") 自動駕駛中的激光雷達目標檢測的原理和數(shù)據(jù)特點
自動駕駛中的激光雷達目標檢測的原理和數(shù)據(jù)特點

安全性是自動駕駛中人們最關注的問題之一。
在算法層面,無人車對周圍環(huán)境的準確感知是保證安全的基礎,因此感知算法的精度十分重要。現(xiàn)有感知算法的思路一般通過某種數(shù)學模型對現(xiàn)實世界的某個子集進行擬合。
當情況足夠簡單的時候,算法可以得到較高的精度。例如現(xiàn)在很多無人駕駛公司有在限定的時間段和限定的場地內(nèi),用單一傳感器的算法就可以得到非常高的精度。
但是自動駕駛中的實際問題非常復雜,各種天氣、路況和障礙物的組合非常多,基于單一傳感器的算法很難解決所有情況。例如在進隧道和出隧道時因為光線的突然變化攝像頭會有欠曝光和過曝光問題,此時拍到的圖片幾乎全黑或全白,僅基于攝像頭的感知算法很難在這種情況給出高精度的結(jié)果。
為了解決這種開放環(huán)境中的自動駕駛問題,很多自動駕駛公司提出了多傳感器方案,希望通過取長補短來提高自動駕駛系統(tǒng)處理復雜環(huán)境的能力。現(xiàn)在最普遍使用的傳感器是攝像頭,除此之外還有激光雷達、毫米波雷達、GPS/IMU等。
激光雷達作為自動駕駛領域中最重要的傳感器之一,常用于物體檢測、道路分割和高精度地圖構建。
本文主要討論基于激光雷達的物體檢測算法。在討論具體的算法之前,首先要了解激光雷達數(shù)據(jù)的特點。
激光雷達原理和數(shù)據(jù)特點
現(xiàn)在自動駕駛中常用的激光雷達為機械式激光雷達,其由若干組可以旋轉(zhuǎn)的激光發(fā)射器和接收器組成。每個發(fā)射器發(fā)射的一條激光束俗稱“線“,主要有單線、4線、16線、32線、64線和128線雷達。
常見機械式激光雷達中激光束是波長在900nm左右的近紅外光(NIR),可以根據(jù)激光直接獲得周圍一圈的準確的三維空間信息。
這種雷達的成像原理比較簡單:發(fā)射器和接收器連接在一個可以旋轉(zhuǎn)的機械結(jié)構上,某時刻發(fā)射器將激光發(fā)射出去,之后接收器接收返回的激光并計算激光與物體碰撞點到雷達原點的距離。
由于每次發(fā)射/接收的角度是預先設定的,因此根據(jù)距離、水平角度和垂直角度就能求出碰撞點相對于激光雷達中心的坐標。每條線每次發(fā)射激光得到的數(shù)據(jù)由一個四元組(x,y,z,i)表示,其中(x,y,z)是三維坐標,i表示反射強度。

圖1:一個32線激光雷達的成像原理示意圖
以某款32線激光雷達為例,32根線從上到下排列覆蓋15.0°到-24.9°。
工作狀態(tài)時這32根線在水平平面旋轉(zhuǎn)可以采集一周360°的數(shù)據(jù)。雷達的旋轉(zhuǎn)速度和角分辨率是可以調(diào)節(jié)的,常用速度為10hz(100ms轉(zhuǎn)一圈)對應每0.2°采集一次數(shù)據(jù),即角分辨率為360/0.2=1800。
由于光速非常快所以在1800中任何一個位置進行一次發(fā)射和接收動作可以看作是瞬時完成的。受到硬件能力的限制,一般轉(zhuǎn)速越快則發(fā)射和接收激光的次數(shù)越少,即角分辨率越小。常用雷達采集到的數(shù)據(jù)點距離雷達中心一般不會超過150米。
通常采集到的360°的數(shù)據(jù)被稱為一幀,上面的例子中一幀數(shù)據(jù)在理論上最多包含32*(360/0.2)=57600個點。
在實際情況中如果雷達被放置在車的上方大約距地面1.9米的位置,則在比較空曠的場景中大約獲得40000個點,一部分激光點因為被發(fā)射向天空或被吸收等并沒有返回到接收器,也就無法得到對應的點。下圖是典型的一幀數(shù)據(jù)的可視化圖。
圖2:一個32線激光雷達的一幀數(shù)據(jù)的三維可視化圖
激光雷達具有不受光照影響和直接獲得準確三維信息的特點,因此常被用于彌補攝像頭傳感器的不足。激光雷達采集到的三維數(shù)據(jù)通常被稱為點云,激光點云數(shù)據(jù)有很多獨特的地方:
距離中心點越遠的地方越稀疏;
