") 爬取b站上的所有短評(píng)進(jìn)行分析,用數(shù)據(jù)說明為什么這部動(dòng)漫會(huì)如此受歡迎
爬取b站上的所有短評(píng)進(jìn)行分析,用數(shù)據(jù)說明為什么這部動(dòng)漫會(huì)如此受歡迎
動(dòng)漫《工作細(xì)胞》最終話已經(jīng)更新完畢,這部動(dòng)漫在 b 站上評(píng)分高達(dá) 9.7。除了口碑之外,熱度也居高不下,更值得關(guān)注的是連很多平時(shí)不關(guān)注動(dòng)漫的小伙伴也加入了追番大軍。這次我們的目標(biāo)是爬取 b 站上的所有短評(píng)進(jìn)行分析,用數(shù)據(jù)說明為什么這部動(dòng)漫會(huì)如此受歡迎。
一、工作細(xì)胞
《工作細(xì)胞》改編自清水茜老師的同名漫畫,由 David Production 制作。眾所周知,日本 ACG 作品向來信奉著“萬物皆可萌”的原則。前有《黑塔利亞》,后有《艦隊(duì)Collection》和《獸娘動(dòng)物園》,分別講述了將國(guó)家,戰(zhàn)艦和動(dòng)物擬人化后的故事。而在《工作細(xì)胞》里擬人的對(duì)象則輪到了我們的細(xì)胞。
這是一個(gè)發(fā)生在人體內(nèi)的故事:人的細(xì)胞數(shù)量,約為37兆2千億個(gè)。其中包括了我們的女主角:一個(gè)副業(yè)是運(yùn)輸氧氣,主業(yè)是迷路的紅血球。
男主角:一個(gè)作者懶得涂色但武力值 max 的白血球。兩人一見面就并肩戰(zhàn)斗,分別的時(shí)候更是滿天粉紅氣泡。
雖然嘴上說著:不會(huì),我只是千千萬萬個(gè)白細(xì)胞中的一員。身體卻很誠實(shí),從第一集偶遇女主到最后一集,每一集都充滿了狗糧的味道。37兆分之一的緣分果然妙不可言。
除了男女主角,配角們的人氣也都很高。連反派 boss 癌細(xì)胞都有人喜歡,主要還是因?yàn)樯硎栏腥?臉長(zhǎng)得好。當(dāng)然人氣最!最!最!高的還是我們奶聲奶氣的血小板。
據(jù)宅男們反映:“看了這么多番。只有這一部的老婆是大家真正擁有的。”不僅有,還有很多。除了新穎的科普形式,這部番令人感觸最深的是:我們每一個(gè)人都不是孤獨(dú)的個(gè)體,有37兆個(gè)只屬于我們的細(xì)胞和我們一同工作不息。每當(dāng)頹唐和失意的時(shí)候,為了那些為了保護(hù)你而戰(zhàn)斗不止的免疫細(xì)胞,為了萌萌的老婆們也要振作起來啊。
《工作細(xì)胞》的成功并不是一個(gè)偶然,而是眾多因素共同作用的結(jié)果。下面從數(shù)據(jù)的角度分析它成為今年7月播放冠軍的原因。
謝謝宇哥對(duì)這部分的貢獻(xiàn),顯然超出我的能力范圍!
二、爬蟲
首先要做的是爬取 b 站的所有短評(píng),包括評(píng)論用戶名、評(píng)論時(shí)間、星級(jí)(評(píng)分)、評(píng)論內(nèi)容、點(diǎn)贊數(shù)等內(nèi)容,本部分內(nèi)容為爬蟲代碼的說明,不感興趣的讀者可以直接跳過,閱讀下一部分的分析。

