") 數(shù)據(jù)集,網(wǎng)絡(luò)架構(gòu)和剪枝方法
數(shù)據(jù)集,網(wǎng)絡(luò)架構(gòu)和剪枝方法
模型剪枝被認(rèn)為是一種有效的模型壓縮方法。然而,剪枝方法真的有文獻(xiàn)中聲稱的那么有效嗎?最近UC Berkeley、清華大學(xué)的研究人員提交給ICLR 2019的論文《重新思考剪枝》質(zhì)疑了六種剪枝方法,引起關(guān)注。
網(wǎng)絡(luò)剪枝(Network Pruning)是常用的模型壓縮方法之一,被廣泛用于降低深度模型的繁重計(jì)算量。
一個(gè)典型的剪枝算法通常有三個(gè)階段,即訓(xùn)練(大型模型),剪枝和微調(diào)。在剪枝過(guò)程中,根據(jù)一定的標(biāo)準(zhǔn),對(duì)冗余權(quán)重進(jìn)行修剪并保留重要權(quán)重,以最大限度地保持精確性。
剪枝通常能大幅減少參數(shù)數(shù)量,壓縮空間,從而降低計(jì)算量。
然而,剪枝方法真的有它們聲稱的那么有效嗎?
最近一篇提交給ICLR 2019的論文似乎與最近所有network pruning相關(guān)的論文結(jié)果相矛盾,這篇論文質(zhì)疑了幾個(gè)常用的模型剪枝方法的結(jié)果,包括韓松(Song Han)獲得ICLR2016最佳論文的“Deep Compression: Compressing Deep Neural Networks with Pruning, Trained Quantization and Huffman Coding”。
這篇論文迅速引起關(guān)注,有人認(rèn)為它甚至可能改變我們?cè)诠I(yè)中訓(xùn)練和部署模型的workflow。論文作者來(lái)自UC Berkeley和清華大學(xué),他們?cè)贠penReview上與被他們質(zhì)疑的模型作者有一些有意思的反饋,感興趣的讀者可以去看看。地址:
https://openreview.net/forum?id=rJlnB3C5Ym
論文地址:
https://arxiv.org/pdf/1810.05270.pdf
在這篇論文里,作者發(fā)現(xiàn)了幾個(gè)與普遍觀念相矛盾的的觀察。他們檢查了6種最先進(jìn)的剪枝算法,發(fā)現(xiàn)對(duì)剪枝后的模型進(jìn)行fine-tuning,只比使用隨機(jī)初始化權(quán)重訓(xùn)練的網(wǎng)絡(luò)的性能好一點(diǎn)點(diǎn),甚至性能更差。
作者說(shuō):“對(duì)于采用預(yù)定義目標(biāo)網(wǎng)絡(luò)架構(gòu)的剪枝算法,可以擺脫整個(gè)pipeline并直接從頭開始訓(xùn)練目標(biāo)網(wǎng)絡(luò)。我們的觀察結(jié)果對(duì)于具有多種網(wǎng)絡(luò)架構(gòu),數(shù)據(jù)集和任務(wù)的各種剪枝算法是一致的。”
作者總結(jié)認(rèn)為,這一發(fā)現(xiàn)有幾個(gè)意義:
1)訓(xùn)練一個(gè)大型、over-parameterized的模型對(duì)于最終得到一個(gè)efficient的小模型不是必需的;
2)為了得到剪枝后的小模型,求取大模型的“important” weights不一定有用;
3)剪枝得到的結(jié)構(gòu)本身,而不是一組“important” weights,是導(dǎo)致最終模型效果提升的原因。這表明一些剪枝算法可以被視為執(zhí)行了“網(wǎng)絡(luò)結(jié)構(gòu)搜索”(network architecture search)。