機械激光雷達的幀率比較低,一般可選5hz、10hz和20hz,但是因為高幀率對應低角分辨率,所以在權衡了采樣頻率和角分辨率之后常用10hz;
點與點之間根據(jù)成像原理有內(nèi)在聯(lián)系,比如平坦地面上的一圈點是由同一個發(fā)射器旋轉(zhuǎn)一周生成的;
激光雷達生成的數(shù)據(jù)中只保證點云與激光原點之間沒有障礙物以及每個點云的位置有障礙物,除此之外的區(qū)域不確定是否存在障礙物;
由于自然中激光比較少見所以激光雷達生成的數(shù)據(jù)一般不會出現(xiàn)噪聲點,但是其他激光雷達可能會對其造成影響,另外落葉、雨雪、沙塵、霧霾也會產(chǎn)生噪聲點;
與激光雷達有相對運動的物體的點云會出現(xiàn)偏移,例如采集一圈激光點云的耗時為100ms,在這一段時間如果物體相對激光有運動,則采集到的物體上的點會被壓縮或拉伸。
激光雷達物體檢測算法

圖3:本節(jié)的敘事結(jié)構
在深度學習流行之前主要用傳統(tǒng)的機器學習方法對點云進行分類和檢測。
在這個領域?qū)τ谶@些學習方法本身的研究并不多,研究者更傾向于直接把理論上較為成熟的方法應用到激光點云數(shù)據(jù)中。研究者將研究重點主要放在對數(shù)據(jù)本身特性的理解上,從而設計出適合點云的算法流程。
上一節(jié)點云圖中最明顯的規(guī)律是地面上的“環(huán)”,根據(jù)點云的成像原理當激光雷達平放在地面上方時,與地面夾角為負角度的“線”在地面上會形成一圈一圈的環(huán)狀結(jié)構。
因為這種結(jié)構有很強的規(guī)律性所以很多物體檢測算法的思路是先做地面分割然后做聚類,最后將聚類得到的物體進行識別。為了提高算法的速度,很多算法并不直接作用于三維點云數(shù)據(jù),而是先將點云數(shù)據(jù)映射到二維平面中然后再處理。常見的二維數(shù)據(jù)形式的有Range Image和Elevation Image。
從2014年開始深度學習廣泛地被應用在各個領域,隨著圖片物體檢測算法的發(fā)展,點云物體檢測也逐步轉(zhuǎn)向了深度學習。
現(xiàn)在自動駕駛中一般關注鳥瞰圖中物體檢測的效果,主要原因是直接在三維中做物體檢測的精確度不夠高,而且目前來說路徑規(guī)劃和車輛控制一般也只考慮在二維平面中車體的運動。
現(xiàn)在在鳥瞰圖中的目標檢測方法以圖片目標檢測的方法為主,主要在鳥瞰圖結(jié)構的建立、物體的空間位置的估計以及物體在二維平面內(nèi)的旋轉(zhuǎn)角度的估計方面有所不同。
從檢測結(jié)果來看這類算法比在三維空間中的物體檢測要好。直接作用在三維空間中的物體檢測方法在近年來也有所突破,其通過某種算子提取三維點云中具有點云順序不變性的特征,然后通過特殊設計的網(wǎng)絡結(jié)構在三維點云上直接做分類或分割。
這類方法的優(yōu)點是能對整個三維空間任何方向任何位置的物體進行無差別的檢測,其思路新穎但是受限于算法本身的能力、硬件設備的能力以及實際應用的場景,現(xiàn)在還不能在實際中廣泛地使用。
自動駕駛對于檢測算法有著比較特殊的要求:首先為了安全性考慮召回率要高,即不能漏檢;其次因為檢測到的物體是下游路徑規(guī)劃和運動決策算法的輸入,這要求檢測到的目標在連續(xù)幀中具有較好的穩(wěn)定性,具體而言即在連續(xù)幀中檢測到的同一個物體的類別、尺寸、位置和方向不能有劇烈的變化。與此同時因為激光點云的稀疏性,現(xiàn)有算法單用一幀點云數(shù)據(jù)無法在小物體、遠處物體和被遮擋物體的檢測上得到令人滿意的結(jié)果。
因此近幾年人們開始考慮結(jié)合多種傳感器數(shù)據(jù)的方法、結(jié)合多個激光雷達的方法以及結(jié)合連續(xù)多幀的方法。
雖然在學術界的排行榜中現(xiàn)在最好的方法是基于深度學習的算法,但是在實際問題中數(shù)據(jù)的預處理、后處理等對最終結(jié)果有著至關重要的影響,而這些部分的算法往往需要根據(jù)數(shù)據(jù)和使用場景有針對性的設計。
所以本節(jié)首先會介紹一些單幀目標檢測中的非深度學習算法中對于激光數(shù)據(jù)的處理方式,然后會在下集介紹深度學習算法以及多幀目標檢測算法中介紹幾個具有代表性的方法。
