看到有人問20nm好還是40nm好,從大小上來看顯而易見20nm好。20nm意味著mos管大小只有40nm的1/4。mos管工作時是一個充電放電的過程,mos管越小,它充電需要的電量越小,所以功耗越小。而且mos管小之后,門電路密度就大,同樣大小芯片能放的mos管數就越多,性能空間越大。40nm工藝門電路密度是65nm的2.35倍。但以上都是在不考慮漏電和二級效應的情況下的理論數據。
當然,IC尺寸縮小也有其物理限制,當我們將晶體管縮小到 20 奈米左右時,就會遇到量子物理中的問題,讓晶體管有漏電的現象,抵銷縮小 L 時獲得的效益。作為改善方式,就是導入 FinFET(Tri-Gate)這個概念,如下圖。在 Intel 以前所做的解釋中,可以知道藉由導入這個技術,能減少因物理現象所導致的漏電現象。
為什么會有人會說各大廠進入 10 奈米制程將面臨相當嚴峻的挑戰,主因是 1 顆原子的大小大約為 0.1 奈米,在 10 奈米的情況下,一條線只有不到 100 顆原子,在制作上相當困難,而且只要有一個原子的缺陷,像是在制作過程中有原子掉出或是有雜質,就會產生不知名的現象,影響產品的良率。
如果無法想象這個難度,可以做個小實驗。在桌上用 100 個小珠子排成一個 10×10 的正方形,并且剪裁一張紙蓋在珠子上,接著用小刷子把旁邊的的珠子刷掉,最后使他形成一個 10×5 的長方形。這樣就可以知道各大廠所面臨到的困境,以及達成這個目標究竟是多么艱巨。
再說說二級效應吧,學過初中物理的都知道一個最簡單電路的組成,包括電源、導線、電阻。接通電源,電流就瞬間流過電阻。如果把電阻換成電感,則電感會有一個逐漸充電的過程,這種情況下,電流就不是瞬間流過電感。
其實電阻也有感抗,只是非常微小,可以忽略不計。但如果接在電阻上的電壓非常微小,電流量非常微小,那此時,感抗就不能被忽略不計了。二級效應在芯片制程非常小時(28nm以下),非常明顯,mos管由于電壓低,電流小,充電受到感抗的影響比40nm大,充電速度慢。芯片想要達到高頻率,mos管要加載更高的電壓,這樣就增加了功耗。漏電也是低制程的一個副作用,也需要提供芯片的功耗才能克服。所以低制程帶來的功耗優勢就被漏電和二級效應扳回去了很多。
當然,新的工藝、好的工藝可以部分解決上面兩個問題,不同工藝用的物理、化學材料不同,工藝流程也不同。高通四核用的是老28nm工藝,目前來看,這個28nm工藝相比40nm工藝優勢不大。
然后制程方面,目前聽過的最先進的制程是7nm,但這個制程只存在于實驗室里,遠遠沒有達到大規模量產的需要。低制程有些困難是難以克服的,學過物理的都知道光的衍射,低制程意味著掩膜透孔會非常小,衍射會非常嚴重,這樣肯定是無法蝕刻硅片的。這個問題也許可以通過使用電子射線或者其他粒子射線來蝕刻硅片解決,但這是那幫孫子去想的問題了。
二、芯片設計考驗公司技術水平
說說設計吧,芯片設計分為前端設計和后端設計。前端設計就像做建筑中的畫設計圖,芯片的邏輯、模塊、門電路關系都是前端設計完成的。后端設計則是布局布線,芯片做出來,最終是個實際的東西,那每個mos管擺放什么位置,每一條線怎么連,這個都是后端設計決定的。前端設計沒啥好說的,雖然技術含量非常高。