推翻網(wǎng)絡(luò)剪枝背后的兩個(gè)共同信念
過(guò)度參數(shù)化(over-parameterization)是深度神經(jīng)網(wǎng)絡(luò)的一個(gè)普遍屬性,這會(huì)導(dǎo)致高計(jì)算成本和高內(nèi)存占用。作為一種補(bǔ)救措施,網(wǎng)絡(luò)剪枝(network pruning)已被證實(shí)是一種有效的改進(jìn)技術(shù),可以在計(jì)算預(yù)算有限的情況下提高深度網(wǎng)絡(luò)的效率。
網(wǎng)絡(luò)剪枝的過(guò)程一般包括三個(gè)階段:1)訓(xùn)練一個(gè)大型,過(guò)度參數(shù)化的模型,2)根據(jù)特定標(biāo)準(zhǔn)修剪訓(xùn)練好的大模型,以及3)微調(diào)(fine-tune)剪枝后的模型以重新獲得丟失的性能。
網(wǎng)絡(luò)剪枝的三個(gè)階段
通常,這種剪枝程序背后有兩個(gè)共同的信念。
首先,人們認(rèn)為從訓(xùn)練一個(gè)大型的、過(guò)度參數(shù)化的網(wǎng)絡(luò)開始是很重要的,因?yàn)樗峁┝艘粋€(gè)高性能的模型,從中可以安全地刪除一組冗余參數(shù)而不會(huì)顯著損害準(zhǔn)確性。因此,這通常被認(rèn)為是比直接從頭開始訓(xùn)練較小的網(wǎng)絡(luò)更好的方法,也是一種常用的baseline方法。
其次,修剪后得到的結(jié)構(gòu)及其相關(guān)權(quán)重被認(rèn)為是獲得最終的有效模型所必需的。
因此,大多數(shù)現(xiàn)有的剪枝技術(shù)選擇fine-tune剪枝模型,而不是從頭開始訓(xùn)練。剪枝后保留的權(quán)重通常被認(rèn)為是關(guān)鍵的,因此如何準(zhǔn)確地選擇重要權(quán)重集是一個(gè)非常活躍的研究課題。
在這項(xiàng)工作中,我們發(fā)現(xiàn)上面提到的兩種信念都不一定正確。
基于對(duì)具有多個(gè)網(wǎng)絡(luò)架構(gòu)的多個(gè)數(shù)據(jù)集的最新剪枝算法的經(jīng)驗(yàn)評(píng)估,我們得出了兩個(gè)令人驚訝的觀察。
圖2:預(yù)定義和非預(yù)定義目標(biāo)架構(gòu)的區(qū)別
首先,對(duì)于具有預(yù)定義目標(biāo)網(wǎng)絡(luò)架構(gòu)的剪枝算法(圖2),從隨機(jī)初始化開始直接訓(xùn)練小型目標(biāo)模型可以實(shí)現(xiàn)與剪枝方法獲得的模型相同(甚至更好)的性能。在這種情況下,不需要從大型模型開始,而是可以直接從頭開始訓(xùn)練目標(biāo)模型。
其次,對(duì)于沒(méi)有預(yù)定義目標(biāo)網(wǎng)絡(luò)的剪枝算法,從頭開始訓(xùn)練剪枝模型也可以實(shí)現(xiàn)與fine-tune相當(dāng)或甚至更好的性能。這一觀察表明,對(duì)于這些剪枝算法,重要的是獲得的模型架構(gòu),而不是保留的權(quán)重,盡管找到目標(biāo)結(jié)構(gòu)需要訓(xùn)練大型模型。
我們的結(jié)果主張重新思考現(xiàn)有的網(wǎng)絡(luò)剪枝算法。似乎在第一階段的訓(xùn)練期間的過(guò)度參數(shù)化并不像以前認(rèn)為的那樣有益。此外,從大型模型繼承權(quán)重不一定是最優(yōu)的,并且可能將修剪后的模型陷入糟糕的局部最小值,即使權(quán)重被剪枝標(biāo)準(zhǔn)視為“重要”。
