 基于STM32介紹DMA的雙緩沖模式
基于STM32介紹DMA的雙緩沖模式

目前STM32家族中有些系列支持DMA的雙緩沖模式,比如STM32F2/STM32F4/STM32F7等系列。尤其隨著人們對STM32F4/F7系列應用不斷拓寬和加深,在設計中運用到DMA雙緩沖的場合也越來越多。STM32芯片中的DMA又可分為兩大類,一類是通用DMA,一類是專用DMA,比如用于USB,TFT LCD,ETHERNET等外設應用上的DMA。這里要談的是基于通用DMA的話題,不妨以STM32F4系列芯片為例。
關于STM32F4的DMA雙緩沖傳輸在STM32F4系列的參考手冊里做了簡單描述。因為它是基于介紹了單緩沖模式的DMA介紹之后接著介紹的,稍顯言簡意賅。
相比單緩沖的數據流,雙緩沖多了一個DMA存儲區和相應的存儲指針;
如果使能DMA雙緩沖,硬件會自動使能DMA的循環傳輸模式;
每一批數據傳輸結束,或者說每次傳輸事務結束時通過交換存儲指針實現更換存儲區的目的。
4.DMA雙緩沖模式僅在外設與存儲器間進行,不支持memoryto Memory間的傳輸。

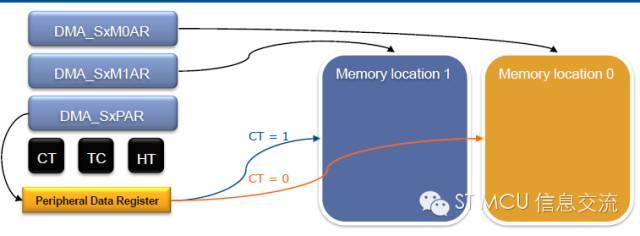
基于DMA雙緩沖模式的的特點,不難理解在應用中必須開辟兩個存儲區以及存放兩個存儲區首地址的存儲寄存器,DMA_SxM0AR和DMA_SxM1AR。
DMA_SxM0AR:指向存儲區0,單緩沖模式下默認使用該寄存器做存儲區指針。
DMA_SxM1AR:指向存儲區1,僅在DMA雙緩沖模式下才能使用。
DMA正在訪問的當前存儲區由CT@DMA_SxCR位表示
?CT = 0:DMA正在訪問存儲區0,CPU可以訪問存儲區1
?CT = 1:DMA正在訪問存儲區1,CPU可以訪問存儲區0
使用DMA雙緩沖傳輸,既可以減少CPU的負荷,又能最大程度地實現DMA數據傳輸和CPU數據處理互不打擾又互不耽擱,同時也給應用開發也帶來方便。比如,假設你使用DMA單存儲緩沖,有些情況下可能是等待DMA搬完了數據,CPU才過來處理;有些情況下可能是DMA一邊傳輸,CPU也一邊來訪問,這時往往會使用到環形存放和讀取,代碼實現起來稍顯繁瑣也容易出紕漏。如果改為DMA雙緩沖模式,應用上實現起來也就簡潔很多。再加上DMA雙緩沖模式的循環特性,使用它對存儲區的空間容量要求也會大大降低。尤其在大批量數據傳送時,你只需開辟兩個合適大小的存儲區,能滿足DMA在切換存儲區時的當前新存儲區空出來就好,并不一定要開辟多大多深的存儲空間。有過這方面應用經驗的工程師可能就有體會,單純一味地加大雙緩沖區的深度并不明顯改善數據傳輸狀況。
關于這點不妨打個比方,某茶館有倆芳名分別為CPU和DMA的伺茶MM,,每人手里有個同樣茶壺。DMA負責把她手里的茶壺裝滿茶水就好,CPU就負責用從DMA手里接過裝滿茶水的壺給客人倒茶,倒完了用空壺與DMA交換裝滿茶水的壺繼續工作。顯然,只要保證CPU妹妹茶壺里總有茶水,至于那兩個茶壺選多大容積并不是很重要。倒是那個茶壺進出口徑對整個事情的效率有影響。
關于DMA雙緩沖話題,我們也不妨看看一個具體的案例加深下印象。案例來自網絡,為了盡量壓縮篇幅,我省卻了部分配置代碼,留下需要交流的關鍵語句。
&&&&&&&&&&&&&&&&&
F407 DMA的double Buffer mode上卡了好久了!大家看看配置哪里出問題了?
