") 深入探討深度學(xué)習(xí),尤其是非常擅長(zhǎng)與理解圖像的深度卷積神經(jīng)網(wǎng)絡(luò)
深入探討深度學(xué)習(xí),尤其是非常擅長(zhǎng)與理解圖像的深度卷積神經(jīng)網(wǎng)絡(luò)

AlexNet發(fā)表的2012年是具有里程碑意義的一年,自那以后,計(jì)算機(jī)視覺領(lǐng)域的所有突破幾乎都來自深度神經(jīng)網(wǎng)絡(luò)。本文深入探討了深度學(xué)習(xí),尤其是非常擅長(zhǎng)與理解圖像的深度卷積神經(jīng)網(wǎng)絡(luò)。
現(xiàn)在,我打開Google Photos,輸入“海灘”,就能查看我過去10年里去過的所有海灘的照片。我從來沒有瀏覽過我的照片,也沒有一張張給它們貼標(biāo)簽;相反,谷歌是根據(jù)照片本身的內(nèi)容來識(shí)別海灘的。
這個(gè)看似平凡的功能是基于一種叫做深度卷積神經(jīng)網(wǎng)絡(luò)的技術(shù),該技術(shù)允許軟件以一種以前的技術(shù)無法實(shí)現(xiàn)的方式理解圖像。
近年來,研究人員發(fā)現(xiàn),隨著他們構(gòu)建的網(wǎng)絡(luò)層數(shù)越深,積累了越大的數(shù)據(jù)集來訓(xùn)練軟件,軟件的準(zhǔn)確性就越高。這使得軟件對(duì)計(jì)算能力產(chǎn)生了幾乎無法滿足的需求,從而提振了英偉達(dá)和AMD等GPU廠商的財(cái)富。谷歌在幾年前開發(fā)了自己的定制神經(jīng)網(wǎng)絡(luò)芯片,其他公司也爭(zhēng)相效仿谷歌的做法。
以特斯拉為例,特斯拉聘請(qǐng)了深度學(xué)習(xí)專家Andrej Karpathy負(fù)責(zé)其自動(dòng)駕駛系統(tǒng)Autopilot項(xiàng)目。特斯拉目前正在開發(fā)一種定制芯片,為未來版本Autopilot的神經(jīng)網(wǎng)絡(luò)操作提供加速。
又或,以蘋果公司為例:最近幾款iphone的核心芯片A11和A12都包含一個(gè)“神經(jīng)引擎”,用來加速神經(jīng)網(wǎng)絡(luò)操作,并支持更好的圖像和語音識(shí)別應(yīng)用程序。
我為這篇文章采訪過的幾位專家都將當(dāng)前的深度學(xué)習(xí)熱潮追溯到一篇特定的論文:AlexNet,名字來自它的主要作者AlexKrizhevsky。
“在我看來,AlexNet發(fā)表的2012年是具有里程碑意義的一年,”機(jī)器學(xué)習(xí)專家、《智能機(jī)器如何思考》(How Smart Machines Think)一書的作者Sean Gerrish說。
在2012年之前,深度神經(jīng)網(wǎng)絡(luò)在機(jī)器學(xué)習(xí)領(lǐng)域幾乎是一潭死水。但后來,Krizhevsky和他在多倫多大學(xué)的同事們?cè)谝豁?xiàng)備受矚目的圖像識(shí)別競(jìng)賽提交了參賽作品,并取得了比以往任何成績(jī)都要精確得多的成果。幾乎一夜之間,深度神經(jīng)網(wǎng)絡(luò)成為圖像識(shí)別的主要技術(shù)。其他使用該技術(shù)的研究人員很快證明了圖像識(shí)別精度的進(jìn)一步飛躍。
在這篇文章中,我們將深入探討深度學(xué)習(xí)。我將解釋什么是神經(jīng)網(wǎng)絡(luò),它們是如何被訓(xùn)練的,以及為什么它們需要如此多的計(jì)算能力。然后我將解釋為什么一種特殊類型的神經(jīng)網(wǎng)絡(luò)——深度卷積網(wǎng)絡(luò)——在理解圖像方面非常擅長(zhǎng)。
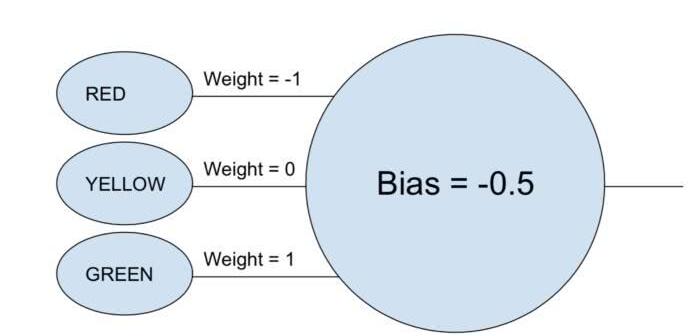
一個(gè)單神經(jīng)元的例子
“神經(jīng)網(wǎng)絡(luò)”(neural network)這個(gè)短語可能仍讓人感覺有點(diǎn)模糊,所以讓我們從一個(gè)簡(jiǎn)單的例子開始吧。假設(shè)你想用一個(gè)神經(jīng)網(wǎng)絡(luò),根據(jù)紅燈、黃燈和綠燈來決定一輛車是否通行。神經(jīng)網(wǎng)絡(luò)用單個(gè)神經(jīng)元就可以完成這項(xiàng)任務(wù)。

