 25篇視覺領域前沿論文的摘要解讀
25篇視覺領域前沿論文的摘要解讀

CVPR 2019錄取1299篇論文,其中騰訊優圖實驗室喜提25篇,本文帶來這25篇視覺領域前沿論文的摘要解讀。
CVPR 2019 即將于六月在美國長灘召開,本屆大會總共錄取來自全球論文 1299 篇。CVPR 作為計算機視覺領域級別最高的研究會議,其錄取論文代表了計算機視覺領域在 2019 年最新和最高的科技水平以及未來發展潮流。
CVPR 官網顯示,今年有超過5165篇的大會論文投稿,錄取1299篇論文,比去年增長了 32%(2017 年錄取 979 篇)。
其中,騰訊有超過58篇論文被本屆 CVPR 大會接收,其中騰訊優圖實驗室25篇、騰訊 AI Lab33篇。
被收錄的論文涵蓋深度學習優化原理、視覺對抗學習、人臉建模與識別、視頻深度理解、行人重識別、人臉檢測等熱門及前沿領域。本文帶來騰訊優圖實驗室以及其他優圖聯合高校實驗室的 25 篇 CVPR論文的解讀。
25篇CVPR論文解讀
1. Unsupervised Person Re-identification by Soft Multilabel Learning
軟多標簽學習的無監督行人重識別
相對于有監督行人重識別(RE-ID)方法,無監督 RE-ID因其更佳的可擴展性受到越來越多的研究關注,然而在非交疊的多相機視圖下,標簽對(pairwise label)的缺失導致學習鑒別性的信息仍然是非常具有挑戰性的工作。
為了克服這個問題,我們提出了一個用于無監督 RE-ID 的軟多標簽學習深度模型。該想法通過將未標注的人與輔助域里的一組已知參考者進行比較,為未標注者標記軟標簽(類似實值標簽的似然向量)。
基于視覺特征以及未標注目標對的軟性標簽的相似度一致性,我們提出了軟多標簽引導的hard negative mining 方法去學習一種區分性嵌入表示(discriminative embedding)。由于大多數目標對來自交叉視角,我們提出了交叉視角下的軟性多標簽一致性學習方法,以保證不同視角下標簽的一致性。為實現高效的軟標簽學習,引入了參考代理學習(reference agent learning)。
我們的方法在 Market-1501 和 DukeMTMC-reID 上進行了評估,顯著優于當前最好的無監督 RE-ID 方法。
2. Visual Tracking via Adaptive Spatially-Regularized Correlation Filters
基于自適應空間加權相關濾波的視覺跟蹤研究
本文提出自適應空間約束相關濾波算法來同時優化濾波器權重及空間約束矩陣。
首先,本文所提出的自適應空間約束機制可以高效地學習得到一個空間權重以適應目標外觀變化,因此可以得到更加魯棒的目標跟蹤結果。
其次,本文提出的算法可以通過交替迭代算法來高效進行求解,基于此,每個子問題都可以得到閉合的解形式。
再次,本文所提出的跟蹤器使用兩種相關濾波模型來分別估計目標的位置及尺度,可以在得到較高定位精度的同時有效減少計算量。大量的在綜合數據集上的實驗結果證明了本文所提出的算法可以與現有的先進算法取得相當的跟蹤結果,并且達到了實時的跟蹤速度。
3. Adversarial Attacks Beyond the Image Space
超越圖像空間的對抗攻擊
生成對抗實例是理解深度神經網絡工作機理的重要途徑。大多數現有的方法都會在圖像空間中產生擾動,即獨立修改圖像中的每個像素。
在本文中,我們更為關注與三維物理性質(如旋轉和平移、照明條件等)有意義的變化相對應的對抗性示例子集。可以說,這些對抗方法提出了一個更值得關注的問題,因為他們證明簡單地干擾現實世界中的三維物體和場景也有可能導致神經網絡錯分實例。
