 向來提倡open的谷歌,現在也玩兒“自閉”?
向來提倡open的谷歌,現在也玩兒“自閉”?
谷歌AI又成了話題。Reddit網友找到了谷歌AI一個名叫Conceptual Captions的數據集,發現該數據集并不完善,于是乎聯系谷歌AI相關人員,卻慘遭三連拒。
向來提倡open的谷歌,現在也玩兒“自閉”?
昨天谷歌AI大佬Jeff Dean剛剛發表長文總結了2018年的主要研究成果,其中包括“開源軟件和數據集”:
發布開源軟件和創建新的公共數據集是我們為研究和軟件工程社區做出貢獻的兩種主要方式。
然而細心的Reddit網友卻發現,谷歌AI并沒有那么“開源”,反而還拒絕共享數據:
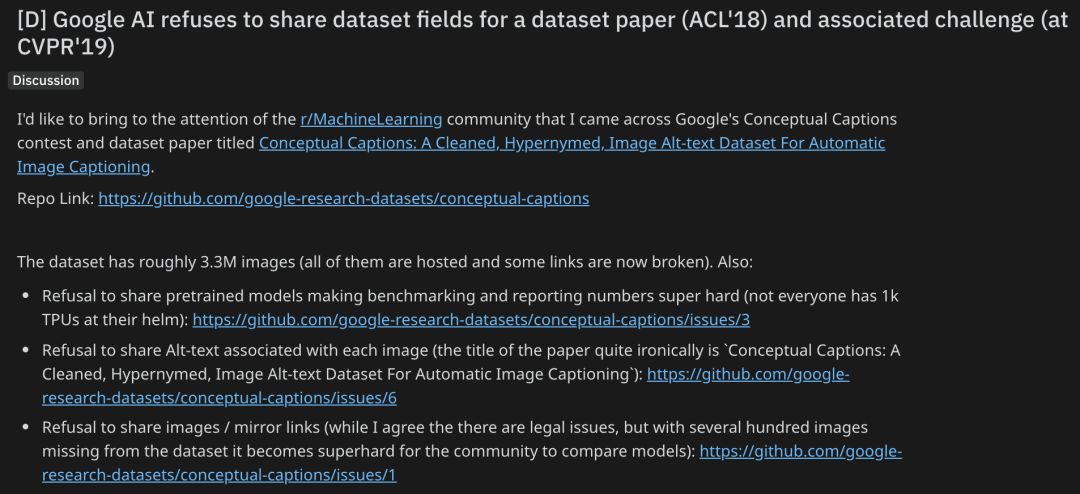
事情是這樣的。
這位網友發現了谷歌AI一個叫Conceptual Captions數據集相關的比賽,以及描述這個數據集的論文(ACL 2018):
論文地址:
http://aclweb.org/anthology/P18-1238
在GitHub中對此數據集的描述為:一種包含330萬張圖像的大規模圖像數據集,專門用于機器學習圖像字幕系統的訓練和評估。
GitHub地址:
https://github.com/google-research-datasets/conceptual-captions
然而,當這位網友躍躍欲試想要拿這個數據集操練一番時卻發現了一些問題:這個數據集全部圖像都是托管的,一些鏈接現在已經失效。
于是,這位網友開始試圖聯系谷歌AI相關人員。
結果,真可謂是大跌眼鏡。
慘遭三連拒,熱心研究者被潑冷水
第一拒:拒絕分享預訓練模型
這就使得基準測試和論文里的結果數字變得非常難以復現。畢竟,不是每個人都有1k的TPU。
地址:https://github.com/google-research-datasets/conceptual-captions/issues/3
問:哪里可以找到基于Conceptual Captions數據集的預訓練模型(RNN-,Transformer-based)?
答:預訓練模型沒有發布。
第二拒:拒絕分享與每個圖像關聯的Alt-text
諷刺的是,這篇論文標題是“Conceptual Captions: A Cleaned, Hypernymed, Image Alt-text Dataset For Automatic Image Captioning”。
地址:https://github.com/google-research-datasets/conceptual-captions/issues/6
問:是否會發布與每個圖像關聯的Alt-text?用于生成字幕的代碼也會公開嗎?
答:沒有發布Alt-text或代碼的計劃。
第三拒:拒絕分享圖像/鏡像鏈接
這位網友表示:雖然我同意存在法律問題,但數據集中缺少數百張圖像,其他研究人員要想比較模型變得超級困難。
地址:https://github.com/google-research-datasets/conceptual-captions/issues/1
問:您能提供從tsv文件通過url下載圖像的示例代碼嗎?Python的urllib無法下載某些url (IOError: [Errno socket error] [Errno 110] Connection timed out)。但是我可以在瀏覽器中看到這些圖像。
答:謝謝你的關注!不幸的是,由于版權/法律問題,我們無法提供通過url從tsv文件下載圖像的代碼。