神經(jīng)元接受每個(gè)輸入(1表示打開,0表示關(guān)閉),將其乘以相關(guān)的權(quán)重(weight),并將所有權(quán)重值相加。然后,神經(jīng)元添加偏差(bias),該偏差確定神經(jīng)元“激活”的閾值。在這個(gè)例子中,如果輸出是正的,我們就認(rèn)為神經(jīng)元已經(jīng)被“激活”了——否則就認(rèn)為神經(jīng)元沒有被激活。這個(gè)神經(jīng)元相當(dāng)于不等式“green - red - 0.5 > 0”。如果評(píng)估結(jié)果為真,即意味著綠燈亮,紅燈關(guān),那么車應(yīng)該通行。
在真實(shí)的神經(jīng)網(wǎng)絡(luò)中,人工神經(jīng)元需要多走了一步。將加權(quán)輸入相加并加入偏差后,神經(jīng)元再應(yīng)用非線性激活函數(shù)。一個(gè)流行的選擇是sigmoid函數(shù),它是一個(gè)s形函數(shù),總是產(chǎn)生0到1之間的值。
激活函數(shù)的使用不會(huì)改變我們這個(gè)簡(jiǎn)單的紅綠燈模型的結(jié)果(除了閾值需要是0.5而不是0),但激活函數(shù)的非線性對(duì)于使神經(jīng)網(wǎng)絡(luò)能夠建模更復(fù)雜的函數(shù)是必不可少的。如果沒有激活函數(shù),每一個(gè)神經(jīng)網(wǎng)絡(luò),不管多么復(fù)雜,都可以簡(jiǎn)化成其輸入的線性組合。線性函數(shù)不能模擬復(fù)雜的現(xiàn)實(shí)世界現(xiàn)象。非線性激活函數(shù)使神經(jīng)網(wǎng)絡(luò)能夠近似任何數(shù)學(xué)函數(shù)。
一個(gè)簡(jiǎn)單的示例網(wǎng)絡(luò)
當(dāng)然,有很多方法可以近似函數(shù)。神經(jīng)網(wǎng)絡(luò)的特別之處在于,我們知道如何用一些微積分、一堆數(shù)據(jù)和大量的計(jì)算能力來“訓(xùn)練”它們。我們可以構(gòu)建以一個(gè)通用神經(jīng)網(wǎng)絡(luò)為基礎(chǔ)的軟件,讓它查看大量的標(biāo)記示例,然后修改神經(jīng)網(wǎng)絡(luò),使其為盡可能多的有標(biāo)記樣本產(chǎn)生正確的標(biāo)簽,而不是讓人類程序員直接為特定任務(wù)設(shè)計(jì)一個(gè)神經(jīng)網(wǎng)絡(luò)。我們的目標(biāo)是使得到的網(wǎng)絡(luò)能夠推廣(generalize),為先前不在訓(xùn)練數(shù)據(jù)集中的樣本生成正確的標(biāo)簽。
早在AlexNet之前研究人員就開始試圖實(shí)現(xiàn)這一點(diǎn)了。1986年,三位研究人員David Rumelhart, Geoffrey Hinton 和 Ronald Williams發(fā)表了一篇關(guān)于反向傳播的里程碑式的論文。反向傳播是一種有助于使訓(xùn)練復(fù)雜神經(jīng)網(wǎng)絡(luò)在數(shù)學(xué)上變得容易操作的技術(shù)。
為了直觀了解反向傳播是如何工作的,讓我們來看看Michael Nielsen在他的在線深度學(xué)習(xí)課本中描述的一個(gè)簡(jiǎn)單神經(jīng)網(wǎng)絡(luò)。這個(gè)網(wǎng)絡(luò)的目標(biāo)是以代表一個(gè)手寫數(shù)字的28×28像素的圖像作為輸入,并且正確地識(shí)別這個(gè)數(shù)字是什么。
每個(gè)圖像都有28個(gè)×28 = 784個(gè)輸入值,每個(gè)輸入值都是0和1之間的實(shí)數(shù),表示像素的亮度或暗度。Nielsen構(gòu)建了這樣一個(gè)神經(jīng)網(wǎng)絡(luò):
在這張圖中,中間和右邊的每一個(gè)圓都是一個(gè)神經(jīng)元。每個(gè)神經(jīng)元對(duì)其輸入進(jìn)行加權(quán)平均,添加一個(gè)偏差值,然后應(yīng)用一個(gè)激活函數(shù)。注意左邊的圓圈不是神經(jīng)元——這些圓圈代表網(wǎng)絡(luò)的輸入值。雖然圖像只顯示了8個(gè)輸入圓,但實(shí)際上有784個(gè)輸入——每個(gè)輸入對(duì)應(yīng)輸入圖像的一個(gè)像素。
右邊的10個(gè)神經(jīng)元分別應(yīng)該為不同的數(shù)字“點(diǎn)亮”:當(dāng)輸入是手寫數(shù)字0時(shí),頂部的神經(jīng)元應(yīng)該被觸發(fā);當(dāng)輸入是手寫數(shù)字1時(shí),第二個(gè)神經(jīng)元應(yīng)該被觸發(fā);如此類推。
