") 騰訊 AI Lab 開源世界首款自動化模型壓縮框架PocketFlow
騰訊 AI Lab 開源世界首款自動化模型壓縮框架PocketFlow

AI科技評論按:騰訊 AI Lab 機器學(xué)習(xí)中心今日宣布成功研發(fā)出世界上首款自動化深度學(xué)習(xí)模型壓縮框架—— PocketFlow,并即將在近期發(fā)布開源代碼。根據(jù)雷鋒網(wǎng)AI科技評論了解,這是一款面向移動端AI開發(fā)者的自動模型壓縮框架,集成了當前主流的模型壓縮與訓(xùn)練算法,結(jié)合自研超參數(shù)優(yōu)化組件實現(xiàn)了全程自動化托管式的模型壓縮與加速。開發(fā)者無需了解具體算法細節(jié),即可快速地將AI技術(shù)部署到移動端產(chǎn)品上,實現(xiàn)用戶數(shù)據(jù)的本地高效處理。
隨著AI技術(shù)的飛速發(fā)展,越來越多的公司希望在自己的移動端產(chǎn)品中注入AI能力,但是主流的深度學(xué)習(xí)模型往往對計算資源要求較高,難以直接部署到消費級移動設(shè)備中。在這種情況下,眾多模型壓縮與加速算法應(yīng)運而生,能夠在較小的精度損失(甚至無損)下,有效提升 CNN 和 RNN 等網(wǎng)絡(luò)結(jié)構(gòu)的計算效率,從而使得深度學(xué)習(xí)模型在移動端的部署成為可能。但是,如何根據(jù)實際應(yīng)用場景,選擇合適的模型壓縮與加速算法以及相應(yīng)的超參數(shù)取值,往往需要較多的專業(yè)知識和實踐經(jīng)驗,這無疑提高了這項技術(shù)對于一般開發(fā)者的使用門檻。
在此背景下,騰訊AI Lab機器學(xué)習(xí)中心研發(fā)了 PocketFlow 開源框架,以實現(xiàn)自動化的深度學(xué)習(xí)模型壓縮與加速,助力AI技術(shù)在更多移動端產(chǎn)品中的廣泛應(yīng)用。通過集成多種深度學(xué)習(xí)模型壓縮算法,并創(chuàng)新性地引入超參數(shù)優(yōu)化組件,極大地提升了模型壓縮技術(shù)的自動化程度。開發(fā)者無需介入具體的模型壓縮算法及其超參數(shù)取值的選取,僅需指定設(shè)定期望的性能指標,即可通過 PocketFlow 得到符合需求的壓縮模型,并快速部署到移動端應(yīng)用中。
框架介紹
PocketFlow 框架主要由兩部分組件構(gòu)成,分別是模型壓縮/加速算法組件和超參數(shù)優(yōu)化組件,具體結(jié)構(gòu)如下圖所示。
開發(fā)者將未壓縮的原始模型作為 PocketFlow 框架的輸入,同時指定期望的性能指標,例如模型的壓縮和/或加速倍數(shù);在每一輪迭代過程中,超參數(shù)優(yōu)化組件選取一組超參數(shù)取值組合,之后模型壓縮/加速算法組件基于該超參數(shù)取值組合,對原始模型進行壓縮,得到一個壓縮后的候選模型;基于對候選模型進行性能評估的結(jié)果,超參數(shù)優(yōu)化組件調(diào)整自身的模型參數(shù),并選取一組新的超參數(shù)取值組合,以開始下一輪迭代過程;當?shù)K止時,PocketFlow 選取最優(yōu)的超參數(shù)取值組合以及對應(yīng)的候選模型,作為最終輸出,返回給開發(fā)者用作移動端的模型部署。
具體地,PocketFlow 通過下列各個算法組件的有效結(jié)合,實現(xiàn)了精度損失更小、自動化程度更高的深度學(xué)習(xí)模型的壓縮與加速:
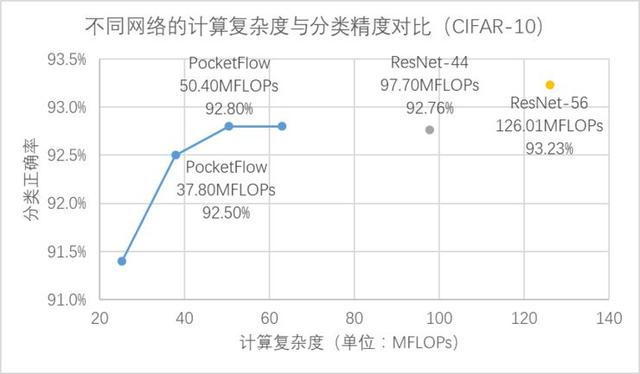
a) 通道剪枝(channel pruning)組件:在CNN網(wǎng)絡(luò)中,通過對特征圖中的通道維度進行剪枝,可以同時降低模型大小和計算復(fù)雜度,并且壓縮后的模型可以直接基于現(xiàn)有的深度學(xué)習(xí)框架進行部署。在CIFAR-10圖像分類任務(wù)中,通過對 ResNet-56 模型進行通道剪枝,可以實現(xiàn)2.5倍加速下分類精度損失0.4%,3.3倍加速下精度損失0.7%。