我就說說后端設計吧,有趣一點。5億個mos管的布局布線,雖然很多用的是IP硬核,別的廠商已經幫忙做好了,但這絕對不是一個輕松的活。拿導線來說,兩條導線在一個硅平面上不能交叉,它們可不像我們家里的導線,包了一層塑料。如果把5億個mos管的導線放在一個平面上,還要讓某些連接、某些不連接,還不能交叉,這絕對是不可能的。
事實上,一個芯片布線,從上到下可能有十幾層。每一層都是蜘蛛網一樣的布線,如果我們化身成一個1nm的小人,進入芯片的世界走一圈,那絕對會發現那是一個非常宏偉,非常不可思議的世界。后端設計除了要保證線路正確連接,還要使模塊占用面積小,功耗小,規避二級效應,要求是很高的。名牌大學畢業搞后端,搞個兩年也才剛剛入門。
再說說仿真,芯片在流片之前,誰都不知道它長什么樣子,更難以去揣測它設計是否成功、合理,流片成本又非常高,不可能為了驗證設計是否成功去流片。這個時候就需要用到仿真,用計算機去模擬電路的運行情況。仿真貫穿芯片設計的始末,有前端仿真、后端仿真、模擬仿真、數字仿真…仿真脫離不了計算機仿真軟件,像Sysnopys、Cadence它們是芯片設計、驗證軟件領域的巨擘,海思每年付給他們的費用我不知道,但起碼千萬級別。
仿真是一個需要超高性能計算機的任務,海思在IT中心有大量高性能計算機組成云計算資源,但在面對大型仿真時還是很吃力,跑幾個小時只能模擬出芯片幾秒鐘的運行情況。因為要跑仿真,這些計算機一天24小時都在跑。順便說一下我們部門一個Linux服務器的配置,英特爾4核4GCPU,內存16G。
這個只是一個打雜的服務器,放個數據庫,編譯幾個軟件。海思小網的Solaris接入服務器同時有上百人在上面辦公。從這點也可以看出,做芯片投入還是非常大的,就光這些軟件、硬件成本,每個人每年要花掉公司幾十萬。
再說說海思目前的水平,我也不想吹牛,確實和美國那些公司比起來有很大差距。畢竟80年代,人家芯片設計、制作都已經非常成熟的時候,我們才有第一臺計算機。比如K3V2,它上面很多模塊都是別人的,公司花了大筆錢買了版權,這個叫IP核。
IP核分軟核和硬核,現在貌似也有軟硬結合的核…它是什么東西呢?比如ARM指令授權,它就是軟核,它只規定了CPU的指令集,好比建橋,它只告訴你橋應該建多長、多寬、大概長什么樣,但是具體細節沒有,不告訴你電路在芯片上怎么擺放,怎么連線。軟核的好處是給了很大的發揮空間,模仿、抄襲也簡單,以后做類似東西可以參考。硬核就是它只告訴你電路在芯片上具體長什么樣子,把它擺上去用就行了。硬核的好處是它一般都是經過其它芯片驗證的,很容易了解它的具體性能。但你幾乎不可能修改它,也很難了解它的實現細節,畢竟有幾千萬個mos管,人怎么分析。
海思自主IP核不多,主要集中在基帶方面和數字電視機頂盒方面,這兩塊還是比較牛的,海思機頂盒芯片占世界份額90%以上(聽老大說)。像K3V2大部分還是在搭積木,搭個USB核,搭一個音頻解碼核…但客觀地說,現在芯片設計分工越來越細,每個公司只是完成其中一小部分,就算是高通,也用了很多其他公司的IP核。