每個(gè)神經(jīng)元從它前面一層的每個(gè)神經(jīng)元接受輸入。因此,中間這15個(gè)神經(jīng)元的每一個(gè)都有784個(gè)輸入值。這15個(gè)神經(jīng)元中的每一個(gè)都有一個(gè)權(quán)重參數(shù),對(duì)應(yīng)于它的784個(gè)輸入。這意味著這一層單獨(dú)就有15×784 = 11760個(gè)權(quán)重參數(shù)。同樣,輸出層包含10個(gè)神經(jīng)元,每一個(gè)都從中間層的15個(gè)神經(jīng)元獲得輸入,并添加另外15×10 = 150個(gè)權(quán)重參數(shù)。除此之外,這個(gè)網(wǎng)絡(luò)還有25個(gè)偏差變量——每個(gè)偏差變量分別對(duì)應(yīng)25個(gè)神經(jīng)元中的每一個(gè)。
訓(xùn)練神經(jīng)網(wǎng)絡(luò)
訓(xùn)練的目標(biāo)是優(yōu)化這11935個(gè)參數(shù),以最大限度地提高正確的輸出神經(jīng)元——并且只有那個(gè)輸出神經(jīng)元——在顯示一個(gè)手寫數(shù)字圖像時(shí)亮起來的機(jī)會(huì)。我們可以用一個(gè)名為MNIST的著名數(shù)據(jù)集來完成此操作,該數(shù)據(jù)集提供60000張有標(biāo)記的28×28像素圖像:

這里顯示了MNIST數(shù)據(jù)集中的160個(gè)圖像
Nielsen展示了如何使用74行Python代碼來訓(xùn)練這個(gè)網(wǎng)絡(luò)——不需要特殊的機(jī)器學(xué)習(xí)庫。訓(xùn)練從為11935個(gè)權(quán)重和偏差參數(shù)中的每一個(gè)選擇隨機(jī)值開始。然后,軟件會(huì)瀏覽示例圖像,為每一個(gè)圖像完成以下兩個(gè)步驟的操作:
前饋步驟:在給定輸入圖像和網(wǎng)絡(luò)的當(dāng)前參數(shù)的條件下,計(jì)算網(wǎng)絡(luò)的輸出值。
反向傳播步驟:計(jì)算結(jié)果與正確的輸出值偏離多少,然后修改網(wǎng)絡(luò)參數(shù),以略微改進(jìn)其在特定輸入圖像上的性能。
這是一個(gè)示例。假設(shè)網(wǎng)絡(luò)顯示下面這張圖:
如果網(wǎng)絡(luò)校準(zhǔn)良好,那么網(wǎng)絡(luò)的“7”輸出應(yīng)該接近1,而網(wǎng)絡(luò)的其他9個(gè)輸出應(yīng)該都接近0。但是,假設(shè)在顯示這個(gè)圖像時(shí),網(wǎng)絡(luò)的“0”的輸出為0.8。這就太高了!訓(xùn)練算法將改變“0”輸出神經(jīng)元的輸入權(quán)重,使其在下次顯示這張圖像時(shí)更接近于0。
為此,反向傳播算法為每個(gè)輸入權(quán)重參數(shù)計(jì)算一個(gè)誤差梯度(error gradient)。這是一種測(cè)量在輸入權(quán)重發(fā)生給定變化時(shí),輸出誤差會(huì)發(fā)生多大變化的方法。然后,算法使用這個(gè)梯度來決定每個(gè)輸入權(quán)重的變化量——梯度越大,參數(shù)的變化就越大。
換句話說,這個(gè)訓(xùn)練過程“教導(dǎo)”輸出層的神經(jīng)元減少對(duì)會(huì)將它們推向錯(cuò)誤答案的輸入(即中間層的神經(jīng)元)的注意力,而將注意力更多地放在將它們推向正確方向的輸入。
該算法對(duì)其他每個(gè)輸出神經(jīng)元重復(fù)這一步驟。它減少“1”、“2”、“3”、“4”、“5”、“6”、“8”和“9”神經(jīng)元(而不是“7”神經(jīng)元)輸入的權(quán)重,從而將這些輸出神經(jīng)元的值向下推。輸入的值越高,輸出誤差相對(duì)于該輸入的權(quán)重參數(shù)的梯度越大——因此它的權(quán)重會(huì)減少得越多。
相反,訓(xùn)練算法增加了導(dǎo)致“7”輸出的輸入權(quán)重,這將導(dǎo)致該神經(jīng)元在下一次顯示這張?zhí)囟▓D像時(shí)產(chǎn)生更高的值。同樣的,輸入值越大,其權(quán)重的增加也越大,使得“7”輸出神經(jīng)元在以后的幾輪中會(huì)更加注意這些輸入。
接下來,算法需要對(duì)中間層執(zhí)行相同的計(jì)算:將每個(gè)輸入權(quán)重改變到可以減少網(wǎng)絡(luò)錯(cuò)誤的方向——同樣,使“7”輸出更接近于1,其他輸出更接近于0。但是每個(gè)中間神經(jīng)元都是輸出層所有10個(gè)神經(jīng)元的輸入,這使得事情在兩個(gè)方面復(fù)雜化了。
