 最嚴峻的挑戰是如何開發能夠應對組合爆炸的算法
最嚴峻的挑戰是如何開發能夠應對組合爆炸的算法
約翰霍普金斯大學教授、計算機視覺的奠基人之一Alan Yuille撰文詳述深度網絡的三大局限及如何破解,提出這一領域最嚴峻的挑戰是如何開發能夠應對組合爆炸的算法。
自2011年AlexNet在ImageNet競賽中“封神”以來,計算機視覺領域的所有突破幾乎都來自深度神經網絡。
深度網絡的成功是非凡的,它們讓視覺研究變得非常受歡迎,戲劇性地增加了學術界和工業界之間的互動,讓視覺技術得以應用于許多廣泛的學科,并產生了許多重要的成果。
但與此同時,深度網絡的局限性也愈加凸顯,它的不可解釋性、容易受到欺騙、過于依賴注釋數據等特性,甚至讓許多研究人員發出“深度學習已死”的呼聲,呼吁關注深度學習之外的其他方法。
本文作者由計算機視覺的奠基人之一、約翰霍普金斯大學教授Alan Yuille和他的學生劉晨曦(Chenxi Liu)撰寫,詳述了深度網絡的局限性和組合爆炸問題對于現實世界應用的重要性。
他們認為該領域最嚴峻的挑戰是開發能夠應對組合爆炸的算法,如果研究人員追求更多樣性的方法和技術,而不僅僅是追逐當前的流行趨勢,這一領域將會得到更快的發展。
Alan Yuille教授
深度學習的歷史
我們正在見證深度學習的第三次崛起。前兩次浪潮——1950 - 1960年代和1980 - 1990年代——引起了相當大的轟動,但卻慢慢失去了動力,因為這些神經網絡既沒有實現它們承諾的性能提升,也沒有幫助我們理解生物視覺系統。
第三次浪潮——2000年至今——則有所不同,因為深度學習在大量基準測試和現實世界應用中已經遠遠超越了其他競爭技術。雖然深度學習的大多數基本想法在第二次浪潮中已經發展起來,但直到大型數據集和強大的計算機(GPU)可用之后,它們的力量才得以釋放。
深度學習的興衰反映了學習算法在學術時髦和流行程度上的變化。第二次浪潮看到了古典人工智能(classical AI)的局限性,其表現是相對于巨大的承諾,AI的表現相當平庸。于是,1980年代中期,AI冬天開始了。
第二次AI浪潮的衰落轉變為支持向量機、kernel methods及相關方法的興起。這時候,我們應當為神經網絡的研究人員鼓掌,盡管也遭遇沮喪,他們仍繼續研究。但是請注意,風水輪流轉。現在論文如果不和神經網絡沾點關系,似乎已經很難發表。這不是一個好現象。我們認為,如果研究人員追求更多樣性的方法和技術,而不僅僅是追逐當前的流行趨勢,這一領域將會得到更快的發展。令人倍感擔憂的是,學生們的AI課程中往往傾向于追逐當前的趨勢,而完全忽略了舊技術。
深度學習三大局限
在2011年AlexNet在Imagenet競賽中擊敗所有競爭對手之前,計算機視覺社區對深度學習持相當懷疑的態度。那時大家還不知道,在接下來的幾年,視覺研究人員將提出各種各樣的神經網絡架構,這些架構在物體分類方面的表現會越來越好。深度學習也很快適應了其他視覺任務,如對象檢測,其中圖像包含一個或多個對象,背景要大得多。
為了完成這項任務,神經網絡在初始階段得到了增強,這一階段對物體可能的位置和大小提出建議。這些方法在PASCAL對象檢測挑戰賽(這是ImageNet之前的主要對象檢測和分類競賽)方面優于以往的最佳方法,即Deformable Part Models。其他深度網絡(Deep Net)架構也在其他經典任務中提供了巨大的性能提升,圖1描述了其中一些任務。
圖1: Deep Nets能夠執行各種各樣的視覺任務。包括:邊界檢測、語義分割、語義邊界、曲面法線、顯著性、人體部位和對象檢測。(來源: https://arxiv.org/abs/1609.02132)
但是,盡管深度學習優于其他技術,它們并非具有通用性。這里,我們列舉了深度學習的三個主要局限。
首先,深度學習幾乎總是需要大量的注釋數據。這使得視覺研究人員的焦點過度集中于容易注釋的任務,而不是重要的任務。
有一些方法可以減少對監督的需要,包括遷移學習、小樣本學習、無監督學習和弱監督學習。但到目前為止,它們的研究成果并沒有像監督學習那樣令人印象深刻。