uint8_tBuffer0[] = {0x11,0x22,0x33,0x44}; //無符號的8位整型數
uint8_tBuffer1[] = {0xaa,0xbb,0xcc,0xdd}; //無符號的8位整型數
voidUSART3_DMA1_Configuration(void)
{
......
DMA_InitStructure.DMA_PeripheralBaseAddr= USART3_DR_Addr; //外設首地
DMA_InitStructure.DMA_Memory0BaseAddr= (uint32_t)Buffer0; //內存區首地址(1)
DMA_InitStructure.DMA_DIR= DMA_DIR_MemoryToPeripheral; //內存->外設
DMA_InitStructure.DMA_BufferSize= 8; //*****傳輸數據個數為8 *****(2)
DMA_InitStructure.DMA_PeripheralInc= DMA_PeripheralInc_Disable;
DMA_InitStructure.DMA_MemoryInc= DMA_MemoryInc_Enable; //
DMA_InitStructure.DMA_PeripheralDataSize= DMA_PeripheralDataSize_Byte;
DMA_InitStructure.DMA_MemoryDataSize= DMA_MemoryDataSize_Byte;
DMA_InitStructure.DMA_Mode= DMA_Mode_Circular; //循環傳輸
……
DMA_DoubleBufferModeConfig(DMA1_Stream3,(uint32_t)Buffer1, DMA_Memory_1);//(3)
DMA_DoubleBufferModeCmd(DMA1_Stream3,ENABLE);//(4)enable double buffle
DMA_Init(DMA1_Stream3,&DMA_InitStructure);
DMA_Cmd(DMA1_Stream3,ENABLE); //使能 DMA1_Stream3通道
DMA_ClearITPendingBit(DMA1_Stream3,DMA_IT_TCIF3);
DMA_ITConfig(DMA1_Stream3,DMA_IT_TC, ENABLE);
}
&&&&&&&&&&&&&&&&&
發帖者述說,如果將藍色語句(3)的DMA_Memory_1改成DMA_Memory_0的話,就能正常打印出 11 22 33 44 aa bb cc dd,如果換成DMA_Memory_1的話,現象就不對了!輸出的結果卻是aa bb cc dd 15 00 08 52。請問是怎么回事?
顯然發帖者使用STM32F4系列芯片DMA的雙緩沖功能,應該只是做做實驗而已。他開辟了兩個長度均為4字節的緩沖存儲區BUFFER0和BUFFER1。從基于ST固件庫函數代碼配置角度看,雙緩沖模式相比單緩沖模式,就是多了(3)(4)兩句,其它都一樣。這里我們特別留意下其中(1)(2)(3)句配置代碼。
綠色語句(1)配置了存儲區0指針指向的地址;
紅色代碼語句(2)處給出了DMA每輪的傳輸數據個數8;
藍色代碼語句(3)處配置存儲區1的地址和選擇第一個當前存儲區;
整體上看,該配置都配置了。結合我們上面的原理介紹,可以看出紅色代碼語句(2)配置每輪DMA傳輸個數為8有點問題,傳輸的數據寬度為BYTE,兩個緩沖區各自空間大小為4 BYTE。也就是說每傳輸4個BYTE數據就輪換存儲區重開下一輪傳輸,每輪DMA傳輸的數據個數應該是4而不是8。
現在發帖者反饋的是調整語句(3)便會呈現不同的結果,當把第(3)句的當前存儲區改為Memory0時就會呈現貌似正確的結果。那是為什么呢?
