 神經網絡發展的重要性
神經網絡發展的重要性

摘要:任何人工智能的難題都可以被解決。唯一能證明這一論斷成立的是這樣一個事實:自然界通過進化已經解決了這些難題。但在20世紀50年代就已經存在各種暗示,如果AI研究者能夠選擇完全不同于符號處理的方式,計算機會如何表現出智能行為。
第一條暗示是,我們的大腦是強大的模式識別器。我們的視覺系統可以在1/10秒內識別混亂場景中的對象,即使我們可能從未見過那個特定的對象,也不論該對象在什么位置,多大尺寸,以什么角度面對我們。簡而言之,我們的視覺系統就像一臺以“識別對象”作為單一指令的計算機。
第二條暗示是,我們的大腦可以通過練習來學會如何執行若干艱巨的任務,比如彈鋼琴、掌握物理學知識。大自然使用通用的學習方法來解決特殊的問題,而人類則是頂尖的學習者。這是我們的特殊能力。我們大腦皮層的結構整體上是相似的,并且我們所有的感受系統和運動系統都有深度學習網絡。
第三條暗示是,我們的大腦并沒有充斥著邏輯或規則。當然,我們可以學習邏輯思維或遵守規則,但必須要經過大量的訓練,而我們當中的大多數人對此并不在行。這一點可以通過人們在一個叫作“華生選擇任務”(Wason selection task)的邏輯謎題上的典型表現來進行說明(見圖3–1)。
圖3–1
圖3-1這四張卡片,每張都是一面有數字,另一面涂滿了顏色。要測試以下命題為真:一張卡片在一面顯示為偶數,那它的另一面就是紅色的。你需要翻哪(幾)張牌呢?圖片來源:“華生選擇任務”,維基百科。
正確的選擇是正面為數字“8”,背面為棕色的卡片。在最初的研究中,只有10%的受試者給出了正確的答案。但是,當給這項邏輯測試加上了熟悉的背景信息時,大多數受試者都能很快找出正確答案(見圖3–2)。
圖3–2
推理似乎是基于特定領域的,我們對該領域越熟悉,就越容易解決其中的問題。經驗使得在一個領域內進行推理變得更容易,因為我們可以用已有的例子來下意識地得到解決方案。例如,在物理學中,我們通過解決各種問題,而不是通過背誦公式,來學習電磁學領域的知識。如果人類的智能是完全基于邏輯的,那么它應該是跨領域的通用智能,但事實并非如此。
圖3-2每張卡片都是一面有一個年齡數字,另一面印著一種飲料。需要翻哪(幾)張牌才能檢驗這條法律:如果你正在喝酒,那說明你一定超過18歲了?圖片來源:“華生選擇任務”,維基百科。
第四條暗示是,我們的大腦充滿了數百億個小小的神經元,每時每刻都在互相傳遞信息。這表明,要解決人工智能中的難題,我們應該研究具有大規模并行體系結構的計算機,而不是那些具有馮·諾依曼數字體系結構,每次只能獲取和執行一個數據或指令的計算機。是的,圖靈機在被給予足夠內存和時間的條件下,的確可以計算任何可計算的函數,但自然界必須實時解決問題。要做到這一點,它利用了大腦的神經網絡,就像地球上最強大的計算機一樣,它們具有大量的并行處理器。只有能有效運行的算法,最終才能在自然選擇中勝出。
深度學習的起點
20世紀五六十年代,在諾伯特·維納(Norbert Wiener)提出基于機器和生物中的通信和控制系統的控制論之后不久,學界對自組織系統開始產生了濃厚的興趣。而其中一個獨創性產物便是由奧利弗·塞弗里奇(Oliver Selfridge) 創造的Pandemonium(鬼域)。這是一個圖案識別設備,其中進行特征檢測的“惡魔”通過互相競爭,來爭取代表圖像中對象的權利(深度學習的隱喻,見圖3–3)。斯坦福大學的伯納德·威德羅(Bernard Widrow)和他的學生泰德·霍夫(Ted Hoff)發明了LMS(最小均方)學習算法,它與其后繼算法一起被廣泛用于自適應信號處理,例如噪聲消除、財務預測等應用。在這里, 我將重點關注一位先驅弗蘭克·羅森布拉特(Frank Rosenblatt)(圖3–4),他發明的感知器是深度學習的前身。