非深度學習算法
2015年之前應用在激光雷達領域的檢測和分類模型以線性模型、SVM和決策樹為主。這些模型的泛化能力和復雜程度無法在實際場景中滿足人們的需求,因此研究者將注意力更多的放在了對于點云數(shù)據(jù)特性的挖掘上。常見的算法流程為:
將三維點云映射為某種結(jié)構,例如Graph和Range Image;
提取每個節(jié)點或像素的特征;
將節(jié)點或像素聚類;
通過一定規(guī)則或分類器將一個或多個聚類確定為地面;
結(jié)合地面信息,通過分類器對其他聚類進行物體級別的識別;
把所有的檢測、識別的結(jié)果映射回三維點云中。
從檢測和分類的效果來說,這類方法遠沒有基于深度學習的方法好。
但無論是基于Graph或是基于Range Image的結(jié)構都比單純的點云蘊涵了更多的信息。在這些結(jié)構中有時使用簡單的基于規(guī)則的方法就可以得到比較好的結(jié)果,這一點在實際應用中非常重要。例如在物體檢測任務中出現(xiàn)了訓練集合中未出現(xiàn)過的物體,基于學習的方法一般無法正確地將其檢測出來。但是基于簡單規(guī)則的方法卻可以正常給出檢測結(jié)果,雖然此時分類結(jié)果往往是未知。
在自動駕駛中檢測算法的漏檢問題遠比錯分類問題嚴重很多,從這個角度說基于簡單規(guī)則的方法是保證安全的一把鎖。從實時數(shù)據(jù)預處理的效率來說,在實際環(huán)境中為了提高檢測精度需要將離散的噪聲點和不在檢測范圍內(nèi)的物體過濾掉。在Graph和Range Image中進行噪聲數(shù)據(jù)的過濾有時比直接在點云上做效率高。
1 基于Graph的方法
基于Graph的建模方法指直接根據(jù)三維點云直接建立無向圖G = {N, E},N表示圖中的節(jié)點E表示節(jié)點之間的邊。常用的建圖方式是將三維點云中每個點的坐標(x,y,z)作為一個節(jié)點。找到每個節(jié)點對應的雷達的線數(shù)l和水平方向的旋轉(zhuǎn)角度θ,當兩個節(jié)點i和j滿足下面任何一個條件時為這兩個節(jié)點建立一條邊。即如果兩個點由相鄰線在同一時刻產(chǎn)生,或由同一根線在相鄰時刻產(chǎn)生,則為兩個點建立一條邊。數(shù)學描述如下:
|l_i - l_j| = 1 and θ_i = θ_j
l_i = l_j and (θ_i - θ_j) mod 360 = r
這里r表示水平方向的最小旋轉(zhuǎn)角,上節(jié)例子中r=0.2。實際在建圖時會增加其他約束,比如兩個節(jié)點的距離不能太遠或兩個節(jié)點的高度差不能太大等。上節(jié)中點云的建圖結(jié)果可視化如下圖,深藍色表示滿足第一個條件的邊,淺藍色表示滿足第二個條件的邊。
圖4:在激光點云中直接根據(jù)三維點云信息建立Graph的可視化結(jié)果,其中深藍色的是縱向的邊,淺藍色的是橫向的邊。右側(cè)的圖是左側(cè)的局部放大版本。
建圖的目的是在空間中離散的三維點之間建立某種聯(lián)系,從而為后續(xù)的聚類和分割做準備。一般這種建圖的方法不設定邊的權重,依靠節(jié)點的特征進行聚類和分割。
Moosmann提出了一種使用法向量作為節(jié)點特征的方法【1】。其思路是將點云看成連續(xù)曲面上的離散采樣。所謂法向量是指曲面在每個節(jié)點處的法向量,如果兩個相鄰的節(jié)點的法向量相似則說明這兩個節(jié)點所在局部平面比較光滑,那么這兩個節(jié)點應當屬于一個同一個物體。論文中使用一種簡單快速的方法對于每個節(jié)點位置的法向量進行估計,即首先計算所有相鄰平面的法向量(如下圖藍色箭頭),然后求法向量的幾何平均值并進行歸一化(下圖紅色箭頭),最后所有節(jié)點的法向量再根據(jù)所有相鄰節(jié)點進行均值濾波。
圖5:節(jié)點法向量的可視化例子。紅色和藍色的圓形是節(jié)點,藍色的箭頭描述了每三個相鄰點組成的平面的法向量,紅色的箭頭描述了最終得到的法向量。
得到特征之后就可以根據(jù)相鄰節(jié)點之間的特征相似性進行聚類,聚類的首要目的一般是求出屬于地面的節(jié)點即地面分割。
