") 一文解讀語音識(shí)別的運(yùn)行原理
一文解讀語音識(shí)別的運(yùn)行原理
今天的文章將向您展示如何構(gòu)建可以識(shí)別 10 個(gè)不同字詞的基本語音識(shí)別網(wǎng)絡(luò)。需要注意的是,真正的語音和音頻識(shí)別系統(tǒng)要復(fù)雜得多,但就像用于識(shí)別圖像的 MNIST,這個(gè)基本語音識(shí)別網(wǎng)絡(luò)能夠幫助您基本了解所涉及的技術(shù)。學(xué)完本教程后,您將獲得一個(gè)模型,該模型會(huì)嘗試將時(shí)長(zhǎng)為 1 秒的音頻片段歸類為無聲、未知字詞、“yes”、“no”、“up”、“down”、“l(fā)eft”、“right”、“on”、“off”、“stop” 或 “go”。您還可以在 Android 應(yīng)用中運(yùn)行該模型。
準(zhǔn)備
您應(yīng)確保安裝了 TensorFlow;此外,由于腳本會(huì)下載超過 1GB 的訓(xùn)練數(shù)據(jù),因此您需要確保計(jì)算機(jī)擁有穩(wěn)定的互聯(lián)網(wǎng)連接和足夠的可用空間。訓(xùn)練過程可能需要幾個(gè)小時(shí),因此請(qǐng)確保您的計(jì)算機(jī)可以完成這么長(zhǎng)時(shí)間的訓(xùn)練操作。
訓(xùn)練
要開始訓(xùn)練過程,請(qǐng)轉(zhuǎn)到 TensorFlow 源代碼樹,然后運(yùn)行以下腳本:
python tensorflow/examples/speech_commands/train.py
該腳本會(huì)先下載語音指令數(shù)據(jù)集,其中包含超過 105000 個(gè) WAVE 音頻文件,音頻內(nèi)容是有人說出 30 個(gè)不同的字詞。這些數(shù)據(jù)由 Google 收集,并依據(jù) CC BY 許可發(fā)布,您可以提交 5 分鐘自己的錄音來幫助改進(jìn)該數(shù)據(jù)。歸檔數(shù)據(jù)超過 2GB,因此這部分過程可能需要一段時(shí)間,但您應(yīng)該可以看到進(jìn)度日志;下載完成后,您無需再次執(zhí)行此步驟。如需詳細(xì)了解該數(shù)據(jù)集,請(qǐng)參閱https://arxiv.org/abs/1804.03209
下載完成后,您將看到如下日志信息:
I0730 16:53:44.766740 55030 train.py:176] Training from step: 1I0730 16:53:47.289078 55030 train.py:217] Step #1: rate 0.001000, accuracy 7.0%, cross entropy 2.611571
這表明初始化過程已經(jīng)完成,訓(xùn)練循環(huán)已經(jīng)開始。您將看到該日志輸出每個(gè)訓(xùn)練步的信息。下面詳細(xì)說明了該日志信息的含義:
Step #1表明正在進(jìn)行訓(xùn)練循環(huán)的第一步。在此示例中總共有 18000 個(gè)訓(xùn)練步,您可以查看步編號(hào)來了解還有多少步即可完成。
rate 0.001000是控制網(wǎng)絡(luò)權(quán)重更新速度的學(xué)習(xí)速率。在訓(xùn)練的早期階段,它是一個(gè)相對(duì)較大的數(shù)字 (0.001),但在訓(xùn)練周期的后期會(huì)減少到原來的十分之一,即 0.0001。
accuracy 7.0%表示模型在本訓(xùn)練步中預(yù)測(cè)正確的類別數(shù)量。該值通常會(huì)有較大的波動(dòng),但應(yīng)該會(huì)隨著訓(xùn)練的進(jìn)行總體有所提高。該模型會(huì)輸出一個(gè)數(shù)字?jǐn)?shù)組,每個(gè)標(biāo)簽對(duì)應(yīng)一個(gè)數(shù)字,每個(gè)數(shù)字都表示輸入可能歸入該類別的預(yù)測(cè)概率。可通過選擇得分最高的條目來挑選預(yù)測(cè)標(biāo)簽。得分始終介于 0 到 1 之間,值越高表示結(jié)果的置信度越高。
cross entropy 2.611571是用于指導(dǎo)訓(xùn)練過程的損失函數(shù)的結(jié)果。它是一個(gè)得分,通過將當(dāng)前訓(xùn)練運(yùn)行的得分向量與正確標(biāo)簽進(jìn)行比較計(jì)算而出,該得分應(yīng)在訓(xùn)練期間呈下滑趨勢(shì)。
經(jīng)過 100 步之后,您應(yīng)看到如下所示的行:
I0730 16:54:41.813438 55030 train.py:252] Saving to "/tmp/speech_commands_train/conv.ckpt-100"