在分類和視覺問答問題的任務中,我們在接收 2D 輸入的神經網絡前邊增加一個渲染模塊來拓展現有的神經網絡。我們的方法的流程是:先將 3D 場景(物理空間)渲染成 2D 圖片(圖片空間),然后經過神經網絡把他們映射到一個預測值(輸出空間)。這種對抗性干擾方法可以超越圖像空間。在三維物理世界中有明確的意義。雖然圖像空間的對抗攻擊可以根據像素反照率的變化來解釋,但是我們證實它們不能在物理空間給出很好的解釋,這樣通常會具有非局部效應。但是在物理空間的攻擊是有可能超過圖像空間的攻擊的,雖然這個比圖像空間的攻擊更難,體現在物理世界的攻擊有更低的成功率和需要更大的干擾。
4. Learning Context Graph for Person Search
基于上下文圖網絡的行人檢索模型
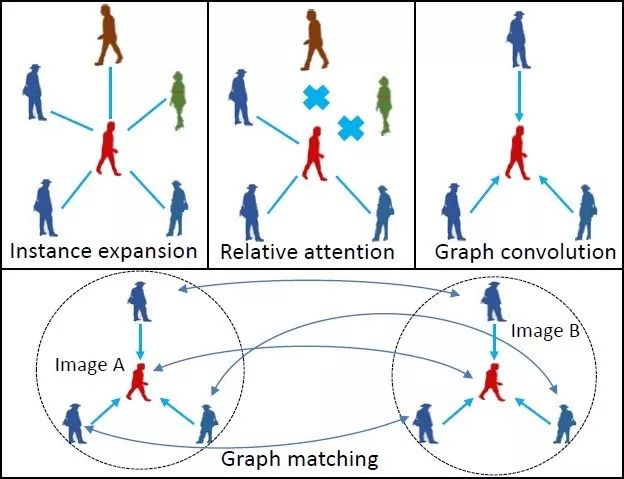
本文由騰訊優圖實驗室與上海交通大學主導完成。
近年來,深度神經網絡在行人檢索任務中取得了較大的成功。但是這些方法往往只基于單人的外觀信息,其在處理跨攝像頭下行人外觀出現姿態變化、光照變化、遮擋等情況時仍然比較困難。
本文提出了一種新的基于上下文信息的行人檢索模型。所提出的模型將場景中同時出現的其他行人作為上下文信息,并使用卷積圖模型建模這些上下文信息對目標行人的影響。我們在兩個著名的行人檢索數據集 CUHK-SYSU 和 PRW 的兩個評測維度上刷新了當時的世界紀錄,取得了top1 的行人檢索結果。
5. Underexposed Photo Enhancement using Deep Illumination Estimation
基于深度學習優化光照的暗光下的圖像增強
本文介紹了一種新的端到端網絡,用于增強曝光不足的照片。
我們不是像以前的工作那樣直接學習圖像到圖像的映射,而是在我們的網絡中引入中間照明,將輸入與預期的增強結果相關聯,這增強了網絡從專家修飾的輸入/輸出圖像學習復雜的攝影調整的能力。
基于該模型,我們制定了一個損失函數,該函數采用約束和先驗在中間的照明上,我們準備了一個3000 個曝光不足的圖像對的新數據集,并訓練網絡有效地學習各種照明條件的豐富多樣的調整。
通過這些方式,我們的網絡能夠在增強結果中恢復清晰的細節,鮮明的對比度和自然色彩。我們對基準 MIT-Adobe FiveK 數據集和我們的新數據集進行了大量實驗,并表明我們的網絡可以有效地處理以前的困難圖像。
6. Homomorphic Latent Space Interpolation for Unpaired Image-to-imageTranslation
基于同態隱空間插值的不成對圖片到圖片轉換
生成對抗網絡在不成對的圖像到圖像轉換中取得了巨大成功。循環一致性允許對沒有配對數據的兩個不同域之間的關系建模。
在本文中,我們提出了一個替代框架,作為潛在空間插值的擴展,在圖像轉換中考慮兩個域之間的中間部分。
該框架基于以下事實:在平坦且光滑的潛在空間中,存在連接兩個采樣點的多條路徑。正確選擇插值的路徑允許更改某些圖像屬性,而這對于在兩個域之間生成中間圖像是非常有用的。我們還表明該框架可以應用于多域和多模態轉換。廣泛的實驗表明該框架對各種任務具有普遍性和適用性。
7. X2CT-GAN: Reconstructing CT from Biplanar X-Rays with GenerativeAdversarial Networks
基于生成對抗網絡的雙平面 X 光至 CT 生成系統
當下 CT 成像可以提供三維全景視角幫助醫生了解病人體內的組織器官的情況,來協助疾病的診斷。但是 CT 成像與 X 光成像相比,給病人帶來的輻射劑量較大,并且費用成本較高。傳統 CT 影像的三維重建過程中圍繞物體中心旋轉采集并使用了大量的 X 光投影,這在傳統的 X 光機中也是不能實現的。
在這篇文章中,我們創新性的提出了一種基于對抗生成網絡的方法,只使用兩張正交的二維 X 光圖片來重建逼真的三維 CT 影像。核心的創新點包括增維生成網絡,多視角特征融合算法等。