首先,任何給定中間層輸入的誤差梯度不僅取決于該輸入值,而且還取決于下一層的誤差梯度。該算法被稱為反向傳播算法,因?yàn)閬碜跃W(wǎng)絡(luò)中較后一層的誤差梯度是向后傳播的,并且用于計(jì)算前一層的梯度。
此外,每個(gè)中間層神經(jīng)元都是輸出層中所有10個(gè)神經(jīng)元的輸入。因此,訓(xùn)練算法必須計(jì)算一個(gè)誤差梯度,以反映特定輸入權(quán)重的變化如何影響所有輸出的平均誤差。
反向傳播是一種爬山算法:每一輪算法都會(huì)使輸出結(jié)果更接近訓(xùn)練圖像的正確結(jié)果——但只會(huì)接近一點(diǎn)點(diǎn)。隨著算法得到越來越多的樣本,它會(huì)“爬坡”到一組最優(yōu)參數(shù),這組參數(shù)能夠正確分類盡可能多的訓(xùn)練樣本。要達(dá)到較高的精度,需要成千上萬的訓(xùn)練樣本,算法可能需要對(duì)訓(xùn)練集中的每幅圖像進(jìn)行幾十次循環(huán)遍歷,才能達(dá)到性能的最高點(diǎn)。
Nielsen展示了如何用74行Python代碼實(shí)現(xiàn)所有這些。值得注意的是,使用這個(gè)簡(jiǎn)單程序訓(xùn)練的神經(jīng)網(wǎng)絡(luò)能夠識(shí)別MNIST數(shù)據(jù)庫中95%以上的手寫數(shù)字。通過一些額外的改進(jìn),像這樣一個(gè)簡(jiǎn)單的兩層神經(jīng)網(wǎng)絡(luò)能夠識(shí)別98%以上的數(shù)字。
AlexNet帶來的突破
你可能認(rèn)為上世紀(jì)80年代反向傳播的發(fā)展會(huì)開啟基于神經(jīng)網(wǎng)絡(luò)的機(jī)器學(xué)習(xí)的快速進(jìn)步時(shí)期,但事實(shí)并非如此。當(dāng)然,在20世紀(jì)90年代和21世紀(jì)初就有人致力于這項(xiàng)技術(shù)。但對(duì)神經(jīng)網(wǎng)絡(luò)的興趣直到2010年初才真正興起。
我們可以從ImageNet競(jìng)賽的結(jié)果中看出這一點(diǎn)。ImageNet競(jìng)賽是由斯坦福大學(xué)計(jì)算機(jī)科學(xué)家李飛飛組織的年度機(jī)器學(xué)習(xí)競(jìng)賽。在每年的比賽中,參賽者都會(huì)得到超過一百萬張圖像的訓(xùn)練數(shù)據(jù)集,每張圖像都被手工標(biāo)記一個(gè)標(biāo)簽,標(biāo)簽有大約1000種類別,比如“消防車”、“蘑菇”或“獵豹”。參賽者的軟件根據(jù)其對(duì)未被包含在訓(xùn)練集的其他圖像進(jìn)行分類的能力進(jìn)行評(píng)判。程序可以進(jìn)行多次猜測(cè),如果前五次猜測(cè)中有一次與人類選擇的標(biāo)簽相匹配,則被認(rèn)為識(shí)別成功。
這項(xiàng)競(jìng)賽始于2010年,前兩年深度神經(jīng)網(wǎng)絡(luò)并沒有發(fā)揮主要作用。頂級(jí)團(tuán)隊(duì)使用了各種其他的機(jī)器學(xué)習(xí)技術(shù),但結(jié)果相當(dāng)平庸。2010年獲勝的團(tuán)隊(duì)的top-5錯(cuò)誤率高達(dá)28%。2011年,這個(gè)錯(cuò)誤率為25%。
然后是2012年。來自多倫多大學(xué)的一個(gè)團(tuán)隊(duì)提交了參賽作品——即后來以主要作者Alex Krizhevsky命名的AlexNet——擊敗了所有競(jìng)爭(zhēng)者。使用深度神經(jīng)網(wǎng)絡(luò),該團(tuán)隊(duì)得到了16%的top-5錯(cuò)誤率。最接近的競(jìng)爭(zhēng)對(duì)手當(dāng)年的錯(cuò)誤率為26%。
上面討論的手寫識(shí)別網(wǎng)絡(luò)有兩層,25個(gè)神經(jīng)元,以及大約12000個(gè)參數(shù)。AlexNet要大得多,也復(fù)雜得多:8個(gè)可訓(xùn)練的層、650000個(gè)神經(jīng)元,以及6000萬個(gè)參數(shù)。
訓(xùn)練這種規(guī)模的網(wǎng)絡(luò)需要大量的計(jì)算能力,而AlexNet被設(shè)計(jì)利用現(xiàn)代GPU提供的大量并行計(jì)算能力。研究人員想出了如何在兩個(gè)GPU之間分配網(wǎng)絡(luò)訓(xùn)練的工作,從而給了它們兩倍的計(jì)算能力。不過,盡管進(jìn)行了積極的優(yōu)化,在2012年可用的硬件條件下(兩個(gè)Nvidia GTX 580 GPU,每個(gè)3GB內(nèi)存),網(wǎng)絡(luò)訓(xùn)練進(jìn)行了5到6天。
