") DeepMind又放福利:開源了一個內(nèi)部的分布式機器學(xué)習(xí)庫TF-Replicator
DeepMind又放福利:開源了一個內(nèi)部的分布式機器學(xué)習(xí)庫TF-Replicator
今天,DeepMind又放福利:開源了一個內(nèi)部的分布式機器學(xué)習(xí)庫TF-Replicator,可以幫助研究人員將TensorFlow模型輕松部署到GPU、TPU,并實現(xiàn)不同類型加速器之間的無縫切換。
最近AI領(lǐng)域的突破,從AlphaFold到BigGAN再到AlphaStar,一個反復(fù)出現(xiàn)的主題是,對方便、可靠的可擴展性的需求。
研究人員已經(jīng)能夠獲取越來越多計算能力,得以訓(xùn)練更大的神經(jīng)網(wǎng)絡(luò),然而,將模型擴展到多個設(shè)備并不是一件容易的事情。
今天,DeepMind又將其內(nèi)部一個秘密武器公之于眾——TF-Replicator,一個可以幫助研究人員將他們的TensorFlow模型輕松部署到GPU、Cloud TPU的分布式機器學(xué)習(xí)框架,即使他們之前完全沒有使用分布式系統(tǒng)的經(jīng)驗。
TF-Replicator由DeepMind的研究平臺團隊開發(fā),初衷是為DeepMind的研究人員提供一個簡單的接入TPU的API,現(xiàn)在,TF-Replicator已經(jīng)是DeepMind內(nèi)部最廣泛使用的TPU編程接口。
TF-Replicator允許研究人員針對機器學(xué)習(xí)定位不同的硬件加速器進行,將工作負(fù)載擴展到許多設(shè)備,并在不同類型的加速器之間無縫切換。
雖然它最初是作為TensorFlow上面的一個庫開發(fā)的,但目前TF-Replicator的API已經(jīng)集成到TensorFlow 2.0新的tf.distribute.Strategy中,作為 tf.distribute.Strategy的一部分開源:
