") 一文了解百度被收錄ACL 2019的10篇論文
一文了解百度被收錄ACL 2019的10篇論文
近日,自然語(yǔ)言處理(NLP)領(lǐng)域的國(guó)際頂級(jí)學(xué)術(shù)會(huì)議“國(guó)際計(jì)算語(yǔ)言學(xué)協(xié)會(huì)年會(huì)”(ACL 2019)公布了今年大會(huì)論文錄用結(jié)果。根據(jù) ACL 2019 官方數(shù)據(jù),今年大會(huì)的有效投稿數(shù)量達(dá)到 2694 篇,相比去年的 1544 篇增長(zhǎng)高達(dá) 75%。其中,百度共有 10 篇論文被大會(huì)收錄。
國(guó)際計(jì)算語(yǔ)言學(xué)協(xié)會(huì)(ACL,The Association for Computational Linguistics)成立于 1962 年,是自然語(yǔ)言處理領(lǐng)域影響力最大、最具活力的國(guó)際學(xué)術(shù)組織之一,自成立之日起就致力于推動(dòng)計(jì)算語(yǔ)言學(xué)及自然語(yǔ)言處理相關(guān)研究的發(fā)展和國(guó)際學(xué)術(shù)交流。百度高級(jí)副總裁、AI 技術(shù)平臺(tái)體系 (AIG) 和基礎(chǔ)技術(shù)體系(TG)總負(fù)責(zé)人王海峰曾于 2013 年出任 ACL 主席,是 ACL 五十多年歷史上首位華人主席,也是 ACL 亞太分會(huì)(AACL)的創(chuàng)始主席,ACL 會(huì)士。研究論文能夠被 ACL 學(xué)術(shù)年會(huì)錄用,意味著研究成果得到了國(guó)際學(xué)術(shù)界的認(rèn)可。
百度被錄用的 10 篇論文,覆蓋了信息抽取、機(jī)器閱讀理解、對(duì)話系統(tǒng)、視頻語(yǔ)義理解、機(jī)器翻譯等諸多 NLP 領(lǐng)域的熱點(diǎn)和前沿研究方向,提出了包括基于注意力正則化的 ARNOR 框架(Attention Regularization based NOise Reduction)、語(yǔ)言表示與知識(shí)表示深度融合的 KT-NET 模型、多粒度跨模態(tài)注意力機(jī)制、基于端到端深度強(qiáng)化學(xué)習(xí)的共指解析方法等,在人機(jī)交互、智能客服、視頻理解、機(jī)器翻譯等場(chǎng)景中具有很大的應(yīng)用價(jià)值。
附:百度被收錄 ACL 2019 論文概覽
ARNOR: Attention Regularization based Noise Reduction for Distant Supervision Relation Classification
摘要:遠(yuǎn)監(jiān)督通過(guò)知識(shí)庫(kù)自動(dòng)獲取標(biāo)注語(yǔ)料,是關(guān)系抽取的關(guān)鍵算法。但是遠(yuǎn)監(jiān)督通常會(huì)引入大量噪聲數(shù)據(jù),即句子并未表達(dá)自動(dòng)標(biāo)注的關(guān)系。進(jìn)一步說(shuō),基于遠(yuǎn)監(jiān)督學(xué)習(xí)的模型效果不佳、解釋性差,無(wú)法解釋關(guān)系的指示詞。
為此,我們提出基于注意力正則化的 ARNOR 框架(Attention Regularization based NOise Reduction)。此方法通過(guò)注意力機(jī)制,要求模型能夠關(guān)注關(guān)系的指示詞,進(jìn)而識(shí)別噪聲數(shù)據(jù),并通過(guò) bootstrap 方法逐步選擇出高質(zhì)量的標(biāo)注數(shù)據(jù),改善模型效果。此方法在關(guān)系分類及降噪上均顯著優(yōu)于此前最好的增強(qiáng)學(xué)習(xí)算法。