其實這個貌似正確的結果是種巧合的假象。巧合的是在定義BUFFER0和BUFFER1時,因為二者緊鄰在一起定義,編譯器剛好把二者安排在連續的8個字節存儲單元。而發帖者又剛好將每輪DMA傳輸數據個數定義為8個緩沖單元,這意味著每傳輸8個緩沖單元數據才切換緩沖區。當從Memory0即BUFFER0開始傳輸時,連續的8個數據在第一輪就讀了出來,也就是說這8個數據并未經過緩沖區的切換就讀出來了。而當發帖者把第(3)句的第一次使用的當前存儲區改為Memory1時就沒那么幸運了。因為這次DMA從BUFFER1開始連續讀取8個數據單元,讀完BUFFER1內的4個單元后,后面的4個緩存單元就是些不確定的數據,自然一眼就看出結果不對了。
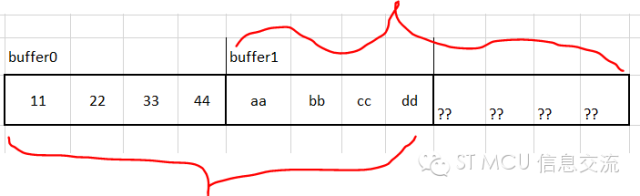
實際上,當把上面紅色代碼語句(2)處的DMA傳輸數據個數調整為4時就結果正常了,至于第(3)句的起始當前緩沖區的選擇無關緊要。
有人在使用DMA雙緩沖模式時,經常為這個傳輸個數糾結,尤其從單緩沖模式轉為雙緩沖模式時。其實,不管單緩沖還是雙緩沖模式,對于整體需要傳輸的數據個數是不會增減的,只是雙緩沖模式由之前的單緩沖模式變成雙緩沖循環。一般來講對于那些無需循環的小數量數據傳輸沒必要使用DMA雙緩沖模式。
相比單緩沖DMA傳輸,雙緩沖模式在設置DMA傳輸數據個數時應更為靈活。比方之前單緩沖DMA傳輸時,每輪傳輸數據個數假設為1024。當改為雙緩沖循環模式時,對應每個緩沖區的DMA傳輸數據個數并不一定要設置為1024,可能設置50、100就能滿足要求,因為這里有兩個存儲區且是不停輪換的。不過,對于這個DMA傳輸數據個數的設置和使用要注意幾點:
1.該數據不要太小,因為DMA傳輸過程中往往伴隨DMA傳輸完成中斷,如果過小會導致中斷頻繁和切換頻繁,并非好事。
2.該數據也不必過大,上面也提過,一味加大緩沖容量對提升傳輸速度并無實質改善。同時也得考慮芯片內存容量的限制與合理使用。
3.盡管DMA雙緩沖模式基于循環傳輸,但實際應用中DMA傳輸請求總有中止或停止的時候。比如,一副圖像數據,完全可能不是剛好結束在事先設置的DMA傳輸數據個數的整數倍的位置點。那么,最后的這批緩沖數據因為未滿而不會發生緩沖交換請求或傳輸完成請求。此時如果不做適當的處理,這批緩沖數據就可能被無意中丟棄掉。所以,我們在程序中需要設計些基于兩次緩沖切換的超時機制,及時收取最后一批緩沖區的數據,以防因不能產生傳輸完成或緩沖切換事件而導致數據丟失的現象。
-
STM32
+關注
關注
2295文章
11032瀏覽量
365226 -
dma
+關注
關注
3文章
576瀏覽量
103309
原文標題:一個關于STM32 DMA雙緩沖的話題
文章出處:【微信號:stmcu832,微信公眾號:茶話MCU】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
PSOC DMA有雙緩沖功能嗎?
EFR32介紹
基于STM32F4系列芯片和STM32CubeF4 HAL庫組織和添加用戶代碼
STM32cubeMX I2S DMA雙緩沖配置

基于STM32H7 EXTI+SPI+DMA雙緩沖應用演示





 工商網監
工商網監
評論