") 如何利用20萬條客戶咨詢消息,打造一款功能定制化的自動聊天應(yīng)答機(jī)器人?
如何利用20萬條客戶咨詢消息,打造一款功能定制化的自動聊天應(yīng)答機(jī)器人?
如何利用20萬條客戶咨詢消息,打造一款功能定制化的自動聊天應(yīng)答機(jī)器人?如何將大量消息轉(zhuǎn)化為常見問題,整合進(jìn)機(jī)器人的設(shè)計(jì)工作流程中?本文除了回答這些問題之外,還從需求、設(shè)計(jì)思路、面向人群、 實(shí)現(xiàn)方式等方面作了一番梳理。
我們在六個(gè)月內(nèi)收集了一家大型房地產(chǎn)公司從訪問該網(wǎng)站的數(shù)據(jù)中收集的20萬條消息,并進(jìn)行了深入分析,設(shè)計(jì)了一個(gè)滿足特定需求的聊天機(jī)器人。
首先看需要確定哪些因素,包括:
最常見的問題(FAQ)/服務(wù)需求
這些問題的主題,以及不同主題之間的分布情況
訪問者通過詢問這些主題試圖實(shí)現(xiàn)的目標(biāo)是什么
我們?yōu)槭裁礇Q定這樣做?簡而言之就是,我們希望做出數(shù)據(jù)驅(qū)動的決策。
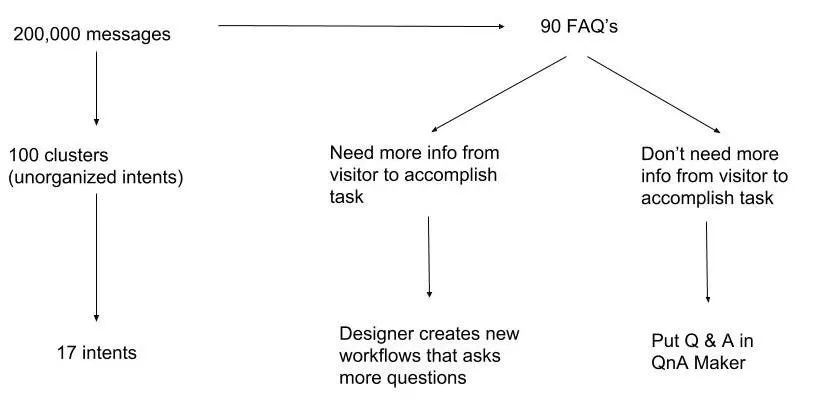
客戶來到我們這里,他們的潛在客戶或現(xiàn)有客戶在訪問網(wǎng)站時(shí)發(fā)送了20萬條消息,這些消息是發(fā)送給實(shí)時(shí)聊天服務(wù)的。包括由在線代理機(jī)器人回復(fù)的消息,以及客服離線期間錯(cuò)過的消息。
我們運(yùn)行了一種數(shù)據(jù)算法,將這些消息分類為類似信息的集群。在這一點(diǎn)上,我們無法自信地考慮他們的意圖。我們花了很多精力將它們設(shè)計(jì)成我們設(shè)計(jì)聊天機(jī)器人的意圖。
這20萬條消息可以歸結(jié)為90個(gè)FAQ,我們通過人工分類劃分為3類,分別是:
1、可以自動回答的問題
2、在回答之前需要一系列問題來獲取上下文信息
3、需要機(jī)器人客服將訪問者轉(zhuǎn)接到人工客服,以獲得準(zhǔn)確的答案
算法解決什么問題?
以前,在決定將哪些會話流轉(zhuǎn)接給聊天機(jī)器人時(shí),很多靠的是猜測。因?yàn)椴]有能夠獲得數(shù)據(jù),讓我們確定哪些對話對用戶而言是最有用的,因?yàn)槲覀儾恢烙脩粝胫朗裁础?/p>
如何實(shí)現(xiàn)?
實(shí)際上,實(shí)現(xiàn)這個(gè)目標(biāo)是一個(gè)“意圖聚類”的過程。這有助于分析兩人之間的聊天記錄。我們將這些信息輸入算法,確定具有相似含義的語句簇,這一過程就是所謂的“語義聚類”。語義聚類讓我們可以考慮優(yōu)先使用哪些短語來訓(xùn)練聊天機(jī)器人,來理解并進(jìn)行對話(NLP訓(xùn)練),哪些問題應(yīng)該通過在問答服務(wù)中進(jìn)行訓(xùn)練,以命令和響應(yīng)的方式提供靜態(tài)的答案,在這種情況下,可以使用微軟的問答機(jī)器人。
潛在用戶有哪些?