Douillard為不同的數(shù)據(jù)類型提出了不同的地面分割方法【2】。其基于Graph結(jié)構的地面分割算法的核心思想是:首先確定屬于地面的種子節(jié)點然后由內(nèi)向外進行區(qū)域增長。
論文中提出的算法為了在處理各種邊緣情況的同時盡可能的增加地面節(jié)點的召回率,手工設定了一系列復雜的約束條件。這樣做確實在實驗指標上看起來好一些,但是在實際的應用中關注更多的并不是地面節(jié)點的召回,而是地面節(jié)點在所有可行駛區(qū)域內(nèi)的分布是否均勻。一般來說根據(jù)這個目標在實際場景中只用很簡單的決策樹,就可以建立出滿足應用要求的約束模型。Douillard在得到地面之后通過聚類算法找到其他類別的物體如下圖。
圖6:基于傳統(tǒng)方法的物體檢測的可視化結(jié)果,圖片引用于【2】
上面介紹的建圖的方法只能作用在低速單幀的數(shù)據(jù)中。因為在高速情況由于多普勒效應很難準確為每一個三維點找到其對應的雷達線數(shù)和水平旋轉(zhuǎn)角度,多幀的情況也類似。而更通用的建模方法是為每個節(jié)點尋找最鄰近的k的節(jié)點建立邊。這種方法雖然可以建立八叉樹等數(shù)據(jù)結(jié)構進行加速,但是沒有在Range Image中建圖的效率高。
2 基于Range Image的方法
Range Image是指距離圖,即一種類似圖片的數(shù)據(jù)結(jié)構。以上節(jié)32線激光雷達的數(shù)據(jù)為例子,對應的Range Image寬360/0.2=1800像素,高32像素。每個像素值表示對應點到原點的距離。上節(jié)中的點云對應的Range Image的的可視化如下圖,因為這個圖非常細長所以只截取了一小段。黑色的部分缺少對應的點云信息,其他的不同顏色代表不同距離。

圖7:一個Range Image的例子。
Zhu提出了一種在Range Image中建立無向圖G = {N, E}的方法【3】。即在圖中每一個像素代表一個節(jié)點,以每一個節(jié)點為中心在二維平面上以一定距離搜索其他節(jié)點,如果兩個節(jié)點在三維空間中滿足某些條件則建立一條邊,邊的權重是兩個點在三維空間中的距離。建圖之后使用基于圖的分割算法(例如【4】)即可得到聚類結(jié)果。
這種方法建圖的速度非常快,在實際使用過程中還需要處理多個點映射到同一個像素的情況,其建圖的結(jié)果和直接在三維點云中建圖相比非常接近。Range Image不僅僅能為計算進行提速,還可以做到一些不方便在點云上直接處理的事情,因為其比點云包含了更多的信息。
Biasutti提出了一種對點云中被遮擋的部分進行還原的方法【5】。其思路是:首先將點云生成Range Image結(jié)構并在其中進行聚類,然后選擇某個物體所代表的類并在圖中抹掉,之后根據(jù)周圍像素將抹掉的部分復原出來,最后將Range Image映射回點云。下圖是論文中的算法的結(jié)果,可以看出白色的行人被抹掉了,而地面上的空洞被漂亮的填充了。
圖8:被遮擋點云和還原被遮擋點云的對比圖,左圖是原始點云,右側(cè)是將人去掉后的點云。圖片引用于【5】。
基于深度學習的算法
現(xiàn)在在激光雷達數(shù)據(jù)目標檢測中最常用的算法是基于深度學習的算法,其效果與傳統(tǒng)學習算法相比要好很多,其中很多算法都采用了與圖片目標檢測相似的算法框架。
早期的激光點云上的目標檢測和圖片上的目標檢測算法并不一樣,圖片數(shù)據(jù)上常見的HOG、LBP和ACF【10,11,12】等算法并沒有應用到點云數(shù)據(jù)中。
這是因為激光點云數(shù)據(jù)與圖片具有不同的特點,例如圖片中存在遮擋和近大遠小的問題而點云上則沒有這些問題,反過來圖片中也并不存在上節(jié)中討論的點云的很多特點。
從2014年開始隨著RCNN、Fast RCNN、Faster RCNN、YOLO和SSD【1,2,3,4,5,6,7】等圖片目標檢測算法的進步,研究者對于檢測算法的理解也在不斷深入。