應(yīng)用價(jià)值:在文本信息抽取有廣泛的應(yīng)用價(jià)值。此方法能夠顯著降低對(duì)標(biāo)注數(shù)據(jù)的依賴,實(shí)現(xiàn)低成本的基于知識(shí)庫(kù)的自動(dòng)關(guān)系學(xué)習(xí),未來(lái)可落地在醫(yī)療、金融等行業(yè)信息抽取中。
Enhancing Pre-trained Language Representations with Rich Knowledge for Machine Reading Comprehension
摘要:機(jī)器閱讀理解 (Machine Reading Comprehension) 是指讓機(jī)器閱讀文本,然后回答和閱讀內(nèi)容相關(guān)的問(wèn)題。該技術(shù)可以使機(jī)器具備從文本數(shù)據(jù)中獲取知識(shí)并回答問(wèn)題的能力,是構(gòu)建通用人工智能的關(guān)鍵技術(shù)之一,長(zhǎng)期以來(lái)受到學(xué)術(shù)界和工業(yè)界的廣泛關(guān)注。近兩年,預(yù)訓(xùn)練語(yǔ)言表示模型在機(jī)器閱讀理解任務(wù)上取得了突破性進(jìn)展。通過(guò)在海量無(wú)標(biāo)注文本數(shù)據(jù)上預(yù)訓(xùn)練足夠深的網(wǎng)絡(luò)結(jié)構(gòu),當(dāng)前最先進(jìn)的語(yǔ)言表示模型能夠捕捉復(fù)雜的語(yǔ)言現(xiàn)象,更好地理解語(yǔ)言、回答問(wèn)題。然而,正如大家所熟知的,真正意義上的閱讀理解不僅要求機(jī)器具備語(yǔ)言理解的能力,還要求機(jī)器具備知識(shí)以支撐復(fù)雜的推理。為此,在論文《Enhancing Pre-trained Language Representations with Rich Knowledge for Machine Reading Comprehension》中,百度開(kāi)創(chuàng)性地提出了語(yǔ)言表示與知識(shí)表示的深度融合模型 KT-NET,希望同時(shí)借助語(yǔ)言和知識(shí)的力量進(jìn)一步提升機(jī)器閱讀理解的效果。
KT-NET 的模型架構(gòu)如下圖所示。首先,針對(duì)給定的閱讀內(nèi)容和結(jié)構(gòu)化知識(shí)圖譜,分別利用語(yǔ)言表示模型和知識(shí)表示模型對(duì)兩者進(jìn)行編碼,得到相應(yīng)的文本表示和知識(shí)表示。接下來(lái),利用注意力機(jī)制從知識(shí)圖譜中自動(dòng)篩選并整合與閱讀內(nèi)容高度相關(guān)的知識(shí)。最后,通過(guò)雙層自注意力匹配,實(shí)現(xiàn)文本表示和知識(shí)表示的深度融合,提升答案邊界預(yù)測(cè)的準(zhǔn)確性。截止到發(fā)稿日,KT-NET 仍然是常識(shí)推理閱讀理解數(shù)據(jù)集 ReCoRD 榜單上排名第一的模型,并在此前很長(zhǎng)一段時(shí)期內(nèi)都是 SQuAD 1.1 榜單上效果最好的單模型。
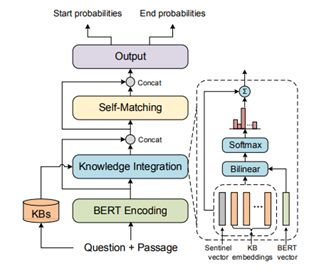
KT-NET: 語(yǔ)言表示與知識(shí)表示的深度融合模型
應(yīng)用價(jià)值:該項(xiàng)技術(shù)可應(yīng)用于搜索問(wèn)答、智能音箱等產(chǎn)品中,直接精準(zhǔn)定位用戶輸入問(wèn)題的答案,并在搜索結(jié)果首條顯著位置呈現(xiàn)或通過(guò)語(yǔ)音播報(bào)呈現(xiàn)給用戶。
Know More about Each Other: Evolving Dialogue Strategy via Compound Assessment