此行會(huì)將當(dāng)前的訓(xùn)練權(quán)重保存到檢查點(diǎn)文件中。如果訓(xùn)練腳本中斷了,您可以查找上次保存的檢查點(diǎn),然后將--start_checkpoint=/tmp/speech_commands_train/conv.ckpt-100用作命令行參數(shù)重啟該腳本,以便從該點(diǎn)開始。
混淆矩陣
經(jīng)過 400 步之后,您會(huì)看到以下日志信息:
I0730 16:57:38.073667 55030 train.py:243] Confusion Matrix:[[258 0 0 0 0 0 0 0 0 0 0 0][ 7 6 26 94 7 49 1 15 40 2 0 11][ 10 1 107 80 13 22 0 13 10 1 0 4][ 1 3 16 163 6 48 0 5 10 1 0 17][ 15 1 17 114 55 13 0 9 22 5 0 9][ 1 1 6 97 3 87 1 12 46 0 0 10][ 8 6 86 84 13 24 1 9 9 1 0 6][ 9 3 32 112 9 26 1 36 19 0 0 9][ 8 2 12 94 9 52 0 6 72 0 0 2][ 16 1 39 74 29 42 0 6 37 9 0 3][ 15 6 17 71 50 37 0 6 32 2 1 9][ 11 1 6 151 5 42 0 8 16 0 0 20]]
第一部分是混淆矩陣。要理解它的具體含義,您首先需要了解所用的標(biāo)簽。在本示例中,所用的標(biāo)簽是 “silence”、“unknown”、“yes”、“no”、“up”、“down”、“l(fā)eft”、“right”、“on”、“off”、“stop” 和 “go”。每列代表一組被模型預(yù)測(cè)為每個(gè)標(biāo)簽的樣本,因此第一列代表預(yù)測(cè)為無聲的所有音頻片段,第二列代表預(yù)測(cè)為未知字詞的所有音頻片段,第三列代表預(yù)測(cè)為 “yes” 的所有音頻片段,依此類推。
每行表示音頻片段實(shí)際歸入的標(biāo)簽。第一行是歸入無聲的所有音頻片段,第二行是歸入未知字詞的所有音頻片段,第三行是歸入 “yes” 的所有音頻片段,依此類推。
此矩陣比單個(gè)準(zhǔn)確率得分更加有用,因?yàn)樗梢院芎玫乜偨Y(jié)網(wǎng)絡(luò)出現(xiàn)的錯(cuò)誤。在此示例中,您可以發(fā)現(xiàn),除了第一個(gè)數(shù)值以外,第一行中的所有條目均為 0。因?yàn)榈谝恍斜硎舅袑?shí)際無聲的音頻片段,這意味著所有音頻片段都未被錯(cuò)誤地標(biāo)記為字詞,因此我們未得出任何有關(guān)無聲的假負(fù)例。這表示網(wǎng)絡(luò)已經(jīng)可以很好地區(qū)分無聲和字詞。
如果我們往下看,就會(huì)發(fā)現(xiàn)第一列有大量非零值。該列表示預(yù)測(cè)為無聲的所有音頻片段,因此第一個(gè)單元格外的正數(shù)是錯(cuò)誤的預(yù)測(cè)。這表示一些實(shí)際是語音字詞的音頻片段被預(yù)測(cè)為無聲,因此我們得出了很多假正例。
完美的模型會(huì)生成混淆矩陣,除了穿過中心的對(duì)角線上的條目以外,所有其他條目都為 0。發(fā)現(xiàn)偏離這個(gè)模式的地方有助于您了解模型最容易在哪些方面混淆;確定問題所在后,您就可以通過添加更多數(shù)據(jù)或清理類別來解決這些問題。
驗(yàn)證
在混淆矩陣之后,您應(yīng)看到如下所示的行:
I0730 16:57:38.073777 55030 train.py:245] Step 400: Validation accuracy = 26.3% (N=3093)
最好將數(shù)據(jù)集分成三個(gè)類別。最大的子集(本示例中為約 80% 的數(shù)據(jù))用于訓(xùn)練網(wǎng)絡(luò),較小的子集(本示例中為約 10% 的數(shù)據(jù),稱為 “驗(yàn)證” 集)預(yù)留下來以評(píng)估訓(xùn)練期間的準(zhǔn)確率,另一個(gè)子集(剩下的 10%,稱為 “測(cè)試” 集)用來評(píng)估訓(xùn)練完成后的準(zhǔn)確率。
之所以采用這種拆分方法,是因?yàn)槭冀K存在這樣一種風(fēng)險(xiǎn):網(wǎng)絡(luò)在訓(xùn)練期間開始記憶輸入。通過將驗(yàn)證集分離開來,可以確保模型能夠處理它之前從未見過的數(shù)據(jù)。測(cè)試集是一種額外的保護(hù)措施,可以確保您不僅以適合訓(xùn)練集和驗(yàn)證集的方式調(diào)整模型,而且使模型能夠泛化到范圍更廣的輸入。
