") 構(gòu)建一個(gè)相對(duì)較小的圖像識(shí)別卷積神經(jīng)網(wǎng)絡(luò)
構(gòu)建一個(gè)相對(duì)較小的圖像識(shí)別卷積神經(jīng)網(wǎng)絡(luò)
今天的文章是有關(guān) “高級(jí)卷積神經(jīng)” 的教程。我們希望您能夠以本文為起點(diǎn),在 TensorFlow 上構(gòu)建更大的 CNN 來(lái)處理視覺(jué)任務(wù)。
概述
CIFAR-10 分類問(wèn)題是機(jī)器學(xué)習(xí)領(lǐng)域一種常見(jiàn)的基準(zhǔn)問(wèn)題,其任務(wù)是將 RGB 32x32 像素的圖像分為以下 10 類:
airplane, automobile, bird, cat, deer, dog, frog, horse, ship, and truck.
有關(guān)詳情,請(qǐng)參閱CIFAR-10 頁(yè)面 (https://www.cs.toronto.edu/~kriz/cifar.html)及 Alex Krizhevsky 發(fā)表的一篇 技術(shù)報(bào)告 (https://tensorflow.google.cn/tutorials/images/deep_cnn?hl=zh-CN)。
目標(biāo)
本文的目標(biāo)是構(gòu)建一個(gè)相對(duì)較小的圖像識(shí)別卷積神經(jīng)網(wǎng)絡(luò)(CNN)。在此過(guò)程中,本文將:
重點(diǎn)介紹網(wǎng)絡(luò)架構(gòu)、訓(xùn)練和評(píng)估的規(guī)范結(jié)構(gòu)
提供一個(gè)用于構(gòu)建更大、更為復(fù)雜的模型的模板
選擇 CIFAR-10 的原因是它足夠復(fù)雜,可以用來(lái)練習(xí) TensorFlow 的大部分功能,進(jìn)而擴(kuò)展到大型模型。同時(shí),該模型足夠小,可以快速訓(xùn)練,是嘗試新想法以及實(shí)驗(yàn)新技術(shù)的理想之選。
本文的要點(diǎn)
CIFAR-10 教程介紹了幾個(gè)用于在 TensorFlow 中設(shè)計(jì)更大、更為復(fù)雜的模型的重要結(jié)構(gòu):
核心數(shù)學(xué)組件,包括卷積(維基百科頁(yè)面)、修正線性激活函數(shù)(維基百科頁(yè)面)、最大池化(維基百科頁(yè)面)和局部響應(yīng)歸一化(AlexNet 論文的第 3.3 節(jié))
訓(xùn)練期間網(wǎng)絡(luò)活動(dòng)(包括輸入圖像、損失以及激活函數(shù)和梯度的分布)的可視化
例行程序,用于計(jì)算已學(xué)參數(shù)的移動(dòng)平均值,并在評(píng)估期間使用這些平均值提升預(yù)測(cè)性能
實(shí)施學(xué)習(xí)速率計(jì)劃(隨時(shí)間的推移系統(tǒng)性地降低)
輸入數(shù)據(jù)的預(yù)取隊(duì)列,使模型避開(kāi)磁盤(pán)延遲和代價(jià)高的圖像預(yù)處理過(guò)程
此外,我們還提供了模型的多 GPU 版本,它會(huì)展示:
如何配置模型以跨多個(gè) GPU 卡并行訓(xùn)練
如何在多個(gè) GPU 間共享和更新變量
模型架構(gòu)
本 CIFAR-10 教程中的模型是一個(gè)多層架構(gòu),由卷積層和非線性層交替排列后構(gòu)成。這些層后面是全連接層,然后通向 softmax 分類器。該模型除了最頂部的幾層外,基本跟Alex Krizhevsky描述的模型架構(gòu)一致。
在 GPU 上經(jīng)過(guò)幾個(gè)小時(shí)的訓(xùn)練后,該模型的準(zhǔn)確率達(dá)到峰值(約 86%)。詳情請(qǐng)參閱下文和相應(yīng)代碼。模型中包含 1068298 個(gè)可學(xué)習(xí)參數(shù),對(duì)一張圖像進(jìn)行推理計(jì)算大約需要 1950 萬(wàn)個(gè)乘加操作。