其次,Deep Nets在基準數據集上表現良好,但在數據集之外的真實世界圖像上,可能會出現嚴重失敗。
所有數據集都存在偏見。這些偏見在早期的視覺數據集中尤其明顯,研究人員很快就學會了利用這些偏見,例如,利用background context(例如,在Caltech101中檢測魚很容易,因為它們是唯一的背景是水的對象)。盡管使用大型數據集和深度網絡,這些問題減少了,但仍然存在。例如,如圖2所示,一個訓練來在ImageNet上檢測“沙發”的Deep Net,如果在訓練數據集中沙發的圖像屬于代表性不足的視角,網絡就可能無法檢測到它們。
特別是,Deep Nets特別難以應付數據集中不經常發生的“罕見事件”。但在現實世界的應用中,這些偏見特別成問題,因為它們可能對應于視覺系統故障可能導致可怕后果的情況。比如,用于訓練自動駕駛汽車的數據集幾乎從不包含“嬰兒坐在路上”的情況。
圖2:UnrealCV讓視覺研究人員能夠輕松地操縱合成場景,例如改變沙發的視角。我們發現Faster-RCNN檢測沙發的平均精度(AP)在0.1到1.0之間,對視角的敏感度極高。這可能是因為訓練中的偏見導致Faster-RCNN偏向于特定的視角。
第三,Deep Nets對圖像中的變化過于敏感,而這種變化不會欺騙人類觀察者。Deep Nets不僅對導致圖像中難以察覺的變化的標準對抗性攻擊敏感,而且對上下文的變化也過于敏感。
圖3顯示了在一張叢林猴子的照片中ps上一把吉他的效果。這導致深度網絡將猴子誤認為人類,同時將吉他誤認為鳥,大概是因為它認為人類比猴子更可能攜帶吉他,而鳥類比吉他更可能出現在附近的叢林中。最近的研究提供了很多關于Deep Nets對環境過度敏感的例子,例如把一頭大象放在房間里。
圖3:添加遮蔽體會導致深度網絡失敗。左:摩托車的遮擋讓AI把一只猴子誤認為人類。中:自行車的遮擋讓AI把猴子誤認為人類,同時叢林背景導致AI將自行車把手誤認為是鳥。右:吉他把猴子變成了人,而叢林把吉他變成了鳥。(來源:https://arxiv.org/abs/1711.04451)
這種對上下文的過度敏感也可以歸因于數據集大小的局限。對于任何對象,數據集中只會出現有限數量的上下文,因此神經網絡會偏向于它們。例如,在早期的圖像字幕數據集中,AI觀察到長頸鹿只出現在樹木附近,因此它生成的圖像說明不會提到沒有樹木的圖像中的長頸鹿,即使它們圖像中是最主要的對象。
捕獲各種各樣的上下文的困難,以及探索大范圍干擾因素的需要,對于像Deep Nets這樣的數據驅動方法來說是一個很大的問題。似乎要確保網絡能夠處理所有這些問題,就需要無限大的數據集,這對訓練和測試數據集都提出了巨大的挑戰。下面我們將討論這些問題。
當大數據集不夠大時——組合爆炸
上面提到的問題都不是破壞深度學習的因素,但我們認為這些是問題的早期預警信號。也就是說,真實世界的圖像集是combinatorially large的,因此任何數據集,無論它有多大,都很難代表真實世界的復雜性。
一個combinatorially large的集合意味著什么呢?想象一下,通過從對象詞典中選擇對象并將它們放在不同的組合中來構建一個視覺場景。這顯然可以有指數級數量的方式。即使是單個對象的圖像,我們也可以獲得類似的復雜度,因為可以有無數種方式將它部分遮擋。我們還可以用無數種方式改變一個對象的背景。
雖然人類很自然地能適應視覺環境的變化,但Deep Nets更敏感,更容易出錯,如圖3所示。
我們注意到,這種組合爆炸(combinatorial explosion)可能不會發生在某些視覺任務上,深度網絡在醫學圖像應用上可能會非常成功,因為醫學圖像中上下文變化相對較小(例如,胰腺總是非常接近十二指腸)。但是對于許多真實世界的應用程序,如果沒有指數級大的數據集,就無法捕捉真實世界的復雜性。
這帶來了巨大的挑戰,因為在有限數量的隨機抽取樣本上訓練和測試模型的標準范式變得不切實際了,因為它們永遠不會大到足以代表數據的底層分布。這迫使我們解決兩個新的問題:
我們如何在有限大小的數據集上訓練算法,使它們能夠在捕捉真實世界的組合復雜性所需的真正龐大的數據集上表現良好?