UX /會話設(shè)計(jì)師。這種分析可以實(shí)現(xiàn)以用戶為中心的設(shè)計(jì),因?yàn)榭梢缘弥枰獦?gòu)建哪些用戶路徑。我們的目標(biāo)是提供問題的在當(dāng)前文本情景下的答案,這類問題是聊天機(jī)器人無法正確處理的。
機(jī)器人訓(xùn)練師。他們現(xiàn)在知道哪些意圖是最重要的。訓(xùn)練師可以優(yōu)先訓(xùn)練機(jī)器人,以了解它們最常被問及的主題的不同短語。
客戶。我們提供關(guān)于對話的概述摘要,內(nèi)容包含主要數(shù)據(jù)點(diǎn)、對話中提及的主題類型和頻率,消息數(shù)量等。
這個(gè)過程具體分哪幾步?下面用“門外漢”式的方式解釋一下。
1、從客戶或第三方聊天機(jī)器人供應(yīng)商出獲得會話腳本。
2、運(yùn)行算法,通過機(jī)器學(xué)習(xí)模型進(jìn)行對話,并處理每個(gè)對話中的句子,按語義對句子進(jìn)行分類。
3、然后運(yùn)行另一種算法,將這些按預(yù)測具有相似“意圖”的句子分成組。注意,這時(shí)的同一聚類中可能包含彼此不完全相關(guān)的句子。這些句子中只是包含類似的信息。
4、接著人工瀏覽這些句子,并對句子集群進(jìn)行分析,向聚類內(nèi)容分配標(biāo)簽,得到一個(gè)單獨(dú)的“意圖”列表。
集群與意圖:這里需要對這兩個(gè)概念作一個(gè)區(qū)分。集群是一組具有相似語義的句子。比如可以確定10個(gè)句子,內(nèi)容似乎都是關(guān)于購買房產(chǎn)的。但是因?yàn)檫@是一種無監(jiān)督的機(jī)器學(xué)習(xí)算法,沒有人類背景,確定某個(gè)集群是否可以轉(zhuǎn)化為“意圖”必須要人類進(jìn)行驗(yàn)證。
5、設(shè)計(jì)師利用這些“意圖”和常見問題設(shè)計(jì)工作流程,以便能夠順利回答人類提出的問題,或滿足人們的請求。
我們對客戶提出問題和要求進(jìn)行了調(diào)查,內(nèi)容包括:
客戶詢問的主要主題和每個(gè)主題中的消息數(shù)量
在每個(gè)主題中子話題的類型
前10個(gè)主題中的消息頻率和分布情況
關(guān)于客服人員在線或不在線時(shí)的對話主題的比較
結(jié)果發(fā)現(xiàn),在最熱門10個(gè)消息主題中,有一半與房價(jià)、設(shè)施和地理位置有關(guān)。
這三個(gè)主題占到用戶查詢在線客服機(jī)器人消息總量的一半。
最冷門的話題是關(guān)于停車位的,只占查詢信息總量的3%。
算法的工作原理
算法從對話中獲取句子并進(jìn)行向量化。在更高一級,向量化的句子對詞語之間的關(guān)系進(jìn)行分配,比如算法會確定,素食者吃蔬菜。
然后再使用另一種基于向量的算法,將句子分組為具有相似語義的群集。
面臨的挑戰(zhàn)
要準(zhǔn)確地將意圖分配給對應(yīng)的信息集群需要人工操作。當(dāng)集群數(shù)量很多時(shí),對團(tuán)隊(duì)而言就是個(gè)很繁瑣的任務(wù)。而且,將90個(gè)常見問題整理成能夠反映用戶意圖的工作流程,需要多元化背景團(tuán)隊(duì)的密切合作。
-
微軟
+關(guān)注
關(guān)注
4文章
6673瀏覽量
105383 -
機(jī)器人
+關(guān)注
關(guān)注
213文章
29504瀏覽量
211609 -
nlp
+關(guān)注
關(guān)注
1文章
490瀏覽量
22488
原文標(biāo)題:如何用20萬條客服咨詢消息“喂”出定制化聊天機(jī)器人
文章出處:【微信號:AI_era,微信公眾號:新智元】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
2016上海工業(yè)自動化及機(jī)器人展覽會
干貨:超級機(jī)器人的探尋之旅
激光導(dǎo)航AGV底盤定制 巡檢機(jī)器人,服務(wù)機(jī)器人,智慧物流搬運(yùn)AGV
如何打造一款服務(wù)型機(jī)器人
電話機(jī)器人顯著提高回款效率,對催收幫助不言而喻。
深圳 AI電銷機(jī)器人源頭開發(fā)商招代理,價(jià)格低、模式新穎。
使用旅游機(jī)器人需要注意哪些問題?
如何打造出與人類自然交流的機(jī)器人?
如何利用Python+ESP8266 DIY 一個(gè)智能聊天機(jī)器人?
基于OP7200的應(yīng)答機(jī)自動測試系統(tǒng)






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論