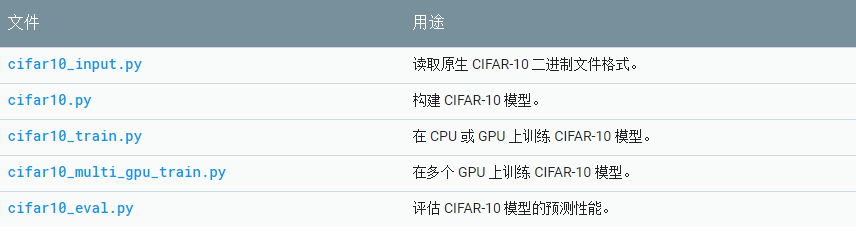
代碼結(jié)構(gòu)
本教程使用的代碼位于models/tutorials/image/cifar10/中。
CIFAR-10 模型
CIFAR-10 網(wǎng)絡(luò)主要包含在cifar10.py中。完整的訓(xùn)練圖大約包含 765 個(gè)操作。我們發(fā)現(xiàn),使用以下模塊構(gòu)建訓(xùn)練圖可最大限度地提高代碼的重復(fù)使用率:
模型輸入:inputs()和distorted_inputs()分別可添加讀取和預(yù)處理 CIFAR 圖像以用于評(píng)估和訓(xùn)練的操作
模型預(yù)測(cè):inference()可添加對(duì)提供的圖像進(jìn)行推理(即分類)的操作
模型訓(xùn)練:loss()和train()可添加計(jì)算損失和梯度、更新變量和呈現(xiàn)可視化匯總的操作
模型輸入
模型的輸入部分由inputs()和distorted_inputs()函數(shù)構(gòu)建,這兩種函數(shù)會(huì)從 CIFAR-10 二進(jìn)制數(shù)據(jù)文件中讀取圖像。這些文件包含字節(jié)長(zhǎng)度固定的記錄,因此我們可以使用tf.FixedLengthRecordReader。如需詳細(xì)了解Reader類的工作原理,請(qǐng)參閱 讀取數(shù)據(jù)(https://tensorflow.google.cn/api_guides/python/reading_data?hl=zh-CN#reading-from-files)。
圖像按以下方式處理:
從中心(用于評(píng)估)或隨機(jī)(用于訓(xùn)練)剪裁成 24 x 24 像素
進(jìn)行近似白化處理,使模型對(duì)圖像的動(dòng)態(tài)范圍變化不敏感
對(duì)于訓(xùn)練,我們還會(huì)額外向圖像應(yīng)用一系列隨機(jī)失真,以人為增加數(shù)據(jù)集的大小:
從左到右隨機(jī)翻轉(zhuǎn)圖像
隨機(jī)對(duì)圖像亮度進(jìn)行失真處理
隨機(jī)對(duì)圖像對(duì)比度進(jìn)行失真處理
要查看可采用的失真列表,請(qǐng)?jiān)L問(wèn)圖像頁(yè)面(https://tensorflow.google.cn/api_guides/python/image?hl=zh-CN)。此外,我們還向圖像附加了tf.summary.image,以便在TensorBoard中可視化它們。這對(duì)驗(yàn)證輸入的構(gòu)建是否正確十分有用。
從磁盤(pán)讀取圖像并進(jìn)行失真處理需要不少時(shí)間。為了防止這些操作影響訓(xùn)練速度,我們?cè)?16 個(gè)獨(dú)立的線程中執(zhí)行這些操作,而這些線程會(huì)不斷填充一個(gè) TensorFlow隊(duì)列。
模型預(yù)測(cè)
模型的預(yù)測(cè)部分由inference()函數(shù)構(gòu)建,該函數(shù)可添加計(jì)算預(yù)測(cè)對(duì)數(shù)的操作。模型這一部分的結(jié)構(gòu)如下:

下圖是從 TensorBoard 生成的圖表,描述了推理操作的過(guò)程:
練習(xí):inference的輸出為非歸一化對(duì)數(shù)。請(qǐng)嘗試使用tf.nn.softmax修改網(wǎng)絡(luò)架構(gòu)以返回歸一化預(yù)測(cè)結(jié)果。
inputs()和inference()函數(shù)提供了評(píng)估模型所需的所有組件。我們現(xiàn)在將重點(diǎn)轉(zhuǎn)向構(gòu)建訓(xùn)練模型所需的操作。