如果我們只能在有限的子集上測試這些算法,如何有效地測試它們,以確保它們在這些龐大的數據集中工作?
克服組合爆炸問題
像目前形式的Deep Nets這樣的方法似乎不太可能處理組合爆炸。數據集可能永遠無法大到足以訓練或測試它們。下面我們概述一些可能的解決方案。
組合性
組合性(Compositionality)是一種普遍的原則,用詩意的方式描述,它是“一種信念的體現,這種信念認為世界是可知的,人們可以將事物拆解,理解它們,并在精神上隨意重新組合它們”。關鍵的假設是,結構是按照一組語法規則,由更基本的子結構分層組成的。這表明,子結構和語法可以從有限的數據中學習,但將推廣到組合情境(combinatorial situations)。
與深度網絡不同的是,組合模型需要結構化的表示來明確它們的結構和子結構。組合模型能夠超越所見數據進行推斷、對系統進行推理、進行干預、進行診斷以及基于相同的底層知識結構回答許多不同問題。
引用Stuart Geman的話來說:“世界是組合的,不然,上帝就是存在的。”(The world is compositional or God exists),因為如果世界不是組合的,上帝似乎有必要手工制作人類智能。我們注意到,雖然深度網絡捕獲了一種組合的形式,例如,高級特征是由較低級別特征的響應組成的,但它們不是我們在本文中所指的意義上的組合性。
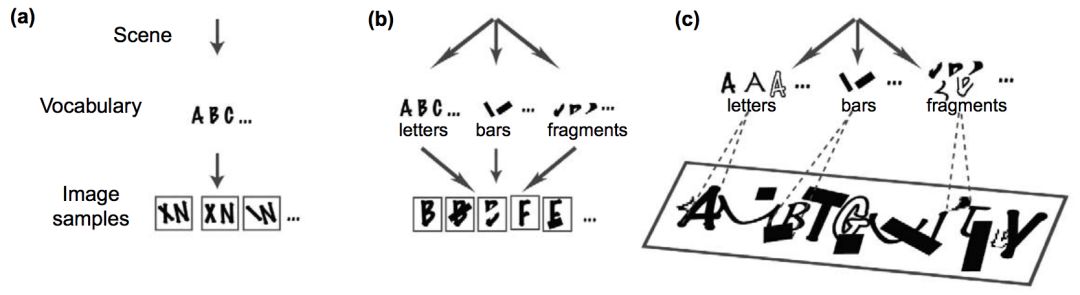
圖4:從(a)到(b)到(c),使用了越來越多的可變性和遮蔽。特別地,(c)是一個組合大數據集的示例,它本質上與驗證碼是一樣的。有趣的是,關于驗證碼的研究表明,組合模型的性能很好,而深度網絡的性能要差得多。(來源:https://www.ncbi.nlm.nih.gov/pubmed/16784882)
圖4說明了組合性的一個例子,涉及到合成分析(analysis by synthesis)。
組合模型的這些概念優勢已經在視覺問題上得到了證明,例如使用相同的底層模型執行多個任務的能力,以及識別驗證碼的能力。
其他非視覺問題的示例也說明了同樣的問題。訓練Deep Nets進行智商測試的嘗試沒有成功。在這個任務中,目標是在一個3x3網格中預測丟失的圖像,其中會給出其他8個網格的圖像,并且基礎規則是組合的(并且可能存在干擾項)。
相反,對于一些自然語言應用,神經模塊網絡(Neural Module Networks)的動態架構似乎足夠靈活,可以捕捉到一些有意義的組合,其性能優于傳統的深度學習網絡。事實上,我們最近證明,經過聯合訓練后,各個模塊確實實現了它們預期的組合功能(如AND、OR、FILTER(RED)等)。
組合模型具有許多理想的理論特性,例如可解釋性,并且能夠生成樣本。這使得錯誤更容易診斷,因此它們比像Deep Nets這樣的黑盒方法更難被欺騙。但是學習組合模型是很困難的,因為它需要學習構建塊和語法(甚至語法的本質也是有爭議的)。此外,為了進行合成分析,他們需要具有對象和場景結構的生成模型。將分布放在圖像上也具有挑戰性,除了人臉、字母和常規紋理等少數例外。
