 一個能同時完成四個任務的的深度神經網絡
一個能同時完成四個任務的的深度神經網絡

本文構建了一個能同時完成四個任務的的深度神經網絡: 生成圖像描述、生成相似單詞、以圖搜圖和根據描述搜圖。傳統上這些任務分別需要一個模型,但我們現在要用一個模型來完成所有這些任務。
眾所周知,神經網絡十分擅長處理特定領域的任務(narrow task),但在處理多任務時結果并不是那么理想。
這與人類的大腦不同,人類的大腦能夠在多樣化任務中使用相同的概念。例如,假如你從來沒聽說過“分形”(fractal),請看下面這張圖:
數學之美:分形圖像
上圖是一個分形圖像。在看到一張分形圖像后,人能夠處理多個與之相關的任務:
在一組圖像中,區分一只貓的圖像和分形圖像;
在一張紙上,粗略地畫一個分形圖像;
將分形圖像與非分形圖像進行分類;
閉上眼睛,想象一下分形圖像是什么樣子的。
那么,你是如何完成這些任務的呢?大腦中有專門的神經網絡來處理這些任務嗎?
現代神經科學認為,大腦中的信息是在不同的部位進行分享和交流的。對于這種多任務性能是如何發生的,答案可能在于如何在神經網絡中存儲和解釋數據。
“表示”的精彩世界
顧名思義,“表示”(representation)就是信息在網絡中編碼的方式。當一個單詞、一個句子或一幅圖像(或其他任何東西)作為輸入提供給一個訓練好的神經網絡時,它就隨著權重乘以輸入和應用激活在連續的層上進行轉換。最后,在輸出層,我們得到一串數字,我們將其解釋為類的標簽或股票價格,或網絡為之訓練的任何其他任務。
輸入->輸出的神奇轉換是由連續層中發生的輸入轉換產生的。輸入數據的這些轉換即稱為“表示”(representations)。一個關鍵的想法是,每一層都讓下一層更容易地完成它的工作。使連續層的周期變得更容易的過程會導致激活(特定層上輸入數據的轉換)變得有意義。
有意義是指什么呢?讓我們看下面的示例,該示例展示了圖像分類器中不同層的激活。