我們通過實驗與量化分析,展示了該方法在二維 X 光到三維 CT 重建上大大優于其他對比方法。通過可視化 CT 重建結果,我們也可以直觀的看到該方法提供的細節更加逼真。在實際應用中, 我們的方法在不改變現有 X 光成像流程的前提下,可以給醫生提供額外的類 CT 的三維影像,來協助他們更好的診斷。
8. Semantic Regeneration Network
語義再生網絡
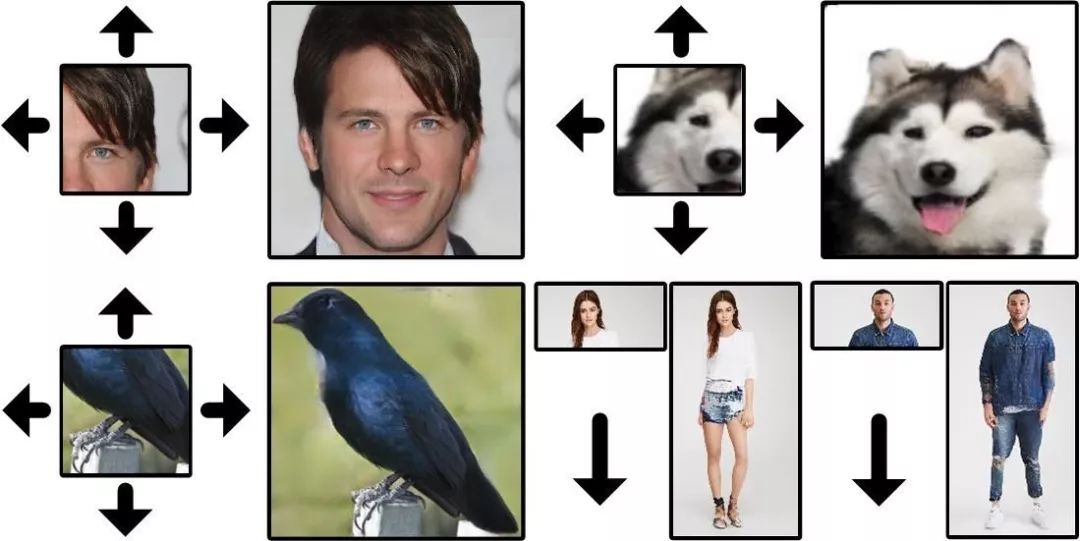
本文研究了使用深度生成模型推斷視覺上下文的基本問題,即利用合理的結構和細節擴展圖像邊界。這個看似簡單的任務實際上面臨著許多關鍵的技術挑戰,并且具有其獨特的性質。任務里兩個主要問題是擴展尺寸和單面約束。我們提出了一個具有多個特殊貢獻的語義再生網絡,并使用多個空間相關的損失來解決這些問題。
本文最終的實驗結果包含了高度一致的結構和高品質的紋理。我們對各種可能的替代方案和相關方法進行了廣泛的實驗。最后, 我們也探索了我們的方法對各種有趣應用的潛力,這些應用可以使各個領域的研究受益。
9. Towards Accurate One-Stage Object Detection with AP-Loss
利用 AP 損失函數實現精確的一階目標檢測
一階的目標檢測器通常是通過同時優化分類損失函數和定位損失函數來訓練。而由于存在大量的錨框,分類損失函數的效果會嚴重受限于前景-背景類的不平衡。
本文通過提出一種新的訓練框架來解決這個問題。我們使用排序任務替換一階目標檢測器中的分類任務,并使用排序問題的中的評價指標 AP 來作為損失函數。由于其非連續和非凸,AP 損失函數不能直接通過梯度下降優化。
為此,我們提出了一種新穎的優化算法,它將感知機學習中的誤差驅動更新方案和深度網絡中的反向傳播算法結合在一起。我們從理論上和經驗上驗證了提出的算法的良好收斂性。
實驗結果表明,在不改變網絡架構的情況下,在各種數據集和現有最出色的一階目標檢測器上,AP 損失函數的性能相比不同類別的分類損失函數有著顯著提高。
10. Amodal Instance Segmentation through KINS Dataset
通過 KINS 數據集進行透視實例分割
透視實例分割是實例分割的一個新方向,旨在模仿人類的能力對每個對象實例進行分割包括其不可見被遮擋的部分。此任務需要推理對象的復雜結構。盡管重要且具有未來感,但由于難以正確且一致地標記不可見部分,這項任務缺乏大規模和詳細注釋的數據,這為探索視覺識別的前沿創造了巨大的障礙。
在本文中,我們使用 8 個類別的更多實例像素級注釋來擴充 KITTI,我們稱之為KITTI INStance 數據集(KINS)。我們提出了通過具有多分支編碼(MBC)的新多任務框架來推理不可見部分的網絡結構,該框架將各種識別級別的信息組合在一起。大量實驗表明,我們的 MBC 有效地同時改善透視和非透視分割。KINS 數據集和我們提出的方法將公開發布。
11. Pyramidal Person Re-IDentification via Multi-Loss Dynamic Training
基于多損失動態訓練策略的金字塔式行人重識別
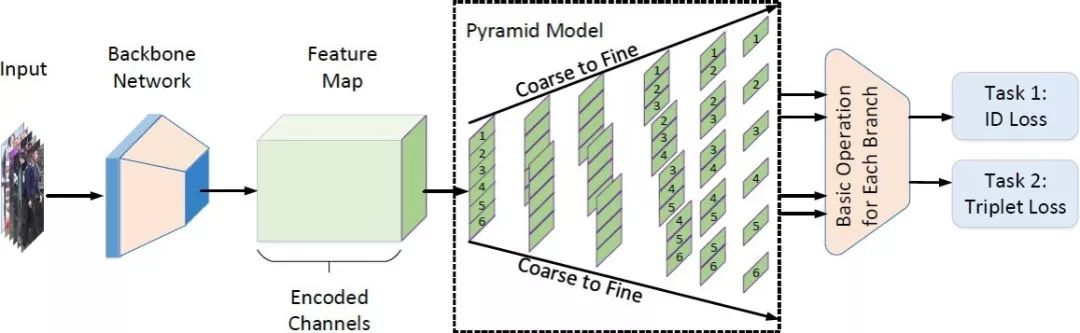
大多數已提出的行人重識別方法高度依賴于精準的人體檢測以保證目標間的相互對齊。然而在復雜的實際場景中,現有模型尚難以保證檢測的精準性,不可避免地影響了行人重識別的性能。
在本文中,我們提出了一種新的由粗及細的金字塔模型,以放寬對檢測框的精度限制,金字塔模型整合了局部、全局以及中間的過渡信息,能夠在不同尺度下進行有效匹配, 即便是在目標對齊不佳情況下。
此外,為了學習具有判別性的身份表征,我們提出了一種動態訓練框架,以無縫地協調兩種損失函數并提取適當的信息。我們在三個數據庫上達到了最好的效果。值得一提的,在最具挑戰性的 CUHK03 數據集上超過當前最佳方法 9.5 個百分點。
