") 什么是決策樹?決策樹算法思考總結(jié)
什么是決策樹?決策樹算法思考總結(jié)

一、什么是決策樹
決策樹是一類常見的機器學習方法,通過歷史數(shù)據(jù)得到的樹結(jié)構(gòu)模型對新數(shù)據(jù)進行分類決策。
決策樹是一種基于實例的歸納學習方法,它能從給定的無序的訓練樣本中,提煉出樹形的分類模型。
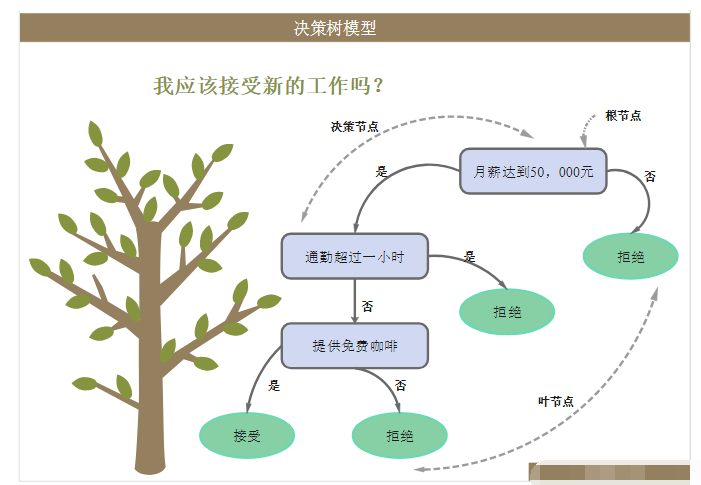
樹中的每個非葉子節(jié)點記錄了使用哪個特征來進行類別的判斷,每個葉子節(jié)點則代表了最后判斷的類別。根節(jié)點到每個葉子節(jié)點均形成一條分類的路徑規(guī)則。
每次判斷都是對某個屬性的測試,每次判斷都會縮小考慮的范圍。
一棵決策樹包含一個根節(jié)點、若干個內(nèi)部結(jié)點和若干個葉節(jié)點;葉節(jié)點對應于決策結(jié)果,其他每個節(jié)點則對應于一個屬性測試;每個節(jié)點包含的樣本集合根據(jù)屬性測試的結(jié)果被劃分到子節(jié)點;
根節(jié)點包含樣本全集。從根節(jié)點到每個葉節(jié)點的路徑對應了一個判斷測試序列。
決策樹的生成是一個遞歸的過程,有三種情形不會再分類:
當前節(jié)點包含的樣本全屬于同一類別
當前屬性集為空
當前節(jié)點的樣本集合為空
對于第二種情形,其類別設(shè)定為結(jié)點所含樣本最多的類別。對于第三種情形,將其類別設(shè)定為其父節(jié)點所含樣本最多的類別
二、常見決策樹分類算法
1、CLS算法:是最原始的決策樹分類算法,基本流程是,從一棵空數(shù)出發(fā),不斷的從決策表選取屬性加入數(shù)的生長過程中,直到?jīng)Q策樹可以滿足分類要求為止。CLS算法存在的主要問題是在新增屬性選取時有很大的隨機性。
2、ID3算法:對CLS算法的最大改進是摒棄了屬性選擇的隨機性,利用信息熵的下降速度作為屬性選擇的度量。ID3是一種基于信息熵的決策樹分類學習算法,以信息增益和信息熵,作為對象分類的衡量標準。
ID3算法結(jié)構(gòu)簡單、學習能力強、分類速度快適合大規(guī)模數(shù)據(jù)分類。但同時由于信息增益的不穩(wěn)定性,容易傾向于眾數(shù)屬性導致過度擬合,算法抗干擾能力差。
ID3算法缺點:傾向于選擇那些屬性取值比較多的屬性,在實際的應用中往往取值比較多的屬性對分類沒有太大價值、不能對連續(xù)屬性進行處理、對噪聲數(shù)據(jù)比較敏感、需計算每一個屬性的信息增益值、計算代價較高。
3、C4.5算法:基于ID3算法的改進,主要包括:使用信息增益率替換了信息增益下降度作為屬性選擇的標準;在決策樹構(gòu)造的同時進行剪枝操作;避免了樹的過度擬合情況;可以對不完整屬性和連續(xù)型數(shù)據(jù)進行處理,提升了算法的普適性。
三、決策樹特征選擇準則
1 信息增益
“信息熵”是度量樣本集合純度最常用的一種指標。假定當前樣本集合D中第K類樣本所占的比例為PK,則D的信息熵定義為
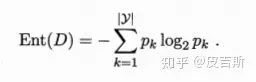
值越小,則D的純度越高。

信息增益越大,則意味著使用屬性a來進行劃分所獲得的“純度提升”越大。