研究者發(fā)現(xiàn)雖然點云數(shù)據(jù)與圖片數(shù)據(jù)有很多不一樣的特點,但是在鳥瞰圖中這兩種不同的數(shù)據(jù)在目標檢測的框架下具有相通之處,因此基于鳥瞰圖的激光點云的目標檢測算法幾乎都沿用了圖片目標檢測算法的思路。
2016年PointNet【8】提出了另外的一種算法框架,其提出了一種在三維空間中與點云順序無關的算子并結(jié)合CNN也在目標分割和識別上得到了很好的效果。
這個方法為三維點云中的目標檢測提供了新的思路,即有可能存在一種比基于鳥瞰圖算法通用的三維目標檢測方法。
如前文所述激光點云數(shù)據(jù)有一些無法克服的問題,其中最主要的就是稀疏性。提高雷達的線數(shù)是一個解決問題的途徑,但是現(xiàn)有高線數(shù)雷達的成本過高很難真正落地,并且高線數(shù)也無法從根本上解決遠距離的稀疏問題。
為了解決這個問題一些研究者提出了激光數(shù)據(jù)和圖片數(shù)據(jù)相融合的方法,這種方法尤其對小物體和遠處的物體有很好的效果。
激光點云中目標檢測的結(jié)果的穩(wěn)定性也十分重要,傳統(tǒng)的檢測算法并不特別關注這個問題,其中一個原因是在后續(xù)的跟蹤和關聯(lián)算法中可以對檢測到的目標的大小、尺寸進行濾波,從而得到穩(wěn)定的結(jié)果。
近幾年一些研究者嘗試將“穩(wěn)定算法輸出”的任務交給深度神經(jīng)網(wǎng)絡,嘗試根據(jù)連續(xù)的多幀數(shù)據(jù)對當前幀進行檢測,這種方法可以增加算法輸出結(jié)果的穩(wěn)定性,減少后續(xù)跟蹤算法的復雜程度,提高整個系統(tǒng)的魯棒性。
接下來會介紹一些在基于單幀激光數(shù)據(jù)、圖片和激光融合以及基于連續(xù)多幀激光數(shù)據(jù)這三個方面具有代表性的算法。
1 基于單幀激光雷達數(shù)據(jù)的方法
Zhou提出的VoxelNet是一個在激光點云數(shù)據(jù)中利用圖片深度學習檢測框架的很好的例子【13】。其先將三維點云轉(zhuǎn)化成voxel結(jié)構,然后以鳥瞰圖的方式來處理這個結(jié)構。這里voxel結(jié)構是用相同尺寸的立方體劃分三維空間,這里每個立方體被稱為voxel即體素。舉一個空間劃分的例子,如果點云中的點在三維空間滿足
(x,y,z) ∈ [-100,100] x [-100,100] x [-1,3]
當設定voxel的尺寸為(1,1,1)時可以將空間劃分為200*200*4 = 160000個voxel。很多論文中稱這種結(jié)構的維度為2.5維,如果把每個格子都看成一個像素那么這是一種類似二維圖片的數(shù)據(jù)結(jié)構,而每個voxel的內(nèi)部是三維空間結(jié)構。
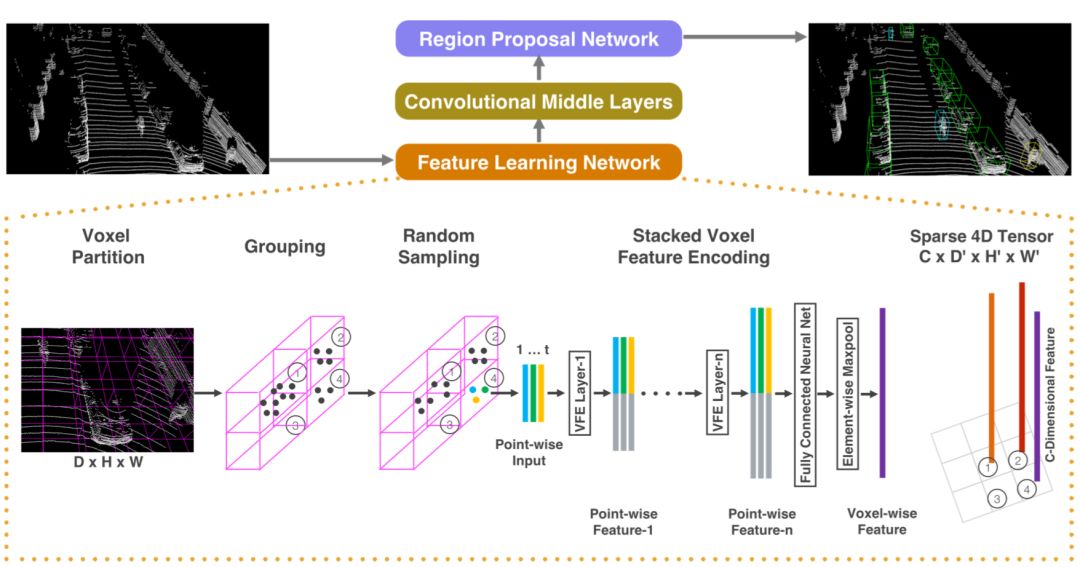
圖1:VoxelNet的算法流程圖,圖片引用于【13】
VoxelNet有兩個主要的過程,第一個被稱為VFE(Voxel Feature Extraction)是voxel的特征提取過程,第二個是類似YOLO的目標檢測過程。在VEF過程中所有voxel共享同一組參數(shù),這組參數(shù)描述了生成voxel的特征的方法。論文中VFE的過程由一系列CNN層組成如下圖。

圖2:VoxelNet算法中VFE部分的流程圖,圖片引用于【13】
VFE過程的結(jié)果是每個voxel都得到了長度相同的特征,將這些特征按照voxel的空間排列方式堆疊在一起形成了一個4維的特征圖,以上面的例子來說特征圖的尺寸為(200,200,4, l),這里l是voxel的特征長度。
在目標檢測過程中其首先將voxel特征通過三維卷積壓縮成3維的形式(200,200,l'),然后對得到的特征圖進行目標檢測。和二維圖片檢測相比VoxelNet不僅要給出物體中心的二維坐標和包圍盒的長寬,還需要給出物體中心在Z軸的位置、物體的高度和物體在XY平面上的朝向。
VoxelNet在實際使用中有兩個問題:首先在VFE過程中因為所有的voxel都共享同樣的參數(shù)和同樣的層,當voxel數(shù)量很大時在計算上會引入錯誤或效率問題,一些神經(jīng)網(wǎng)絡的框架例如Caffe在bn和scale層的實現(xiàn)時沒有考慮到這點,需要使用者自己去做調(diào)整;其次三維卷積操作的復雜度太高使得這個算法很難在自動駕駛車輛上實際使用的硬件設備上滿足實時性要求。
