 AI算法在FPGA芯片上的創新應用
AI算法在FPGA芯片上的創新應用
碾壓與崛起
AI算法的崛起并非一帆風順的,現在的主流的NN類的卷積神經網絡已經是第二波浪潮了,早在上個世紀80年代,源于仿生學,后又發展于概率學的早期AI算法已經取得了重大的進展,到1986年Rumelhart等人提出多層網絡的反向傳播算法(BP算法,這是AI算法可進行數據訓練并能收斂的基礎)后,第一波AI算法以“連接主義”的旗幟高高舉起。
不幸的是,旗幟沒舉多久就開始偃旗息鼓,讓位于基于統計學的算法,直到2006年,Hinton提出了“深度信念網絡”的概念,從此,AI算法從“連接主義”變成“深度神經網絡”再次華麗登場。
第一波AI算法之所以會快速落寞,不在于算法不夠精美,是因為當時的cpu不夠強大,算力完全無法適配當時的算法需求.第二次AI算法的崛起也并非算法足夠驚艷,恰恰是證明了算力的崛起。
而且這算力的提供者并不是CPU,這種基于調度和內存交換的方式難以支持如此強大的AI算力缺口。
與此同時,基于異構計算的ASIC/FPGA/GPU也在快速崛起,其計算性能完全碾壓CPU,有效的補充AI算力的缺口。
其中GPU迅速發展,成為目前AI崛起之路的最大收益者,然而GPU最初的設計目的不是針對AI算法而是處理圖形圖像的,因為圖像上每個像素點處理的過程和方式都十分相似,所以GPU的構成相對簡單,有數量眾多的計算單元和用于并行的流水線,正是這種單指令流多數據流的設計模式,特別適合處理大量的類型統一的數據。
這也是在用GPU處理AI算法時,batchsize不能太低的原因。而在其他方面,如面積/功耗/能耗比方面,GPU也便成了弱勢,相比較而言,ASIC芯片從一開始便是為AI而生,能效比高,不會有冗余,功耗低,適合算法穩定且要求的應用。
其缺點也是硬件為算法而定制,導致其只能運行特定的算法,當然,能做出通用AI算法的ASIC芯片是業界的終極目標。
而同時,作為ASIC的共軛形式存在的FPGA越來越受重視,FPGA能效比高,可編程邏輯,計算效率高,FPGA 同時擁有控制流并行和數據并行,是天生適合異構計算的芯片,目前開發FPGA應用方面還有很多潛能可挖。
通用Or靈活
一個基本的認知是ASIC雖然高效,但只能走專業化定制化的部分,ASIC制作成本很高,而算法一直在持續更新,如何解決這個矛盾呢?
是否可以做一個通用的ASIC來解決算力提升和靈活性的問題?寒武紀的NPU和google的TPU給出了答案,兩者的實現雖然不同,但思路是一致的。
即:既然NN算法可以拆分成不同的算子,設計的硬件建模應該全部支持這些算子從而解決通用性問題,并建立相應的指令集來解決不同算子的組合,來解決靈活性的問題。當然,核心模塊還是圍繞計算量最大的模塊卷積進行的。那么,在實現方式上它們又有哪些共同點和不足呢?