12. Dynamic Scene Deblurring with Parameter Selective Sharing and Nested Skip Connections
基于選擇性參數共享和嵌套跳躍連接的圖像去模糊算法
動態場景去模糊是一個具有挑戰的底層視覺問題因為每個像素的模糊是多因素共同導致,包括相機運動和物體運動。最近基于深度卷積網絡的方法在這個問題上取得了很大的提高。
相對于參數獨立策略和參數共享策略,我們分析了網絡參數的策略并提出了一種選擇性參數共享的方案。在每個尺度的子網絡內,我們為非線性變換的模塊提出了一種嵌套跳躍連接的結構。此外,我們依照模糊數據生成的方法建立了一個更大的數據集并訓練出效果更佳的去模糊網絡。
實驗表明我們的選擇性參數共享,嵌套跳躍鏈接,和新數據集都可以提高效果,并達到最佳的去模糊效果。
13. Learning Shape-Aware Embedding for Scene Text Detection
一種基于實例分割以及嵌入特征的文本檢測方法
由于復雜多變的場景,自然場景下的任意形狀文本的檢測十分具有挑戰性,本文主要針對檢測任意形狀的文本提出了解決方案。
具體地,我們將文本檢測視作一個實例分割問題并且提出了一個基于分割的框架,該框架使用相互獨立的連通域來表示不同的文本實例。為了區分不同文本實例,我們的方法將圖片像素映射至嵌入特征空間當中,屬于同一文本實例的像素在嵌入特征空間中會更加接近彼此,反之屬于不同文本實例的像素將會遠離彼此。
除此之外,我們提出的Shape-Aware 損失可以使得模型能夠自適應地去根據文本實例復雜多樣的長寬比以及實例間的狹小縫隙來調整訓練,同時加以我們提出的全新后處理算法,我們的方法能夠產生精準的預測。我們的實驗結果在三個具有挑戰性的數據集上(ICDAR15、MSRA-TD500 以及 CTW1500)驗 證了我們工作的有效性。
14. PointWeb: Enhancing Local Neighborhood Features for Point Cloud Processing
PointWeb: 通過局部近鄰特征增強點云處理
本文提出一種新的在局部近鄰點云中提取上下文特征的方法:PointWeb。與之前的方法不同,為了明確每個基于局部區域特性的點特征,我們密集地連接在局部近鄰里的所有點, 這樣可以更好地表征該區域。
我們提出了“自適應特征調整”模塊(AFA),計算兩點之間的相互作用。對于每個局部區域,通過特征差分圖計算點對之間對應每個元素影響程度的“影響圖”。根據自適應學習到的影響因子,每個特征都會被相同區域內的其他特征“推開”或“拉近”。調整過的特征圖更好地編碼區域信息,類似點云分割和分類的點云識別任務,將從中受益。
實驗結果表明我們的模型在語義分割和形狀分類數據集上,超出當前最優的算法。代碼和訓練好的模型將同論文一起發布。
15. Associatively Segmenting Instances and Semantics in Point Clouds
聯合分割點云中的實例和語義
一個 3D 點云精細和直觀的描述了一個真實場景。但是迄今為止怎樣在這樣一個信息豐富的三維場景分割多樣化的元素,仍然很少得到討論。
在本文中,我們首先引入一個簡單且靈活的框架來同時分割點云中的實例和語義。進一步地,我們提出兩種方法讓兩個任務從彼此中受益,得到雙贏的性能提升。具體來說,我們通過學習富有語義感知的實例嵌入向量來使實例分割受益于語義分割。同時,將屬于同一個實例的點的語義特征融合在一起,從而更準確地對每個點進行語義預測。我們的方法大幅超過目前最先進的 3D 實例分割方法,在 3D 語義分割上也有顯著提升。
代碼和模型已經開源:https://github.com/WXinlong/ASIS.