谷歌AI“自閉”拒共享,引網友熱議
這位熱心網友在慘遭三連拒后表示對這樣的事情非常痛心:
一篇數據集論文對于復現結果非常重要,如果存在阻礙數據集共享的法律問題,那么發表私人數據集論文就好了(有些領域不公開Alt-text),但基于一個不公開預訓練模型、不完全共享的數據集舉辦挑戰賽,我認為這就不太酷了。
而后,其它網友們也炸鍋了。
熱心網友1:_michaelx99
Deepmind的一些論文也是這樣,僅僅根據他們發表的論文,完全不可能把結果復現出來。我花了一段時間才意識到Arxiv或他們網站上的一篇“論文”并不是真正的出版物,因此它的主要目標是展示公司已經開發了某種能力。這與其他人能夠證實或否認他們在科學過程中所做的事情關系不大。我并不是說大公司在網上發布的所有論文都是這樣,但正如你剛剛發現的,其中一些論文確實如此。
熱心網友2:duckbill_principate
據我所知,四分之一的ML論文本質上是美化的廣告。
熱心網友3:GoAwayStupidAI
可重復性是科學的標志。沒有這些數據,這個結果是不可復制的,所以科學會很糟糕。
熱心網友4:Silver5005
這是ML論文最大的問題。我一直在嘗試實現一個股票預測的LSTM,你可以找到數百篇論文都在做同樣的概念。但它們都沒有數據集,也不會談論它們如何清理或標準化它們的數據。
熱心網友5:duckbill_principate
人們不分享他們的模型、代碼或數據集,這本身并不困擾我。令我困擾的是,這種情況發生了,而這些論文仍然被接受。這是同行評審過程的絕對失敗,它的責任完全落在審查員(和我們)的肩上。這些論文是在信任的基礎上被接受的,在某些情況下甚至是權威(我們都知道,盡管存在著雙盲的本質,但不難推斷出某些論文可能來自哪個群體),這是絕對不可接受的。
這更接近于廣告而不是科學。
熱心網友6:epic
我不知道為什么有這么多谷歌的辯護者。這對科學和機器學習都不利。是的,我們都明白為什么,但這仍然很糟糕。特別是像這樣的論文,如果不能從數據中分離出來的話,再現性是非常困難的。有機會的組織和個人應該以一個好榜樣來領導這個領域,而不是反過來。
對此,你怎么看?
-
谷歌
+關注
關注
27文章
6207瀏覽量
106148 -
AI
+關注
關注
87文章
31844瀏覽量
270639 -
數據集
+關注
關注
4文章
1210瀏覽量
24861
原文標題:谷歌AI遭猛懟!發布數據集論文和挑戰賽,卻拒絕公開數據集
文章出處:【微信號:AI_era,微信公眾號:新智元】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
Open AI 將在德國投資
Open-E JovianDSS Up31增強的功能和新特性
TAS5411-Q1 open load不管接不接喇叭都是open,重啟也不變,為什么?
谷歌獲Character.AI大模型技術授權,創始人重歸谷歌懷抱
單北斗定位智能終端提倡應用的重要性

蘋果確認未來也將與谷歌Gemini合作
兩小時“吼出”121次AI,谷歌背后埋伏著Open AI的幽靈

中國電信和GSMA成立全球首個Open Gateway聯合開放實驗室
opc ua open62541.c和open62541.h如何移植到stm32中?
Open RAN的未來及其對AT&T的意義
谷歌模型合成軟件有哪些
谷歌模型怎么用手機打開文件






 工商網監
工商網監
評論