寒武紀dadiannao:
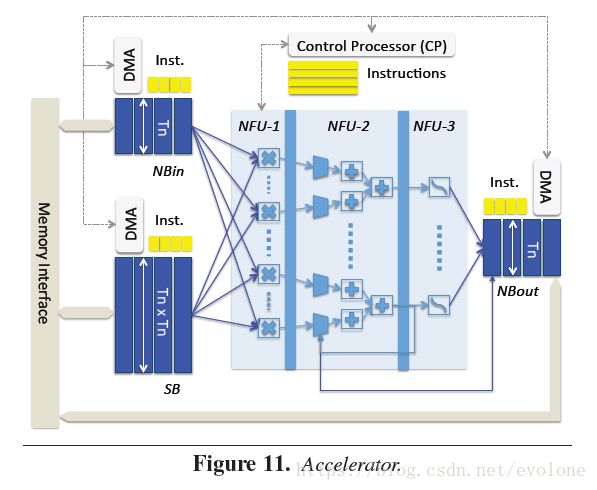
圖1 (dadiannao)
上圖的硬件建模就是在模仿神經網絡部分的數據流向,NFU(Neural Functional Units)分三部分順序展開,NFU-1是乘法單元,NFU-2是加法數樹,處理filter內部或通道累加的問題,NFU-3是激活單元。
從模型上不難看出,這里的核心處理卷積的單元是在數據流方向上的一維展開進行計算的。
一維度展開會帶來兩個問題,一個是多扇出(fan-out)的問題,如果想更大限度的利用內部數據帶寬優勢以及多用乘法器模塊,一個data需要同時廣播給多個計算單元,這會導致多扇出的問題,要保證多個模塊同時到達,則頻率就不能提的太高。
另外一個問題就是為了保證乘法器都能充分工作,需對filter的相關參數進行限制.以DianNao為例,一個PE中的16個mul是同時計算的,那么卷積層中的kernel、channel、windows的長和寬都會對計算的效率造成影響,如channel最好是16或16的倍數,否則就會造成計算資源的浪費.
相比較而言,Google的TPU采用脈動矩陣的方式,巧妙的避開了對filter敏感的問題,TPU的脈動矩陣是面向數據流方向的二維結構,在處理卷積乘加這塊有很強的優勢。
理論上可以支持任何形式的windows、kernel和channel這種設計使得TPU有更強的靈活性和高效性。
TPU:
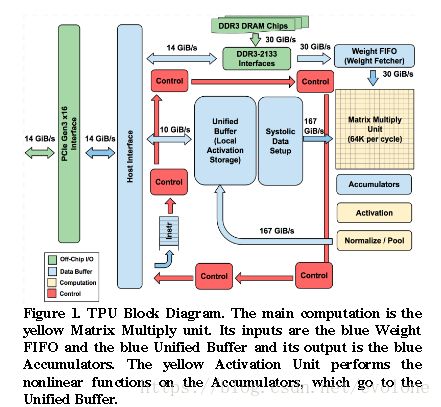
圖2 (TPU)
然而,有得必有失。脈動矩陣中處理卷積時優勢明顯,但在處理非卷積類算子方面則未必高效。
比如在fastRcnn中的要用到排序算法proposal層,又如在多網融合的過程中會經常被使用 interp層(雙線性插值)。
其中,排序算法在基因里是反asic的(區塊鏈中的零幣就是以排序為主的算法,主要用于反asic的功能)。類似這種非卷積算法因子則會導致脈動矩陣的功能大大降低,正是因為硬件的固定設置所限制。
ASIC 在走一個統一的路子,DADIANNAO和TPU都在用統一的模式來解決一切問題,然而現實是很骨感的,有兩個基本點是ASIC中無法完美解決的,一個就是AI算法在不同的探索和更改期。
目前尚未突破其中的黑盒特性,而支持AI算法優化的強有力的基礎理論遲遲沒有發現,這個時期就好比科學歷史上人們只知道電的存在而沒有電磁原理支撐是一個道理,說明AI算法的研究應處于發展初期。
另外一點就是針對各個垂直領域,如無人機/自動駕駛/智能安防/無人零售的各種特殊的情況,每一個領域都對功耗/能耗比/性能/系統等等方面有不同的訴求,這些需求都有極強的定制性。如此,想要一顆ASIC芯片通吃天下的事情似乎是個無法求出的解。
找規律,找突破
如果ASIC無法解決算法通用性問題,那么更具有靈活配置性的芯片FPGA便越來越受到重視,FPGA的低延時,高可配置性的特點使其天然的在靈活性方面比ASIC略勝一籌。