16. Cyclic Guidance for Weakly Supervised Joint Detection and Segmentation
基于循環指導的弱監督聯合檢測和分割
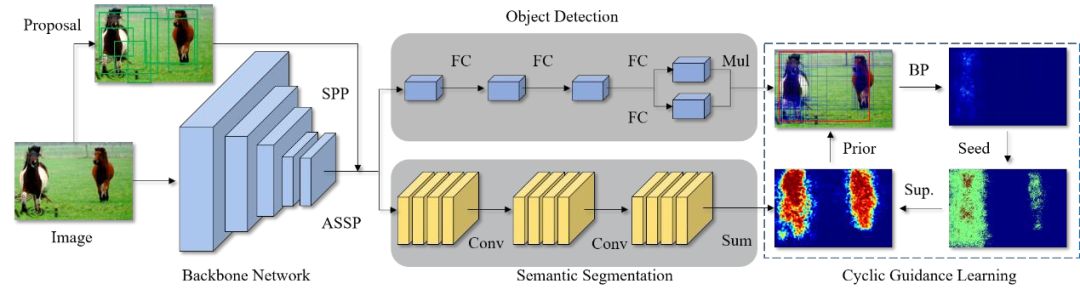
本文由騰訊優圖實驗室與廈門大學紀榮嶸教授團隊主導完成。
我們首次提出使用多任務學習機制聯合弱監督檢測和分割任務,并基于兩個任務各自的互補失敗模式來改進對方。這種交叉任務的增強使得兩個任務更能逃離局部最小值。
我們的方法 WS-JDS 有兩個分支并共享同一個骨干模型,分別對應兩個任務。在學習過程中,我們提出循環指導范式和特地的損失函數來改進雙方。實驗結果表明該算法取得了的性能提升。
17. ROI Pooled Correlation Filters for Visual Tracking
基于感興趣區域池化的相關濾波跟蹤研究
基于 ROI 的池化算法在樣本被提取的感興趣區域進行池化操作,并已經在目標檢測等領域取得了較大的成功。該池化算法可以較好的壓縮模型的尺寸,并且保留原有模型的定位精度,因此非常適合視覺跟蹤領域。盡管基于 ROI 的池化操作已經被不同領域證明了其有效性,其在相關濾波領域仍然沒有得到很好的應用。
基于此,本文提出了新穎的具有ROI 池化功能的相關濾波算法進行魯棒的目標跟蹤。通過嚴謹的數學推導,我們證明了相關濾波中的 ROI 池化可以通過在學習到的濾波器上引入附加的約束來等效實現,這樣就使得我們可以在不必明確提取出訓練樣本的情況下完成池化操作。我們提出了一個高效的相關濾波算法,并給出了基于傅立葉的目標函數求解算法。
我們在 OTB-2013、OTB-2015 及 VOT-2017 上對所提出的算法進行測試,大量的實驗結果證明了本文所提出算法的有效性。
18. Exploiting Kernel Sparsity and Entropy for Interpretable CNN Compression
基于卷積核稀疏性與密度熵的神經網絡壓縮方法
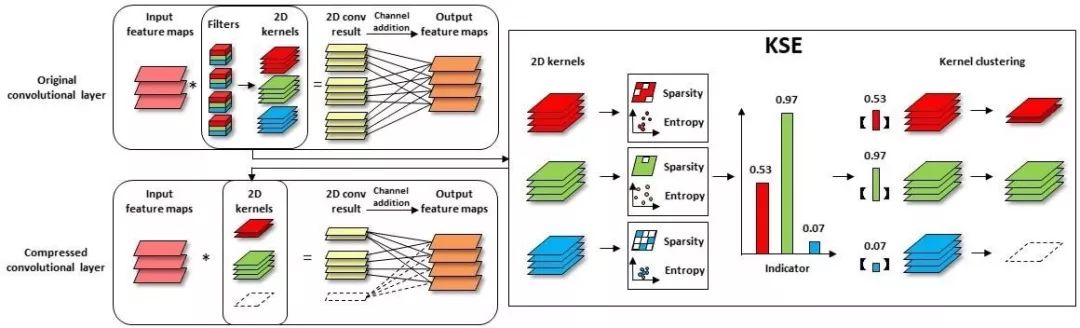
本文由騰訊優圖實驗室與廈門大學紀榮嶸教授團隊主導完成。
我們從神經網絡的解釋性角度出發,分析卷積神經網絡特征圖的冗余性問題,發現特征圖的重要性取決于它的稀疏性和信息豐富度。但直接計算特征圖的稀疏性與信息豐富度,需要巨大計算開銷。
為克服此問題,我們建立了特征圖和其對應二維卷積核之間的聯系,通過卷積核的稀疏性和密度熵來表征對應特征圖的重要程度,并得到判定特征圖重要性的得分函數。在此基礎上,我們采用較為細粒度壓縮的卷積核聚類代替傳統的剪枝方式壓縮模型。大量的實驗結果表明,我們所提出的基于卷積核稀疏性與密度熵的壓縮方法可以達到更高的壓縮率和精度。