相反,我們的結(jié)果表明,自動(dòng)剪枝算法的價(jià)值在于識(shí)別有效的結(jié)構(gòu)和執(zhí)行隱式架構(gòu)搜索(implicit architecture search),而不是選擇“important”權(quán)重。我們通過(guò)精心設(shè)計(jì)的實(shí)驗(yàn)驗(yàn)證了這一假設(shè),并展示了剪枝模型中的模式可以為有效的模型架構(gòu)提供設(shè)計(jì)指導(dǎo)。
從頭開始訓(xùn)練小模型的方法
本節(jié)描述了從頭開始訓(xùn)練小型目標(biāo)模型的方法。
目標(biāo)剪枝架構(gòu)(Target Pruned Architectures)
我們首先將網(wǎng)絡(luò)剪枝方法分為兩類。在pruning pipeline中,目標(biāo)剪枝模型的架構(gòu)可以由人(即預(yù)定義的)或剪枝算法(即自動(dòng)的)來(lái)確定(見圖2)。
數(shù)據(jù)集,網(wǎng)絡(luò)架構(gòu)和剪枝方法
在network pruning 的相關(guān)文獻(xiàn)中,CIFAR-10,CIFAR-100和ImageNet數(shù)據(jù)集是事實(shí)上的基準(zhǔn),而VGG,ResNet和DenseNet是常見的網(wǎng)絡(luò)架構(gòu)。
我們?cè)u(píng)估了三種預(yù)定義目標(biāo)架構(gòu)的剪枝方法:Li et al. (2017), Luo et al. (2017), He et al. (2017b),以及評(píng)估了三種自動(dòng)發(fā)現(xiàn)目標(biāo)模型的剪枝方法Liu et al. (2017), Huang & Wang (2018), Han et al. (2015)。
訓(xùn)練預(yù)算
一個(gè)關(guān)鍵問(wèn)題是,我們應(yīng)該花多長(zhǎng)時(shí)間從頭開始訓(xùn)練這個(gè)剪枝后的小模型?用與訓(xùn)練大型模型同樣的epoch數(shù)量來(lái)訓(xùn)練可能是不公平的,因?yàn)樾∧P驮谝粋€(gè)epoch中需要的計(jì)算量要少得多。
在我們的實(shí)驗(yàn)中,我們使用Scratch-E表示訓(xùn)練相同epoch的小剪枝模型,用Scratch-B表示訓(xùn)練相同數(shù)量的計(jì)算預(yù)算。
實(shí)現(xiàn)(Implementation)
為了使我們的設(shè)置盡可能接近原始論文,我們使用了以下協(xié)議:
1)如果以前的剪枝方法的訓(xùn)練設(shè)置是公開的,如Liu et al.(2017)和Huang & Wang(2018),就采用原始實(shí)現(xiàn);
2)對(duì)于更簡(jiǎn)單的剪枝方法,如Li et al.(2017)和Han et al.(2015),我們重新實(shí)現(xiàn)了剪枝方法,得到了與原論文相似的結(jié)果;
3)其余兩種方法(Luo et al., 2017; He et al., 2017b),剪枝后的模型是公開的,但是沒(méi)有訓(xùn)練設(shè)置,因此我們選擇從頭訓(xùn)練目標(biāo)模型。
結(jié)果和訓(xùn)練模型的代碼可以在這里中找到:
https://github.com/Eric-mingjie/rethinking-networks-pruning