Yang提出的PixorNet算法可以在一定程度上解決上述問題【14】,首先其沒有VFE的過程,而是用手工設計的0-1的布爾變量和像素的反射強度表示每一個voxel,即每個voxel由兩個數(shù)值表示。其次PixorNet從4維到2維做的簡單的線性映射,即按照某種固定順序?qū)?200,200,4, l)整理成(200,200,4*l)的結(jié)構。
與VoxelNet相比PixorNet可以節(jié)約非常多的計算量,從而達到實時性的要求,但是因為其手工設計的特征過于簡單檢測效果不是特別好。
上述方法主要在鳥瞰圖上進行目標檢測,Qi提出了PointNet和PointNet++可以在三維空間中直接做分割和識別任務【8,9】。
PointNet首先為點云中每一個點計算特征(下圖中1024維),然后通過一個點云順序無關的操作(下圖max pool)將這些特征組合起來得到屬于全體點云的特征,這個特征可以直接用于識別任務。而將全局特征與每個點的特征組合到一起形成的新特征可以用于點云分割任務中。

圖3:PointNet的算法流程圖,圖片引用于【8】
PointNet在計算點的特征時共享一組參數(shù),這一點和VoxelNet很類似因此也有與之相同的問題。另外PointNet主要提取了所有點云組成的集合的全局特征,而沒有提取描述點與點之間關系的特征。將PointNet的方法類比到二維圖片中,可以看出其與傳統(tǒng)卷積神經(jīng)網(wǎng)絡的區(qū)別,即PointNet中沒有類似卷積的操作。
PointNet++主要解決的就是這個問題,其嘗試通過使用聚類的方法建立點與點之間的拓撲結(jié)構,并在不同粒度的聚類中心進行特征的學習。
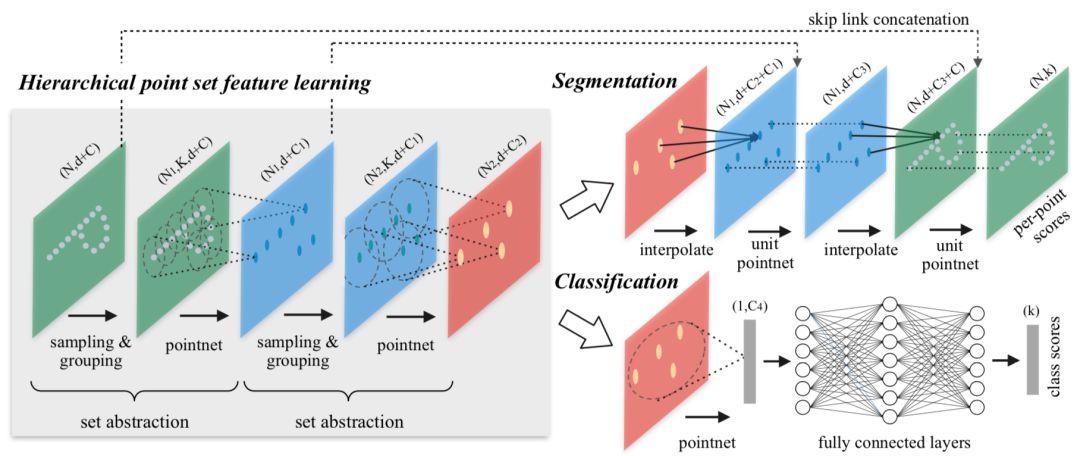
圖4:PointNet++的算法流程圖,圖片引用于【9】
這種方法確實比PointNet在分割算法中有所提高,但是將其直接用于檢測算法卻不能得到較好的結(jié)果。主要原因是在PointNet的結(jié)構中很難設計anchor。現(xiàn)在圖片中的檢測算法一般需要先在稠密的二維空間中提取anchor,然后再對anchor不斷過濾、回歸和分類。但是在PointNet++中處理的是稀疏的點云,在點云中很難確根據(jù)一個點確定物體的中心位置。
2 基于圖片和激光雷達數(shù)據(jù)的方法
從融合的時間點來看,多特征融合方法大致可以分為兩類:前融合和后融合。前融合首先將不同來源的數(shù)據(jù)的特征進行融合,然后對融合后的特征進行處理得到檢測的結(jié)果。后融合中不同特征分別經(jīng)過獨立的過程得到檢測結(jié)果,然后再將這些結(jié)果融合到一起。
兩種方法各有優(yōu)劣,前融合能夠更好的挖掘不同特征之間的聯(lián)系從而得到更好的檢測結(jié)果,而后融合從宏觀來看具有更強的系統(tǒng)穩(wěn)定性,當部分感知設備出現(xiàn)故障時只要還有一個設備在工作,那么就不會讓整個感知系統(tǒng)崩潰。
本節(jié)主要介紹一些前融合的相關算法。
近幾年出現(xiàn)了很多圖片和激光雷達數(shù)據(jù)融合的方法。Chen提出了MV3D的方法,其首先在不同數(shù)據(jù)上提取特征圖,然后在點云的鳥瞰圖中做三維物體檢測,之后將檢測的結(jié)果分別映射到鳥瞰圖、Range Image和圖片中,通過roi-pooling分別在三種特征圖中進行特征提取,最后將提取到的特征融合在一起再做后續(xù)的處理【16】。這個方法中檢測過程只在鳥瞰圖中進行,融合了鳥瞰圖、Range Image和圖片這三類數(shù)據(jù)源的特征。
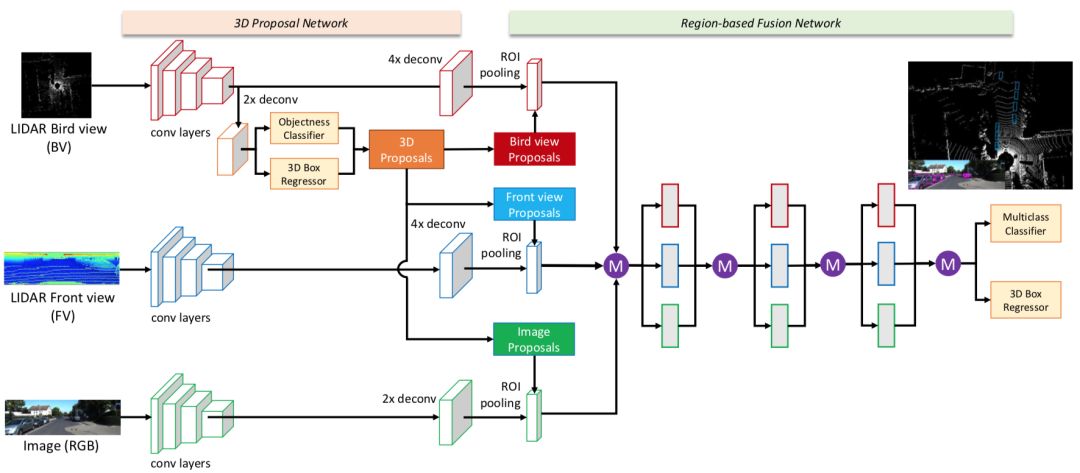
圖5:MV3D的算法流程圖, 圖片引用于【16】
Qi提出的FPointNet方法也使用了類似的思路,首先在圖片上做物體檢測,然后找到對應的物體的點云【18】。得到每個物體的點云之后,采用了類似PointNet的思路對物體的點云進行特征提取。