19. MMFace: A Multi-Metric Regression Network for Unconstrained Face Reconstruction
MMFace: 用于無約束三維人臉重建的多度量回歸網絡
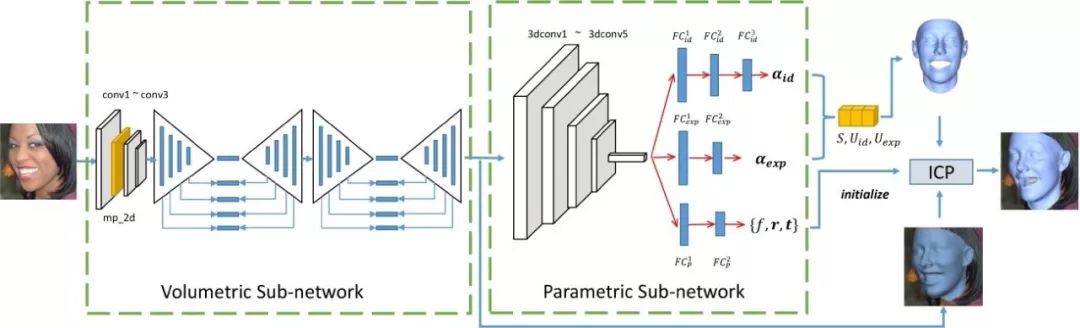
本文提出了一個用于進行無約束三維人臉重建的多度量回歸網絡。
其核心思想是利用一個體素回歸子網絡從輸入圖像生成一個人臉幾何結構的中間表達,再從該中間表達回歸出對應的三維人臉形變模型參數。我們從包括人臉身份、表情、頭部姿態,以及體素等多個度量對回歸結果進行了約束,使得我們的算法在夸張的表情,大頭部姿態、局部遮擋、復雜光照環境都有很好的魯棒性。
相比于目前的主流算法,我們的方法在公開的三維人臉數據集LS3D-W 和 Florence 上都得到了顯著的提升。此外,我們的方法還直接應用到對視頻序列的處理。
20. Towards Optimal Structured CNN Pruning via Generative Adversarial Learning
基于生成對抗學習的最優結構化卷積神經網絡剪枝方法
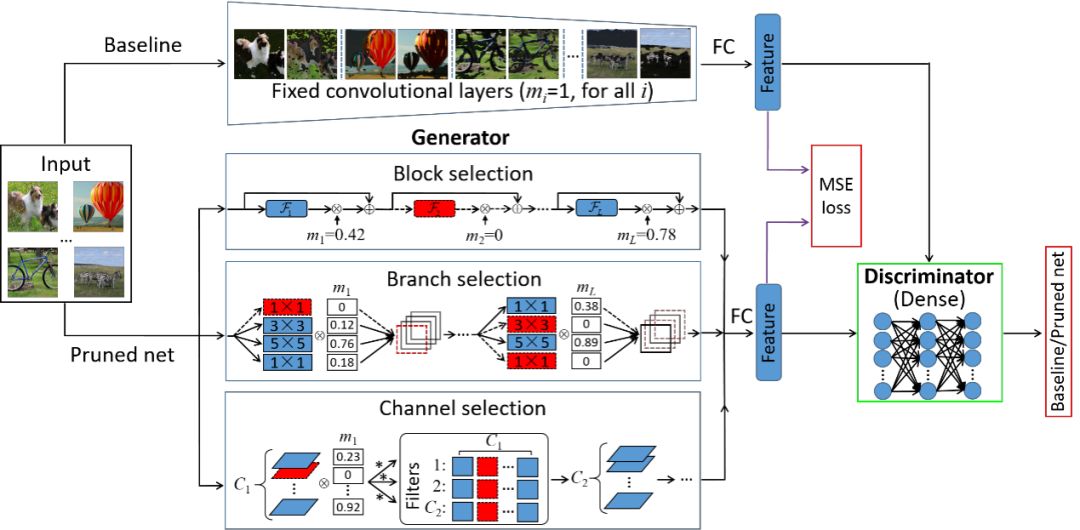
本文由騰訊優圖實驗室與廈門大學紀榮嶸教授團隊主導完成。
我們提出了一種基于生成對抗學習的最優結構化網絡剪枝方法,利用無監督端對端訓練剪枝網絡中冗余的異質結構,有效解決了傳統結構化剪枝方法存在剪枝效率低、缺乏松弛性、強標簽依賴等問題。該方法對每個模型結構引入了軟掩碼,并對其加入稀疏限制,使其表征每個結構的冗余性。
為了更好學習模型參數和掩碼,我們利用無類別標簽生成對抗學習框架,構建新的結構化剪枝目標函數,并利用快速的迭代閾值收縮算法解決該優化問題,穩定移除冗余結構。通過大量的實驗結果表明,相比于目前最先進的結構化剪枝方法,我們所提出的剪枝方法可以獲得更好的性能。
21. Semantic Component Decomposition for Face Attribute Manipulation
基于語義成分分解的人臉屬性編輯
最近,基于深度神經網絡的方法已被廣泛研究用于面部屬性編輯。然而,仍然存在兩個主要問題,即視覺質量不佳以及結果難以由用戶控制。這限制了現有方法的適用性,因為用戶可能對不同的面部屬性具有不同的編輯偏好。
在本文中,我們通過提出一個基于語義組件的模型來解決這些問題。該模型將面部屬性分解為多個語義成分,每個語義成分對應于特定的面部區域。這不僅允許用戶基于他們的偏好來控制不同部分的編輯強度,而且還使得有效去除不想要的編輯效果。此外,每個語義組件由兩個基本元素組成,它們分別確定編輯效果和編輯區域。此屬性允許我們進行更細粒度的交互式控制。實驗表明,我們的模型不僅可以產生高質量的結果,還可以實現有效的用戶交互。