圖像分類網絡的作用是將像素空間中的圖像轉化為更高級的概念空間。例如,一張汽車的圖像最初被表示為RGB值,在第一層開始被表示為邊緣空間,然后在第二層被表示為圓圈和基本形狀空間,在倒數第二層,它將開始表示為高級對象(如車輪、車門等)。
這種越來越豐富的表示(由于深度網絡的分層性質而自動出現)使得圖像分類的任務變得簡單。最后一層要做的就是斟酌,比如說,車輪和車門的概念更像汽車,耳朵和眼睛的概念更像人。
你能用這些表示做什么?
由于這些中間層存儲有意義的輸入數據編碼,所以可以對多個任務使用相同的信息。例如,你可以使用一個語言模型(一個經過訓練的、用于預測下一個單詞的遞歸神經網絡),并解釋某個特定神經元的激活,從而預測句子帶有的情緒。
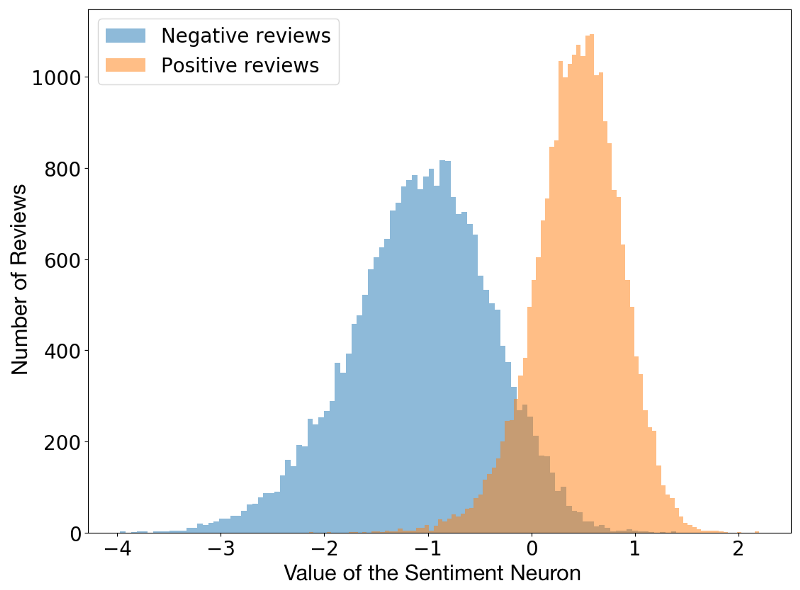
一個令人驚訝的事實是,情感神經元是在無監督的語言建模任務中自然產生的。網絡被訓練去預測下一個單詞,它的任務中并沒有被要求去預測情感。也許情感是一個非常有用的概念,以至于網絡為了更好地進行語言建模而發明它。
一旦你理解了“表示”這個概念,你就會開始從完全不同的角度來理解深層神經網絡。你會開始將感知表示(sensing representations)作為一種可轉換的語言,使不同的網絡(或同一網絡的不同部分)能夠彼此通信。
通過構建一個四合一的網絡來探索表示
為了充分理解“表示”,讓我們來構建一個能同時完成四個任務的的深度神經網絡:
圖像描述生成器:給定圖像,為其生成描述
相似單詞生成器:給定一個單詞,查找與之相似的其他單詞
視覺相似的圖像搜索:給定一幅圖像,找出與之最相似的圖像
通過描述圖像內容進行搜索:給出文本描述,搜索具有所描述的內容的圖像
這里的每一個任務本身就是一個項目,傳統上分別需要一個模型。但我們現在要用一個模型來做所有這些任務。
Pytorch代碼:
https://github.com/paraschopra/one-network-many-uses
第一部分:看圖說話(Image Captioning)
在網上有很多實現Image Captioning的很好的教程,所以這里不打算深入講解。我的實現與這個教程中的完全相同:https://daniel.lasiman.com/post/image-captioning/。關鍵的區別在于,我的實現是在Pytorch中實現的,而這個教程使用的是Keras。
接下來,你需要下載Flickr8K數據集。你還需要下載圖像描述。提取“caption_datasets”文件夾中的文字描述。
模型
Image Captioning一般有兩個組成部分:
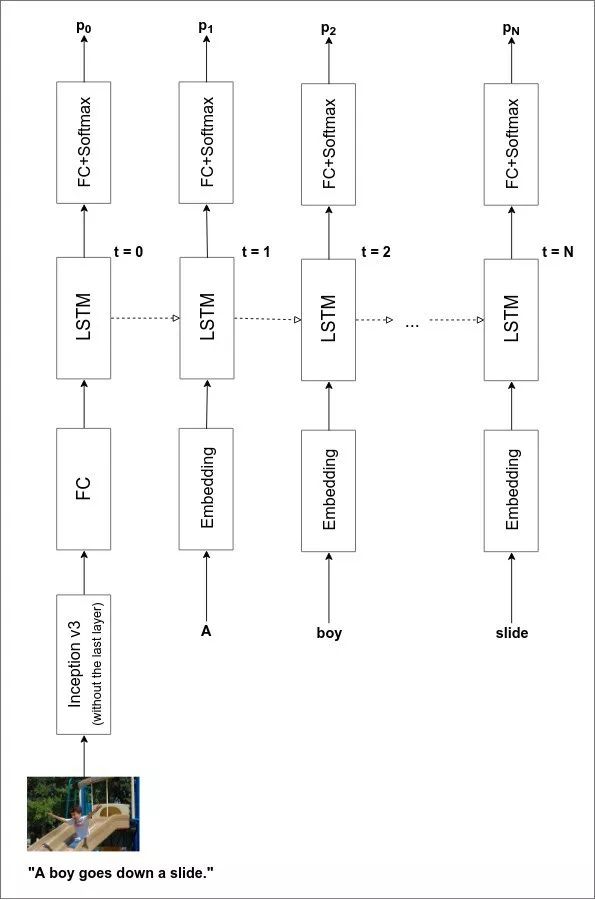
a)圖像編碼器(image encoder),它接收輸入圖像并以一種對圖像描述有意義的格式來表示圖像;
b)圖說解碼器(caption decoder),它接受圖像表示,并輸出文本描述。
image encoder是一個深度卷積網絡,caption decoder則是傳統的LSTM/GRU遞歸神經網絡。當然,我們可以從頭開始訓練它們。但這樣做需要比我們現有的(8k圖像)更多的數據和更長的訓練時間。因此,我們不從頭開始訓練圖像編碼器,而是使用一個預訓練的圖像分類器,并使用它的pre-final層的激活。
這是一個示例。我使用PyTorch modelzoo中可用的Inception網絡,該網絡在ImageNet上進行了訓練,可以對100個類別的圖像進行分類,并使用它來提供一個可以輸入給遞歸神經網絡中的表示。