訓(xùn)練腳本會(huì)自動(dòng)將數(shù)據(jù)集分為這三個(gè)類別,上面的日志行會(huì)顯示在驗(yàn)證集上運(yùn)行時(shí)模型的準(zhǔn)確率。理想情況下,該準(zhǔn)確率應(yīng)該相當(dāng)接近訓(xùn)練準(zhǔn)確率。如果訓(xùn)練準(zhǔn)確率有所提高但驗(yàn)證準(zhǔn)確率沒有,則表明存在過擬合,模型只學(xué)習(xí)了有關(guān)訓(xùn)練音頻片段的信息,而沒有學(xué)習(xí)能泛化的更廣泛模式。
Tensorboard
使用 Tensorboard 可以很好地觀察訓(xùn)練進(jìn)度。默認(rèn)情況下,腳本會(huì)將事件保存到 /tmp/retrain_logs,您可以通過運(yùn)行以下命令加載這些事件:
tensorboard --logdir /tmp/retrain_logs
然后,在瀏覽器中轉(zhuǎn)到http://localhost:6006,您將看到顯示模型進(jìn)度的圖表。
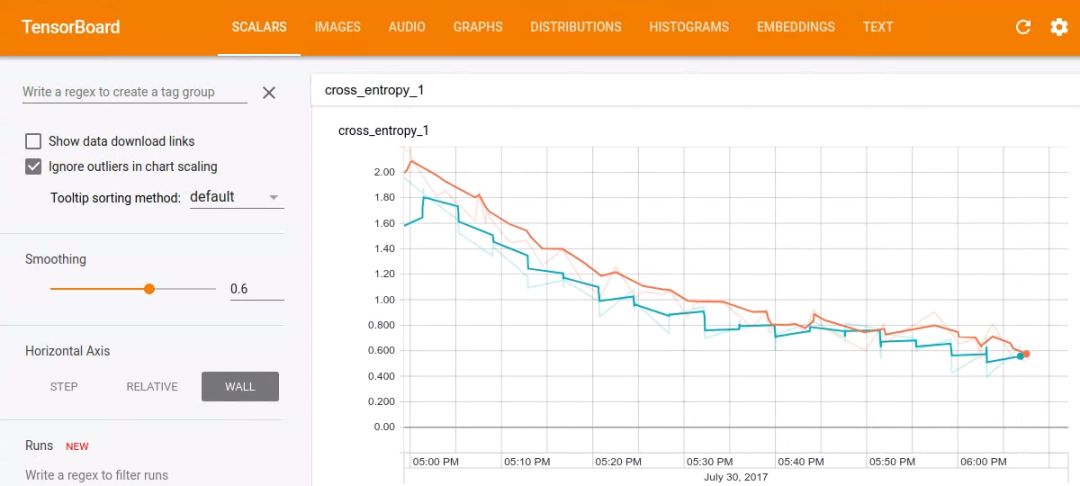
訓(xùn)練完成
經(jīng)過幾個(gè)小時(shí)(具體取決于計(jì)算機(jī)的速度)的訓(xùn)練后,腳本應(yīng)該已經(jīng)完成了全部 18000 個(gè)訓(xùn)練步。它會(huì)輸出在測(cè)試集上運(yùn)行時(shí)的最終混淆矩陣以及準(zhǔn)確率得分。使用默認(rèn)設(shè)置時(shí),您應(yīng)該會(huì)看到準(zhǔn)確率介于 85% 到 90% 之間。
由于音頻識(shí)別在移動(dòng)設(shè)備上特別有用,因此接下來我們會(huì)將其導(dǎo)出為易于在這些平臺(tái)上使用的緊湊格式。為此,請(qǐng)運(yùn)行以下命令行:
python tensorflow/examples/speech_commands/freeze.py --start_checkpoint=/tmp/speech_commands_train/conv.ckpt-18000 --output_file=/tmp/my_frozen_graph.pb
創(chuàng)建凍結(jié)模型后,您可以使用label_wav.py腳本對(duì)其進(jìn)行測(cè)試,如下所示:
python tensorflow/examples/speech_commands/label_wav.py --graph=/tmp/my_frozen_graph.pb --labels=/tmp/speech_commands_train/conv_labels.txt --wav=/tmp/speech_dataset/left/a5d485dc_nohash_0.wav
上述命令應(yīng)該會(huì)輸出 3 個(gè)標(biāo)簽:
left (score = 0.81477)right (score = 0.14139)_unknown_ (score = 0.03808)
希望 “l(fā)eft” 的得分最高,因?yàn)樗钦_的標(biāo)簽,但由于訓(xùn)練是隨機(jī)的,因此嘗試的第一個(gè)文件可能并非如此。嘗試一下同一文件夾中的其他一些 .wav 文件,看看效果如何。
得分介于 0 到 1 之間,值越高表示模型對(duì)其預(yù)測(cè)越有信心。
在 Android 應(yīng)用中運(yùn)行模型
要查看該模型在實(shí)際應(yīng)用中的工作原理,最簡(jiǎn)單的方法是下載預(yù)構(gòu)建的 Android 演示應(yīng)用,并將其安裝在手機(jī)上。您會(huì)在應(yīng)用列表中看到 “TF Speech”,打開它就會(huì)看到我們剛剛訓(xùn)練模型時(shí)使用的動(dòng)詞列表(以 “Yes” 和 “No” 開始)。授權(quán)該應(yīng)用使用麥克風(fēng)以后,您應(yīng)該可以試著說出這些字詞,在該模型識(shí)別出其中一個(gè)字詞時(shí),您會(huì)在界面中看到相應(yīng)字詞突出顯示出來。
您還可以自行構(gòu)建該應(yīng)用,因?yàn)樗情_源的,可在 GitHub 上的 TensorFlow 代碼庫中找到。默認(rèn)情況下,它會(huì)從 tensorflow.org 下載預(yù)訓(xùn)練的模型,但您可以輕松地將其替換為自己訓(xùn)練的模型。如果這樣做,您需要確保主要 SpeechActivity Java 源文件中的常量(例如SAMPLE_RATE和SAMPLE_DURATION)與您在訓(xùn)練期間對(duì)默認(rèn)設(shè)置所做的任何更改相匹配。您還會(huì)看到一個(gè)Java 版本的 RecognizeCommands 模塊,它與本教程中的 C++ 版本非常相似。如果您已經(jīng)調(diào)整了參數(shù),也可以在 SpeechActivity 中進(jìn)行更新,以獲得與服務(wù)器測(cè)試中的結(jié)果相同的結(jié)果。