實(shí)驗(yàn)與結(jié)果
在本節(jié)中,我們將展示實(shí)驗(yàn)結(jié)果,這些實(shí)驗(yàn)結(jié)果比較了從頭開始的訓(xùn)練剪枝模型和基于繼承權(quán)重進(jìn)行微調(diào),以及預(yù)定義和自動(dòng)發(fā)現(xiàn)的目標(biāo)體系結(jié)構(gòu)的方法。此外還包括從圖像分類到物體檢測(cè)的轉(zhuǎn)移學(xué)習(xí)實(shí)驗(yàn)。
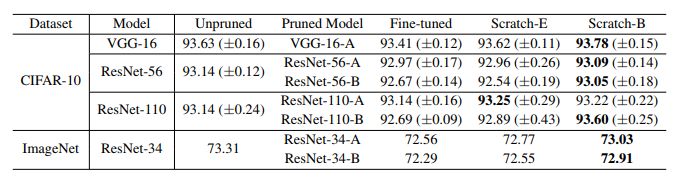
表1:基于L1范數(shù)的通道剪枝的結(jié)果(準(zhǔn)確度)。“剪枝模型”是從大型模型中進(jìn)行剪枝的模型。原模型和剪枝模型的配置均來(lái)自原始論文。
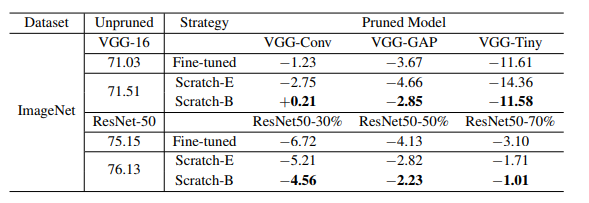
表2:ThiNet的結(jié)果(準(zhǔn)確度)。“VGG-GAP”和“ResNet50-30%”等指ThiNet中配置的剪枝模型。為了適應(yīng)本文的方法和原論文之間不同框架的影響,我們比較了相對(duì)于未剪枝的大型模型的相對(duì)精度下降。例如,對(duì)于剪枝后的模型VGG-Conv為-1.23,即表示相對(duì)左側(cè)的71.03的精度下降,后者為原始論文中未剪枝的大型VGG-16的報(bào)告精度
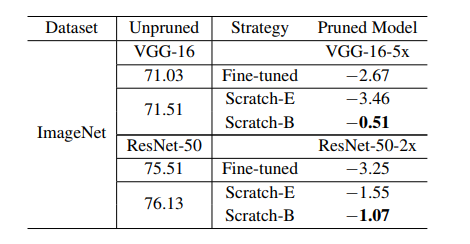
表3:基于回歸的特征重建結(jié)果(準(zhǔn)確度)。與表2類似,我們比較了相對(duì)于未剪枝的大型模型的相對(duì)精度下降。
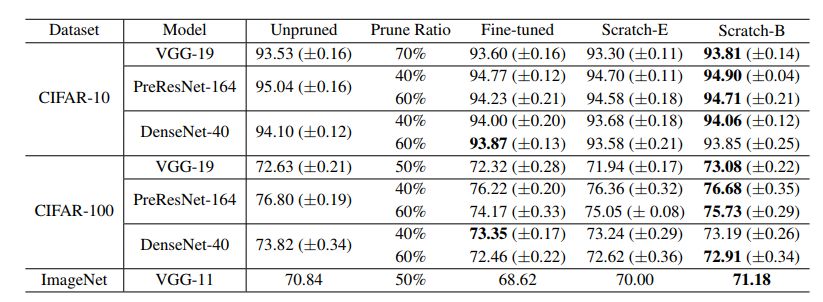
表4:網(wǎng)絡(luò)Slimming的結(jié)果(準(zhǔn)確度)“剪枝比”表示在整個(gè)網(wǎng)絡(luò)中,剪枝通道所占的總百分比。每種模型使用與原論文的相同比率。

表5:使用稀疏結(jié)構(gòu)選擇的殘余塊剪枝結(jié)果(準(zhǔn)確度)。在原始論文中不需要微調(diào),因此存在一個(gè)“剪枝”列,而不是“微調(diào)”列
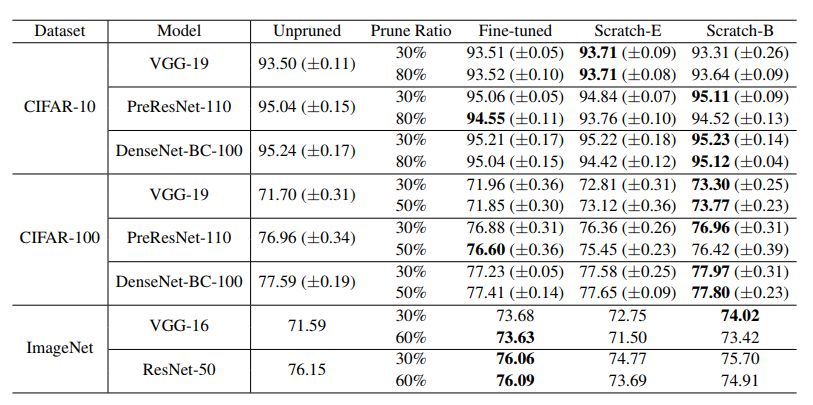
表6:非結(jié)構(gòu)化剪枝的結(jié)果(準(zhǔn)確度)“剪枝比”表示在所有卷積權(quán)重集中,進(jìn)行剪枝的參數(shù)的比例。

表7:用于檢測(cè)任務(wù)的剪枝結(jié)果(mAP)。Prune-C指的是剪枝分類預(yù)訓(xùn)練的權(quán)重,Prune-D指的是在權(quán)重轉(zhuǎn)移到檢測(cè)任務(wù)后剪枝。 Scratch-E / B表示從頭開始訓(xùn)練分類剪枝模型,移至檢測(cè)任務(wù)。
總之,對(duì)于面向預(yù)定義目標(biāo)架構(gòu)的剪枝方法而言,使用與大型模型(Scratch-E)數(shù)量相同的迭代次數(shù)來(lái)訓(xùn)練小模型,通常就足以實(shí)現(xiàn)與三步輸出的模型相同的精度。再加上目標(biāo)架構(gòu)是預(yù)定義的,在實(shí)際應(yīng)用中,人們往往更愿意直接從頭開始訓(xùn)練小模型。
此外,如果具備與大型模型相當(dāng)?shù)挠?jì)算預(yù)算(算力)時(shí),從頭訓(xùn)練的模型的性能甚至可能微調(diào)模型更高。
討論與結(jié)論