https://www.tensorflow.org/alpha/guide/distribute_strategy
團隊還公開了相關(guān)論文:TF-Replicator: Distributed Machine Learning for Researchers,全面描述了這個新框架的技術(shù)細(xì)節(jié)。
https://arxiv.org/abs/1902.00465
接下來,我們將介紹TF-Replicator背后的想法和技術(shù)挑戰(zhàn)。
構(gòu)建一個分布式機器學(xué)習(xí)庫
雖然TensorFlow為CPU、GPU和TPU設(shè)備都提供了直接支持,但是在目標(biāo)之間切換需要用戶付出大量的努力。這通常涉及為特定的硬件目標(biāo)專門編寫代碼,將研究想法限制在該平臺的功能上。
一些構(gòu)建在TensorFlow之上的現(xiàn)有框架,例如Estimators,已經(jīng)試圖解決這個問題。然而,它們通常針對生產(chǎn)用例,缺乏快速迭代研究思路所需的表達性和靈活性。
我們開發(fā)TF-Replicator的初衷是為DeepMind的研究人員提供一個使用TPU的簡單API。TPU為機器學(xué)習(xí)工作負(fù)載提供了可擴展性,實現(xiàn)了許多研究突破,例如使用我們的BigGAN模型實現(xiàn)了最先進的圖像合成。
TensorFlow針對TPU的原生API與針對GPU的方式不同,這造成了使用TPU的障礙。TF-Replicator提供了一個更簡單、更用戶友好的API,隱藏了TensorFlow的TPU API的復(fù)雜性。此外,研究平臺團隊與不同機器學(xué)習(xí)領(lǐng)域的研究人員密切合作,開發(fā)了TF-Replicator API,以確保必要的靈活性和易用性。
TF-Replicator API
使用TF-Replicator編寫的代碼與使用TensorFlow中為單個設(shè)備編寫的代碼類似,允許用戶自由定義自己的模型運行循環(huán)。用戶只需要定義(1)一個公開數(shù)據(jù)集的輸入函數(shù),以及(2)一個定義其模型邏輯的step函數(shù)(例如,梯度下降的單個step):