圖3-3 Pandemonium。奧利弗·塞弗里奇認為,大腦中有惡魔負責從感官輸入中先后提取更復雜的特征和抽象概念,從而做出決定。如果每個級別的惡魔與前一個級別的輸入相匹配,則會激動不已。做決定的惡魔需要衡量所有信息傳遞者的興奮程度和重要性。這種形式的證據評估是對當前多層次深度學習網絡的隱喻。圖片來源:Peter H. Lindsay and Donald A. Norman, Human Information Processing: An Introduction to Psychology, 2nded. (New York: Academic Press, 1977),圖3-1。維基共享資源:https://commons.wikimedia.org/wiki/File:Pande.jpg。
圖3-4深思中的康奈爾大學教授弗蘭克·羅森布拉特,他發明了感知器。作為深度學習網絡的早期雛形,感知器是能夠將圖像進行分類的簡易學習算法。圖中文章是1958年7月8日在《紐約時報》上發表的一篇來自合眾國際社(UPI)的報道。感知器在1959年完成時預計花費了10萬美元,相當于今天的100萬美元。IBM 704計算機在1958年價值200萬美元,相當于現在的2000萬美元,可以實現每秒12000次的乘法運算,這在當時已經是極快的速度了。不過相比之下,現在價格要低得多的三星Galaxy S 6手機每秒可以執行340億次操作,速度要快100萬倍以上。圖片來源:George Nagy。
從樣本中學習
盡管我們對大腦功能缺乏足夠的了解,但神經網絡的AI先驅們依然依靠著神經元的繪圖以及它們相互連接的方式,進行著艱難的摸索。康奈爾大學的弗蘭克·羅森布拉特是最早模仿人體自動圖案識別視覺系統架構的人之一。他發明了一種看似簡單的網絡感知器(perceptron),這種學習算法可以學習如何將圖案進行分類,例如識別字母表中的不同字母。算法是為了實現特定目標而按步驟執行的過程,就像烘焙蛋糕的食譜一樣。
如果你了解了感知器如何學習圖案識別的基本原則,那么你在理解深度學習工作原理的路上已經成功了一半。感知器的目標是確定輸入的圖案是否屬于圖像中的某一類別(比如貓)。方框3.1解釋了感知器的輸入如何通過一組權重,來實現輸入單元到輸出單元的轉換。權重是對每一次輸入對輸出單元做出的最終決定所產生影響的度量,但是我們如何找到一組可以將輸入進行正確分類的權重呢?
工程師解決這個問題的傳統方法,是根據分析或特定程序來手動設定權重。這需要耗費大量人力,而且往往依賴于直覺和工程方法。另一種方法則是使用一種從樣本中學習的自動過程,和我們認識世界上的對象的方法一樣。需要很多樣本來訓練感知器,包括不屬于該類別的反面樣本,特別是和目標特征相似的,例如,如果識別目標是貓,那么狗就是一個相似的反面樣本。這些樣本被逐個傳遞給感知器,如果出現分類錯誤,算法就會自動對權重進行校正。
這種感知器學習算法的美妙之處在于,如果已經存在這樣一組權重,并且有足夠數量的樣本,那么它肯定能自動地找到一組合適的權重。在提供了訓練集中的每個樣本,并且將輸出與正確答案進行比較后,感知器會進行遞進式的學習。如果答案是正確的,那么權重就不會發生變化。但如果答案不正確(0被誤判成了1,或1被誤判成了0),權重就會被略微調整,以便下一次收到相同的輸入時,它會更接近正確答案(見方框3.1)。這種漸進的變化很重要,這樣一來,權重就能接收來自所有訓練樣本的影響,而不僅僅是最后一個。
如果對感知器學習的這種解釋還不夠清楚,我們還可以通過另一種更簡潔的幾何方法,來理解感知器如何學習對輸入進行分類。對于只有兩個輸入單元的特殊情況,可以在二維圖上用點來表示輸入樣本。每個輸入都是圖中的一個點,而網絡中的兩個權重則確定了一條直線。感知器學習的目標是移動這條線,以便清楚地區分正負樣本(見圖3–5)。對于有三個輸入單元的情況,輸入空間是三維的,感知器會指定一個平面來分隔正負訓練樣本。在一般的情況下,即使輸入空間的維度可能相當高且無法可視化,同樣的原則依然成立。
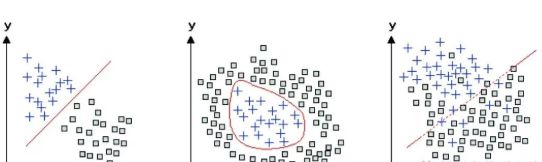
圖3-5關于感知器如何區分兩個對象類別的幾何解釋。這些對象有兩個特征,例如尺寸和亮度,它們依據各自的坐標值(x,y)被繪制在每張圖上。左邊圖中的兩種對象(加號和正方形)可以通過它們之間的直線分隔開;感知器能夠學習如何進行這種區分。其他兩個圖中的兩種對象不能用直線隔開,但在中間的圖中,兩種對象可以用曲線分開。而右側圖中的對象必須舍棄一些樣本才能分隔成兩種類型。如果有足夠的訓練數據,深度學習網絡就能夠學習如何對這三個圖中的類型進行區分。
