 是否可以利用全局語義上下文改進QuickType鍵盤的單詞預測?
是否可以利用全局語義上下文改進QuickType鍵盤的單詞預測?
編者按:從iOS 8開始,蘋果就在iPhone上采用了一個全新的預測文本功能——QuickType鍵盤。當你在打字的時候,系統會根據你的書寫風格,提示接下來可能會鍵入的字詞或短語供你選擇,類似中文輸入法中的智能建議。
這一功能基于其背后強大的自然語言處理(NLP)模型,而在過去幾年中,這種詞向量模型也是新聞、搜索和地圖等其他應用程序的核心。在這篇文章中,我們將介紹蘋果研究人員近期的一項新探索:是否可以利用全局語義上下文改進QuickType鍵盤的單詞預測?
簡介
You shall know a word by the company it keeps.(現代語言學名句:觀其伴而知其意。即通過分析大型語言語料庫中詞匯共現的模式,我們可以得出詞語的語義表征)
現如今,訓練詞嵌入模型的大多數方法都圍繞句子中給定單詞的上下文,以出現在中心詞前后的幾個單詞(比如5個)為觀察“窗口”,從中挖掘信息。以美國《獨立宣言》中出現的代詞“self-evident”為例,它的左側是“hold these truths to be”,右側是“that all men are created”。
本文將在這類方法的基礎上做進一步擴展,探索模型是否能捕獲文檔的整個語義結構,簡而言之,在新模型中,“self-evident”將可以把整本《獨立宣言》作為自己的上下文。那么,這種全局語義上下文能否提高語言模型的性能呢?要解決這個問題,我們先看看現在的詞嵌入用法。
詞嵌入
詞嵌入(Word Embeddings)是NLP中的一個常見操作,現在,以無監督方式訓練的連續空間詞嵌入已經被證實可用于各種NLP任務,比如信息檢索、文本分類、問答和序列語言建模等。其中最基礎的一種詞嵌入是1-of-N Encoding,即假設存在一個大小為N的基礎單詞集,每個單詞都由一個N維系數向量表示(在單詞索引處為1,在其他地方為0)。
但這種方法有兩個缺陷,一是它的正交性會弱化相似單詞之間關系,二是編碼結果容易過長。因此我們也已經有了更復雜的嵌入——將單詞映射到低維連續向量空間中的密集向量中,這種映射不僅能降低維度,還有利于捕獲關于單詞的語義、句法和語用信息。
有了詞向量,我們就能通過計算向量之間的距離判斷兩個單詞的相似程度。
比較常見的降維詞嵌入類型有兩種:
從單詞所在文本的上下文中導出表示(前L個單詞和后L個單詞,L一般是個較小的整數)
利用圍繞單詞的全局上下文的表示(單詞所在的整個文本)
其中,利用文本上下文的方法包括:
用于預測的神經網絡架構,如連續詞袋模型和skip-gram模型
序列語言模型中的投影層(projection layer)
自編碼器的Bottleneck表示
利用全局上下文的方法包括:
全局矩陣分解方法,如潛在語義映射(LSM),它計算word-document共現次數
Log-Liner Model,如GloVe,它計算word-word共現次數
從理想的角度看,像LSM這種計算全局共現的方法其實是最接近真正的語義嵌入的,因為它們捕獲的是整個文本傳達的語義概念的統計信息。相比之下,基于預測的神經網絡只是把語義關系封裝到以目標單詞為中心的局部文本中,不夠全面。因此,當涉及全局語義信息時,由這種方法產生的嵌入往往存在局限。
但是,盡管存在這種局限,現在越來越多的研究人員還是投向神經網絡,尤其是廣受歡迎的連續詞袋模型和skip-gram模型。因為它們能解決“國王對于女王就像男人對于女人”這類類比,而LSM經常失敗。對此,一種普遍看法是基于LSM的方法會使向量空間的各個維度不夠精確,因此只能產生次優的空間結構。
這個認識引起了蘋果研究人員的極大興趣,因為現用QuickType鍵盤是基于LSM設計的,在他們最新的博客中,他們就是否可以通過使用不同類型的神經網絡架構來實現更強大的語義嵌入進行了探討。
神經架構
談及生成詞嵌入,最著名的框架之一是word2vec,但研究人員在文章中采用的是一種能提供全局語義嵌入的特殊RNN——bi-LSTM。它允許模型訪問先前、當前和未來的輸入信息,把握全局上下文。
為了讓模型能輸入整個完整文檔,他們重新設計了這個架構,如下圖所示,模型的輸出能提供與該文檔相關聯的語義類別這意味著生成的詞嵌入捕獲的是輸入的整個語義結構,而不僅是局部上下文。
這個架構主要解決了兩個障礙。其一是對目標單詞上下文的單詞數限制,它原則上可以容納無限長度的上下文,這樣就不僅可以處理句子,還可以處理整個段落,甚至是完整的文檔。
圖一 能捕獲全局語義結構的RNN
其二涉及預測目標本身。到目前為止,神經網絡這種解決方案都基于局部上下文信息,無法充分反映全局語義信息,但是上圖已經是一個能輸入完整文本的神經網絡了。為了簡化語義標簽的生成,研究人員發現派生合適的聚類類別是有幫助的,例如,他們可以用LSM獲得初始word-document嵌入。
設當前存在一個文本塊(可以是句子,也可以是段落、文檔),它由T個單詞x(t)構成(1≤t≤T),且存在一個全局關聯的語義類別z。我們把它輸入修改過的bi-LSTM。
用1-of-N encoding對輸入文本中的單詞x(t)編碼,把x(t)轉成N維稀疏向量。此時,x(t)左側的上下文向量h(t ? 1)維數為H,它包含前一個時間步的隱藏層中輸出值信息的內部表示;x(t)右側的上下文向量g(t + 1)維數也是H,它包含下一個時間步的隱藏層中的右側上下文輸出值信息。網絡在當前時間步計算隱藏節點的輸出值,如下所示:

其中,
F{·}表示激活函數,如sigmoid、tanh、ReLU
s(t)表示網絡狀態,這是左右上下文隱藏節點的串聯:s(t) = [g(t) h(t)],維數為2H。我們可以把網絡狀態看作是2H向量空間中,單詞x(t)的連續空間表示
網絡的輸出是與輸入文本相關聯的語義類別。在每個時間步,對應于當前單詞的輸出標簽z再被1-of-K encoding:
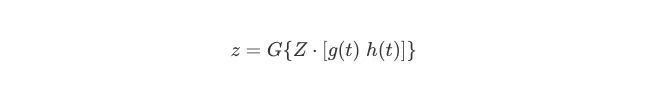
其中,G {·}表示softmax激活函數。
當我們訓練網絡時,我們假設有一組語義類別注釋可用。如前所述,這些注釋可能來自使用LSM獲得的初始word-document嵌入。為了避免出現梯度消失,這個架構把隱藏節點設計成了LSTM和GRU里的形式,我們可以根據需要將圖一中的單個隱藏層擴展到任意復雜、任意深度的網絡。
神經語言建模
在實驗中,研究人員使用的是之前訓練QuickType時所用的語料庫的子集,如下表所示,他們測試了三種不同嵌入模型在測試集上的困惑度表現,其中“1-of-N”表示標準稀疏嵌入,“word2vec”是標準word2vec嵌入,“bi-LSTM”是他們改進后的方法。

可以發現,“bi-LSTM”使用的訓練數據是最少的,但它的性能卻和比他多用了6倍訓練數據的“word2vec”差不多,而“1-of-N”模型如果要達到同樣的困惑度,它使用的訓練數據得是“bi-LSTM”的5000倍以上。
因此,這種能捕獲全局語義結構的方法非常適合數據量有限的公司、實驗室。
結論
相比現有方法,將全局語義信息納入神經語言模型具有明顯的潛在優勢,它也是NLP研究的一個趨勢。但是,在實驗過程中,研究人員也發現這種方法確實還存在限制,在段落數據上訓練詞嵌入和在句子數據上訓練語言模型時,其中還存在一個長度不匹配的問題。
對此,研究人員提出的方案是修改語言模型訓練中使用的客觀標準,以便人們能在同一段落數據上同時訓練嵌入和語言模型。總之,使用bi-LSTM RNN訓練全局語義詞嵌入確實可以提高神經語言建模的準確性,它還可以大大降低對訓練所需的數據量的要求。
-
神經網絡
+關注
關注
42文章
4785瀏覽量
101269 -
自然語言處理
+關注
關注
1文章
620瀏覽量
13661
原文標題:Apple:全局語義上下文可以改善神經語言模型嗎?
文章出處:【微信號:jqr_AI,微信公眾號:論智】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
【「基于大模型的RAG應用開發與優化」閱讀體驗】+Embedding技術解讀
《具身智能機器人系統》第7-9章閱讀心得之具身智能機器人與大模型
是否可以利用偽差分的方式通過ADS1256進行采集?
阿里通義千問發布Qwen2.5-Turbo開源AI模型
SystemView上下文統計窗口識別阻塞原因
【《大語言模型應用指南》閱讀體驗】+ 基礎知識學習
鴻蒙Ability Kit(程序框架服務)【應用上下文Context】
編寫一個任務調度程序,在上下文切換后遇到了一些問題求解
鴻蒙開發接口Ability框架:【ServiceExtensionContext】

鴻蒙開發接口Ability框架:【ExtensionContext】
鴻蒙開發接口Ability框架:【(AbilityContext)】





 工商網監
工商網監
評論