爬的過程寫了很久,b站短評(píng)不需要登陸直接就可以爬,剛開始用類似之前爬豆瓣的方法,用 Selenium+xpath 定位爬

但 b 站短評(píng)用這種方法并不好處理。網(wǎng)站每次最多顯示 20 條短評(píng),滾動(dòng)條移動(dòng)到最下面才會(huì)加載之后的 20 條,所以剛開始用了每次爬完之后將定位到當(dāng)前爬的位置的方法,這樣定位到當(dāng)前加載的最后一條時(shí),就會(huì)加載之后的 20 條短評(píng)。
邏輯上是解決了這個(gè)問題,但真的爬的時(shí)候就出現(xiàn)了問題,一個(gè)是爬的慢,20條需要十來秒的樣子,這個(gè)沒關(guān)系,大不了爬幾個(gè)小時(shí),但問題是辛辛苦苦爬了兩千多條之后,就自動(dòng)斷了,不知道是什么原因,雖然之前爬的數(shù)據(jù)都存下來了,但沒法接著斷開的地方接著爬,又要重新開始,還不知道會(huì)不會(huì)又突然斷,所以用這種方法基本就無解了。代碼附在下面,雖然是失敗的,但也可以爬一些評(píng)論下來,供參考。
1#-*-coding:utf-8-*- 2""" 3CreatedonMonSep1019:36:242018 4""" 5fromseleniumimportwebdriver 6importpandasaspd 7fromdatetimeimportdatetime 8importnumpyasnp 9importtime10importos1112os.chdir('F:\python_study\pachong\工作細(xì)胞')13defgethtml(url):1415browser=webdriver.PhantomJS()16browser.get(url)17browser.implicitly_wait(10)18return(browser)1920defgetComment(url):2122browser=gethtml(url)23i=124AllArticle=pd.DataFrame(columns=['id','author','comment','stars1','stars2','stars3','stars4','stars5','unlike','like'])25print('連接成功,開始爬取數(shù)據(jù)')26whileTrue:2728xpath1='//*[@id="app"]/div[2]/div[2]/div/div[1]/div/div/div[4]/div/div/ul/li[{}]'.format(i)29try:30target=browser.find_element_by_xpath(xpath1)31except:32print('全部爬完')33break3435author=target.find_element_by_xpath('div[1]/div[2]').text36comment=target.find_element_by_xpath('div[2]/div').text37stars1=target.find_element_by_xpath('div[1]/div[3]/span/i[1]').get_attribute('class')38stars2=target.find_element_by_xpath('div[1]/div[3]/span/i[2]').get_attribute('class')39stars3=target.find_element_by_xpath('div[1]/div[3]/span/i[3]').get_attribute('class')40stars4=target.find_element_by_xpath('div[1]/div[3]/span/i[4]').get_attribute('class')41stars5=target.find_element_by_xpath('div[1]/div[3]/span/i[5]').get_attribute('class')42date=target.find_element_by_xpath('div[1]/div[4]').text43like=target.find_element_by_xpath('div[3]/div[1]').text44unlike=target.find_element_by_xpath('div[3]/div[2]').text454647comments=pd.DataFrame([i,author,comment,stars1,stars2,stars3,stars4,stars5,like,unlike]).T48comments.columns=['id','author','comment','stars1','stars2','stars3','stars4','stars5','unlike','like']49AllArticle=pd.concat([AllArticle,comments],axis=0)50browser.execute_script("arguments[0].scrollIntoView();",target)51i=i+152ifi%100==0:53print('已爬取{}條'.format(i))54AllArticle=AllArticle.reset_index(drop=True)55returnAllArticle5657url='https://www.bilibili.com/bangumi/media/md102392/?from=search&seid=8935536260089373525#short'58result=getComment(url)59#result.to_csv('工作細(xì)胞爬蟲.csv',index=False)
這種方法爬取失敗之后,一直不知道該怎么處理,剛好最近看到網(wǎng)上有大神爬貓眼評(píng)論的文章,照葫蘆畫瓢嘗試了一下,居然成功了,而且爬的速度也很快,十來分鐘就全爬完了,思路是找到評(píng)論對(duì)應(yīng)的 Json 文件,然后獲取 Json 中的數(shù)據(jù),過程如下。
在 Google 瀏覽器中按 F12 打開卡發(fā)者工具后,選擇 Network

往下滑動(dòng),會(huì)發(fā)現(xiàn)過一段時(shí)間,會(huì)出現(xiàn)一個(gè) fetch,右鍵打開后發(fā)現(xiàn),里面就是 20 條記錄,有所有我們需要的內(nèi)容,Json格式。