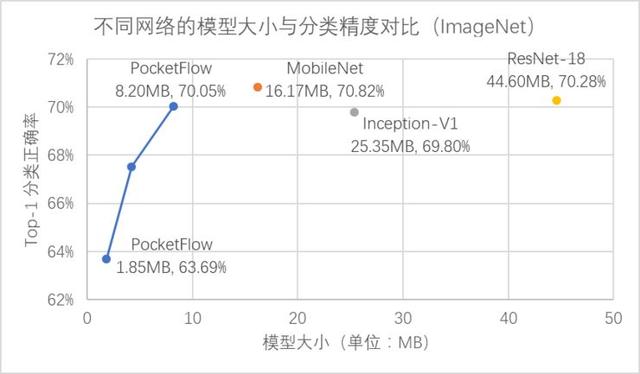
b) 權(quán)重稀疏化(weight sparsification)組件:通過對網(wǎng)絡(luò)權(quán)重引入稀疏性約束,可以大幅度降低網(wǎng)絡(luò)權(quán)重中的非零元素個數(shù);壓縮后模型的網(wǎng)絡(luò)權(quán)重可以以稀疏矩陣的形式進行存儲和傳輸,從而實現(xiàn)模型壓縮。對于 MobileNet 圖像分類模型,在刪去50%網(wǎng)絡(luò)權(quán)重后,在 ImageNet 數(shù)據(jù)集上的 Top-1 分類精度損失僅為0.6%。
c) 權(quán)重量化(weight quantization)組件:通過對網(wǎng)絡(luò)權(quán)重引入量化約束,可以降低用于表示每個網(wǎng)絡(luò)權(quán)重所需的比特數(shù);團隊同時提供了對于均勻和非均勻兩大類量化算法的支持,可以充分利用 ARM 和 FPGA 等設(shè)備的硬件優(yōu)化,以提升移動端的計算效率,并為未來的神經(jīng)網(wǎng)絡(luò)芯片設(shè)計提供軟件支持。以用于 ImageNet 圖像分類任務(wù)的 ResNet-18 模型為例,在8比特定點量化下可以實現(xiàn)精度無損的4倍壓縮。
d) 網(wǎng)絡(luò)蒸餾(network distillation)組件:對于上述各種模型壓縮組件,通過將未壓縮的原始模型的輸出作為額外的監(jiān)督信息,指導(dǎo)壓縮后模型的訓(xùn)練,在壓縮/加速倍數(shù)不變的前提下均可以獲得0.5%-2.0%不等的精度提升。
e) 多GPU訓(xùn)練(multi-GPU training)組件:深度學(xué)習(xí)模型訓(xùn)練過程對計算資源要求較高,單個GPU難以在短時間內(nèi)完成模型訓(xùn)練,因此團隊提供了對于多機多卡分布式訓(xùn)練的全面支持,以加快使用者的開發(fā)流程。無論是基于 ImageNet 數(shù)據(jù)的Resnet-50圖像分類模型還是基于 WMT14 數(shù)據(jù)的 Transformer 機器翻譯模型,均可以在一個小時內(nèi)訓(xùn)練完畢。[1]
f) 超參數(shù)優(yōu)化(hyper-parameter optimization)組件:多數(shù)開發(fā)者對模型壓縮算法往往不甚了解,但超參數(shù)取值對最終結(jié)果往往有著巨大的影響,因此團隊引入了超參數(shù)優(yōu)化組件,采用了包括強化學(xué)習(xí)等算法以及 AI Lab 自研的 AutoML 自動超參數(shù)優(yōu)化框架來根據(jù)具體性能需求,確定最優(yōu)超參數(shù)取值組合。例如,對于通道剪枝算法,超參數(shù)優(yōu)化組件可以自動地根據(jù)原始模型中各層的冗余程度,對各層采用不同的剪枝比例,在保證滿足模型整體壓縮倍數(shù)的前提下,實現(xiàn)壓縮后模型識別精度的最大化。
性能展示
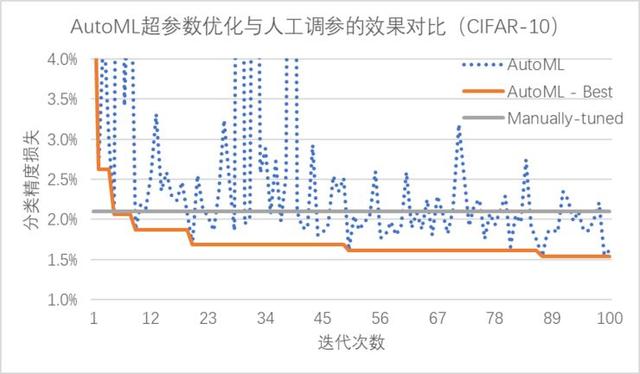
通過引入超參數(shù)優(yōu)化組件,不僅避免了高門檻、繁瑣的人工調(diào)參工作,同時也使得 PocketFlow 在各個壓縮算法上全面超過了人工調(diào)參的效果。以圖像分類任務(wù)為例,在 CIFAR-10 和 ImageNet 等數(shù)據(jù)集上, PocketFlow 對 ResNet 和 MobileNet 等多種 CNN 網(wǎng)絡(luò)結(jié)構(gòu)進行有效的模型壓縮與加速。[1]
在 CIFAR-10 數(shù)據(jù)集上,PocketFlow 以 ResNet-56 作為基準模型進行通道剪枝,并加入了超參數(shù)優(yōu)化和網(wǎng)絡(luò)蒸餾等訓(xùn)練策略,實現(xiàn)了2.5倍加速下分類精度損失0.4%,3.3倍加速下精度損失0.7%,且顯著優(yōu)于未壓縮的ResNet-44模型; [2] 在 ImageNet 數(shù)據(jù)集上,PocketFlow 可以對原本已經(jīng)十分精簡的 MobileNet 模型繼續(xù)進行權(quán)重稀疏化,以更小的模型尺寸取得相似的分類精度;與 Inception-V1 、ResNet-18 等模型相比,模型大小僅為后者的約20~40%,但分類精度基本一致(甚至更高)。