演示應(yīng)用會(huì)根據(jù)您復(fù)制到資源(位于凍結(jié)圖旁邊)中的標(biāo)簽文本文件自動(dòng)更新其結(jié)果界面列表,這意味著您可以輕松嘗試不同的模型,而無需更改任何代碼。如果更改路徑,則需要更新LABEL_FILENAME和MODEL_FILENAME以指向所添加的文件。
此模型的工作原理
本教程中使用的架構(gòu)基于小型關(guān)鍵字檢測(cè)卷積神經(jīng)網(wǎng)絡(luò)這篇論文中介紹的一些架構(gòu)。之所以選擇它,是因?yàn)樗m然不是最先進(jìn)的架構(gòu),但是相對(duì)簡(jiǎn)單、可快速訓(xùn)練,并且易于理解。可以通過多種方法構(gòu)建用于處理音頻的神經(jīng)網(wǎng)絡(luò)模型,其中包括遞歸網(wǎng)絡(luò)或擴(kuò)張(帶洞)卷積。對(duì)于本教程所基于的卷積網(wǎng)絡(luò)類型,接觸過圖像識(shí)別的人可能都很熟悉。不過,初次接觸時(shí)也可能會(huì)覺得不可思議,因?yàn)橐纛l本身是一段時(shí)間內(nèi)的一維連續(xù)信號(hào),而不是二維空間問題。
為了解決這一問題,我們會(huì)定義一個(gè)我們認(rèn)為我們的語音字詞應(yīng)該符合的時(shí)間范圍,并將這段時(shí)間內(nèi)的音頻信號(hào)轉(zhuǎn)換成圖像。為此,可以將傳入的音頻樣本分成小段(時(shí)長(zhǎng)僅為幾毫秒)并計(jì)算一組頻段內(nèi)頻率的強(qiáng)度。一段音頻內(nèi)的每組頻率強(qiáng)度被視為數(shù)字向量,這些向量按時(shí)間順序排列,形成一個(gè)二維數(shù)組。然后,該值數(shù)組可被視為單通道圖像,稱為聲譜圖。如果要查看音頻樣本生成的圖像類型,可以運(yùn)行 wav_to_spectrogram 工具:
bazel run tensorflow/examples/wav_to_spectrogram:wav_to_spectrogram -- --input_wav=/tmp/speech_dataset/happy/ab00c4b2_nohash_0.wav --output_image=/tmp/spectrogram.png
如果您打開/tmp/spectrogram.png,應(yīng)該會(huì)看到如下內(nèi)容:
由于 TensorFlow 的內(nèi)存排序原因,該圖像中的時(shí)間從上往下逐漸增加,而頻率從左到右排列,這與時(shí)間從左到右排列的聲譜圖慣例不同。您應(yīng)該能夠看到幾個(gè)不同的部分,第一個(gè)音節(jié) “Ha” 與 “ppy” 不同。
由于人耳對(duì)某些頻率更加敏感,因此語音識(shí)別領(lǐng)域傳統(tǒng)的做法是進(jìn)一步處理該表示法,將其轉(zhuǎn)換成一組梅爾倒頻譜系數(shù)(簡(jiǎn)稱 MFCC)。MFCC 也是一種二維單通道表示法,因此也可將其視為圖像。如果您的目標(biāo)是一般聲音而不是語音,您可以跳過此步驟并直接在聲譜圖上進(jìn)行操作。
然后,這些處理步驟生成的圖像會(huì)饋送到多層卷積神經(jīng)網(wǎng)絡(luò)中,最后是全連接層,后跟 softmax。您可以在以下位置了解該部分的定義:tensorflow/examples/speech_commands/models.py。
流式處理準(zhǔn)確率
大部分音頻識(shí)別應(yīng)用需要在連續(xù)的音頻流上運(yùn)行,而不是在單個(gè)音頻片段上運(yùn)行。在此環(huán)境中使用模型的典型方法是在不同的時(shí)間偏移量處重復(fù)應(yīng)用該模型,并計(jì)算一小段時(shí)間內(nèi)結(jié)果的平均值,以生成平滑預(yù)測(cè)。如果您將輸入視為圖像,則它將沿時(shí)間軸持續(xù)滾動(dòng)。我們想要識(shí)別的字詞可能在任意時(shí)間點(diǎn)出現(xiàn),因此,我們需要拍攝一系列快照,以便有機(jī)會(huì)生成一種對(duì)齊方式,用于捕獲在我們饋送到模型的時(shí)間段內(nèi)出現(xiàn)的大部分語音內(nèi)容。如果我們以足夠快的速度采樣,那么我們就很有可能在多個(gè)時(shí)間段內(nèi)捕獲相關(guān)字詞,因此計(jì)算結(jié)果的平均值可以提高預(yù)測(cè)的整體置信度。
有關(guān)如何對(duì)流式數(shù)據(jù)使用模型的示例,請(qǐng)查看test_streaming_accuracy.cc(https://www.tensorflowers.cn/t/7512)。該示例使用RecognizeCommands(https://www.tensorflowers.cn/t/7514)類處理一個(gè)較長(zhǎng)的輸入音頻、嘗試檢測(cè)字詞,并將這些預(yù)測(cè)結(jié)果與標(biāo)簽和時(shí)間的真實(shí)列表進(jìn)行對(duì)比。該示例可清楚說明如何將模型應(yīng)用于一段時(shí)間內(nèi)的音頻信號(hào)流。