所以現(xiàn)在需要做的就是去找這些Json文件的路徑的規(guī)律。多看幾條之后,就發(fā)現(xiàn)了規(guī)律:
第一個(gè)Json:
https://bangumi.bilibili.com/review/web_api/short/list?media_id=102392&folded=0&page_size=20&sort=0
第二個(gè)Json:
https://bangumi.bilibili.com/review/web_api/short/list?media_id=102392&folded=0&page_size=20&sort=0&cursor=76553500953424
第三個(gè)Json:
https://bangumi.bilibili.com/review/web_api/short/list?media_id=102392&folded=0&page_size=20&sort=0&cursor=76549205971454
顯然所有的Json路徑的前半部分都是一樣,都是在第一條Json之后加上不同的 cursor = xxxxx,所以只要能找到cursor值的規(guī)律,就可以用循環(huán)的辦法,爬完所有的Json,這個(gè)值看上去沒什么規(guī)律,最后發(fā)現(xiàn),每一個(gè)Json路徑中 cursor 值就藏在前一個(gè)Json的最后一條評(píng)論中

在 python 中可以直接把 JSON 轉(zhuǎn)成字典,cursor 值就是最后一條評(píng)論中鍵 cursor 的值,簡(jiǎn)直不要太容易。
所以爬的思路就很清晰了,從一個(gè)Json開始,爬完 20 條評(píng)論后,獲取最后一個(gè)評(píng)論中的cursor值,更改路徑之后獲取第二個(gè)Json,重復(fù)上面的過程,直到爬完所有的Json。
至于如何知道爬完了所有Json,也很容易,每個(gè)Json中一個(gè)total鍵,表示了當(dāng)前一共有多少條評(píng)論,所以只需要寫一個(gè)while循環(huán),當(dāng)爬到的評(píng)論數(shù)達(dá)到total值時(shí)停止。
爬的過程中還發(fā)現(xiàn),有些Json中的評(píng)論數(shù)不夠 20 條,如果每次用 20 去定位,中間會(huì)報(bào)錯(cuò)停止,需要注意一下。所以又加了一行代碼,每次獲得Json后,通過 len() 函數(shù)得到當(dāng)前Json中一共包含多少條評(píng)論,cursor 在最后一個(gè)評(píng)論中。
以上是整個(gè)爬的思路,我們最終爬到以下信息:

需要說明的地方,一個(gè)是 liked 按照字面意思應(yīng)該是用戶的點(diǎn)贊數(shù),但爬完才發(fā)現(xiàn)全是 0,沒有用。另一個(gè)是關(guān)于時(shí)間,里面有 ctime 和 mtime 兩個(gè)跟時(shí)間有關(guān)的值,看了幾個(gè),基本都是一樣的,有個(gè)別不太一樣,差的不多,就只取了 ctime,我猜可能一個(gè)是點(diǎn)擊進(jìn)去的時(shí)間,一個(gè)是評(píng)論提交時(shí)間,但沒法驗(yàn)證,就隨便取一個(gè)算了,ctime 的編碼很奇怪,比如某一個(gè)是 ctime = 1540001677,渣渣之前沒有見過這種編碼方式,請(qǐng)教了大佬之后知道,這個(gè)是Linux系統(tǒng)上的時(shí)間表示方式,是1970 年 1 月 1 日 0 時(shí) 0 分 0 秒到當(dāng)時(shí)時(shí)點(diǎn)的秒數(shù),python 中可以直接用 time.gmtime() 函數(shù)轉(zhuǎn)化成年月日小時(shí)分鐘秒的格式。還有 last_ep_index 里面存的是用戶當(dāng)前的看劇狀態(tài),比如看至第 13 話,第 6 話之類的,但后來發(fā)現(xiàn)很不準(zhǔn),絕大多數(shù)用戶沒有 last_ep_index 值,所以也沒有分析這個(gè)變量。
代碼如下:
1importrequests 2fromfake_useragentimportUserAgent 3importjson 4importpandasaspd 5importtime 6importdatetime 7headers={"User-Agent":UserAgent(verify_ssl=False).random} 8comment_api='https://bangumi.bilibili.com/review/web_api/short/list?media_id=102392&folded=0&page_size=20&sort=0' 910#發(fā)送get請(qǐng)求11response_comment=requests.get(comment_api,headers=headers)12json_comment=response_comment.text13json_comment=json.loads(json_comment)1415total=json_comment['result']['total']1617cols=['author','score','disliked','likes','liked','ctime','score','content','last_ep_index','cursor']18dataall=pd.DataFrame(index=range(total),columns=cols)192021j=022whilej
三、影評(píng)分析
最終一共爬到了 17398 條影評(píng)數(shù)據(jù)。里面的 date 是用 ctime 轉(zhuǎn)過來的,接下來對(duì)數(shù)據(jù)進(jìn)行一些分析,數(shù)據(jù)分析通過 python3.6 完成。
評(píng)分分布
評(píng)分取值范圍為2、4、6、8、10分,對(duì)應(yīng)1-5顆星
可以看出,幾乎所有的用戶都給了這部動(dòng)漫五星好評(píng),影響力可見一斑。
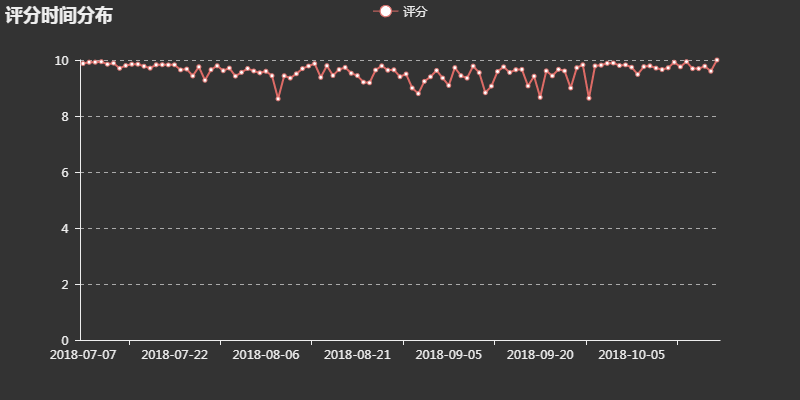
評(píng)分時(shí)間分布
將這部動(dòng)漫從上線至今所有的評(píng)分按日進(jìn)行平均,觀察評(píng)分隨時(shí)間的變化情況
可以看出,評(píng)分一直居高不下,尤其起始和結(jié)束時(shí)都接近滿分,足見這是一部良好開端、圓滿結(jié)束的良心作品。
每日評(píng)論數(shù)
看完評(píng)分之后,再看看評(píng)論相關(guān)的數(shù)據(jù),我最感興趣的是,這些評(píng)論的時(shí)間分布是怎么樣的,統(tǒng)計(jì)了每一日的評(píng)論數(shù)之后,得到了評(píng)論數(shù)的分布圖
基本上是每出了新的一話,大家看完后就會(huì)在短評(píng)中分享自己的感受,當(dāng)然同樣是起始和結(jié)束階段的評(píng)論數(shù)最多,對(duì)比同期的百度指數(shù)
評(píng)論日內(nèi)分布
除了每日的評(píng)論數(shù),也想分析一下評(píng)論的日內(nèi)趨勢(shì),用戶都喜歡在每日的什么時(shí)間進(jìn)行評(píng)論?將評(píng)論分 24 個(gè)小時(shí)求和匯總后,得到了下圖