看看AlexNet的結(jié)果對(duì)于理解這是一個(gè)多么厲害的突破是很有幫助的。以下是AlexNet論文中的截圖,展示了一些圖像和AlexNet的top-5分類:
AlexNet能夠識(shí)別出第一張圖片中有一只螨蟲,即使這只螨蟲只是在圖片邊緣的一個(gè)小形狀。AlexNet不僅能正確識(shí)別美洲豹,它的其他top猜測(cè)——美洲虎、獵豹、雪豹和埃及貓——都是長(zhǎng)相相似的貓科動(dòng)物。AlexNet將蘑菇的圖片標(biāo)記為“木耳”——蘑菇的一種。“蘑菇”——官方正確的標(biāo)簽,是AlexNet的第二選擇。
AlexNet的“錯(cuò)誤”幾乎同樣令人印象深刻。照片上,一只斑點(diǎn)狗站在櫻桃后面,AlexNet的猜測(cè)是“斑點(diǎn)狗”,而官方的標(biāo)簽是“櫻桃”。AlexNet意識(shí)到這幅畫中含有某種水果——“葡萄”和“接骨木漿果”是它的前五種選擇——但它并沒有完全認(rèn)識(shí)到它們是櫻桃。在一張馬達(dá)加斯加貓站在樹上的照片中,AlexNet列出了一群會(huì)爬樹的小型哺乳動(dòng)物。很多人(包括我)都可能會(huì)弄錯(cuò)。
這是真正令人印象深刻的性能表現(xiàn),表明軟件可以識(shí)別各種方向和背景中的常見對(duì)象。深度神經(jīng)網(wǎng)絡(luò)迅速成為圖像識(shí)別任務(wù)最受歡迎的技術(shù),此后機(jī)器學(xué)習(xí)領(lǐng)域就再也不回頭看其他技術(shù)了。
“隨著基于深度學(xué)習(xí)的方法在2012年取得成功,2013年的絕大多數(shù)參賽方法都使用了深度卷積神經(jīng)網(wǎng)絡(luò),”ImageNet的贊助商寫道。這種模式在隨后的幾年里持續(xù),后來的獲勝者的技術(shù)建立在AlexNet團(tuán)隊(duì)開創(chuàng)的基本技術(shù)之上。到2017年,使用更深層的神經(jīng)網(wǎng)絡(luò)的參賽者將top-5錯(cuò)誤率降到3%以下。考慮到這項(xiàng)任務(wù)的復(fù)雜性,可以說計(jì)算機(jī)比許多人能更好地完成這項(xiàng)任務(wù)了。

卷積網(wǎng)絡(luò):概念
從技術(shù)上講,AlexNet是一個(gè)卷積神經(jīng)網(wǎng)絡(luò)。在這一節(jié)中,我將解釋卷積網(wǎng)絡(luò)是做什么的,以及為什么這種技術(shù)對(duì)現(xiàn)代圖像識(shí)別算法至關(guān)重要。
我們之前討論的簡(jiǎn)單的手寫識(shí)別網(wǎng)絡(luò)是完全連接的:第一層的每個(gè)神經(jīng)元都是第二層每個(gè)神經(jīng)元的輸入。這種結(jié)構(gòu)足以完成相對(duì)簡(jiǎn)單的識(shí)別28×28像素的數(shù)字的任務(wù)。但它不能很好地?cái)U(kuò)展。
在MNIST手寫數(shù)字?jǐn)?shù)據(jù)集中,字符總是居中的。這大大簡(jiǎn)化了訓(xùn)練,因?yàn)檫@意味著(比如說)“7”這個(gè)數(shù)字在圖像的頂部和右側(cè)總是有一些暗像素,而左下角總是白色的。一個(gè)“0”幾乎總是中間白色,在邊緣有一些較暗的像素。一個(gè)簡(jiǎn)單的、完全連接的網(wǎng)絡(luò)可以相當(dāng)容易地檢測(cè)出這類模式。
但假設(shè)你想構(gòu)建一個(gè)可以識(shí)別出可能位于大圖像中任何位置的數(shù)字的神經(jīng)網(wǎng)絡(luò)。一個(gè)完全連接的網(wǎng)絡(luò)是不能很好地工作的,因?yàn)樗鼪]有一種有效的方法來識(shí)別位于圖像不同部分的形狀之間的相似性。如果你的訓(xùn)練集恰好大多數(shù)“7”都位于左上角,那么你最終會(huì)得到一個(gè)更擅長(zhǎng)識(shí)別左上角的“7”的網(wǎng)絡(luò)。
從理論上講,你可以通過確保你的訓(xùn)練集在每個(gè)可能的像素位置上都有很多每個(gè)數(shù)字的樣本來解決這個(gè)問題。但在實(shí)踐中,這將是巨大的浪費(fèi)。隨著圖像的大小和網(wǎng)絡(luò)深度的增加,連接的數(shù)量——也就是輸入權(quán)重參數(shù)的數(shù)量——將會(huì)激增。你需要更多的訓(xùn)練圖像(更不用說更多的計(jì)算能力)來達(dá)到足夠的準(zhǔn)確性。