要測(cè)試模型,您需要使用一個(gè)時(shí)長(zhǎng)較長(zhǎng)的音頻文件,以及標(biāo)注每個(gè)語音字詞出現(xiàn)位置的標(biāo)簽文件。如果您不想自己錄制音頻,可以使用generate_streaming_test_wav實(shí)用程序生成一些合成測(cè)試數(shù)據(jù)。默認(rèn)情況下,該實(shí)用程序會(huì)生成一個(gè)時(shí)長(zhǎng)為 10 分鐘的 .wav 文件(其中大約每隔 3 秒出現(xiàn)一個(gè)語音字詞),以及一個(gè)包含字詞語音實(shí)際出現(xiàn)時(shí)間的文本文件。這些字詞來自當(dāng)前數(shù)據(jù)集的測(cè)試部分,與背景噪聲混在一起。要運(yùn)行該文件,請(qǐng)使用:
bazel run tensorflow/examples/speech_commands:generate_streaming_test_wav
該命令會(huì)將 .wav 文件保存到/tmp/speech_commands_train/streaming_test.wav,并將列出標(biāo)簽的文本文件保存到/tmp/speech_commands_train/streaming_test_labels.txt。然后,您可以通過以下命令運(yùn)行準(zhǔn)確率測(cè)試:
bazel run tensorflow/examples/speech_commands:test_streaming_accuracy -- --graph=/tmp/my_frozen_graph.pb --labels=/tmp/speech_commands_train/conv_labels.txt --wav=/tmp/speech_commands_train/streaming_test.wav --ground_truth=/tmp/speech_commands_train/streaming_test_labels.txt --verbose
該命令會(huì)輸出以下信息:字詞與標(biāo)簽匹配正確的字詞數(shù)量、預(yù)測(cè)為錯(cuò)誤標(biāo)簽的字詞數(shù)量,以及沒有實(shí)際語音內(nèi)容時(shí)觸發(fā)模型的次數(shù)。有多種參數(shù)可以控制平均信號(hào)操作的行為,其中包括--average_window_ms(設(shè)置計(jì)算結(jié)果平均值的時(shí)長(zhǎng))、--clip_stride_ms(表示應(yīng)用模型的間隔時(shí)間)、--suppression_ms(在發(fā)現(xiàn)第一個(gè)字詞后的一段時(shí)間內(nèi)阻止觸發(fā)后續(xù)字詞檢測(cè)),以及--detection_threshold(控制平均得分必須達(dá)到多少才可被視為穩(wěn)定結(jié)果)。
您將看到流式準(zhǔn)確率輸出 3 個(gè)數(shù)字,而不僅僅是訓(xùn)練中使用的一個(gè)指標(biāo)。這是因?yàn)椴煌膽?yīng)用具有不同的要求,其中一些應(yīng)用可以容忍頻繁的錯(cuò)誤結(jié)果,只要找到了實(shí)際字詞(較高的召回率)就行;還有一些應(yīng)用非常注重確保預(yù)測(cè)出的標(biāo)簽很有可能正確,即便未檢測(cè)到一些字詞(較高的精確率)。您可以根據(jù)該工具提供的數(shù)字了解模型在應(yīng)用中的效果,還可以嘗試調(diào)整信號(hào)平均參數(shù)來調(diào)整模型,以獲得所需的效果。要了解適用于您應(yīng)用的參數(shù),您可以查看生成的ROC 曲線來權(quán)衡利弊。
RecognizeCommands
流式準(zhǔn)確率工具使用一個(gè)簡(jiǎn)單的解碼器,該解碼器包含在名為RecognizeCommands的小型 C++ 類中。該類會(huì)獲得在一段時(shí)間內(nèi)運(yùn)行 TensorFlow 模型的輸出,然后計(jì)算信號(hào)的平均值,并在有充分證據(jù)表明已發(fā)現(xiàn)可識(shí)別的字詞時(shí)返回有關(guān)標(biāo)簽的信息。這個(gè)實(shí)現(xiàn)的規(guī)模很小,只需跟蹤最后幾條預(yù)測(cè)并計(jì)算平均值即可,因此可根據(jù)需要輕松移植到其他平臺(tái)和語言。例如,在 Android 上可以通過 Java 很方便地執(zhí)行相似的操作,或者在樹莓派上使用 Python 執(zhí)行相似的操作。只要這些實(shí)現(xiàn)采用相同的邏輯,您就可以使用流式測(cè)試工具調(diào)整控制計(jì)算平均值的參數(shù),然后將這些參數(shù)轉(zhuǎn)到應(yīng)用中以獲取類似的結(jié)果。