一個公司想把所有活都干了,那絕對是不可能的,就算做到了,它的芯片也不會有競爭力。其實玩搭積木也是很有技術含量的,海思肯定是國內玩得最好的公司。目前公司的一個目標也是把越來越多的模塊自主化,但是需要時間。
先從最底層芯片說起,開頭說了mos管,現在說說與非門。上面說了mos管是芯片的最小單位,但這是對于芯片制造廠而言的。芯片設計時不會直接畫mos管,在數字電路中,使用的最小單位是門電路,與非門就是用得最廣泛的一種。一個與非門大概要4個mos管組成,與非門大家應該都非常熟悉。如下圖:
大家都知道,家里的開關有兩種狀態嘛,打開和關閉。當上圖中的開關1和開關2兩個開關中只有1個開關打開時,經過與非門處理,開關3就打開了。如果開關1和開關2兩個開關都關閉或者兩個開關都打開,經過與非門處理,開關3就關閉了。 其實和與非門類似的東西生活中隨處可見。比如說有的人家里有一個燈,這個燈在家門口設了一個開關,方便進出家門時開關燈。在床邊也設了個開關,方便晚上睡覺時關燈。這個其實就是一個與非門,兩個開關控制同一個燈。一個開關打開,燈就亮了,兩個開關同時打開或者關閉,燈就滅了。
這樣的話,用一個與非門和一個與門就模擬了最簡單的一個加法器,最大只能計算1+1。計算機中有幾億個這樣的門電路,它們組合起來就能做非常復雜的運算。現在的大部分CPU都是64位的,這種CPU肯定會有64位加法器甚至128位加法器。拿64位加法器來說,它最大可以計算出18446744073709551616 + 18446744073709551616。
說到這里,不得不說說芯片頻率。K3V2年初時號稱1.5G四核,到發布密派時,又改口1.2G,到D1四核,又改成1.4G…可謂坑爹至極,這件事也引發了不少爭論。但估計大部分人和我原來一樣,只知道爭論多少G,不知道這個芯片頻率意味著什么。先說說1G是什么概念吧,就是每秒鐘10億(1,000,000,000)次。為什么會有這個東西呢?剛才我說了與非門,開關3是隨著開關1和開關2的變化而變化的,對人類來說,開關3的變化速度很快,是瞬間的,但這個變化總是需要一點時間的。開關3可能是另外一個門電路的輸入開關,如果變化到一半,它的下一個門電路就接受開關3的輸入,可能會產生很嚴重的問題。
一般來說,一層門電路需要等它的上一層門電路完全變化完畢,輸出穩定之后,它才接收上一層的輸入,開始變化。這個時候就需要有一個指揮家來指揮這些門電路什么時候開始變化,這個指揮家就是芯片頻率,指揮家會定時發出脈沖,1G就是每秒1一次脈沖。門電路等脈沖到來的時候就開始做這個變化。
從上面可以看出,指揮家指揮得越快,芯片運算速度越快。但要說明一點,兩倍的頻率并不代表兩倍的性能。因為CPU和內存、外設頻率不同步,它們之間的頻率相差越多,CPU空轉的次數越多。另外再說一點,門電路變化的過程其實就是mos充電放電的過程,mos管充電放電越快,芯片的頻率可以做到越高,而二級效應會減慢mos充電放電的速度。如果mos管想要充電放電快一點,要提高mos管電壓,這樣就提高了芯片的功耗。