當(dāng)神經(jīng)網(wǎng)絡(luò)學(xué)會(huì)識(shí)別圖像中某個(gè)位置的形狀時(shí),它應(yīng)該能夠?qū)⑦@種學(xué)習(xí)應(yīng)用到圖像其他部分的相似形狀識(shí)別中。卷積神經(jīng)網(wǎng)絡(luò)為這一問題提供了一個(gè)優(yōu)雅的解決方案。
所以,想象一下,如果我們把一個(gè)大的圖像分割成28×28像素的方格,然后,我們可以將每個(gè)方格輸入到之前探討的完全連接的手寫識(shí)別網(wǎng)絡(luò)中。如果“7”的輸出在這些方格中至少有一個(gè)亮起,那就表示圖像整體上可能有一個(gè)7。這就是卷積網(wǎng)絡(luò)的本質(zhì)。
卷積網(wǎng)絡(luò)在AlexNet中的重要作用
在卷積網(wǎng)絡(luò)中,這些“模板”被稱為特征檢測(cè)器,它們所看到的區(qū)域稱為感受野。真實(shí)特征探測(cè)器往往具有遠(yuǎn)小于28像素的感知場(chǎng)。在AlexNet中,第一個(gè)卷積層具有特征檢測(cè)器,其感知場(chǎng)是11*11像素。 AlexNet中的后續(xù)卷積層具有三或五個(gè)單位寬的感受域。
當(dāng)特征檢測(cè)器掃過輸入圖像時(shí),它會(huì)生成一個(gè)特征圖:一個(gè)二維網(wǎng)格,指示探測(cè)器被圖像的不同部分激活的強(qiáng)度。卷積層中通常有多個(gè)特征檢測(cè)器,每個(gè)特征檢測(cè)器掃描輸入圖像以獲得不同的圖案。在AlexNet中,第一層有96個(gè)特征探測(cè)器,產(chǎn)生96個(gè)特征圖。

為了使其更具體,這里給出網(wǎng)絡(luò)訓(xùn)練后AlexNet第一層中96個(gè)特征探測(cè)器中每個(gè)探測(cè)器學(xué)習(xí)的視覺模式的直觀表示。探測(cè)器可以定位水平線或垂直線、從淺到深的畫面漸變、棋盤圖案和許多其他形狀。
彩色圖像通常表示為每個(gè)像素?fù)碛腥齻€(gè)數(shù)字屬性的像素圖:分別為紅色值、綠色值和藍(lán)色值。AlexNet的第一層就采用圖像的這種“三數(shù)字”表示,并將其轉(zhuǎn)換為96數(shù)字表示,即圖像中的每個(gè)“像素”具有96個(gè)值,由96個(gè)特征檢測(cè)器一一對(duì)應(yīng)。
在此例中,這96個(gè)值中的第一個(gè)指示圖像中的特定點(diǎn)是否與此模式匹配:
第二個(gè)值指示特定點(diǎn)是否與此模式匹配:
第三個(gè)值指示特定點(diǎn)是否與此模式匹配:
...依舊為AlexNet的第一層中的其他93個(gè)特征檢測(cè)器。第一層輸出圖像的新表示,其中每個(gè)“像素”是96個(gè)數(shù)字的向量(正如我稍后將解釋的,這個(gè)新表示也按比例縮小了四倍)。
這就是AlexNet的第一層。接下來還有四個(gè)卷積層,每個(gè)層都將前一層的輸出作為輸入。
正如我們所見,第一層檢測(cè)基本圖案,如水平線和垂直線,明暗漸變和曲線。第二層使用這些輸出作為構(gòu)建塊,來檢測(cè)稍微復(fù)雜的形狀。例如,第二層的特征檢測(cè)器通過組合找到曲線的第一層特征檢測(cè)器的輸出來找到圓。第三層通過組合第二層的特征,找到更復(fù)雜的形狀。第四層和第五層以此類推,能夠找到的圖案越來越復(fù)雜。
2014年,研究人員Matthew Zeiler和Rob Fergus發(fā)表了一篇論文,文中提供了一些有用的方法來對(duì)ImageNet的五層神經(jīng)網(wǎng)絡(luò)所識(shí)別的模式類型進(jìn)行可視化。
第一層在單側(cè)具有11個(gè)單元的感受野,而后面的層在一側(cè)具有三至五個(gè)單元的感受野。注意,后面的這些層正在查看由較早層生成的要素圖,這些要素圖中的每個(gè)“像素”代表原始圖像中的多個(gè)像素。因此,每個(gè)圖層的感知區(qū)域都比前面的圖層包含原始圖像的比例更大。這也是后面的圖層中的縮略圖圖像看起來比前面的圖層更復(fù)雜的部分原因。
網(wǎng)絡(luò)的第五層,也是最后一層(上圖),能夠識(shí)別這些圖像中各種元素。
右邊的九個(gè)圖像可能看起來不太相似。但是如果你看一下左邊的九個(gè)熱圖,你會(huì)發(fā)現(xiàn)這個(gè)特殊的特征探測(cè)器沒有聚焦在每個(gè)圖像前景中的物體上。相反,它專注于每個(gè)圖像背景中的草地部分!