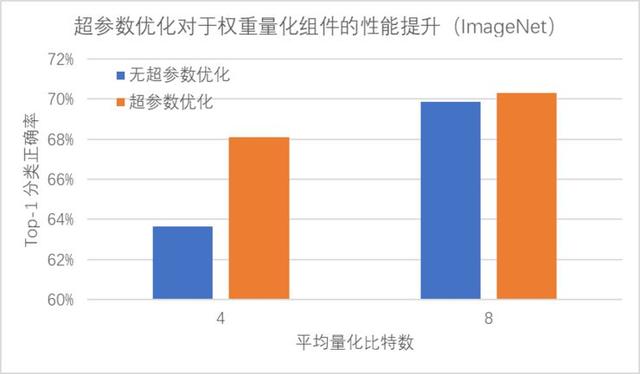
相比于費時費力的人工調(diào)參,PocketFlow 框架中的 AutoML 自動超參數(shù)優(yōu)化組件僅需10余次迭代就能達到與人工調(diào)參類似的性能,在經(jīng)過100次迭代后搜索得到的超參數(shù)組合可以降低約0.6%的精度損失;通過使用超參數(shù)優(yōu)化組件自動地確定網(wǎng)絡(luò)中各層權(quán)重的量化比特數(shù),PocketFlow 在對用于 ImageNet 圖像分類任務(wù)的ResNet-18模型進行壓縮時,取得了一致性的性能提升;當平均量化比特數(shù)為4比特時,超參數(shù)優(yōu)化組件的引入可以將分類精度從63.6%提升至68.1%(原始模型的分類精度為70.3%)。
深度學(xué)習(xí)模型的壓縮與加速是當前學(xué)術(shù)界的研究熱點之一,同時在工業(yè)界中也有著廣泛的應(yīng)用前景。隨著PocketFlow的推出,開發(fā)者無需了解模型壓縮算法的具體細節(jié),也不用關(guān)心各個超參數(shù)的選擇與調(diào)優(yōu),即可基于這套自動化框架,快速得到可用于移動端部署的精簡模型,從而為AI能力在更多移動端產(chǎn)品中的應(yīng)用鋪平了道路。
參考文獻
[1] Zhuangwei Zhuang, Mingkui Tan, Bohan Zhuang, Jing Liu, Jiezhang Cao, Qingyao Wu, Junzhou Huang, Jinhui Zhu, “Discrimination-aware Channel Pruning for Deep Neural Networks", In Proc. of the 32nd Annual Conference on Neural Information Processing Systems, NIPS '18, Montreal, Canada, December 2018.
[2] Jiaxiang Wu, Weidong Huang, Junzhou Huang, Tong Zhang, “Error Compensated Quantized SGD and its Applications to Large-scale Distributed Optimization”, In Proc. of the 35th International Conference on Machine Learning, ICML ’18, Stockholm, Sweden, July 2018.
本文來源:AI科技評論
-
AI
+關(guān)注
關(guān)注
88文章
35194瀏覽量
280305 -
騰訊
+關(guān)注
關(guān)注
7文章
1678瀏覽量
50317
發(fā)布評論請先 登錄
Nordic收購 Neuton.AI 關(guān)于產(chǎn)品技術(shù)的分析
APP自動化測試框架

首創(chuàng)開源架構(gòu),天璣AI開發(fā)套件讓端側(cè)AI模型接入得心應(yīng)手
銷售易在騰訊云城市峰會上發(fā)布中國首款AI CRM
自動化標注技術(shù)推動AI數(shù)據(jù)訓(xùn)練革新
FPGA+AI王炸組合如何重塑未來世界:看看DeepSeek東方神秘力量如何預(yù)測......
HFSS 自動化建模工具
開源技術(shù)在工業(yè)自動化領(lǐng)域的作用
AI工作流自動化是做什么的
通用自動化測試軟件 - TAE





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論