最終,如果解決方案是可行的,權重將不再變化,這意味著感知器已經正確地將訓練集中的所有樣本進行了分類。但是,在所謂的“過度擬合”(overfitting)中,也可能沒有足夠的樣本,網絡僅僅記住了特定的樣本,而不能將結論推廣到新的樣本。為了避免過度擬合,關鍵是要有另一套樣本,稱為“測試集”(test set),它沒有被用于訓練網絡。訓練結束時,在測試集上的分類表現,就是對感知器是否能夠推廣到類別未知的新樣本的真實度量。泛化(generalization)是這里的關鍵概念。在現實生活中,我們幾乎不會在同樣的視角看到同一個對象,或者反復遇到同樣的場景,但如果我們能夠將以前的經驗泛化到新的視角或場景中, 我們就可以處理更多現實世界的問題。
利用感知機區分性別
舉一個用感知器解決現實世界問題的例子。想想如果去掉頭發、首飾和第二性征,比如男性比女性更為突起的喉結,該如何區分男性和女性的面部。比阿特麗斯·哥倫布(Beatrice Golomb)是1990年我實驗室里的一名博士后研究員,她利用一個數據庫中的大學生面部照片作為感知器的輸入,經過訓練的感知器能以81%的準確度對面部的性別進行分類(見圖3–6)。而對于感知器難以分類的面部,人類也同樣很難做出區分。我實驗室的成員在同一組人的面部識別上達到了88%的平均準確度。比阿特麗斯還訓練了多層感知器,其準確度達到了92%,9比我實驗室的成員還要準確。她在1991年的NIPS大會上發表的演講中總結道:“經驗可以提高性能,這表明實驗室的研究人員需要花更多時間來進行性別鑒定的工作。”她把她的多層感知器叫作“SEXNET”(性別網絡)。在問答環節,有人問是否可以使用SEXNET來檢測異裝癖者的面孔。“可以。”比阿特麗斯這樣回答。而NIPS大會的創始人愛德華·波斯納(Edward Posner)辯駁道:“那就應該叫DRAGNET(法網)。”
圖3-6這張臉屬于男性還是女性?人們通過訓練感知器來辨別男性和女性的面孔。來自面部圖像(上圖)的像素乘以相應的權重(下圖),并將該乘積的總和與閾值進行比較。每個權重的大小被描繪為不同顏色像素的面積。正值的權重(白色)表現為男性,負值的權重(黑色)傾向于女性。鼻子寬度,鼻子和嘴之間區域的大小,以及眼睛區域周圍的圖像強度對于區分男性很重要,而嘴和顴骨周圍的圖像強度對于區分女性更重要。圖片來源:M. S. Gray,D. T. Lawrence,B. A. Golomband T.J.Sejnowski,“A Perceptron Reveals the Face of Sex,” Neural Computation 7 ( 1995 ):1160 - 1164,圖1。
區分男性與女性面部的工作有趣的一點是,雖然我們很擅長做這種區分,卻無法確切地表述男女面部之間的差異。由于沒有單一特征是決定性的,因此這種模式識別問題要依賴于將大量低級特征的證據結合起來。感知器的優點在于,權重提供了對性別區分最有幫助的面部的線索。令人驚訝的是,人中(即鼻子和嘴唇之間的部分)是最顯著的特征,大多數男性人中的面積更大。眼睛周圍的區域(男性較大)和上頰(女性較大)對于性別分類也有著很高的信息價值。感知器會權衡來自所有這些位置的證據來做出決定,我們也是這樣來做判定的, 盡管我們可能無法描述出到底是怎么做到的。
1957年羅森布拉特對“感知器收斂定理”的證明是一個突破,他的演示令人印象深刻。在美國海軍研究辦公室(Office of Naval Research)的支持下,他搭建了一個以400個光電單元作為輸入的定制硬件模擬計算機,其權重是由電機調整的可變電阻電位器。模擬信號隨著時間連續變化,就像黑膠唱片中的信號一樣。用一組圖片集(其中部分圖片中有坦克,另外一部分則沒有)進行訓練,羅森布拉特的感知器即使在新圖像中也能準確識別坦克。這一成果經《紐約時報》報道后引起了轟動(見圖3–4)。