那么FPGA能否滿足統一性呢?其實,在業界對FPGA的探索一直沒有停止,
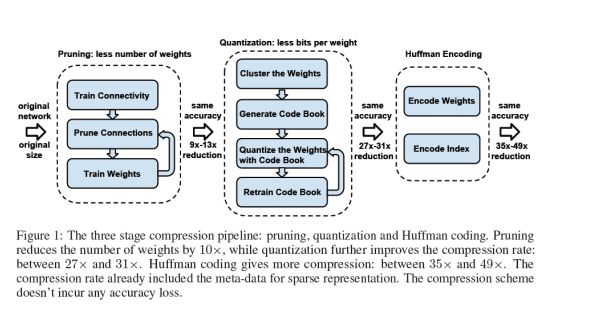
圖3(三級壓縮流水線)
國內FPGA的頭部公司深鑒科技一直研究深度壓縮技術,并在FPGA上實現了基于深度壓縮技術的方案:深度壓縮技術,其采用剪枝+量化+霍夫曼編碼,形成三級大流水,如圖3所示,實現高度壓縮權重占用的存儲空間。
其基本的思路就是,先對網絡本身做pruning來減少權重的個數,同時通過訓練來彌補由于減少權重而帶來的精度損失,然后經過量化部分來減少權重的位寬,最后用霍夫曼編碼來壓縮權重。
總之目的只有一個,制作稀疏矩陣,然后利用稀疏矩陣的特性生成weight查找表,從而達到數據壓縮的目的。數據壓縮后再用FPGA實現會大大的降低開發難度和門檻。
而國內另外一個頭部公司商湯科技的設計思想就是:通過大量減少卷積計算的乘法操作,降低運算復雜度,來提高運算速度,并在FPGA中順利實現。
不管是降低乘法操作,還是做網絡裁剪,其思路都是在修改算法的方式來適配FPGA的實現。
即先將FPGA的設計以固定的方式配置好,然后去修改算法來適配這種固定好的硬件設計。
這種方式的缺點也是顯而易見的,且不說固定的設計方式會遇到ASIC同樣的問題,單就修改網絡的部分可能會導致原有網絡的精度丟失的問題。
更為嚴重的是,這種設計方式會導致無法挖掘FPGA的全部潛力。
FPGA本身就是一個可編程系統,能夠適配各種算法,為什么大家都在想辦法修改算法問題,而沒有想辦法去修改FPGA的內部實現優化,從而完美的使其適配不同神經網絡算法呢?答案很簡單,用FPGA開發高難度的算法是一件很困難的事。
換一個語言,換一個世界
工欲善其事,必先利其器,現在主流的開發語言verilog HDL 是上個世紀80年代研究出來的,這在計算機界就好比是原始社會階段,而且這么多年來一直沒有更新過,對比高級語言的B->C->C++->java->python的不斷升級,它就好比一個古老的青銅寶劍,雖價值連城,但并不適用,而讓這個古老的語言來開發現在最先進的AI算法,這便是一個現代版的愚翁移山的故事。
接著探尋問題的本質,verilog的缺陷:
A)無規則化,或規范化,或許這是一個社會工程的問題,因為用的人少,所以沒有形成統一的規范,編程方式過分自由,基本上是一千個人里有一千個哈姆雷特。
B)遇到復雜的邏輯,只能用狀態機。
C)同步信號建模時,對控制信號的掌控偏弱。
D)沒有圖形化界面,仿真工具都是看波形。
而改進的方案正是解決這些問題,FPGA的開發就像是在玩樂高游戲,其實現過程就是在搭積木,其中的原語部分就是積木的原始器件,只是顆粒度有點小而已。
有沒有一種方式將原始器件進行封裝,加強控制邏輯,同時將控制邏輯和數據流邏輯分開,用軟件的思想來封裝硬件,包含繼承,多態,遞歸,然后以圖形化的形式展現出來,自帶仿真系統,所見即所得,利用核心庫器件,真正做到用搭積木的方式來開發FPGA,這樣便能大大降低其開發門檻。