ID3決策樹學習算法就是以信息增益為準則來選擇劃分屬性的。
2 信息增益率
實際上信息增益準則對可取值數(shù)目較多的屬性有所偏好,為了減少這種偏好可能帶來的不利影響。使用信息增益率來選擇最優(yōu)劃分屬性。
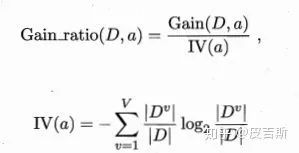
C4.5算法常使用信息增益率來選擇最優(yōu)屬性劃分
3 基尼指數(shù)
CART決策樹使用“基尼指數(shù)”來選擇劃分屬性,
數(shù)據(jù)集D的純度可用基尼值來度量:
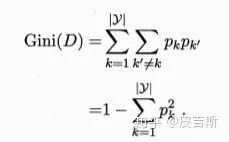
Gini(D)反映了從數(shù)據(jù)集D中隨機抽取兩個樣本,其類別標記不一致的概率。故其值越小越好。數(shù)據(jù)集D的純度越高。
屬性a的基尼指數(shù)定義為
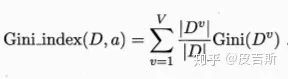
于是,我們在候選屬性集合A中,選擇哪個使得劃分后基尼指數(shù)最小的屬性作為最優(yōu)劃分屬性。
4 剪枝處理
剪枝是決策樹學習算法對付“過擬合”的主要手段。剪枝的基本策略有“預剪枝”和“后剪枝”。
預剪枝是指在決策樹生成過程中,對每個結(jié)點在劃分前進行估計,若當前節(jié)點的劃分不能帶來決策樹泛化能力提升,則停止劃分并將當前節(jié)點標記為葉節(jié)點。
后剪枝則是先從訓練集生成一顆完整的決策樹,然后自底向上地對非葉節(jié)點進行考察,若將該節(jié)點對應的子樹替換為葉節(jié)點能帶來決策樹泛化能力提升,則將該節(jié)點替換為葉節(jié)點。
5 連續(xù)與缺失值
5.1 連續(xù)值處理
將該節(jié)點上的所有樣本按照屬性的取值有小到大排序,在兩個值之間去平均值,依次將所有平均值作為分割點,分別計算他們的信息增益率,將值最大的那個作為最優(yōu)分割點。
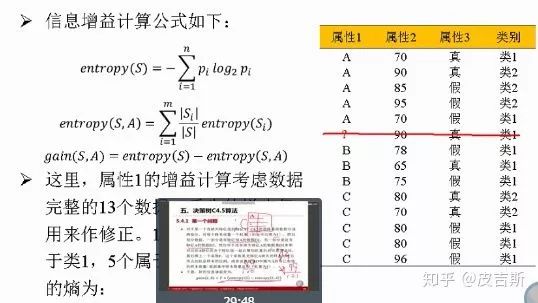
5.2 缺失值的處理
處理過程如下


四、sklearn參數(shù)
1criterion:gini或者entropy,前者是基尼系數(shù),后者是信息熵。兩種算法差異不大對準確率無影響,信息墑運算效率低一點,
2 因為它有對數(shù)運算.一般說使用默認的基尼系數(shù)”gini”就可以了,即CART算法。除非你更喜歡類似ID3,C4.5的最優(yōu)特征選擇方法。
3 4splitter:bestorrandom前者是在所有特征中找最好的切分點后者是在部分特征中, 5 默認的”best”適合樣本量不大的時候,而如果樣本數(shù)據(jù)量非常大,此時決策樹構(gòu)建推薦”random”。 6max_features:None(所有),log2,sqrt,N特征小于50的時候一般使用所有的 7 8max_depth:intorNone,optional(default=None)一般來說,數(shù)據(jù)少或者特征少的時候可以不管這個值。 9如果模型樣本量多,特征也多的情況下,推薦限制這個最大深度,具體的取值取決于數(shù)據(jù)的分布。10常用的可以取值10-100之間。