感知器激發了對高維空間中模式分離的美妙的數學分析。當那些點存在于有數千個維度的空間中時,我們就無法依賴在生活的三維空間里對點和點之間距離的直覺。俄羅斯數學家弗拉基米爾·瓦普尼克(Vladimir Vapnik)在這種分析的基礎上引入了一個分類器, 稱為“支持向量機”(Support Vector Machine),它將感知器泛化,并被大量用于機器學習。他找到了一種自動尋找平面的方法,能夠最大限度地將兩個類別的點分開(見圖3–5,線性)。這讓泛化對空間中數據點的測量誤差容忍度更大,再結合作為非線性擴充的“內核技巧”(kernel trick),支持向量機算法就成了機器學習中的重要支柱。
一個被低估的神經網路
但是有一個限制,使得感知器的研究存在問題。上面的假設“如果存在這樣的權重集合”提出了一個這樣的困惑,即什么樣的問題可能或不可能被感知器解決。令人尷尬的是,在二維平面中,簡單分布的點不能被感知器分開(見圖3–5,非線性)。事實證明,坦克感知器不是坦克分類器,而是天氣分類器。a對圖像中的坦克進行分類要困難得多,而事實上,它不能用感知器來完成。這也表明,即使感知器學到了一些東西,也可能不是你認為它應該學到的那些東西。壓倒感知器的最后一根稻草是馬文·明斯基和西摩爾·帕普特在1969年發表的數學專著《感知器》(Perceptrons)。 他們明確的幾何分析表明,感知器的能力是有限的:它們只能區分線性可分的類別(見圖3–5)。
這本書的封面展示了明斯基和帕普特證明的感知器無法解決的幾何問題(見圖3–7)。盡管在書的末尾,明斯基和帕普特考慮了將單層感知器進行泛化成為多層感知器的前景, 但他們懷疑可能沒有辦法訓練這些更強大的感知器。不幸的是,許多人對他們的論斷堅信不疑,于是這個研究領域漸漸被人們遺忘,直到20世紀80年代,新一代神經網絡研究人員開始重新審視這個問題。
在感知器中,每個輸入都獨立地向輸出單元提供證據。但是,如果需要依靠多個輸入的組合來做決定,那會怎樣呢?這就是感知器無法區分螺旋結構是否相連的原因:單個像素并不能提供它是在內部還是外部的位置信息。盡管在多層前饋神經網絡中,可以在輸入和輸出單元之間的中間層中形成多個輸入的組合,但是在20世紀60年代,還沒有人知道如何訓練簡單到中間只有一層“隱藏單元”(hiddenunits)的神經網絡。
弗蘭克·羅森布拉特和馬文·明斯基曾是紐約市布朗克斯科技高中的同班同學。他們在科學會議上為各自迥異的人工智能研究方法展開了辯論,而與會者更傾向于明斯基的方法。盡管存在差異,但他們二人對我們理解感知器都有著重要貢獻,而這正是深度學習的起點。
羅森布拉特在1971年死于一次駕船事故,年僅43歲,當時正值人們幾乎一邊倒地反對感知器的時期。有傳言說他可能是自殺,但也可能只是一次不幸的出游。15不可否認的是,一個發現了利用神經網絡進行計算的新方式的英雄時代已經謝幕;又過了整整一代人的時間,羅森布拉特開創性努力的承諾才得以實現。
未來智能實驗室是人工智能學家與科學院相關機構聯合成立的人工智能,互聯網和腦科學交叉研究機構。
未來智能實驗室的主要工作包括:建立AI智能系統智商評測體系,開展世界人工智能智商評測;開展互聯網(城市)云腦研究計劃,構建互聯網(城市)云腦技術和企業圖譜,為提升企業,行業與城市的智能水平服務。
-
神經網絡
+關注
關注
42文章
4814瀏覽量
103695 -
人工智能
+關注
關注
1807文章
49029瀏覽量
249681
原文標題:神經網絡的黎明
文章出處:【微信號:AItists,微信公眾號:人工智能學家】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
神經網絡專家系統在電機故障診斷中的應用
NVIDIA實現神經網絡渲染技術的突破性增強功能
BP神經網絡的調參技巧與建議
BP神經網絡與卷積神經網絡的比較
如何優化BP神經網絡的學習率
BP神經網絡的優缺點分析
什么是BP神經網絡的反向傳播算法
BP神經網絡與深度學習的關系
人工神經網絡的原理和多種神經網絡架構方法






 工商網監
工商網監
評論