# Deploying a model with TpuReplicator.repl = tf_replicator.TpuReplicator( num_workers=1, num_tpu_cores_per_worker=8)with repl.context(): model = resnet_model() base_optimizer = tf.train.AdamOptimizer() optimizer = repl.wrap_optimizer(base_optimizer)# ... code to define replica input_fn and step_fn.per_replica_loss = repl.run(step_fn, input_fn)train_op = tf.reduce_mean(per_replica_loss)with tf.train.MonitoredSession() as session: repl.init(session) for i in xrange(num_train_steps): session.run(train_op) repl.shutdown(session)
將計算擴展到多個設(shè)備需要設(shè)備之間進行通信。在訓(xùn)練機器學(xué)習(xí)模型的背景下,最常見的通信形式是累積梯度(accumulate gradients)以用于優(yōu)化算法,如隨機梯度下降。
因此,我們提供了一種方便的方法來封裝TensorFlow Optimizers,以便在更新模型參數(shù)之前在設(shè)備之間累積梯度。對于更一般的通信模式,我們提供了類似于MPI的原語,如“all_reduce”和“broadcast”。這些使得實現(xiàn)諸如全局批標(biāo)準(zhǔn)化之類的操作變得非常簡單,這是擴展BigGAN模型訓(xùn)練的關(guān)鍵技術(shù)。