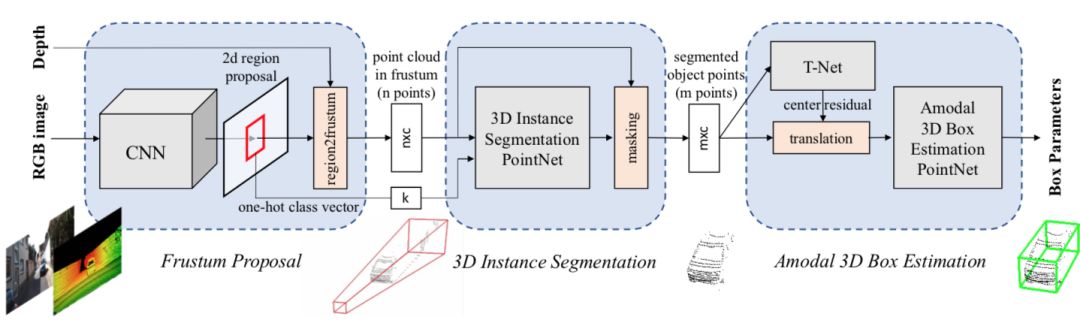
圖6:FPointNet的算法流程圖, 圖片引用于【18】
這兩個方法具有一定的共通之處:都具有似于FasterRCNN的兩段式(two-stage)檢測方法的串行過程,即先在某一種數(shù)據(jù)的特征圖上進行物體的檢測(這個過程也稱為proposal),然后根據(jù)檢測到的結(jié)果再在其他的數(shù)據(jù)中提取特征。這類方法的問題在于第一步proposal的過程并沒有引入其他的特征。上面討論過對于自動駕駛的檢測任務來說,召回率是非常重要的指標,而這類算法的召回率的上限直接與某一種數(shù)據(jù)類型綁定,并沒有很好地達到自動駕駛目標檢測中特征融合的目的。
Liang提出了一種將圖片特征融合到鳥瞰圖中的方法【19】。其核心思路是:對于鳥瞰圖中每個位置首先在三維空間中尋找臨近的點,然后把將這些點根據(jù)激光雷達和攝像機標定信息投影到圖片特征圖上,最后將對應的圖片特征和點的三維信息融合到鳥瞰圖對應的位置中。融合后的結(jié)果是得到了一個具有更多信息量的鳥瞰圖的特征圖。
這個特征圖中除了包含自帶的點云信息還包含了相關的圖片信息。后續(xù)的分割和檢測任務都基于這個特征圖。這個方法中雖然還是在鳥瞰圖中對物體進行檢測,但是由于此時特征圖中還包含了圖像信息,因此從理論上來說可以得到更高的召回率。

圖7:圖片特征與點云特征融合的算法流程圖,圖片引用于【19】
3 基于多幀激光雷達數(shù)據(jù)的方法
為了得到較穩(wěn)定的檢測結(jié)果,可以在后處理中增加約束、也可以在跟蹤算法中進行濾波。這些方法可以看作通過手工設計一些操作以減少各項檢測結(jié)果的方差,從現(xiàn)有的理論上來看,通過學習類算法自動設計相關操作應該有更好的效果。Luo利用深度神經(jīng)網(wǎng)絡在鳥瞰圖中通過連續(xù)幀的數(shù)據(jù)進行目標檢測【20】。
其建立了一個“多入多出”的結(jié)構,即算法的輸入是過去連續(xù)幀的鳥瞰圖,而算法的輸出是當前時刻和未來連續(xù)時刻的物體位置。Luo希望通過這種結(jié)構讓網(wǎng)絡不僅僅學習到物體在鳥瞰圖中的形狀,還可以學習到物體的速度、加速度信息。其步驟如下:
設當前幀為i并設定時間窗口k,選取第i-k+1幀到第i幀的點云,并將這些點云根據(jù)GPS/IMU的信息映射到第i幀的坐標系下;
分別提取這k幀點云的特征;
融合這些特征;
輸出第i幀和未來若干幀物體的信息,并建立軌跡。
這個方法可以在減少物體檢測的噪聲、增加召回率同時增加檢測結(jié)果的穩(wěn)定性。例如當?shù)缆飞夏齿v車突然被其他其他的車輛遮擋,由于前面若干幀中是存在這個車的點云的,所以此時是可以通過網(wǎng)絡猜測到其當前真實的位置。
當被遮擋的車輛逐漸脫離遮擋區(qū)域時,雖然歷史時刻中沒有其對應的點云信息,但是當前時刻存在其點云,所以同樣也可以檢測到其位置。
這篇文章從一定程度上證明了這樣做的可行性,但是還有一些方面值得繼續(xù)挖掘:更好的特征融合的方式、每次不重復提取幀的特征以及更好的處理軌跡的方法等。
總結(jié)
本文介紹了自動駕駛中常用的激光雷達的成像原理及其生成數(shù)據(jù)的特點,并簡單描述了相關的目標檢測的數(shù)據(jù)結(jié)構和算法。基于激光雷達數(shù)據(jù)的目標檢測不是一個很新的領域,但是隨著在深度學習的廣泛運用以及自動駕駛的興起,這個領域在這幾年不斷出現(xiàn)更好的方法。下表是對本文中提到的方法的簡單的總結(jié)。表中感知范圍一欄表示約束算法檢測范圍的最主要的傳感器。
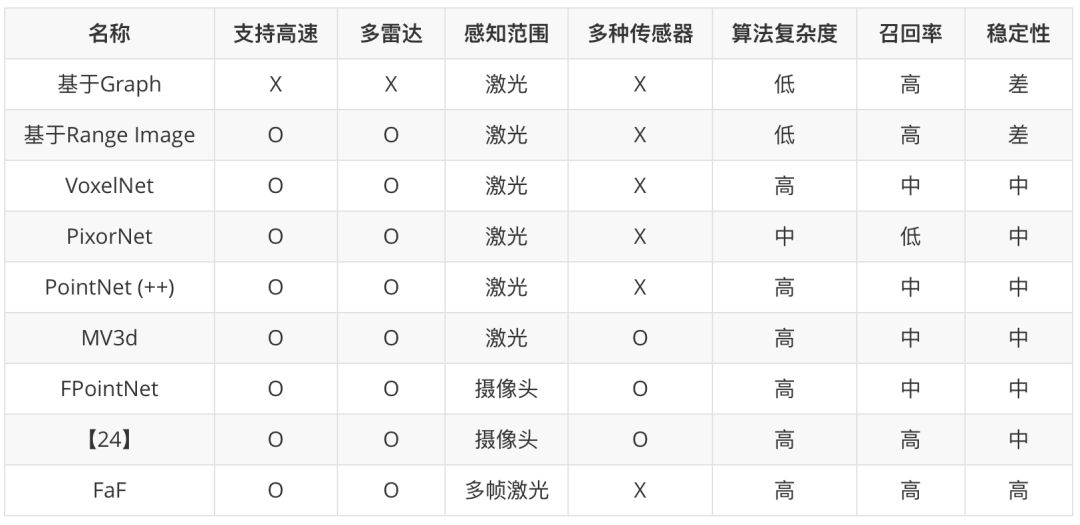
在實際中設計相關算法時一般不是完整地應用其中某一個方法,而是首先采用某個方法的工作流程作為主體框架,然后根據(jù)在實際情況中遇到的問題再不斷地對其進行修改。
從長遠來看,激光雷達未必是自動駕駛系統(tǒng)中必須的設備,因為多角度攝像頭的圖片結(jié)果理論上可以做到周圍空間的三維感知。但是就現(xiàn)階段來說,激光雷達還是一種非常可靠的感知手段。