22. Memory-Attended Recurrent Network for Video Captioning
一種針對視頻描述的基于記憶機制的循環神經網絡
傳統的視頻描述生成的模型遵循編碼-解碼 (encoder-decoder) 的框架,對輸入的視頻先進行視頻編碼,然后解碼生成相應的視頻描述。這類方法的局限在于僅能關注到當前正在處理的一段視頻。而在實際案例中,一個詞或者短語可以同時出現在不同但語義相似的視頻中,所以基于編碼-解碼的方法不能同時抓取一個詞在多個相關視頻中的上下文語義信息。
為了解決這個局限性,我們提出了一種基于記憶機制的循環神經網絡模型,設計了一種獨特的記憶結構來抓取每個詞庫中的詞與其所有相關視頻中的對應語義信息。因此,我們的模型可以對每個詞的語義有更全面和深入的理解,從而提高生成的視頻描述的質量。另外,我們設計的記憶結構能夠評估相鄰詞之間的連貫性。充足的實驗證明我們的模型比現有的其他模型生成的視頻描述質量更高。
23. Distilled Person Re-identification: Towards a More Scalable System
蒸餾的行人重識別:邁向更具可擴展性的系統
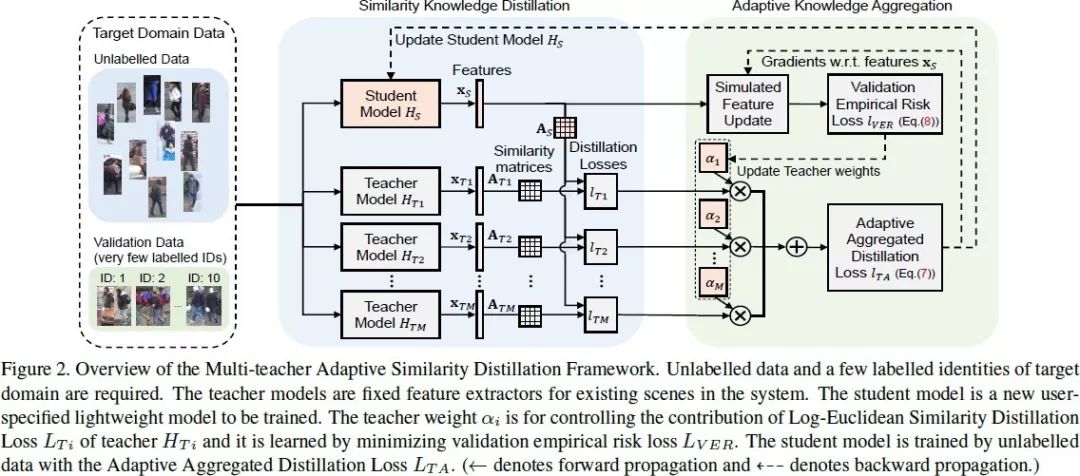
行人重識別(Re-ID),作為面向非交疊相機視角下的行人比對技術,在具備豐富標簽數據下有監督學習領域的研究已取得了長足的進步。然而可擴展性問題仍然是系統走向大規模應用的瓶頸。
我們從三個方面考慮 Re-ID 的可擴展性問題:(1)減少標簽規模來降低標注成本,(2)復用已有知識來降低遷移成本(3)使用輕量模型來降低預測成本。
為解決這些問題,我們提出了一種多教師自適應的相似度蒸餾框架,僅需要少量有標注的目標域身份, 即可將多種教師模型中的知識遷移到訂制的輕量級學生模型,而無需利用源域數據。為有效選擇教師模型,完成知識遷移,我們提出了 Log-Euclidean 的相似度蒸餾損失函數,并進一步整合了 Adaptive Knowledge Aggregator。大量的實驗評估結果論證了方法的可擴展性,在性能上可與當前最好的無監督和半監督 Re-ID 方法相媲美。
24. DSFD: Dual Shot Face Detector
雙分支人臉檢測器
本文由南京理工大學計算機科學與工程學院 PCALab 與騰訊優圖實驗室合作完成。
近年來,卷積神經網絡在人臉檢測中取得了很大的成功。然而這些方法在處理人臉中多變的尺度,姿態,遮擋,表情,光照等問題時依然比較困難。