請注意,Inception network從未針對圖說生成任務進行過訓練。然而,它的確有效!
我們也可以使用一個預訓練的語言模型來作為caption decoder。但這一次,由于我重新實現了一個運行良好的模型,所以可以從頭開始訓練解碼器。
完整的模型架構如下圖所示:
你可以從頭開始訓練模型,但是需要在CPU上花費幾天時間(我還沒有針對GPU進行優化)。但不用擔心,你也可以享受一個已經訓練完成的模型。(如果你是從頭開始訓練,請注意,我在大約40 epochs時停止訓練,當時運行的平均損失約為2.8)。
性能
我實現了性能良好的beam search方法。下面是網絡為測試集中的圖像生成的圖說示例(以前從未見過)。
用我自己的照片試試,讓我們看看網絡生成的圖說是什么:
效果不錯!令人印象深刻的是,網絡知道這張照片里有一個穿著白色T恤的男人。但語法有點偏離(我相信通過更多的訓練可以修正),但基本的要點抓住了。
如果輸入的圖像包含網絡從未見過的東西,它往往會失敗。例如,我很好奇網絡會給iPhone X的圖像貼上什么樣的標簽。
效果不太好。但總的來說,我對它的表現非常滿意,這為我們使用網絡在學習給圖像生成圖說時開發的“表示”來構建其他功能提供了良好的基礎。
第二部分:查找相似單詞
回想一下我們如何從圖像表示中解碼圖說。我們將該表示提供給LSTM/GRU網絡,生成一個輸出,將其解釋為第一個單詞,然后將第一個單詞返回到網絡以生成第二個單詞。這個過程一直持續到網絡生成一個表示句子結束的特殊標記為止。
為了將單詞反饋到網絡中,我們需要將單詞轉換為表示,再輸入給網絡。這意味著,如果輸入層包含300個神經元,那么對于所有圖說中的8000多個不同的單詞,我們需要有一個300個相關聯的數字,唯一地指定那個單詞。將單詞字典轉換成數字表示的過程稱為詞匯嵌入(或詞匯表示)。
我們可以下載和使用已經存在的詞匯嵌入,如word2vec或GLoVE。但在這個示例中,我們從頭開始學習詞匯嵌入。我們從隨機生成的詞匯嵌入開始,探索在訓練結束時,網絡對單詞的了解。
由于我們無法想象100維的數字空間,我們將使用一種稱為t-SNE的奇妙技術來在2維中可視化學習的詞匯嵌入。t-SNE是一種降維技術,它試圖使高維空間中的鄰域同時也是低維空間中的鄰域。
詞匯嵌入的可視化
讓我們來看看caption decoder學習到的詞匯嵌入空間(不像其他語言任務有數百萬單詞和句子,我們的解碼器在訓練數據集中只有~30k的句子)。

因此,我們的網絡已經了解到像“play”、“plays”和“playing”這樣的詞匯是非常相似的(它們具有相似的表示形式,如紅色箭頭所示的緊密聚類)。讓我們在這個二維空間中探索另一個區域:

這個區域似乎有一堆數字——“two”、“three”、“four”、“five”,等等。
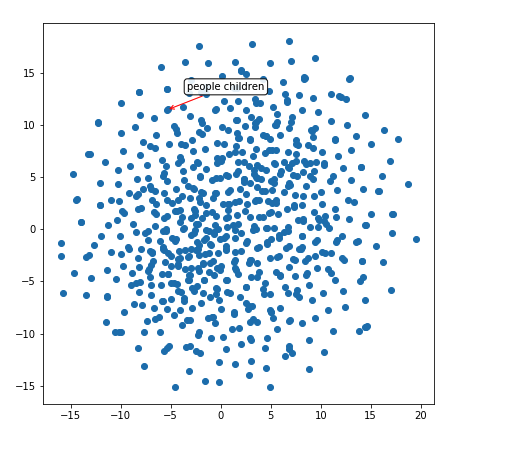
上圖,它知道people和children兩個單詞相似。而且,它還隱式地推斷出了物體的形狀。