隨著工藝的進步,激光雷達的線數(shù)和可視范圍會逐漸增加。對于目標檢測算法來說,高線數(shù)激光雷達的數(shù)據(jù)一定比低線數(shù)雷達的要好,但是高線數(shù)也對算法的速度有著更高的要求,所以相關算法的效率的提高可能會是一個研究的方向。
由于激光雷達的本身的特性,小物體、遠處物體和被遮擋物體的點云相對稀疏,提高這種情況下算法的效果可能會是相關研究的另一個方向。實際應用中激光雷達目標檢測可能面臨的問題更多,包括但不僅限于高效的數(shù)據(jù)標注、處理不平坦的地面、不同天氣的影響、不同物體材質(zhì)的區(qū)分、算法效果與復雜度的權衡、算法效果的評估等等。
希望這些問題可以隨著技術的發(fā)展逐步得到解決,未來可以真正實現(xiàn)安全便捷的自動駕駛。
參考文獻
[1] Moosmann, Frank, Oliver Pink, and Christoph Stiller. "Segmentation of 3D lidar data in non-flat urban environments using a local convexity criterion." Intelligent Vehicles Symposium, 2009 IEEE. IEEE, 2009.
[2] Douillard, Bertrand, et al. "On the segmentation of 3D LIDAR point clouds." Robotics and Automation (ICRA), 2011 IEEE International Conference on. IEEE, 2011.
[3] Zhu, Xiaolong, et al. "Segmentation and classification of range image from an intelligent vehicle in urban environment." Intelligent Robots and Systems (IROS), 2010 IEEE/RSJ International Conference on. IEEE, 2010.
[4] Felzenszwalb, Pedro F., and Daniel P. Huttenlocher. "Efficient graph-based image segmentation." International journal of computer vision 59.2 (2004): 167-181.
[5] Biasutti, Pierre, et al. "Disocclusion of 3D LiDAR point clouds using range images." ISPRS International Society for Photogrammetry and Remote Sensing (CMRT). 2017.
-
激光雷達
+關注
關注
971文章
4243瀏覽量
193086 -
自動駕駛
+關注
關注
790文章
14359瀏覽量
171037
原文標題:自動駕駛中的激光雷達目標檢測
文章出處:【微信號:IV_Technology,微信公眾號:智車科技】歡迎添加關注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
FPGA在自動駕駛領域有哪些應用?
淺析自動駕駛發(fā)展趨勢,激光雷達是未來?
激光雷達是自動駕駛不可或缺的傳感器
激光雷達在無人駕駛技術中的應用解析
激光雷達-無人駕駛汽車的必爭之地
成熟的無人駕駛方案離不開激光雷達
即插即用的自動駕駛LiDAR感知算法盒子 RS-Box
北醒固態(tài)設計激光雷達
固態(tài)設計激光雷達
從光電技術角度解析自動駕駛激光雷達
激光雷達成為自動駕駛門檻,陶瓷基板豈能袖手旁觀
LaserNet:基于激光雷達數(shù)據(jù)的激光網(wǎng)絡自動駕駛三維目標檢測





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論