大家對海思比較好奇的,可能都有這么幾點疑問:
1、海思用了ARM的IP核,是不是閉著眼睛就能把K3V2(海思4核A9架構處理器)整出來?
2、ARM核究竟是怎么回事?
3、開發K3V2的團隊實力如何,在海思地位怎么樣?
4、海思究竟有沒有競爭力,核心技術在哪里,和國外比相差多少?
先說說ARM的IP核吧,ARM授權包括指令集和CPU核心架構。據我了解,除了高通外,其它芯片廠商都使用了ARM的CPU核心架構,也就是經常可以聽到的A9 A15。高通比較高端,CPU核心架構自己搞,如果搞得比A9 A15好的話確實可以提高CPU性能,但由于ARM收取高昂的核心架構修改費用,所以要付更多的錢給ARM。指令集是CPU與上層的編譯器、操作系統和應用程序的接口,使用ARM指令集意味著你做的CPU可以兼容安卓系統、安裝應用、C編譯器。
如果哪個公司自己整一套全新的指令集,那它做出來的CPU一點用處沒有,既沒有操作系統也沒用應用。此前聯想出了個K800,用的是英特爾Atom CPU,這款CPU非常特別,使用X86指令集,結果是一出悲劇,很多游戲兼容不了。不過英特爾還得感謝谷歌,否則這個CPU連安卓都兼容不了。目前來看,CPU不用ARM指令集很難玩轉,而且隨著越來越多應用只支持ARM,ARM的地位會越來越鞏固,就像電腦CPU,如果不用X86指令集,連Windows都很難安裝,這是一個壟斷的帝國。
下面說說CPU核心架構,說之前不得不先談談PDK。PDK是ProcessDesign Kit 工藝設計包,它和晶圓廠的制作工藝緊密相關。PDK是什么呢,它描述了一個具體工藝基本元器件的電器特性。比如臺積電28nm工藝和40nm工藝做出來的mos管電器特性肯定不一樣。28nm工藝和40nm工藝做出來的mos管額定電流范圍、電壓范圍肯定不同,在相同外界輸入下,輸出曲線也肯定不一樣。芯片公司如果沒有PDK,根本不知道設計出來的電路性能如何,也沒辦法跑仿真。簡單一點說,你拿40nm PDK設計電路,用28nm工藝生產,生產出來的芯片絕對一點用處沒有。所以說芯片設計非常苦逼,搞編程的,代碼可以重用,搞芯片設計的,如果換了生產工藝,很多東西得要從頭再來。
ARM給華為的CPU核心架構只是FPGA代碼,它不是工藝相關的,數字前端設計的工作會少不少,但后端設計有大量的工作要做。但ARM提供的僅僅是一個計算核心,外圍一個都沒有。外圍包括一些什么呢?比如USB IP核,沒有這個,手機就沒有USB功能;比如GPU,這個不用我多說吧;比如音頻IP核,杜比音效就是這么來的;比如視頻解碼IP核,沒有這個,看視頻只能軟解;還有CPU功耗控制IP核,K3V2功耗低,說明海思這一塊做得不錯。這些外圍的IP核海思很多都是外購的,海思也自主了一部分。所以說看CPU真心不能只看頻率,外圍IP有好有壞,有些比較高端的IP核授權費用非常高。即使買了很多IP核,但芯片也絕不是閉著眼睛就能整出來的。