練習(xí):inference()中的模型架構(gòu)與cuda-convnet中指定的 CIFAR-10 模型的架構(gòu)略有不同。具體而言,Alex 的初始模型的頂層是局部連接層,而非全連接層。請(qǐng)嘗試修改架構(gòu)以在頂層中完全重現(xiàn)局部連接層。
模型訓(xùn)練
訓(xùn)練網(wǎng)絡(luò)執(zhí)行 N 元分類的常用方法是多項(xiàng)邏輯回歸(又稱 Softmax 回歸)。Softmax 回歸向網(wǎng)絡(luò)輸出應(yīng)用Softmax非線性函數(shù),并計(jì)算歸一化預(yù)測(cè)與標(biāo)簽索引之間的交叉熵。在正則化過(guò)程中,我們還會(huì)對(duì)所有已學(xué)變量應(yīng)用常見(jiàn)的權(quán)重衰減損失。模型的目標(biāo)函數(shù)是求交叉熵?fù)p失和所有權(quán)重衰減項(xiàng)的和并由loss()函數(shù)返回。
我們通過(guò)tf.summary.scalar在 TensorBoard 中對(duì)其進(jìn)行可視化:
我們使用標(biāo)準(zhǔn)的梯度下降法訓(xùn)練模型(有關(guān)其他方法,請(qǐng)參閱 訓(xùn)練https://github.com/tensorflow/docs/tree/master/site/en/api_guides/python),其中學(xué)習(xí)速率隨時(shí)間的推移呈指數(shù)級(jí)衰減。
train()函數(shù)會(huì)添加一些最小化目標(biāo)所需的操作,包括計(jì)算梯度、更新學(xué)習(xí)變量(詳情請(qǐng)參閱tf.train.GradientDescentOptimizerhttps://tensorflow.google.cn/api_docs/python/tf/train/GradientDescentOptimizer?hl=zh-CN)。它會(huì)返回一項(xiàng)用以對(duì)一批圖像執(zhí)行所有計(jì)算的操作,以便訓(xùn)練并更新模型。
啟動(dòng)并訓(xùn)練模型
我們已構(gòu)建了模型,現(xiàn)在使用腳本cifar10_train.py啟動(dòng)該模型并執(zhí)行訓(xùn)練操作。
python cifar10_train.py
注意:首次運(yùn)行 CIFAR-10 教程中的任何目標(biāo)時(shí),系統(tǒng)都會(huì)自動(dòng)下載 CIFAR-10 數(shù)據(jù)集。該數(shù)據(jù)集大約為 160MB,因此首次運(yùn)行時(shí)您可以喝杯咖啡小棲一會(huì)。
您應(yīng)該會(huì)看到以下輸出:
Filling queue with 20000 CIFAR images before starting to train. This will take a few minutes.
2015-11-04 11:45:45.927302: step 0, loss = 4.68 (2.0 examples/sec; 64.221 sec/batch)2015-11-04 11:45:49.133065: step 10, loss = 4.66 (533.8 examples/sec; 0.240 sec/batch)2015-11-04 11:45:51.397710: step 20, loss = 4.64 (597.4 examples/sec; 0.214 sec/batch)2015-11-04 11:45:54.446850: step 30, loss = 4.62 (391.0 examples/sec; 0.327 sec/batch)2015-11-04 11:45:57.152676: step 40, loss = 4.61 (430.2 examples/sec; 0.298 sec/batch)2015-11-04 11:46:00.437717: step 50, loss = 4.59 (406.4 examples/sec; 0.315 sec/batch)...