高級(jí)訓(xùn)練
訓(xùn)練腳本的默認(rèn)設(shè)置旨在在一個(gè)相對(duì)較小的文件中生成良好的端到端結(jié)果,但您可以根據(jù)自己的要求更改多個(gè)選項(xiàng)以自定義結(jié)果。
自定義訓(xùn)練數(shù)據(jù)
默認(rèn)情況下,腳本將下載Speech Commands 數(shù)據(jù)集,但您也可提供自己的訓(xùn)練數(shù)據(jù)。要使用您自己的數(shù)據(jù)進(jìn)行訓(xùn)練,您應(yīng)確保您要識(shí)別的每個(gè)聲音至少有幾百條錄音,并按照類別將它們整理到文件夾中。例如,如果您嘗試讓模型區(qū)分狗吠聲和貓叫聲,則需要?jiǎng)?chuàng)建一個(gè)名為animal_sounds的根文件夾,然后在該文件夾下創(chuàng)建兩個(gè)分別名為bark和miaow的子文件夾。然后,將音頻文件整理到相應(yīng)文件夾中。
要將腳本指向新的音頻文件,您需要設(shè)置--data_url=以阻止 Speech Commands 數(shù)據(jù)集的下載,并設(shè)置--data_dir=/your/data/folder/以查找您剛剛創(chuàng)建的文件。
這些文件本身應(yīng)是 16 位有小端字節(jié)序且采用 PCM 編碼的 WAVE 格式。采樣率默認(rèn)為 16000,但是可以使用--sample_rate參數(shù)更改采樣率,只要所有音頻始終保持相同的采用率(腳本不支持重新采樣)即可。音頻片段也應(yīng)保持大致相同的時(shí)長(zhǎng)。默認(rèn)預(yù)期時(shí)長(zhǎng)為 1 秒,但您可以使用--clip_duration_ms標(biāo)記設(shè)置時(shí)長(zhǎng)。如果音頻片段在開頭的無聲時(shí)長(zhǎng)不同,則可以考慮使用字詞對(duì)齊工具標(biāo)準(zhǔn)化這些音頻片段。
需要注意一個(gè)問題,數(shù)據(jù)集中可能存在相同聲音的非常類似的重復(fù),如果這些重復(fù)分布在訓(xùn)練集、驗(yàn)證集和測(cè)試集中,可能會(huì)產(chǎn)生誤導(dǎo)性指標(biāo)。例如,Speech Commands 集合讓人們多次重復(fù)相同的字詞。這些重復(fù)的語音之間可能會(huì)非常相似,如果訓(xùn)練出現(xiàn)過擬合并記住其中一個(gè),則模型在測(cè)試集中發(fā)現(xiàn)非常類似的副本時(shí)會(huì)給出過好的預(yù)測(cè)。為了避免這種風(fēng)險(xiǎn),Speech Commands 努力確保將同一人發(fā)出的相同字詞的多個(gè)音頻片段放入同一數(shù)據(jù)集中。音頻片段根據(jù)其文件名的哈希值分配到訓(xùn)練集、測(cè)試集或驗(yàn)證集中,這樣一來,即使添加新的音頻片段,也能確保分配是穩(wěn)定的,并避免訓(xùn)練樣本轉(zhuǎn)移到其他集合。為了確保同一位指定發(fā)聲人的所有字詞語音都位于同一數(shù)據(jù)集中,哈希函數(shù)在計(jì)算分配時(shí)會(huì)忽略文件名中 “nohash” 之后的所有內(nèi)容。這意味著如果您有pete_nohash_0.wav和pete_nohash_1.wav這樣的文件名,則它們肯定位于同一集合中。
未知類別
應(yīng)用可能會(huì)聽到訓(xùn)練集之外的聲音,并且您希望模型表明它無法識(shí)別這些情況下的噪聲。為了幫助網(wǎng)絡(luò)學(xué)習(xí)要忽略哪些聲音,您需要提供一些不屬于任何類別的音頻片段。為此,您需要?jiǎng)?chuàng)建quack、oink和moo子文件夾,并使用用戶可能會(huì)聽到的其他動(dòng)物的噪聲填充這些子文件夾。在訓(xùn)練期間,腳本的--wanted_words參數(shù)定義您關(guān)注的類別,子文件夾名稱中提到的所有其他類別用于填充_unknown_類別。Speech Commands 數(shù)據(jù)集中的未知類別下有 20 個(gè)字詞,包括 0 到 9 之間的數(shù)字和隨機(jī)姓名(如 “Sheila”)。
默認(rèn)情況下,從未知類別中挑選 10% 的訓(xùn)練樣本,但您可以使用--unknown_percentage標(biāo)記控制該比例。如果提高該比例,模型將未知字詞誤識(shí)別為所需字詞的可能性就會(huì)降低,但如果該比例過高,則可能會(huì)適得其反,因?yàn)槟P涂赡苷J(rèn)為將所有字詞都?xì)w類為未知字詞是最安全的做法!