摘要:現(xiàn)有的基于監(jiān)督學(xué)習(xí)的對(duì)話系統(tǒng),缺乏對(duì)多輪回復(fù)方向的控制和規(guī)劃,通常導(dǎo)致對(duì)話中發(fā)生重復(fù)、發(fā)散等問(wèn)題,使得用戶的交互體驗(yàn)偏差。 在本文中,我們對(duì)多輪對(duì)話進(jìn)行了復(fù)合評(píng)估 (compound assessment),并基于該評(píng)估利用強(qiáng)化學(xué)習(xí)優(yōu)化兩個(gè)自對(duì)話 (self-play) 的機(jī)器人,促進(jìn)生成過(guò)程中較好地控制多輪對(duì)話的方向。考慮到對(duì)話的一個(gè)主要?jiǎng)訖C(jī)是進(jìn)行有效的信息交換,針對(duì) Persona Chat 問(wèn)題(兩個(gè)人相互對(duì)話聊興趣愛(ài)好),我們?cè)O(shè)計(jì)了一個(gè)較為完善的評(píng)估系統(tǒng),包括對(duì)話的信息量和連貫度兩個(gè)主要方面。我們利用復(fù)合評(píng)估作為 reward,基于策略梯度算法 (policy gradient),指導(dǎo)優(yōu)化兩個(gè)同構(gòu)的對(duì)話生成機(jī)器人之間的對(duì)話策略 (dialogue strategy)。該對(duì)話策略通過(guò)控制知識(shí)的選擇來(lái)主導(dǎo)對(duì)話的流向。 我們公開(kāi)數(shù)據(jù)集上進(jìn)行了全面的實(shí)驗(yàn),結(jié)果驗(yàn)證了我們提出的方法生成的多輪對(duì)話質(zhì)量,顯著超過(guò)其他最優(yōu)方法。
應(yīng)用價(jià)值:可應(yīng)用于對(duì)話系統(tǒng)、智能客服。
Proactive Human-Machine Conversation with Explicit Conversation Goal
摘要:目前的人機(jī)對(duì)話還處于初級(jí)水平,機(jī)器大多是被動(dòng)對(duì)話,無(wú)法像人類一樣進(jìn)行充分交互。我們提出了基于知識(shí)圖譜的主動(dòng)對(duì)話任務(wù),讓機(jī)器像人類一樣主動(dòng)和用戶進(jìn)行對(duì)話。對(duì)話過(guò)程中,機(jī)器根據(jù)知識(shí)圖譜主動(dòng)引領(lǐng)對(duì)話進(jìn)程完成提前設(shè)定的話題 (實(shí)體) 轉(zhuǎn)移目標(biāo),并保持對(duì)話的自然和流暢性。為此,我們?cè)陔娪昂蛫蕵?lè)任務(wù)領(lǐng)域人工標(biāo)注 3 萬(wàn)組共 27 萬(wàn)個(gè)句子的主動(dòng)對(duì)話語(yǔ)料,并實(shí)現(xiàn)了生成和檢索的兩個(gè)主動(dòng)對(duì)話基線模型。
應(yīng)用價(jià)值:可應(yīng)用于智能音箱中的對(duì)話技能,也可以基于此開(kāi)發(fā)閑聊技能,讓機(jī)器主動(dòng)發(fā)起基于知識(shí)圖譜的聊天。
Multi-grained Attention with Object-level Grounding for Visual Question Answering
摘要:視覺(jué)問(wèn)答 (VQA) 是一類跨模態(tài)信息理解任務(wù),要求系統(tǒng)理解視覺(jué)圖片信息,并回答圍繞圖片內(nèi)容的文本問(wèn)題。這篇文章提出一種多粒度跨模態(tài)注意力機(jī)制,在圖片 - 句子粒度注意力的基礎(chǔ)上,提出更細(xì)粒度的物體級(jí)別跨模態(tài)信息注意力機(jī)制,并給出 2 種有效的細(xì)粒度信息理解增強(qiáng)的方法。實(shí)驗(yàn)表明我們的方法有助于對(duì)復(fù)雜圖像和細(xì)小物體的識(shí)別,使系統(tǒng)更準(zhǔn)確地定位到回答文本問(wèn)題所依賴的視覺(jué)信息,從而顯著提升 VQA 準(zhǔn)確率。