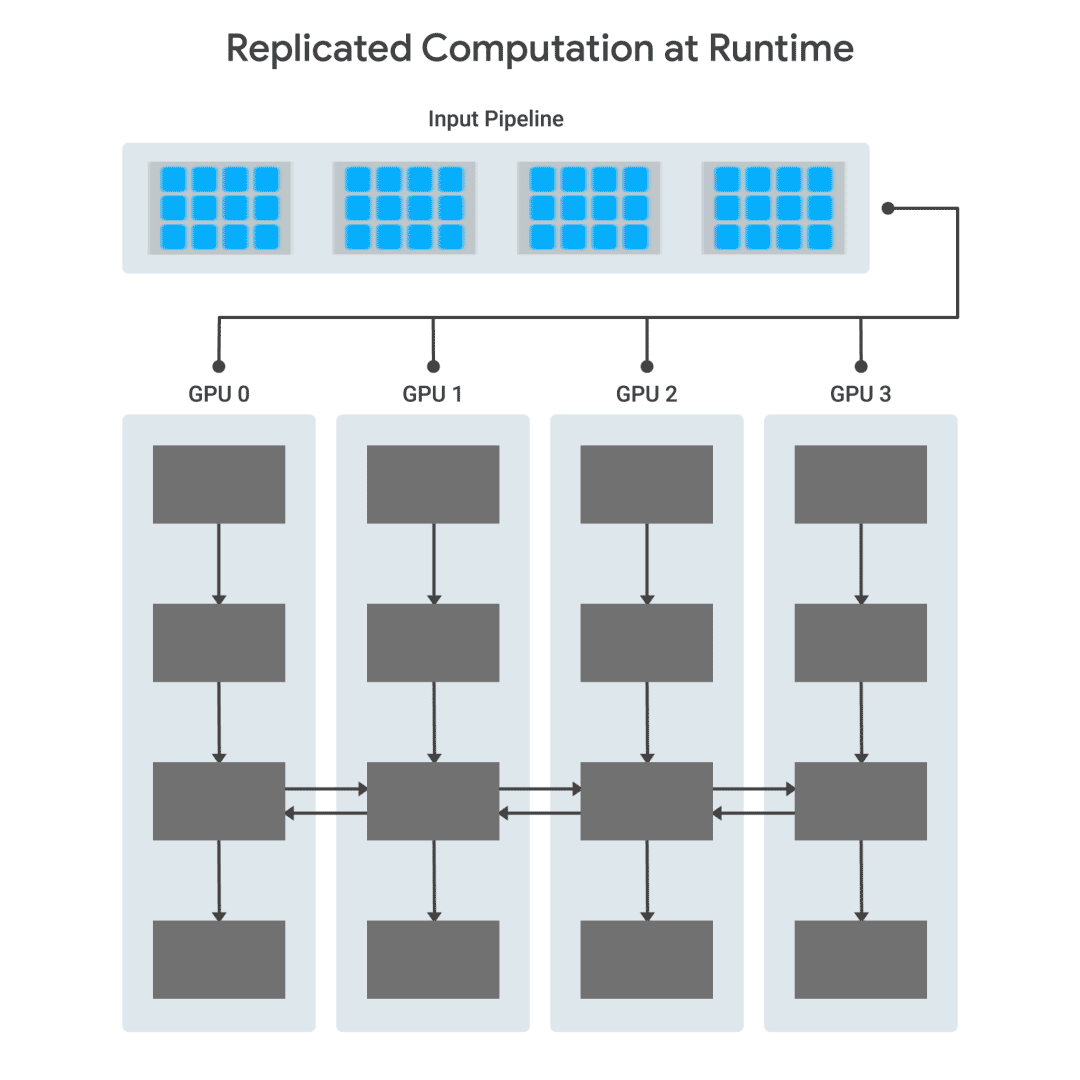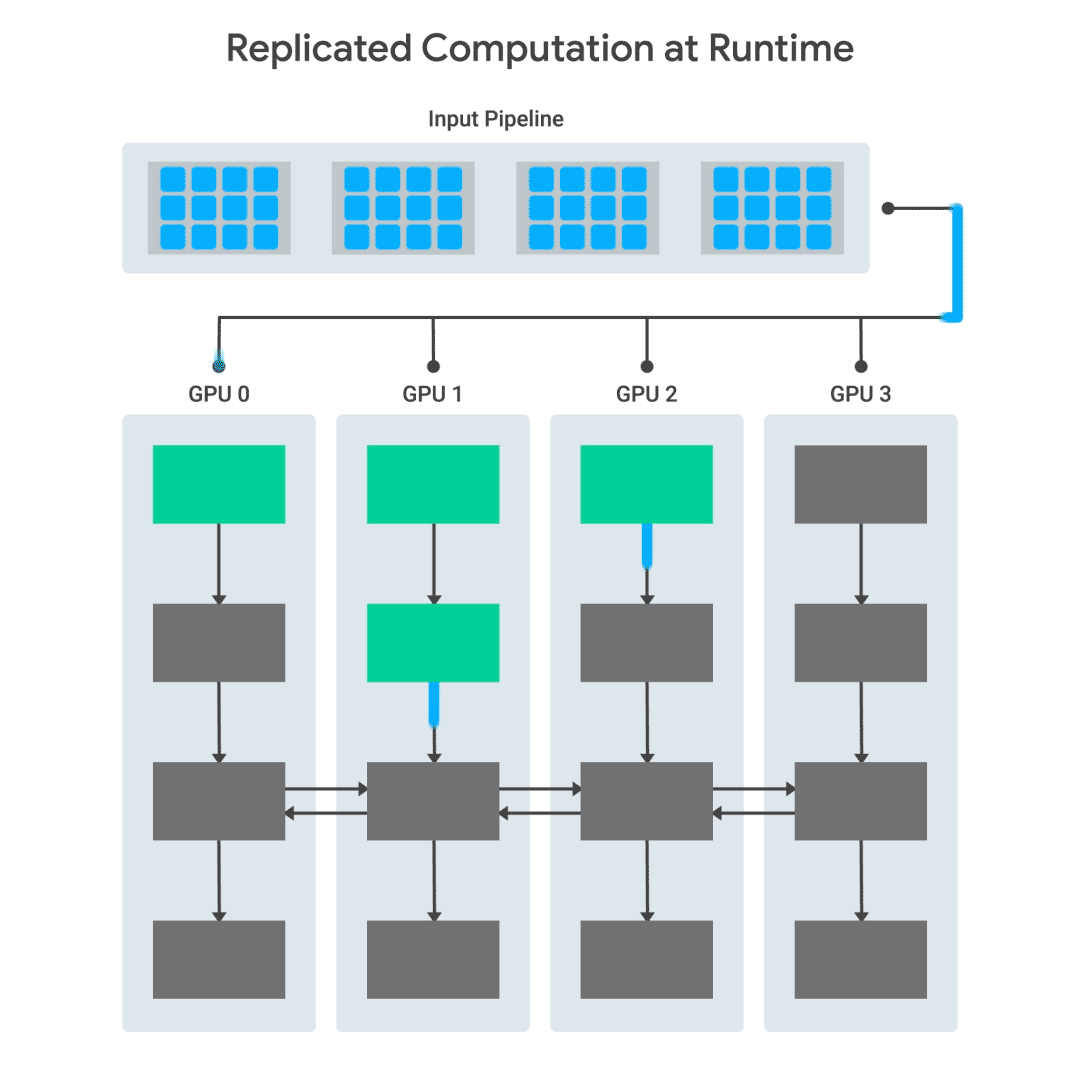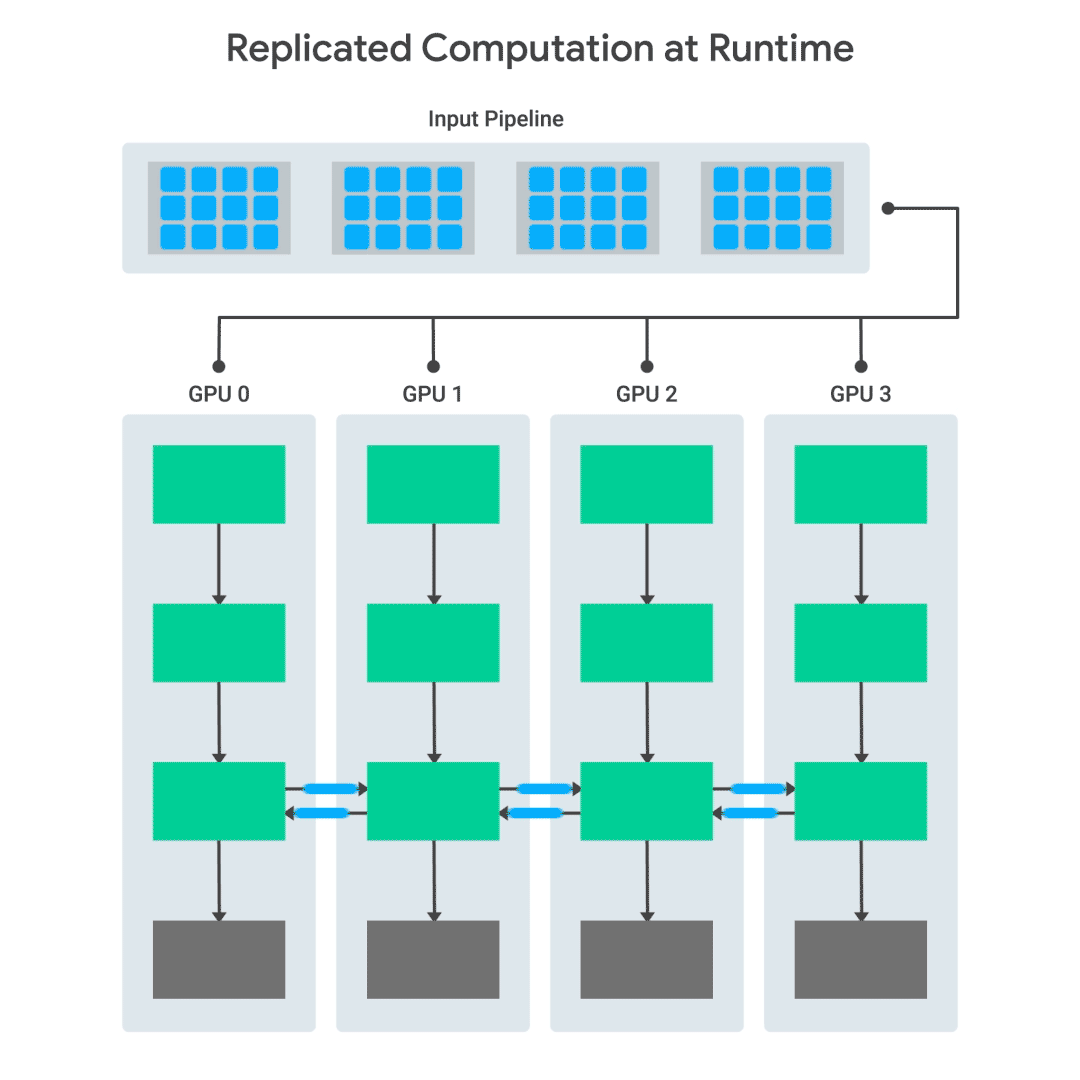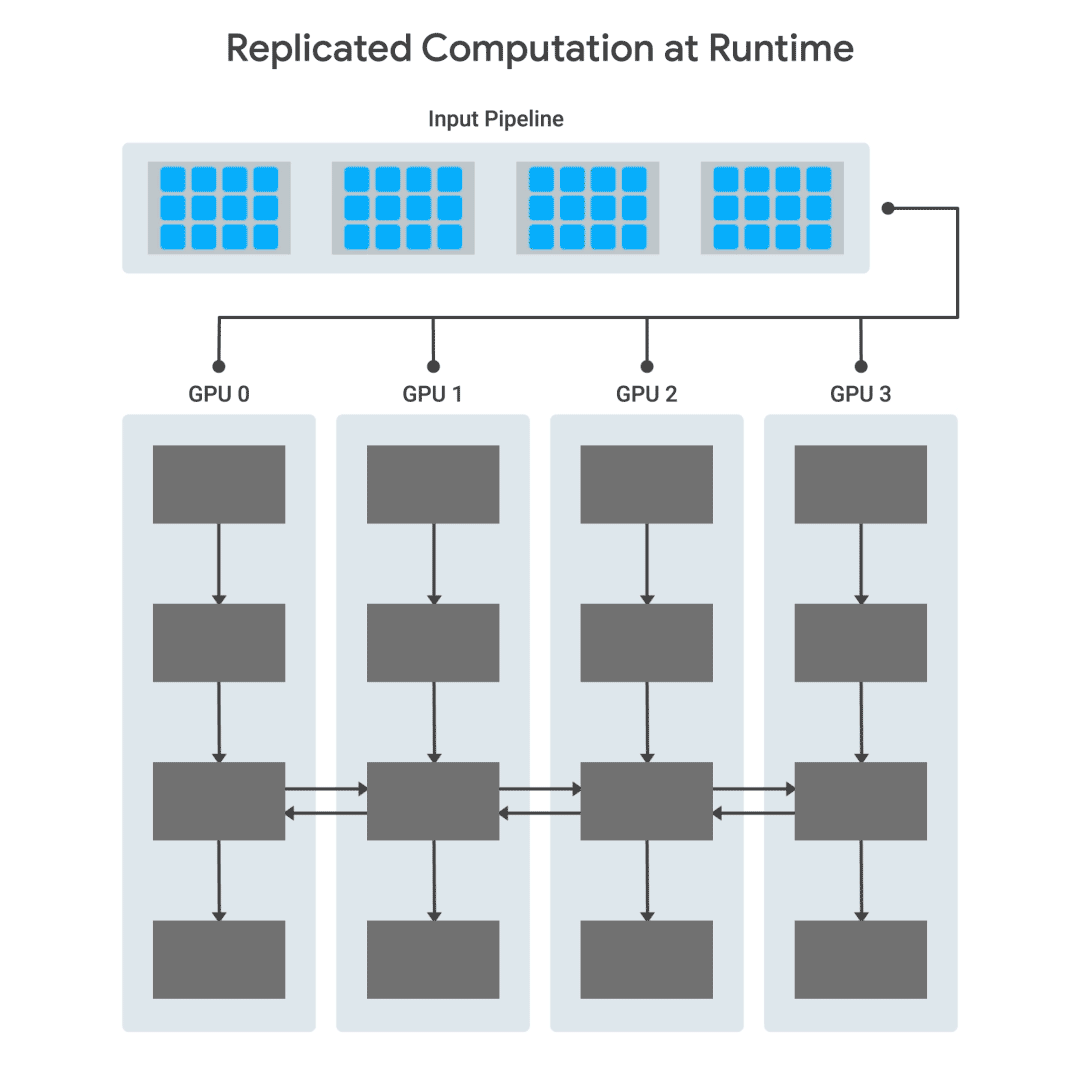
輸入數(shù)據(jù)從主機發(fā)送到各個GPU, GPU立即開始處理。當(dāng)需要在GPU之間交換信息時,它們會在發(fā)送數(shù)據(jù)之前進行同步。
實現(xiàn)
對于多GPU計算,TF-Replicator依賴于“圖內(nèi)復(fù)制”(“in-graph replication)模式,其中每個設(shè)備的計算在同一個TensorFlow graph中復(fù)制。設(shè)備之間的通信是通過連接設(shè)備對應(yīng)子圖中的節(jié)點來實現(xiàn)的。在TF-Replicator中實現(xiàn)這一點很具挑戰(zhàn)性,因為在TensorFlow graph中的任何位置都可能發(fā)生通信。因此,構(gòu)造計算的順序至關(guān)重要。
我們的第一個想法是在一個單獨的Python線程中同時構(gòu)建每個設(shè)備的子圖。當(dāng)遇到通信原語時,線程同步,主線程插入所需的跨設(shè)備計算。之后,每個線程將繼續(xù)構(gòu)建其設(shè)備的計算。
然而,在我們考慮這種方法時,TensorFlow的圖形構(gòu)建API不是線程安全的,這使得在不同線程中同時構(gòu)建子圖非常困難。相反,我們使用圖形重寫(graph rewriting)在所有設(shè)備的子圖構(gòu)建完成后插入通信。在構(gòu)造子圖時,占位符被插入到需要通信的位置。然后,我們跨設(shè)備收集所有匹配占位符,并用適當(dāng)?shù)目缭O(shè)備計算替換它們。