有一種很好用的開發工具ptero,是雪湖信息科技公司自主研發的開發FPGA的工具鏈,可以顛覆對FPGA開發的認知,上文的種種特性都已經在該工具中實現,相當于用全新的語言來開發FPGA,且完全是界面化的形式進行開發,所見即所得,極大的降低了開發門檻并提高了開發效率。
舉個例子,在實現AI算法的過程中,對數據流的嚴格控制是關鍵,如下圖所示,圖中的例子是一個卷積核是3×3的數據組裝功能實現,一個數據產生器來模擬數據來源,補零模塊來進行padding補零操作,地址譯碼器來處理數據組裝需要的不斷變化的bram地址,三行緩存模塊完成數據的組裝。
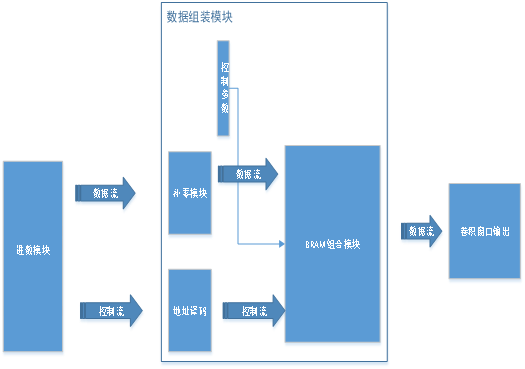
圖4 卷積里面的數據組裝模塊
圖4便是對上述流程的一個展示,從圖形化里面我們很容易理解設計思路,由于里面的用到的模塊都是在核心模塊封裝好。
所以,對開發人員來說,只需要將所有的精力都來放到邏輯這塊即可。
同時,可以隨時驗證邏輯的正確性,所有的輸出結果都可以打印輸出。這種所見即所得的開發模式極大的提高了硬件邏輯的開發效率。
那么,在FPGA實現的過程中,是否可以做出通用化的過程呢?答案是肯定的,如圖4中的紅色字體所示,控制參數部分就是自動更新的參數,通過自動化工具生成的控制參數能有效的控制不同算子模塊的實現,而無需改動硬件電路。
有了這樣方便又強大的工具,又有了底層封裝的模塊,才能在上層建筑有更大的發揮空間,就能更好的發揮FPGA的潛能,使其適配更多的算法結構,而不是只關注于修改算法來削足適履。
換一種維度思考
解決了開發FPGA效率的問題,我們可以把主要精力在提升FPGA的性能上下功夫,利用FPGA的分布式的存儲的思路來設計模型,將FPGA的性能提升到最高。
假設網絡結構中有三層卷積依次執行,如下圖所示:

圖5(卷積合并示例)
在這樣的網絡結構下,第一層是1×1的卷積核,第二層是3×3的depwise卷積運算,第三層又是一個1×1的卷積核,每層的conv模塊的kernel和channel都不是很大,類似這樣的網絡不同的算子組合在AI算法中很常見,若按傳統的思路,只能每層conv都單獨計算。
但每一層的計算都不能將FPGA的資源用滿(dsp&bram),這會導致資源的浪費,最重要的是沒有發揮FPGA的最大的性能,從而導致處理的幀率降低。
為了更好的利用FPGA 資源,挖掘FPGA的潛能,我們可以根據每層的資源分布做個統計,發現將上述三層的資源合并成一個全流水的方式(即一次IO讀寫,三層連續計算)才能將FPGA的潛能發揮到最大。
這種設計方案是根據算法的規律進行調整FPGA的組裝結構,從而發揮出并行計算的最大性能。
如此定制化的方式是發揮了FPGA的最大性能,那么又會產生一個問題:AI算法那么多,有沒有那種即能發揮FPGA的最大性能,又能有通用性的方法?