顯然,如果您嘗試識(shí)別的類別之一是“草”,草地檢測(cè)器就是很有用的,而且對(duì)識(shí)別許多其他類別的目標(biāo)也很有用。在五層卷積層之后,AlexNet有三層全連接層,就像我們的手寫識(shí)別網(wǎng)絡(luò)中的層一樣。這些層參考了第五層卷積層產(chǎn)生的每個(gè)特征映射,因?yàn)樗鼈冊(cè)噲D將圖像分類為1000個(gè)可能的類別之一。
因此,如果圖片背景中有草,則更有可能顯示出野生動(dòng)物。另一方面,如果圖片背景中有草,則不太可能是室內(nèi)家具的圖片。這和其他第五層特征檢測(cè)器提供了有關(guān)照片中可能內(nèi)容的大量信息。網(wǎng)絡(luò)的最后幾層合成了這些信息,以便對(duì)整個(gè)圖片所描繪的內(nèi)容產(chǎn)生有根據(jù)的猜測(cè)。
不同卷積層之間的差異:共享輸入權(quán)重
我們已經(jīng)看到卷積層中的特征檢測(cè)器執(zhí)行了令人印象深刻的模式識(shí)別,但到目前為止,我還沒有解釋卷積網(wǎng)絡(luò)實(shí)際上是如何工作的。
卷積層是一層神經(jīng)元。像任何神經(jīng)元一樣,它們會(huì)對(duì)輸入進(jìn)行加權(quán)平均,然后應(yīng)用激活函數(shù)。使用反向傳播技術(shù)來訓(xùn)練參數(shù)。
但與上述神經(jīng)網(wǎng)絡(luò)不同,卷積層未完全連接。每個(gè)神經(jīng)元僅從前一層中的一小部分神經(jīng)元獲取輸入。而且,至關(guān)重要的是,卷積網(wǎng)絡(luò)中的神經(jīng)元具有共享的輸入權(quán)重。
放大AlexNet第一個(gè)卷積層中的第一個(gè)神經(jīng)元。該層具有11×11像素的感受野,因此第一神經(jīng)元在圖像的一個(gè)角上觀察11×11像素。這個(gè)神經(jīng)元從這121個(gè)像素中獲取輸入,每個(gè)像素存在三個(gè)參數(shù)值——紅色、綠色和藍(lán)色。所以神經(jīng)元總共有363個(gè)輸入。像任何神經(jīng)元一樣,這個(gè)神經(jīng)元對(duì)這363個(gè)輸入值進(jìn)行加權(quán)平均,然后應(yīng)用激活函數(shù)。因?yàn)樗?63個(gè)輸入值,所以還需要363個(gè)輸入權(quán)重參數(shù)。
AlexNet第一層中的第二個(gè)神經(jīng)元看上去與第一個(gè)神經(jīng)元很相似。它還會(huì)看到一個(gè)11×11像素的正方形,但其感受野比第一個(gè)神經(jīng)元的感受野偏移了四個(gè)像素。這在兩個(gè)感受野之間產(chǎn)生了七個(gè)像素的重疊,這避免了跨越兩個(gè)神經(jīng)元之間的線路就會(huì)錯(cuò)失信息的模式。第二個(gè)神經(jīng)元還采用描述其11×11像素平方的363個(gè)值,將每個(gè)值乘以權(quán)重參數(shù),將這些值相加,并應(yīng)用激活函數(shù)。
第二個(gè)神經(jīng)元使用與第一個(gè)神經(jīng)元相同的輸入權(quán)重。第一神經(jīng)元的左上像素使用與第二神經(jīng)元的左上像素相同的輸入權(quán)重。所以這兩個(gè)神經(jīng)元尋找完全相同的模式;他們只有四個(gè)像素偏移的感受野。
當(dāng)然,神經(jīng)元的總數(shù)遠(yuǎn)不只兩個(gè):在55×55的網(wǎng)格中,實(shí)際上有3025個(gè)神經(jīng)元。這3025個(gè)神經(jīng)元中的每一個(gè)都使用與前兩個(gè)神經(jīng)元相同的363個(gè)輸入權(quán)重集。所有這些神經(jīng)元一起形成一個(gè)特征檢測(cè)器,無論它位于圖像中的哪個(gè)位置,都可以“掃描”特定的圖案。
不難看出,上面這兩張圖是采自某個(gè)真實(shí)的人臉,但把眼睛和嘴巴部分倒過來了。當(dāng)你倒著看時(shí),這張圖看起來相對(duì)正常,因?yàn)槿祟惖囊曈X習(xí)慣于在這個(gè)方向看到眼睛和嘴巴。但是,當(dāng)你正過來看這張臉時(shí),臉上的表情會(huì)立刻變得異常猙獰。
這表明,人類的視覺系統(tǒng)與神經(jīng)網(wǎng)絡(luò)的樣式匹配技術(shù)遵循的原則是相近的。如果我們看的東西總是在一個(gè)方向上的,比如說人類的眼睛,那么我們更習(xí)慣于以通常的方向來識(shí)別它們。
訓(xùn)練數(shù)據(jù)越充分,網(wǎng)絡(luò)性能越好,各大廠商紛紛發(fā)力
AlexNet的論文很快就在機(jī)器學(xué)習(xí)學(xué)術(shù)界引起轟動(dòng),其重要性也在工業(yè)界得到迅速認(rèn)可。谷歌對(duì)這項(xiàng)技術(shù)特別感興趣。
2013年,谷歌收購了由AlexNet論文的作者開辦的創(chuàng)業(yè)公司。他們使用該技術(shù)為Google相冊(cè)添加了新的圖片搜索功能。谷歌的查克·羅森伯格寫道:“我們直接從一個(gè)學(xué)術(shù)研究實(shí)驗(yàn)室走向了前沿研究,并在短短六個(gè)多月內(nèi)推出了新的功能。”
與此同時(shí),2013年的一篇論文描述了Google如何使用深度卷積網(wǎng)絡(luò)從Google街景圖像中的照片中讀取郵編。作者寫道:“該系統(tǒng)幫助我們從街景圖像中提取了近1億個(gè)真實(shí)街道上的數(shù)字。”