相似詞匯
我們可以使用100維表示(100-dimensional representation)來構建一個函數,該函數提出與輸入單詞最相似的單詞。它的工作原理很簡單:采用100維的表示,并找出它與數據庫中所有其他單詞的余弦相似度。
讓我們來看看與“boy”這個單詞最相似的單詞:
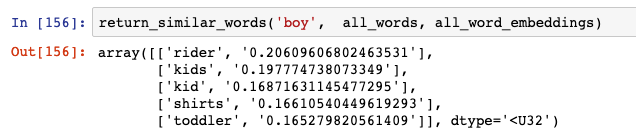
結果不錯。“Rider”除外,但“kids”、“kid”和“toddler”都是正確的。
這個網絡認為與“chasing”相似的詞匯是:

“Chases”是可以的,但我不確定為什么它認為“police”與“chasing”類似。
單詞類比(Word analogies)
關于詞匯嵌入的一個令人興奮的事實是,你可以對它們進行微積分。你可以用兩個單詞(如“king”和“queen”)并減去它們的表示來得到一個方向。當你把這個方向應用到另一個詞的表示上(如“man”),你會得到一個與實際類似詞(比如“woman”)很接近的表示。這就是為什么word2vec一經推出就如此受歡迎的原因:
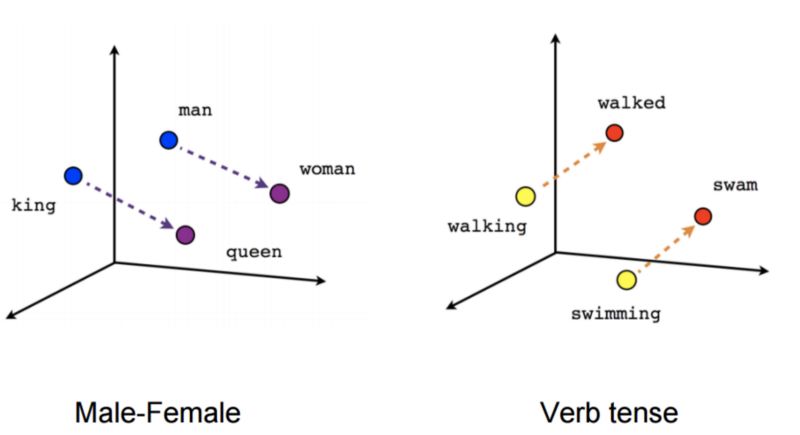
我很好奇通過caption decoder學習到的表示是否具有類似的屬性。盡管我持懷疑態度,因為訓練數據并不大(大約3萬個句子),我還是嘗試了一下。
網絡學習到的類比并不完美(有些單詞字面上出現的次數<10次,所以網絡沒有足夠的信息可供學習)。但仍有一些類比。
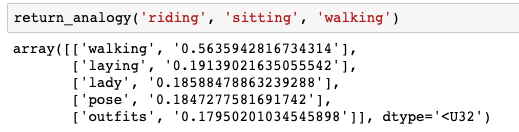
如果riding對應sitting,那么walking對應什么呢?我的網絡認為應該是“laying”(這個結果還不錯!)
同樣,如果“man”的復數是“men”,那么“woman”的復數應該是什么呢:

第二個結果是“women”,相當不錯了。
最后,如果grass對應green,那么sky對應什么呢:

網絡認為sky對應silver或grey的,雖然沒有出現blue,但它給的結果都是顏色詞。令人驚訝的是,這個網絡能夠推斷顏色的方向。
第三部分:查找相似圖像
如果單詞表示將類似的單詞聚在一起,那么圖像表示(Inception支持的圖像編碼器輸出)呢?我將相同的t-SNE技術應用于圖像表示(在caption decoder的第一步中作為輸入的300-dimensional tensor)。
可視化
這些點是不同圖像的表示(不是全部8K圖像,大約是100張圖像的樣本)。紅色箭頭指向附近的一組表示的聚類。
賽車的圖像被聚類在一起。
孩子們在森林/草地玩耍的圖像也被聚類在一起。
籃球運動員的圖像被聚類在一起。
查找與輸入圖像相似的圖像
對于查找相似單詞任務,我們被限制在測試集詞匯表中尋找相似的單詞(如果測試集中不存在某個單詞,我們的caption decoder就不會學習它的嵌入)。然而,對于類似的圖像任務,我們有一個圖像表示生成器(image representation generator),它可以接受任何輸入圖像并生成其編碼。
這意味著我們可以使用余弦相似度方法來構建一個按圖像搜索的功能,如下所示:
步驟1:獲取數據庫或目標文件夾中的所有圖像,并存儲它們的表示(由image encoder給出)
步驟2:當用戶希望搜索與已有圖像最相似的圖像時,使用新圖像的表示并在數據庫中找到最接近的圖像(由余弦相似度給出)
谷歌圖像可能正式使用這種(或類似的)方法來支持其反向圖像搜索功能。
讓我們看看這個網絡是如何工作的:
上面這張圖像是我自己的。我們使用的模型以前從未見過它。當我查詢類似圖像時,網絡從Flickr8K數據集輸出如下圖像:
是不是很像?我沒想到會有這么好的表現,但我們確實做到了!
第四部分:通過描述查找圖像
在最后一部分中,我們將反向運行caption generator。因此,我們不是獲取圖像并為其生成標題,而是輸入標題(文本描述)并找到與之最匹配的圖像。
過程如下:
步驟1:不是從來自編碼器的300維圖像表示開始,而是從一個完全隨機的300維輸入張量開始
步驟2:凍結整個網絡的所有層(即指示PyTorch不要計算梯度)
步驟3:假設隨機生成的輸入張量來自image encoder,將其輸入到caption decoder中
步驟4:獲取給定隨機輸入時網絡生成的標題,并將其與用戶提供的標題進行比較
步驟5:計算比較生成的標題和用戶提供的標題的損失
步驟6:找到使損失最小的輸入張量的梯度
步驟7:根據梯度改變輸入張量的方向(根據學習率改變一小步)
繼續步驟4到步驟7,直到收斂或當損失低于某個閾值時為止
最后一步:取最終的輸入張量,并利用它的值,通過余弦相似度找到離它最近的圖像
結果相當神奇的:
我搜索了“a dog”,這是網絡找到的圖像:
搜索“a boy smiling”:
最后,搜索:

前兩個結果是:
以及
總結和挑戰
所有這些操作的代碼可以從github存儲庫下載執行:
https://github.com/paraschopra/one-network-many-uses
這個存儲庫包括了用于數據預處理、模型描述、預訓練的圖說生成網絡、可視化的代碼。但不包括Flickr8K數據集或標題,需要單獨下載。
如果你想更進一步,這里有一個挑戰:從給定的描述生成圖像。
這比本文中處理的要難10倍,但我感覺這是可行的。如果一項服務不僅能夠搜索與文本對應的圖像,而且能夠動態地生成圖像,那該多酷啊。
在未來,如果Google Images實現了這個功能,并能夠為不存在的圖像提供結果(比如“兩只獨角獸在披薩做成的地毯上飛翔”),我不會感到驚訝的。
就這樣。祝你能安全愉快地探索表示的世界。
-
神經網絡
+關注
關注
42文章
4814瀏覽量
103685 -
圖像
+關注
關注
2文章
1094瀏覽量
41284 -
生成器
+關注
關注
7文章
322瀏覽量
21909 -
圖像分類
+關注
關注
0文章
96瀏覽量
12174
原文標題:一個神經網絡實現4大圖像任務,GitHub已開源
文章出處:【微信號:AI_era,微信公眾號:新智元】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
BP神經網絡與卷積神經網絡的比較
BP神經網絡的優缺點分析
BP神經網絡與深度學習的關系
人工神經網絡的原理和多種神經網絡架構方法






 工商網監
工商網監
評論