不過這個(gè)結(jié)果就不是很理想了,橫軸是時(shí)間,縱軸是評(píng)論數(shù),中午到下午的趨勢(shì)上升可以理解,晚上七八點(diǎn)沒有人評(píng)論反倒是凌晨三四點(diǎn)評(píng)論數(shù)最多,這個(gè)就很反常了,可能是評(píng)論在系統(tǒng)中上線的時(shí)間有一定偏差?
好評(píng)字?jǐn)?shù)
此外還想分析一下,是否點(diǎn)贊數(shù)多的,一定是寫的字?jǐn)?shù)越多的?因?yàn)槲恼轮写蟛糠值脑u(píng)論是沒有點(diǎn)贊的,所以這里中統(tǒng)計(jì)了有點(diǎn)贊(likes>0)的評(píng)論點(diǎn)贊數(shù)和評(píng)論字?jǐn)?shù)的數(shù)據(jù)。由于有一條評(píng)論字點(diǎn)贊數(shù)太多,嚴(yán)重偏離整體趨勢(shì),所以做了對(duì)數(shù)圖進(jìn)行觀察。
整體來看,似乎沒什么關(guān)系,大量字?jǐn)?shù) 1-100 不等的,點(diǎn)贊數(shù)都為 1,點(diǎn)贊數(shù)大于 5 的部分有一定的正相關(guān)性,說明評(píng)論不僅要看數(shù)量,還要看質(zhì)量,寫出了大家的心聲,大家才會(huì)使勁點(diǎn)贊。
評(píng)論分析 TF-IDF
分析完基礎(chǔ)數(shù)據(jù)后,想更深入挖掘一下評(píng)論信息,大家都說了些什么?為什么這部劇這么受歡迎?也許都能在評(píng)論中找到答案。
jieba 分詞、去除停止詞、計(jì)算詞頻和 TF-IDF 的過程不表,與之前兩篇文章類似。我們提取了重要性前 500 的詞,這里展示部分
血小板高居首位,畢竟大家對(duì)萌萌噠事物都是沒什么抵抗力的。
詞語中也存在一些意義不大的詞,前期處理不太到位。不過從這些詞云中還是可以看出很多東西,為什么這部劇如此受歡迎?這里通過分詞可以得到以下三個(gè)解釋:
1. 題材好:科普類動(dòng)漫,老少皆宜
評(píng)論中提到了科普、生物、題材等詞,還有各種細(xì)胞。區(qū)別于一般科普向動(dòng)漫受眾低幼的問題,這部番的受眾年齡比較廣泛。因?yàn)樗婕暗降闹R(shí)并不算過于常識(shí)。動(dòng)漫中,每一話,身體的主人都會(huì)生一場(chǎng)病,每次出現(xiàn)新的細(xì)胞和病毒出現(xiàn)時(shí),都會(huì)對(duì)他們的身份有比較詳細(xì)和準(zhǔn)確的介紹
這種形式寓教于樂,同時(shí)戰(zhàn)斗的過程也充分地體現(xiàn)了每種細(xì)胞的特性。例如,前期因?yàn)閼?zhàn)斗力弱而被別的細(xì)胞瞧不起的嗜酸性粒細(xì)胞,在遇到寄生蟲的時(shí)候大放異彩。可以說,每一種細(xì)胞爆種都爆得都有理有據(jù)。
2. 人設(shè)好
這部番把幾乎人體所有的細(xì)胞擬人化:紅細(xì)胞、白細(xì)胞、血小板、巨噬細(xì)胞等。每一種細(xì)胞都有比較獨(dú)特的設(shè)定,從御姐到蘿莉,從高冷到話癆。十幾個(gè)出場(chǎng)的主要人物都各自有立得住的萌點(diǎn)。滿足各種口味的需求。
3. 制作精良
這一點(diǎn)是毋庸置疑的,好的人設(shè)好的題材,如果沒有好的制作,都是白談,評(píng)論中也有很多人提到了“聲優(yōu)”、“配音”等。
當(dāng)然一部劇能夠火,不僅僅是這么簡(jiǎn)單的原因,這里所說的,只是從數(shù)據(jù)可以看出的,觀眾的直觀感受。







-
數(shù)據(jù)
+關(guān)注
關(guān)注
8文章
7232瀏覽量
90712 -
函數(shù)
+關(guān)注
關(guān)注
3文章
4364瀏覽量
63805 -
爬蟲
+關(guān)注
關(guān)注
0文章
83瀏覽量
7270
原文標(biāo)題:用Python分析《工作細(xì)胞》的一萬多條評(píng)論后,非漫迷也要入番了
文章出處:【微信號(hào):rgznai100,微信公眾號(hào):rgznai100】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
鋰電車載式UPS產(chǎn)品受歡迎的原因
豆瓣電影Top250信息爬取
BLE低功耗藍(lán)牙模塊為何如此受歡迎?
iOS 12的裝機(jī)率已達(dá)到88%,是什么讓iOS 12如此受歡迎?
SDEV-B系列動(dòng)力鋰離子電池系統(tǒng)的數(shù)據(jù)說明

淺談:耐彎曲電纜為何如此受歡迎?
如何用python爬取抖音app數(shù)據(jù)
阿爾法機(jī)器狗如此受歡迎的魅力是什么

為什么8.6代線TFT工廠如此受歡迎
Scrapy怎么爬取Python文件





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論