研究人員發(fā)現(xiàn)神經(jīng)網(wǎng)絡(luò)的性能隨著網(wǎng)絡(luò)的深度而不斷提高。 “我們發(fā)現(xiàn)這種方法的性能隨著卷積網(wǎng)絡(luò)的深度而增加,最佳性能出現(xiàn)在我們訓(xùn)練的最深層的架構(gòu)中,我們的實(shí)驗(yàn)表明,更深層次的架構(gòu)可能會(huì)獲得更好的精度,收益遞減。”
因此,在AlexNet誕生后,神經(jīng)網(wǎng)絡(luò)不斷深入。在2014年AlexNet獲勝后兩年,Google團(tuán)隊(duì)向2014年ImageNet競(jìng)賽提交了獲獎(jiǎng)作品。與AlexNet一樣,它基于深度卷積神經(jīng)網(wǎng)絡(luò),但Google使用更深層次的22層網(wǎng)絡(luò)來實(shí)現(xiàn)6.7-百分之五的錯(cuò)誤率 - 比AlexNet的16%錯(cuò)誤率大大提高。
更深層的網(wǎng)絡(luò)只適用于大型訓(xùn)練集。出于這個(gè)原因,Gerrish認(rèn)為ImageNet數(shù)據(jù)集在深度卷積網(wǎng)絡(luò)的成功方面發(fā)揮了關(guān)鍵作用。ImageNet比賽為參賽者提供了一百萬張圖片,并要求他們將這些圖片分配給1000個(gè)不同類別中的一個(gè)。
“擁有一百萬張圖像來訓(xùn)練網(wǎng)絡(luò),意味著每個(gè)級(jí)別上有1000張圖像。”Gerrish說。他說,如果沒有如此大的數(shù)據(jù)集,“需要訓(xùn)練的參數(shù)數(shù)量就太多了。”
近年來,人們一直致力于積累更大的數(shù)據(jù)量,以便用于訓(xùn)練更深、更準(zhǔn)確的網(wǎng)絡(luò)。所以自動(dòng)駕駛汽車企業(yè)一直專注于積累路測(cè)里程,途中采集到的圖像和測(cè)試視頻可以用于訓(xùn)練圖像識(shí)別網(wǎng)絡(luò)。
深度學(xué)習(xí)算力需求幾無止境,GPU廠商盆滿缽滿
更深層的網(wǎng)絡(luò)和更大的訓(xùn)練集可以提供更好的性能,激發(fā)了對(duì)更多計(jì)算力的永不滿足的需求。AlexNet成功的一個(gè)重要原因是認(rèn)識(shí)到了神經(jīng)網(wǎng)絡(luò)訓(xùn)練可以利用顯卡的并行計(jì)算能力進(jìn)行高效快速的矩陣操作。
這對(duì)于GPU制造商N(yùn)vidia和AMD來說,無疑是一筆可觀的財(cái)富。這兩家公司都致力于開發(fā)面向機(jī)器學(xué)習(xí)應(yīng)用的獨(dú)特需求而開發(fā)的新芯片,AI應(yīng)用程序現(xiàn)在占這類公司GPU銷售額的很大一部分。
2016年,谷歌宣布創(chuàng)建了名為Tensor Processing Unit(TPU)的定制芯片,專門用于神經(jīng)網(wǎng)絡(luò)操作。 Google早在2006年就考慮為神經(jīng)網(wǎng)絡(luò)構(gòu)建專用集成電路(ASIC),但情況在2013年變得緊迫起來。“那時(shí)我們意識(shí)到,神經(jīng)網(wǎng)絡(luò)快速增長(zhǎng)的計(jì)算需求可能要求我們將運(yùn)營的數(shù)據(jù)中心數(shù)量增加一倍。“
最初,TPU的訪問權(quán)限僅限谷歌自己的專有服務(wù),但后來逐步開放,允許任何人通過谷歌的云計(jì)算平臺(tái)使用該技術(shù)。
當(dāng)然,谷歌并不是唯一一家致力于AI芯片的公司。iPhone的最新版本芯片就具備針對(duì)神經(jīng)網(wǎng)絡(luò)操作優(yōu)化的“神經(jīng)引擎”。英特爾也在開發(fā)針對(duì)深度學(xué)習(xí)而優(yōu)化的一系列芯片。特斯拉最近宣布將不再使用英偉達(dá)的芯片,轉(zhuǎn)而支持自研的神經(jīng)網(wǎng)絡(luò)芯片。另據(jù)報(bào)道,亞馬遜也在開發(fā)自己的AI芯片。
-
神經(jīng)網(wǎng)絡(luò)
+關(guān)注
關(guān)注
42文章
4814瀏覽量
103666 -
圖像
+關(guān)注
關(guān)注
2文章
1094瀏覽量
41280 -
機(jī)器學(xué)習(xí)
+關(guān)注
關(guān)注
66文章
8503瀏覽量
134639
原文標(biāo)題:卷積神經(jīng)網(wǎng)絡(luò)的“封神之路”:一切始于AlexNet
文章出處:【微信號(hào):AI_era,微信公眾號(hào):新智元】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
詳解深度學(xué)習(xí)、神經(jīng)網(wǎng)絡(luò)與卷積神經(jīng)網(wǎng)絡(luò)的應(yīng)用

從AlexNet到MobileNet,帶你入門深度神經(jīng)網(wǎng)絡(luò)
卷積神經(jīng)網(wǎng)絡(luò)—深度卷積網(wǎng)絡(luò):實(shí)例探究及學(xué)習(xí)總結(jié)
解析深度學(xué)習(xí):卷積神經(jīng)網(wǎng)絡(luò)原理與視覺實(shí)踐
卷積神經(jīng)網(wǎng)絡(luò)模型發(fā)展及應(yīng)用
卷積神經(jīng)網(wǎng)絡(luò)的在人工智能中的發(fā)展
使用多孔卷積神經(jīng)網(wǎng)絡(luò)解決機(jī)器學(xué)習(xí)的圖像深度不準(zhǔn)確的方法說明
基于多孔卷積神經(jīng)網(wǎng)絡(luò)的圖像深度估計(jì)模型






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論