更重要的是,處理組合爆炸需要學習三維世界的因果模型,以及這些模型如何生成圖像。對人類嬰兒的研究表明,他們是通過建立因果模型來學習的,這些因果模型可以預測他們所處環境的結構,包括樸素物理學。這種因果關系的理解使我們能夠從有限的數據中學習,并真正地推廣到新情況。這類似于將牛頓定律與托勒密的地心說模型進行對比,前者用最少的自由參數給出因果關系的理解,后者給出非常準確的預測,但需要大量的數據來確定其細節(即本輪)。
組合數據的測試
在真實世界的組合復雜性上測試視覺算法的一個潛在挑戰是,我們只能在有限的數據上進行測試。
博弈論通過關注最壞情況而非平均情況來解決這個問題。如前所述,如果數據集沒有捕捉到問題的組合復雜性,那么有限大小數據集上的平均情況結果可能沒有意義。如果我們的目標是為自動駕駛汽車開發視覺算法,或者利用醫學圖像診斷癌癥,算法的失敗就可能帶來嚴重后果,那么關注最糟糕的情況顯然也是有意義的。
如果能夠在低維空間中捕捉到故障模式,如立體視覺的危險因素,那么我們可以用計算機圖形學和網格搜索來研究它們。但是對于大多數視覺任務,特別是涉及組合數據的任務,很難識別出少數可以分離和測試的危險因素。
一種策略是將標準對抗性攻擊的概念擴展到包括非局部結構,允許對圖像或場景造成變化的復雜操作,例如通過遮擋或改變被觀察對象的物理屬性,但不顯著影響人類感知。
將這種策略擴展到處理組合數據的視覺算法仍然非常具有挑戰性。但是,如果算法在設計時考慮到了組合性,那么它們的顯式結構可能使診斷它們和確定它們的故障模式成為可能。
最嚴峻的挑戰
幾年前,Aude Oliva和Alan Yuille(本文第一作者)共同組織了一個由NSF贊助的計算機視覺前沿研討會(MIT CSAIL 2011)。會議鼓勵坦誠交換意見,尤其在計算機視覺領域深度網絡的潛力方面存在巨大的分歧。
Yann LeCun大膽地預言,在不久的將來,每個人都將使用深度網絡。
他是對的。深度網絡的成功是非凡的,它們讓視覺研究變得非常受歡迎,戲劇性地增加了學術界和工業界之間的互動,讓視覺技術得以應用于許多廣泛的學科,并產生了許多重要的成果。
但是,盡管深度網絡取得了成功,但在實現通用人工智能和理解生物視覺系統的目標之前,仍必須克服巨大的挑戰。
我們的擔憂與最近Gary Marcus等人對深度網絡的批判中提到的類似。可以說,最嚴峻的挑戰是如何開發能夠應對組合爆炸的算法,研究人員需要在越來越現實的條件下處理越來越復雜的視覺任務。雖然深度網絡肯定是解決方案的一部分,但我們認為,我們還需要包含組合原則和因果模型的補充方法,以捕捉數據的基本結構。此外,面對組合爆炸,我們需要重新思考如何訓練和評估視覺算法。
-
人工智能
+關注
關注
1797文章
47919瀏覽量
240966 -
計算機視覺
+關注
關注
8文章
1701瀏覽量
46180 -
數據集
+關注
關注
4文章
1211瀏覽量
24890
原文標題:破局!Alan Yuille:深度學習關鍵在于克服組合爆炸
文章出處:【微信號:AI_era,微信公眾號:新智元】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦





 工商網監
工商網監
評論