要回答這個問題,我們得先探究FPGA的本質,FPGA本質上是個分布式的資源分布系統,那么對核心資源(主要是dsp和bram)是否可以進行動態分配?
如果解決了這個問題,那么就能完美解決上述問題。
我們可以通過給相應模塊不同的參數來適配不同的算法因子以及不同的算法組合,而修改這些參數并不需要修改FPGA程序。
而對這種方式的探索,雪湖信息科技已經做了很多工作,并有相當多的積累,并有可以商用的成熟案例,如下圖,是我們生成參數的一角。
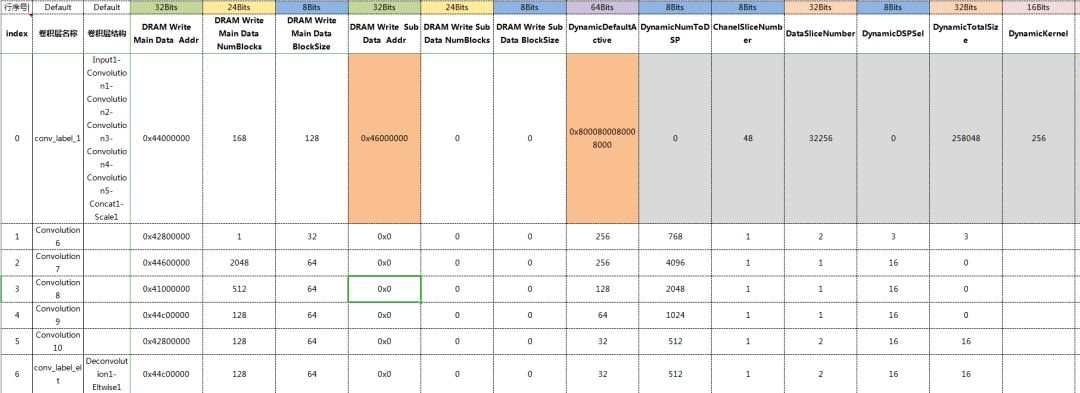
圖6(控制參數列表)
這樣的設計思路是根據不同的參數控制,針對不同的filter大小、不同的算子、不同的算子組合、不同的conv層的組合,來進行不同的控制。
這種設計兼顧了FPGA的靈活性和通用性,可以說著兼顧通用性的情況下最大限度的提高了FPGA資源的使用率,也不會出現設計硬傷,可以適配任何新的算子,對interp等非卷積類支持很充分。
而針對proposal層的處理,可以在采用將網絡一分為二,預留比較小的資源進行排序處理,而其他資源可以處理新的數據,兩者并行處理,只有控制邏輯和周期計算處理好,兩者不會產生阻塞和延時。
另一種維度的統一
反過來想,能否在保持FPGA靈活性的情況下,做成統一平臺,這種探索是可行的,這種探索雪湖信息科技一直在堅持。
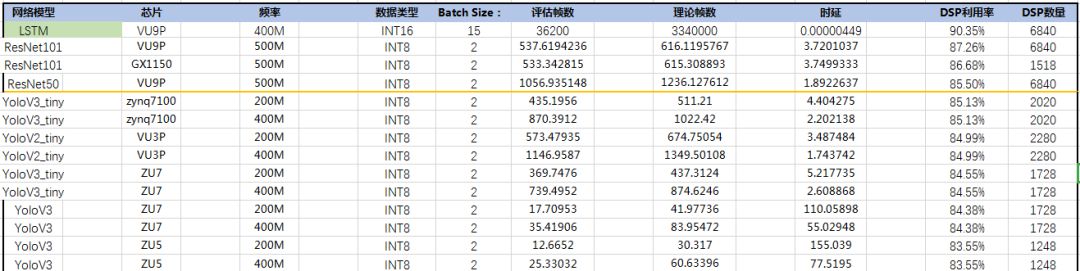
圖7(各個網絡/芯片平臺的評估數據表)
控制參數在處理平臺的靈活性,而模塊化的開發則是開發平臺的基石ptero在開發卷積過程中不斷的積累現有的卷積模塊/非卷積模塊,在不斷的打磨過程中將平臺的核心庫不斷的更新/優化,這些高效的模塊才是能兼顧通用和靈活的關鍵所在。
當這種模塊經過實踐證明可行之后,雪湖開發出了自動化工具平臺,該工具平臺包括自動解析網絡結構、生成控制參數、生成計算參數、推薦相應的模塊、分配合理的FPGA資源等等內容。