該腳本每隔 10 步報(bào)告一次總損失值及最后一批數(shù)據(jù)的處理速度。需要注意以下幾點(diǎn):
第一批數(shù)據(jù)的處理速度可能會(huì)非常慢(例如,需要幾分鐘),因?yàn)轭A(yù)處理線程需要將 20000 張?zhí)幚磉^(guò)的 CIFAR 圖像填充到隨機(jī)化處理隊(duì)列中
報(bào)告的損失是最近一批數(shù)據(jù)的平均損失。請(qǐng)注意,該損失是交叉熵和所有權(quán)重衰減項(xiàng)的和
請(qǐng)留意一批數(shù)據(jù)的處理速度。上述數(shù)字是在 Tesla K40c 上得出的結(jié)果。如果您是在 CPU 上運(yùn)行,速度可能會(huì)慢些
練習(xí):進(jìn)行實(shí)驗(yàn)時(shí),有時(shí)候第一個(gè)訓(xùn)練步持續(xù)時(shí)間比較長(zhǎng)。請(qǐng)嘗試減少最初填充隊(duì)列的圖像數(shù)量。在cifar10_input.py中搜索min_fraction_of_examples_in_queue。
cifar10_train.py會(huì)定期將所有模型參數(shù)保存在檢查點(diǎn)文件中,但不會(huì)對(duì)模型進(jìn)行評(píng)估。cifar10_eval.py將使用檢查點(diǎn)文件衡量預(yù)測(cè)性能(請(qǐng)參閱下文中的評(píng)估模型部分)。
如果您按照上述步驟進(jìn)行操作,那么現(xiàn)在已開(kāi)始訓(xùn)練 CIFAR-10 模型了。恭喜!
cifar10_train.py返回的終端文本幾乎不提供任何有關(guān)模型訓(xùn)練情況的信息。我們希望在訓(xùn)練期間更深入地了解模型的以下信息:
損失是真的在減小,還是只是噪點(diǎn)?
為模型提供的圖像是否合適?
梯度、激活函數(shù)和權(quán)重的值是否合理?
當(dāng)前的學(xué)習(xí)速率是多少?
TensorBoard可提供此功能,它會(huì)通過(guò)tf.summary.FileWriter顯示定期從cifar10_train.py導(dǎo)出的數(shù)據(jù)。
例如,我們可以觀看local3特征中激活函數(shù)的分步及稀疏程度在訓(xùn)練過(guò)程中的變化情況:
跟蹤各個(gè)損失函數(shù)以及總損失在不同時(shí)間段的情況尤為有用。不過(guò),由于訓(xùn)練所用的批次較小,因此損失中夾雜的噪點(diǎn)相當(dāng)多。在實(shí)踐中,我們發(fā)現(xiàn)除了原始值之外,可視化損失的移動(dòng)平均值也非常有用。了解腳本如何將tf.train.ExponentialMovingAverage用于此用途。
評(píng)估模型
現(xiàn)在,我們來(lái)評(píng)估一下經(jīng)過(guò)訓(xùn)練的模型在保留數(shù)據(jù)集上的表現(xiàn)如何。該模型由腳本cifar10_eval.py進(jìn)行評(píng)估。它通過(guò)inference()函數(shù)構(gòu)建模型,并使用 CIFAR-10 評(píng)估數(shù)據(jù)集中的全部 10000 張圖像。它會(huì)計(jì)算 precision @ 1,表示得分最高的一項(xiàng)預(yù)測(cè)與圖像的真實(shí)標(biāo)簽一致的頻率。
為了監(jiān)控模型在訓(xùn)練過(guò)程中的改進(jìn)情況,評(píng)估腳本會(huì)定期在cifar10_train.py創(chuàng)建的最新檢查點(diǎn)文件上運(yùn)行。
python cifar10_eval.py
注意不要在同一 GPU 上同時(shí)運(yùn)行評(píng)估和訓(xùn)練二進(jìn)制文件,否則可能會(huì)耗盡內(nèi)存。您可以考慮在其他 GPU(如可用)上單獨(dú)運(yùn)行評(píng)估二進(jìn)制文件,或在同一 GPU 上運(yùn)行評(píng)估二進(jìn)制文件時(shí)暫停訓(xùn)練二進(jìn)制文件的運(yùn)行。
您應(yīng)該會(huì)看到以下輸出:
2015-11-06 08:30:44.391206: precision @ 1 = 0.860...