當(dāng)TF-Replicator構(gòu)建一個in-graph replicated計算時,它首先獨立地為每個設(shè)備構(gòu)建計算,并將占位符留給用戶指定的跨設(shè)備計算。構(gòu)建好所有設(shè)備的子圖之后,TF-Replicator通過用實際的跨設(shè)備計算替換占位符來連接它們。
為AI研究構(gòu)建一個平臺
通過在TF-Replicator的設(shè)計和實現(xiàn)過程中與研究人員密切合作,我們最終構(gòu)建一個庫,讓用戶能夠輕松地跨多個硬件加速器進行大規(guī)模計算,同時讓他們擁有進行前沿AI研究所需的控制和靈活性。
例如,在與研究人員討論之后,我們添加了MPI風(fēng)格的通信原語,如all-reduce。TF-Replicator和其他共享基礎(chǔ)架構(gòu)使我們能夠在穩(wěn)健的基礎(chǔ)上構(gòu)建越來越復(fù)雜的實驗,并在整個DeepMind快速傳播最佳實踐。
在撰寫本文時,TF-Replicator已經(jīng)成為DeepMind應(yīng)用最廣泛的TPU編程接口。雖然這個庫本身并不局限于訓(xùn)練神經(jīng)網(wǎng)絡(luò),但它最常用來訓(xùn)練大量數(shù)據(jù)。例如,BigGAN模型是在一個512核的TPUv3 pod訓(xùn)練的,batch size為2048。
在采用分布式actor-learner設(shè)置的增強學(xué)習(xí)智能體中,例如我們的重要性加權(quán)actor-learner架構(gòu),可擴展性是通過讓許多actor通過與環(huán)境的交互生成新的體驗來實現(xiàn)的。然后,learner對這些數(shù)據(jù)進行處理,以改進agent的策略,表示為一個神經(jīng)網(wǎng)絡(luò)。為了應(yīng)對越來越多的actor,TF-Replicator可以很輕松地將learner分布在多個硬件加速器上。
這些以及更多例子在我們的arXiv論文中有更詳細(xì)的描述。
Blog:
https://deepmind.com/blog/tf-replicator-distributed-machine-learning/
Paper:
https://arxiv.org/abs/1902.00465
-
神經(jīng)網(wǎng)絡(luò)
+關(guān)注
關(guān)注
42文章
4811瀏覽量
103009 -
機器學(xué)習(xí)
+關(guān)注
關(guān)注
66文章
8496瀏覽量
134216 -
DeepMind
+關(guān)注
關(guān)注
0文章
131瀏覽量
11424
原文標(biāo)題:你的模型可以輕松使用TPU了!DeepMind 開源分布式機器學(xué)習(xí)庫TF-Replicator
文章出處:【微信號:AI_era,微信公眾號:新智元】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
分布式存儲數(shù)據(jù)恢復(fù)—虛擬機上hbase和hive數(shù)據(jù)庫數(shù)據(jù)恢復(fù)案例
使用VirtualLab Fusion中分布式計算的AR波導(dǎo)測試圖像模擬
鐵塔基站分布式儲能揭秘!
分布式云化數(shù)據(jù)庫有哪些類型
基于ptp的分布式系統(tǒng)設(shè)計
HarmonyOS Next 應(yīng)用元服務(wù)開發(fā)-分布式數(shù)據(jù)對象遷移數(shù)據(jù)權(quán)限與基礎(chǔ)數(shù)據(jù)
PingCAP推出TiDB開源分布式數(shù)據(jù)庫
分布式通信的原理和實現(xiàn)高效分布式通信背后的技術(shù)NVLink的演進

分布式光纖測溫是什么?應(yīng)用領(lǐng)域是?
分布式光纖聲波傳感技術(shù)的工作原理
分布式輸電線路故障定位中的分布式是指什么

一文講清什么是分布式云化數(shù)據(jù)庫!
分布式存儲費用高嗎?大概需要多少錢
基于分布式存儲WDS的金融信創(chuàng)云承載數(shù)據(jù)庫類關(guān)鍵應(yīng)用





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論