我們建議,未來(lái)應(yīng)采用相對(duì)高性能的基線方法來(lái)評(píng)估剪枝方法,尤其是在預(yù)定義目標(biāo)的體系結(jié)構(gòu)剪枝。除了高精度之外,從頭開始訓(xùn)練預(yù)定義的目標(biāo)模型與傳統(tǒng)的網(wǎng)絡(luò)剪枝相比具有以下優(yōu)勢(shì):
? 由于模型較小,可以使用更少的GPU資源來(lái)訓(xùn)練模型,而且可能比訓(xùn)練原始大型模型速度更快。
? 無(wú)需實(shí)施剪枝的標(biāo)準(zhǔn)和流程,這些流程有時(shí)需要逐層微調(diào)和/或需要針對(duì)不同的網(wǎng)絡(luò)架構(gòu)進(jìn)行定制。
? 可以避免調(diào)整剪枝過(guò)程中涉及的其他超參數(shù)。
我們的結(jié)果可利用剪枝方法來(lái)尋找高效的架構(gòu)或稀疏模式,可以通過(guò)自動(dòng)剪枝方法來(lái)完成。此外,在有些情況下,傳統(tǒng)的剪枝方法比從頭開始訓(xùn)練要快得多,比如:
?已經(jīng)提供預(yù)訓(xùn)練的大型模型,且訓(xùn)練預(yù)算很少。
? 需要獲得不同大小的多個(gè)模型,在這種情況下,可以訓(xùn)練大型模型,然后以不同的比例剪枝。
總之,我們的實(shí)驗(yàn)表明,從頭開始訓(xùn)練小修剪模型幾乎總能達(dá)到與典型的“訓(xùn)練-剪枝-微調(diào)”流程獲得的模型相當(dāng)或更高的精度。這改變了我們對(duì)過(guò)度參數(shù)化的必要性的理解,進(jìn)一步證明了自動(dòng)剪枝算法的價(jià)值,可以用來(lái)尋找高效的架構(gòu),并為架構(gòu)設(shè)計(jì)提供指導(dǎo)。
-
模型
+關(guān)注
關(guān)注
1文章
3464瀏覽量
49815 -
數(shù)據(jù)集
+關(guān)注
關(guān)注
4文章
1221瀏覽量
25195
原文標(biāo)題:清華&伯克利ICLR論文:重新思考6大剪枝方法
文章出處:【微信號(hào):AI_era,微信公眾號(hào):新智元】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
解讀CPU的組成指令集架構(gòu)
AVR架構(gòu)下的匯編語(yǔ)言常用指令集
精簡(jiǎn)指令集架構(gòu)RISC與復(fù)雜指令集架構(gòu)CISC有何區(qū)別
基于Vague集的網(wǎng)絡(luò)安全態(tài)勢(shì)評(píng)估方法
基于PC架構(gòu)的網(wǎng)絡(luò)時(shí)延測(cè)量方法

一種改進(jìn)的神經(jīng)網(wǎng)絡(luò)相關(guān)性剪枝算法
基于影響度剪枝的ELM分類算法
如何使用剪枝優(yōu)化與索引求交改進(jìn)Eclat算法
基于深度神經(jīng)網(wǎng)絡(luò)的結(jié)構(gòu)化剪枝算法
嵌入式設(shè)備的YOLO網(wǎng)絡(luò)剪枝算法
神經(jīng)網(wǎng)絡(luò)模型剪枝后泛化能力的驗(yàn)證方案
基于LZW編碼的卷積神經(jīng)網(wǎng)絡(luò)壓縮方法綜述
如何搭建VGG網(wǎng)絡(luò)實(shí)現(xiàn)Mnist數(shù)據(jù)集的圖像分類
DepGraph:任意架構(gòu)的結(jié)構(gòu)化剪枝,CNN、Transformer、GNN等都適用!
CVPR 2023:基于可恢復(fù)性度量的少樣本剪枝方法





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論