順便說一下,高通芯片外圍的IP核很多也是外購的。再說說開發K3V2的海思圖靈團隊,這個團隊的前身是海思平臺的數字什么開發部,具體叫什么我忘了,做K3V2之前,也沒什么名聲。這個團隊的技術實力和海思其它開發部的技術實力差不多,因為做K3V2的時候圖靈也沒有說去別的部門抓厲害的壯丁進去。另外,K3V2完全不能說是海思做的最有技術含量的產品。海思成立七、八年了,做K3V2之前核心技術都在路由器芯片和安防芯片那塊。
大家可以去百度一下華為最新的高性能路由器,吞吐量是思科高性能路由器的好幾倍,至少領先思科一年。這是怎么做到的呢?因為那些路由器用的是海思專門定制的芯片,這些芯片也是ARM架構的,只是外圍IP核變成了處理網絡數據的IP核,這些IP核都是有自主知識產權的。把程序寫進芯片是目前的一個趨勢,典型的例子就是原來播放rmvb都是用播放器軟解,軟解的時候CPU占用率非常高,稍微清晰一點的容易卡,而現在的CPU或顯卡基本都有硬解rmvb的的功能。把程序寫進芯片可以讓程序跑得更快,所以華為的路由器在性能上可以超過思科。
所以說海思絕對不是第一次做ARM,能做出四核K3V2也是有原因的,另外八核、十六核目前都在研發過程中。海思在做手機芯片時和國外廠商比,幾乎沒有任何優勢,因為除了K3,原來基本沒有做過手機芯片,IP核自主化程度還比較低,優勢還得靠積累,這個要慢慢來。另外,海思也有自己的核心技術,其它廠商來做路由芯片,不見得能比海思做得好。
-
ARM
+關注
關注
134文章
9346瀏覽量
376741 -
華為
+關注
關注
216文章
35185瀏覽量
255638 -
海思
+關注
關注
43文章
495瀏覽量
117698
原文標題:華為人眼中的海思芯片發家史
文章出處:【微信號:icunion,微信公眾號:半導體行業聯盟】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
Deepseek海思SD3403邊緣計算AI產品系統
我有一塊海思 9610A 芯片的問界M9的車載娛樂主機,怎么把這個當成開發板重裝系統
極海G32R501數據手冊# 內置FPU,支持 Arm Helium,實時控制 MCU

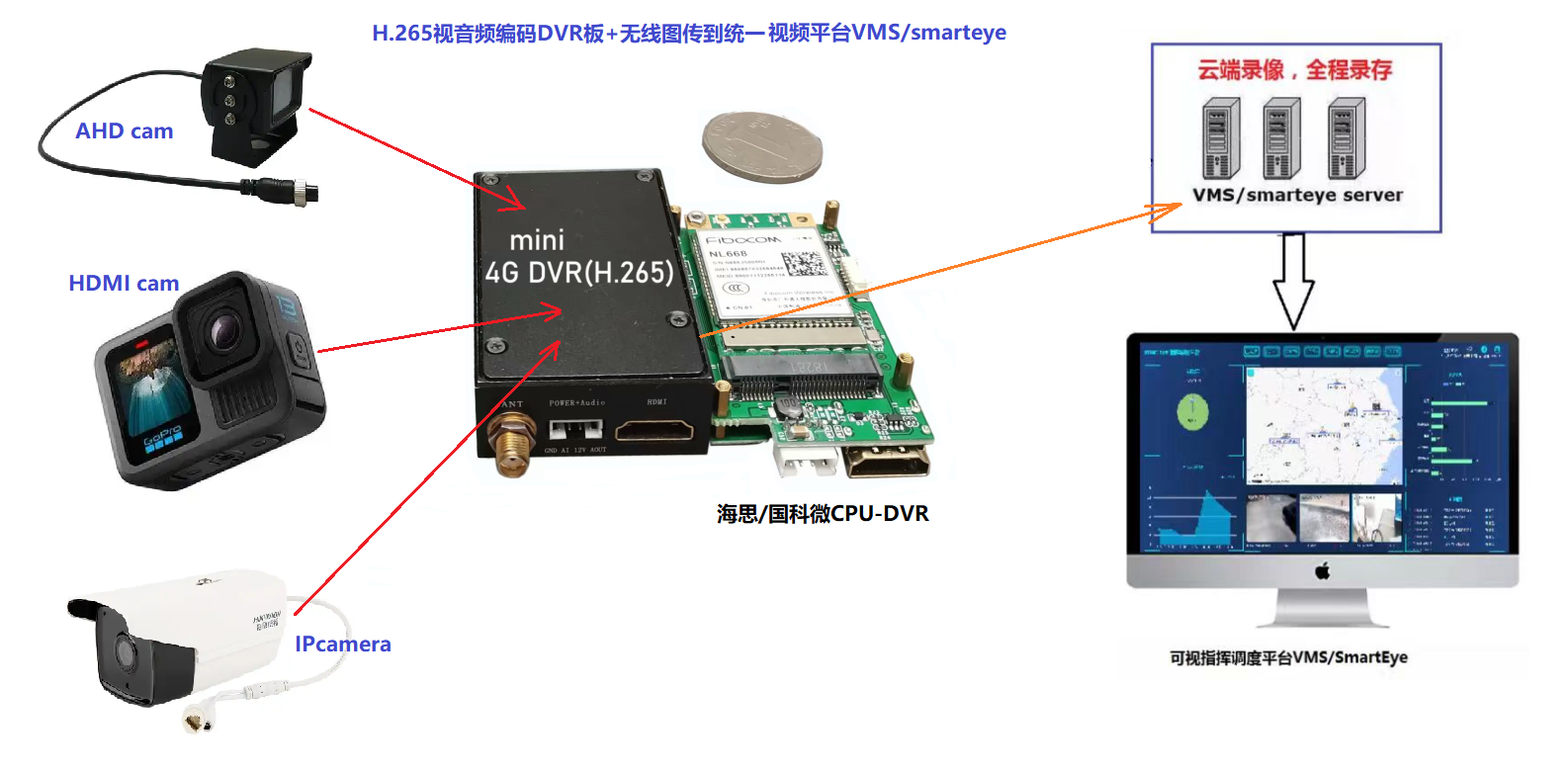
基于君正T30/T41、海思、國科微芯片處理器的圖像傳輸開發板、智能安全帽、執法記錄儀ODM定制開發
華為海思正式進入Wi-Fi FEM賽道?
2024福布斯中國創新力企業50強:華為海思等6家半導體企業上榜

實際項目開發中為何選擇ARM? Cortex?-M4 內核的HK32MCU?

華為海思躋身上半年乘用車座艙芯片交付量TOP10
海博思創HyperBlock II液冷儲能系統榮獲AS/NZS 3000國際認證

2024年上海海思MCU開發者體驗官招募,手機/MatePad大獎等你拿!
基于 ARM Cortex M0+內核BAT32A237芯片

5G和AI加持!智物聯躍上新臺階,海思、芯昇和樂鑫新品匯總






 工商網監
工商網監
評論