同時會包含自動測試部分,有了自動化工具的支持,對平臺的通用性和便捷性提到了一個新的高度。
如下圖,便是自動化測試工具測試示例:
已經實現的卷積算法計算量在5.3 Gflops左右(算法的細節涉及機密不便展開),用znq7020里進行實現,dsp利用率在88.88%左右,下圖為自動測試工具生成結果圖:
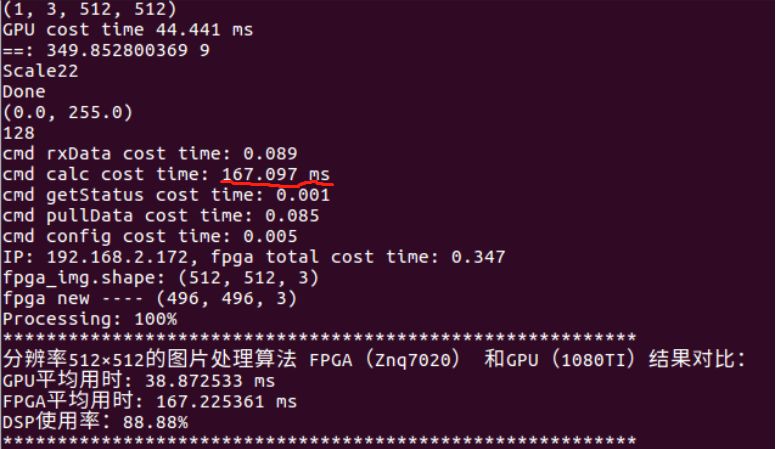
圖8(自動測試工具生成結果圖)
自動化工具是自適應FPGA開發平臺的濃縮表現,可以根據不同的算法推薦不同的方案,通過生成的不同的控制參數來合理的分配FPGA資源使用。隨著該平臺的不斷更新和升級,最終完成一鍵式端到端的FPGA實現方案。
通過這種方式,最終解決FPGA開發中通用性和靈活性的問題,這是雪湖不遺余力去追求的目標。
通過這種方式,不同的用戶可以根據自己的需求進行不同的配置,得到高性價比的FPGA開發方案。
同時,更重要的是該方案不需要修改網絡結構,不需要對用戶的數據進行重新訓練,從而保護用戶的核心資產。
而同時,由于FPGA的高度可配置性,當用戶的算法進行更新時,可以快速的修改和部署,這也是保護用戶投資的有效手段。
總之,從復雜到簡單,由繁瑣到簡潔,是事物發展的普遍規律。
而將FPGA開發的由難到易,以工具建平臺,以平臺來培養人才,在靈活易用的FPGA芯片上,解決應用開發難題,能夠加快AI算法的快速落地。
-
FPGA芯片
+關注
關注
3文章
246瀏覽量
40127 -
TPU
+關注
關注
0文章
151瀏覽量
21013 -
寒武紀
+關注
關注
11文章
198瀏覽量
74165 -
AI算法
+關注
關注
0文章
259瀏覽量
12535
原文標題:AI算法在FPGA芯片上還有這種操作?| 技術頭條
文章出處:【微信號:rgznai100,微信公眾號:rgznai100】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦





 工商網監
工商網監
評論