背景噪聲
即使環(huán)境中出現(xiàn)其他不相關(guān)的聲音,實(shí)際應(yīng)用也必須識(shí)別音頻。為了構(gòu)建一個(gè)可以穩(wěn)健應(yīng)對(duì)此類干擾的模型,我們需要使用具有類似特性的已錄制音頻進(jìn)行訓(xùn)練。Speech Commands 數(shù)據(jù)集中的文件是由用戶使用各種設(shè)備在多種不同的環(huán)境(而不是在錄音室)中錄制的,因此有助于提高訓(xùn)練的真實(shí)性。為了更加真實(shí),您可以將環(huán)境音頻的隨機(jī)片段混合到訓(xùn)練輸入中。Speech Commands 集合中有一個(gè)名為_background_noise_的特殊文件夾,其中包含時(shí)長(zhǎng) 1 分鐘的 WAVE 文件,內(nèi)容為白噪音以及機(jī)械和日常家庭活動(dòng)的錄音。
這些文件的小片段是隨機(jī)選擇的,并在訓(xùn)練期間以較低的音量混合到音頻片段中。音量也是隨機(jī)選擇的,并由--background_volume參數(shù)按比例進(jìn)行控制,其中 0 表示無聲,1 表示最大音量。并非所有音頻片段中都加入背景噪聲,因此--background_frequency標(biāo)記控制混入噪聲的比例。
您自己的應(yīng)用在其自身環(huán)境中運(yùn)行所用的背景噪聲模式可能與默認(rèn)模式不同,因此您可以在_background_noise_文件夾中提供自己的音頻片段。這些音頻片段的采樣率應(yīng)與主數(shù)據(jù)集相同,但時(shí)長(zhǎng)應(yīng)該長(zhǎng)很多,以便可以從中選擇一組效果良好的隨機(jī)片段。
無聲
在大多數(shù)情況下,您關(guān)注的聲音都是斷斷續(xù)續(xù)的,因此務(wù)必要清楚何時(shí)沒有匹配的音頻。為此,可以使用一個(gè)特殊的_silence_標(biāo)簽,表明模型何時(shí)未檢測(cè)到任何值得關(guān)注的內(nèi)容。由于真實(shí)環(huán)境中并不存在絕對(duì)的無聲情況,因此我們實(shí)際上必須提供安靜且不相關(guān)的音頻樣本。為此,我們重復(fù)使用也混入到實(shí)際音頻片段中的_background_noise_文件夾,提取音頻數(shù)據(jù)的簡(jiǎn)短片段,并饋送這些片段(包含實(shí)際類別標(biāo)簽_silence_)。默認(rèn)情況下,10% 的訓(xùn)練數(shù)據(jù)是按照這種方法提供的,但可以使用--silence_percentage控制該比例。與未知字詞一樣,如果提高該比例,則模型給出的結(jié)果可能傾向于無聲的真正例,代價(jià)是字詞出現(xiàn)假負(fù)例;但如果該比例過高,則可能導(dǎo)致模型陷入始終猜測(cè)無聲的陷阱。
時(shí)移
為了符合實(shí)際地扭曲訓(xùn)練數(shù)據(jù)以有效增加數(shù)據(jù)集的大小,進(jìn)而提高整體準(zhǔn)確率,一種方式是添加背景噪聲,而另一種方式是時(shí)移。這涉及到訓(xùn)練樣本數(shù)據(jù)在時(shí)間方面的隨機(jī)偏移,以便截去開頭或結(jié)尾的一小部分,而另一部分則用零填充。這模擬了訓(xùn)練數(shù)據(jù)開始時(shí)間的自然變化,并由--time_shift_ms標(biāo)記控制,默認(rèn)為 100 毫秒。提高該值將提供更多變化,但可能會(huì)截去音頻的重要部分。一種通過真實(shí)扭曲來增強(qiáng)數(shù)據(jù)的相關(guān)方法是使用時(shí)間伸縮和音調(diào)縮放,但這不在本教程的討論范圍之內(nèi)。
自定義模型
用于該腳本的默認(rèn)模型非常大,每次推理需要使用超過 8 億 FLOP,并需要使用 940000 個(gè)權(quán)重參數(shù)。該模型在臺(tái)式機(jī)或新型手機(jī)上可以快速運(yùn)行,但要在資源更有限的設(shè)備上快速運(yùn)行,則涉及到太多計(jì)算。為了支持這些用例,可以采用幾個(gè)替代方法:
low_latency_conv基于Neural Networks for Small-footprint Keyword Spotting(小型關(guān)鍵字檢測(cè)卷積神經(jīng)網(wǎng)絡(luò))這篇論文中介紹的 “cnn-one-fstride4” 拓?fù)洹?zhǔn)確率略低于卷積神經(jīng)網(wǎng)絡(luò),但權(quán)重參數(shù)的數(shù)量大致相同,但運(yùn)行一次預(yù)測(cè)只需要 1100 萬 FLOP,提高了模型的運(yùn)行速度。
要使用該模型,請(qǐng)?jiān)诿钚猩现付?-model_architecture=low_latency_conv。您還需要更新訓(xùn)練速率和訓(xùn)練步數(shù),因此完整命令如下所示:
python tensorflow/examples/speech_commands/train --model_architecture=low_latency_conv --how_many_training_steps=20000,6000 --learning_rate=0.01,0.001
該命令要求腳本以 0.01 的學(xué)習(xí)速率訓(xùn)練 20000 個(gè)訓(xùn)練步,然后進(jìn)行微調(diào),以原來速率的十分之一完成 6000 個(gè)訓(xùn)練步。
low_latency_svdf基于Compressing Deep Neural Networks using a Rank-Constrained Topology paper(利用秩受限的拓?fù)鋲嚎s深度神經(jīng)網(wǎng)絡(luò))這篇論文中介紹的拓?fù)洹?zhǔn)確率也低于卷積神經(jīng)網(wǎng)絡(luò),但只使用大約 750000 個(gè)參數(shù),最重要的是,它允許在測(cè)試時(shí)(即您在應(yīng)用中實(shí)際用到時(shí))優(yōu)化執(zhí)行,并且需要 750000 個(gè) FLOP。