常用來解決過擬合1112min_samples_split:如果某節(jié)點的樣本數(shù)少于min_samples_split,則不會繼續(xù)再嘗試選擇最優(yōu)特征來進行劃分,13如果樣本量不大,不需要管這個值。如果樣本量數(shù)量級非常大,則推薦增大這個值。14min_samples_leaf:這個值限制了葉子節(jié)點最少的樣本數(shù),如果某葉子節(jié)點數(shù)目小于樣本數(shù),則會和兄弟節(jié)點一起被剪枝,15如果樣本量不大,不需要管這個值,大些如10W可是嘗試下516min_weight_fraction_leaf:這個值限制了葉子節(jié)點所有樣本權(quán)重和的最小值,如果小于這個值,則會和兄弟節(jié)點一起被剪枝默認是0,就是不考慮權(quán)重問題。17一般來說,如果我們有較多樣本有缺失值,或者分類樹樣本的分布類別偏差很大,就會引入樣本權(quán)重,這時我們就要注意這個值了。1819max_leaf_nodes:通過限制最大葉子節(jié)點數(shù),可以防止過擬合,默認是"None”,即不限制最大的葉子節(jié)點數(shù)。如果加了限制,算法會建立在最大葉子節(jié)點數(shù)內(nèi)最優(yōu)的決策樹。20如果特征不多,可以不考慮這個值,但是如果特征分成多的話,可以加以限制具體的值可以通過交叉驗證得到。21class_weight:指定樣本各類別的的權(quán)重,主要是為了防止訓練集某些類別的樣本過多導致訓練的決策樹過于偏向這些類別。這里可以自己指定各個樣本的權(quán)重,22如果使用“balanced”,則算法會自己計算權(quán)重,樣本量少的類別所對應的樣本權(quán)重會高。23min_impurity_split:這個值限制了決策樹的增長,如果某節(jié)點的不純度(基尼系數(shù),信息增益,均方差,絕對差)小于這個閾值則該節(jié)點不再生成子節(jié)點。24即為葉子節(jié)點。25
-
算法
+關(guān)注
關(guān)注
23文章
4705瀏覽量
95075 -
決策樹
+關(guān)注
關(guān)注
3文章
96瀏覽量
13797 -
ID3
+關(guān)注
關(guān)注
0文章
5瀏覽量
3716
原文標題:決策樹算法思考總結(jié)
文章出處:【微信號:AI_shequ,微信公眾號:人工智能愛好者社區(qū)】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
關(guān)于決策樹,這些知識點不可錯過
決策樹的生成資料
一個基于粗集的決策樹規(guī)則提取算法
改進決策樹算法的應用研究
決策樹的構(gòu)建設(shè)計并用Graphviz實現(xiàn)決策樹的可視化
決策樹的原理和決策樹構(gòu)建的準備工作,機器學習決策樹的原理
決策樹的構(gòu)成要素及算法
決策樹的基本概念/學習步驟/算法/優(yōu)缺點
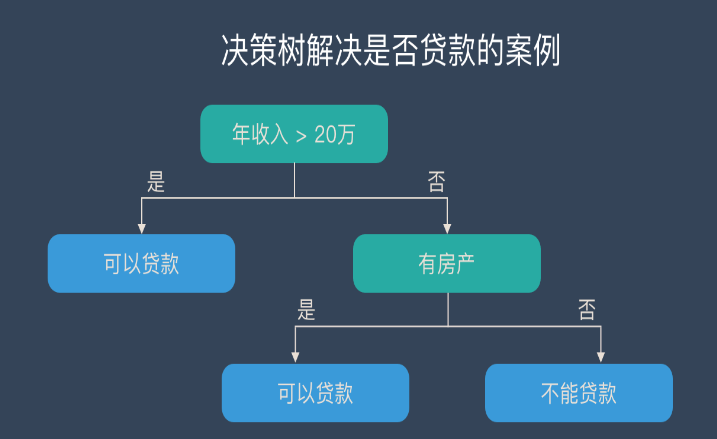
什么是決策樹模型,決策樹模型的繪制方法





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論