本文提出了一種新的方法,分別處理了人臉檢測方向的三個關鍵點,包括更好的特征學習,漸進式的損失函數設計以及基于錨點分配的數據擴充。
首先,我們提出了一種特征增強單元,以增強特征能力的方式將單分支擴展到雙分支結構。其次,我們采用漸進式的錨點損失函數,通過給雙分支不同尺度的錨點集更有效地促進特征學習。最后,我們使用了一種改進的錨點匹配方法,為回歸器提供了更好的初始化數據。
由于上述技術都與雙分支的設計相關,我們將本文方法命名為雙分支人臉檢測器。我們在兩個著名的人臉檢測數據集 WIDER FACE 和 FDDB 的 5 個評測維度上均刷新了當時的世界紀錄,取得了 Top1 的人臉檢測結果。
25. 3D Motion Decomposition for RGBD Future Dynamic Scene Synthesis
基于 3D 運動分解合成 RGBD 未來動態場景
視頻中未來時刻的幀,是由相機自身運動和場景中物體運動后的 3D 場景投影到 2D 形成的。因此,從根本上說,精確預測視頻未來的變化,需要理解場景的 3D 運動和幾何特性。
在這篇文章中,我們提出了通過3D 運動分解來實現的 RGBD 場景預測模型。我們首先預測相機運動和前景物體運動,它們共同用來生成 3D 未來場景,然后投影到 2D 相機平面來合成未來的運動、RGB 圖像和深度圖。我們也可以把語義分割信息融入系統,以預測未來時刻的語義圖。
我們在 KITTI 和 Driving 上的結果說明,我們的方法超過了當前最優的預測RGBD 未來場景的方法
-
濾波器
+關注
關注
162文章
8116瀏覽量
181502 -
神經網絡
+關注
關注
42文章
4812瀏覽量
103174 -
深度學習
+關注
關注
73文章
5557瀏覽量
122626
原文標題:騰訊優圖25篇CVPR解讀:視覺對抗學習、視頻深度理解等
文章出處:【微信號:AI_era,微信公眾號:新智元】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
后摩智能四篇論文入選三大國際頂會
云知聲四篇論文入選自然語言處理頂會ACL 2025

老板必修課:如何用NotebookLM 在上下班路上吃透一篇科技論文?
美報告:中國芯片研究論文全球領先
海伯森亮相VisionCon合肥視覺系統技術設計會議
后摩智能5篇論文入選國際頂會

直播報名丨AIGC技術在工業視覺領域的應用

CMPA601C025F 6-12GHz頻段的25瓦GaN功率放大器


NVIDIA視覺生成式AI的最新進展
深視智能參編《2024智能檢測裝備產業發展研究報告:機器視覺篇》






 工商網監
工商網監
評論