該腳本只是定期返回 precision @ 1,在本例中,返回的準(zhǔn)確率為 86%。cifar10_eval.py還會(huì)導(dǎo)出可以在 TensorBoard 中可視化的匯總。在評(píng)估期間,您可通過(guò)這些匯總進(jìn)一步了解模型。
訓(xùn)練腳本會(huì)計(jì)算所有已學(xué)變量的移動(dòng)平均值。評(píng)估腳本會(huì)將所有已學(xué)模型參數(shù)替換為移動(dòng)平均值。這種替換可以在評(píng)估時(shí)提升模型的性能。
練習(xí):根據(jù) precision @ 1,采用平均參數(shù)可以使預(yù)測(cè)性能提升 3% 左右。修改cifar10_eval.py,使模型不采用平均參數(shù),然后驗(yàn)證預(yù)測(cè)性能是否會(huì)下降。
使用多個(gè) GPU 卡訓(xùn)練模型
現(xiàn)代工作站可能會(huì)包含多個(gè)用于科學(xué)計(jì)算的 GPU。TensorFlow 可利用此環(huán)境在多個(gè)卡上同時(shí)運(yùn)行訓(xùn)練操作。
如果要以并行的分布式方式訓(xùn)練模型,則需要協(xié)調(diào)訓(xùn)練過(guò)程。在接下來(lái)的內(nèi)容中,術(shù)語(yǔ) “模型副本” 指在數(shù)據(jù)子集上訓(xùn)練的模型副本。
簡(jiǎn)單地采用模型參數(shù)異步更新方法會(huì)導(dǎo)致訓(xùn)練性能無(wú)法達(dá)到最佳,因?yàn)閱蝹€(gè)模型副本在訓(xùn)練時(shí)使用的可能是過(guò)時(shí)的模型參數(shù)。反之,如果采用完全同步的更新后參數(shù),其速度堪比最慢的模型副本。
在具有多個(gè) GPU 卡的工作站中,每個(gè) GPU 的速度大致相當(dāng),且具有足夠的內(nèi)存來(lái)運(yùn)行整個(gè) CIFAR-10 模型。因此,我們選擇按照以下方式設(shè)計(jì)訓(xùn)練系統(tǒng):
在每個(gè) GPU 上放一個(gè)模型副本
等待所有 GPU 完成一批數(shù)據(jù)的處理工作,然后同步更新模型參數(shù)
模型示意圖如下所示:
請(qǐng)注意,每個(gè) GPU 都會(huì)針對(duì)一批唯一的數(shù)據(jù)計(jì)算推理和梯度。這種設(shè)置可以有效地將一大批數(shù)據(jù)劃分到各個(gè) GPU 上。
這種設(shè)置要求所有 GPU 都共享模型參數(shù)。眾所周知,將數(shù)據(jù)傳輸?shù)?GPU 或從中向外傳輸數(shù)據(jù)的速度非常慢。因此,我們決定在 CPU 上存儲(chǔ)和更新所有模型參數(shù)(如綠色方框所示)。當(dāng)所有 GPU 均處理完一批新數(shù)據(jù)時(shí),系統(tǒng)會(huì)將一組全新的模型參數(shù)傳輸給相應(yīng) GPU。
GPU 會(huì)同步運(yùn)行。GPU 的所有梯度將累積并求平均值(如綠色方框所示)。模型參數(shù)會(huì)更新為所有模型副本的梯度平均值。
將變量和操作放到多個(gè)設(shè)備上
將操作和變量放到多個(gè)設(shè)備上需要一些特殊的抽象操作。
第一個(gè)抽象操作是計(jì)算單個(gè)模型副本的推理和梯度的函數(shù)。在代碼中,我們將此抽象操作稱為 “tower”。我們必須為每個(gè) tower 設(shè)置兩個(gè)屬性:
tower 中所有操作的唯一名稱。tf.name_scope通過(guò)添加作用域前綴提供唯一的名稱。例如,第一個(gè) tower 中的所有操作都會(huì)附帶tower_0前綴,例如tower_0/conv1/Conv2D
運(yùn)行 tower 中操作的首選硬件設(shè)備。tf.device會(huì)指定該屬性。例如,第一個(gè) tower 中的所有操作都位于device('/device:GPU:0')作用域內(nèi),表示它們應(yīng)在第一個(gè) GPU 上運(yùn)行
為了在多 GPU 版本中共享變量,所有變量都固定到 CPU 上且通過(guò)tf.get_variable訪問(wèn)。了解如何共享變量。
在多個(gè) GPU 卡上啟動(dòng)并訓(xùn)練模型
如果計(jì)算機(jī)上安裝了多個(gè) GPU 卡,您可以使用cifar10_multi_gpu_train.py腳本借助它們加快模型的訓(xùn)練過(guò)程。此版訓(xùn)練腳本可在多個(gè) GPU 卡上并行訓(xùn)練模型。
python cifar10_multi_gpu_train.py --num_gpus=2
請(qǐng)注意,使用的 GPU 卡數(shù)量默認(rèn)為 1。此外,如果計(jì)算機(jī)上僅有一個(gè) GPU,則所有計(jì)算都會(huì)在該 GPU 上運(yùn)行,即使您設(shè)置的是多個(gè) GPU。
練習(xí):cifar10_train.py的默認(rèn)設(shè)置是在大小為 128 的批次數(shù)據(jù)上運(yùn)行。請(qǐng)嘗試在 2 個(gè) GPU 上運(yùn)行cifar10_multi_gpu_train.py,批次大小為 64,然后比較這兩種方式的訓(xùn)練速度。
后續(xù)學(xué)習(xí)計(jì)劃
如果您有興趣開(kāi)發(fā)并訓(xùn)練您自己的圖像分類系統(tǒng),我們建議您分叉本教程的代碼,并替換組件以解決您的圖像分類問(wèn)題。
練習(xí):下載Street View House Numbers (SVHN)數(shù)據(jù)集(http://ufldl.stanford.edu/housenumbers/)。分叉 CIFAR-10 教程的代碼并將輸入數(shù)據(jù)替換為 SVHN。嘗試調(diào)整網(wǎng)絡(luò)架構(gòu)以提高預(yù)測(cè)性能。
-
神經(jīng)網(wǎng)絡(luò)
+關(guān)注
關(guān)注
42文章
4810瀏覽量
102943 -
圖像識(shí)別
+關(guān)注
關(guān)注
9文章
526瀏覽量
38937
原文標(biāo)題:TensorFlow 中的高級(jí)卷積神經(jīng)網(wǎng)絡(luò)
文章出處:【微信號(hào):tensorflowers,微信公眾號(hào):Tensorflowers】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
使用Python卷積神經(jīng)網(wǎng)絡(luò)(CNN)進(jìn)行圖像識(shí)別的基本步驟
【uFun試用申請(qǐng)】基于cortex-m系列核和卷積神經(jīng)網(wǎng)絡(luò)算法的圖像識(shí)別
基于賽靈思FPGA的卷積神經(jīng)網(wǎng)絡(luò)實(shí)現(xiàn)設(shè)計(jì)
基于特征交換的卷積神經(jīng)網(wǎng)絡(luò)圖像分類算法






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論