要使用該模型,請(qǐng)?jiān)诿钚猩现付?-model_architecture=low_latency_svdf,并更新訓(xùn)練速率和訓(xùn)練步數(shù),因此完整命令如下所示:
python tensorflow/examples/speech_commands/train --model_architecture=low_latency_svdf --how_many_training_steps=100000,35000 --learning_rate=0.01,0.005
請(qǐng)注意,盡管所需的訓(xùn)練步數(shù)多于前兩個(gè)拓?fù)洌?jì)算數(shù)量減少意味著訓(xùn)練花費(fèi)的時(shí)間應(yīng)大致相同,并且最終得出的準(zhǔn)確率大約為 85%。此外,您還可以通過在 SVDF 層中更改以下參數(shù)輕松地進(jìn)一步調(diào)整拓?fù)洌员銓?shí)現(xiàn)所需的計(jì)算量和準(zhǔn)確率。
rank - 近似秩(通常越高越好,但會(huì)導(dǎo)致更多計(jì)算)。
num_units - 類似于其他層類型,指定層中的節(jié)點(diǎn)數(shù)(節(jié)點(diǎn)越多,效果越好,計(jì)算量也會(huì)更多)。
對(duì)于運(yùn)行時(shí),由于層允許通過緩存某些內(nèi)部神經(jīng)網(wǎng)絡(luò)激活進(jìn)行優(yōu)化,因此您需要確保在凍結(jié)圖和在流式模式(例如 test_streaming_accuracy.cc)下執(zhí)行模型時(shí)使用一致的步長(zhǎng)(例如 clip_stride_ms 標(biāo)記)。
自定義其他參數(shù)
如果您想嘗試自定義模型,最好先從調(diào)整聲譜圖創(chuàng)建參數(shù)開始。這可能會(huì)更改模型的輸入圖像的大小,并且models.py中的創(chuàng)建代碼會(huì)自動(dòng)調(diào)整計(jì)算和權(quán)重的數(shù)量(https://www.tensorflowers.cn/t/7516),以適應(yīng)不同維度。如果您縮小輸入圖像的大小,則模型將需要更少的計(jì)算來處理輸入,這樣做可以很好地改善延遲情況,但會(huì)降低準(zhǔn)確率。--window_stride_ms控制每個(gè)頻率分析樣本與前一個(gè)之間相隔的時(shí)間。如果增加該值,則指定時(shí)長(zhǎng)內(nèi)的樣本就會(huì)變少,輸入的時(shí)間軸也會(huì)變短。--dct_coefficient_count標(biāo)記控制用于頻率計(jì)算的分桶數(shù)量,因此降低該值會(huì)減少其他維度中的輸入。--window_size_ms參數(shù)不會(huì)影響大小,但會(huì)控制每個(gè)樣本用于計(jì)算頻率的區(qū)域?qū)挾取H绻獙ふ业穆曇魰r(shí)長(zhǎng)很短,則縮短訓(xùn)練樣本的時(shí)長(zhǎng)(由--clip_duration_ms控制)也會(huì)有所幫助,因?yàn)檫@樣也會(huì)縮短輸入的時(shí)間維度。不過,您需要確保所有訓(xùn)練數(shù)據(jù)都在音頻片段的初始部分包含正確的音頻。
如果您想到了一個(gè)可以解決問題的完全不同模型,您可以將其插入models.py中,并讓腳本的剩余部分處理所有預(yù)處理和訓(xùn)練工作。您可以向create_model添加一個(gè)新子句,查找該模型架構(gòu)的名稱,然后調(diào)用模型創(chuàng)建函數(shù)。該函數(shù)獲得聲譜圖輸入的大小以及其他模型信息,并且會(huì)創(chuàng)建 TensorFlow 操作來讀取這些信息,同時(shí)生成輸出預(yù)測(cè)向量和控制丟棄率的占位符。腳本的剩余部分負(fù)責(zé)將該模型集成到更大的圖中,該圖會(huì)執(zhí)行輸入計(jì)算,并應(yīng)用 softmax 和損失函數(shù)來訓(xùn)練模型。
在調(diào)整模型和訓(xùn)練超參數(shù)時(shí)會(huì)遇到的一個(gè)常見問題是,可能會(huì)引入非數(shù)字值,這是由數(shù)值精確問題所致。通常,解決此問題的方式是減小學(xué)習(xí)速率等數(shù)值的大小并減少權(quán)重初始化函數(shù),但如果問題仍然存在,則可以啟用--check_nans標(biāo)記來跟蹤錯(cuò)誤的來源。啟用該標(biāo)記后,系統(tǒng)會(huì)在 TensorFlow 中的大部分常規(guī)操作之間插入檢查操作,而且會(huì)在遇到這些錯(cuò)誤時(shí)中止訓(xùn)練過程并顯示實(shí)用的錯(cuò)誤消息。
-
語音識(shí)別
+關(guān)注
關(guān)注
39文章
1774瀏覽量
114010
原文標(biāo)題:簡(jiǎn)單的音頻識(shí)別
文章出處:【微信號(hào):tensorflowers,微信公眾號(hào):Tensorflowers】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
設(shè)計(jì)一個(gè)語音識(shí)別的模塊
自動(dòng)語音識(shí)別的原理是什么?
基于語音識(shí)別做一款能識(shí)別語音的App
一個(gè)基于語音識(shí)別的盲人上網(wǎng)輔助系統(tǒng)的設(shè)計(jì)
語音識(shí)別的應(yīng)用場(chǎng)景
語音識(shí)別的技術(shù)歷程
語音識(shí)別的兩個(gè)方法_語音識(shí)別的應(yīng)用有哪些
情感語音識(shí)別的前世今生
情感語音識(shí)別的研究方法與實(shí)踐
情感語音識(shí)別的應(yīng)用與挑戰(zhàn)
情感語音識(shí)別的挑戰(zhàn)與未來趨勢(shì)
語音識(shí)別的技術(shù)歷程及工作原理





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論