應(yīng)用價(jià)值:可應(yīng)用于基于多模態(tài)信息和知識(shí)圖譜的小視頻內(nèi)容理解項(xiàng)目。
Hubless Nearest Neighbor Search for Bilingual Lexicon Induction
摘要:這項(xiàng)基礎(chǔ)研究提出了一種提高最近鄰搜索的方法。該方法有非常漂亮的理論基礎(chǔ),不僅能顯著提升雙語(yǔ)詞典編纂(Bilingual Lexicon Induction)的準(zhǔn)確率,對(duì)涉及最近鄰搜索的很多任務(wù)都有指導(dǎo)意義。
應(yīng)用價(jià)值:機(jī)器翻譯需要大量對(duì)齊的雙語(yǔ)文本作為訓(xùn)練數(shù)據(jù)。這一要求在某些情況下不能被滿足,比如小語(yǔ)種文本,專業(yè)文獻(xiàn)。雙語(yǔ)詞典編纂在這種情況下能提升翻譯系統(tǒng)的準(zhǔn)確率。
STACL: Simultaneous Translation with Implicit Anticipation and Controllable Latency
摘要:同聲翻譯是人工智能領(lǐng)域公認(rèn)的最難問(wèn)題之一,已經(jīng)困擾學(xué)術(shù)界和工業(yè)界幾十年了。我們提出了歷史上第一個(gè)超前預(yù)測(cè)和可控延遲的同聲翻譯算法。去年 10 月發(fā)布以來(lái),被各大技術(shù)外媒廣泛報(bào)導(dǎo),包括 MIT 技術(shù)評(píng)論、IEEE Spectrum、財(cái)富雜志等。量子位總結(jié)報(bào)道:“這是 2016 年百度 Deep Speech 2 發(fā)布以來(lái),又一項(xiàng)讓技術(shù)外媒們?nèi)绱思?dòng)的新進(jìn)展。”
應(yīng)用價(jià)值:2018 年 11 月的百度世界大會(huì)采用了這項(xiàng)同傳技術(shù),全程同傳翻譯了 Robin 所有演講,延遲僅為 3 秒左右,而之前的整句翻譯技術(shù)延遲為一整句(可達(dá) 10 秒以上)。同時(shí),翻譯質(zhì)量也沒(méi)有明顯的下降。
Simultaneous Translation with Flexible Policy via Restricted Imitation Learning
摘要:本文旨在提高同聲翻譯的質(zhì)量。我們?nèi)ツ晏岢龅?STACL 框架(即上述文章 7)雖然簡(jiǎn)單有效,但有時(shí)不夠靈活。現(xiàn)在我們提出一種基于模仿學(xué)習(xí)的同聲翻譯算法,通過(guò)模仿本文設(shè)計(jì)的動(dòng)態(tài)策略,該模型可以實(shí)時(shí)靈活地決定是否需要等待更多信息來(lái)繼續(xù)翻譯,進(jìn)而在保持低延遲的情況下提高了翻譯質(zhì)量。
應(yīng)用價(jià)值:該技術(shù)可用于同聲傳譯系統(tǒng)。
Robust Neural Machine Translation with Joint Textual and Phonetic Embedding
摘要:該文章旨在提高翻譯的魯棒性,特別是對(duì)同音詞噪音的魯棒性。我們?cè)诜g的輸入端,通過(guò)聯(lián)合嵌入的方式,加入輸入單詞對(duì)應(yīng)的發(fā)音信息。實(shí)驗(yàn)結(jié)果表明,該方法不僅大大提高了翻譯系統(tǒng)在噪聲情況下的魯棒性,也大幅提高了翻譯系統(tǒng)在非噪聲情況下的性能。
應(yīng)用價(jià)值:可用于翻譯,特別是語(yǔ)音到語(yǔ)音的同聲傳譯系統(tǒng)。語(yǔ)音翻譯的一個(gè)主要難題是語(yǔ)音識(shí)別的錯(cuò)誤太多,而這些錯(cuò)誤大多是同音詞或發(fā)音相似的單詞,此技術(shù)可以很大程度上降低這些來(lái)自于語(yǔ)音識(shí)別的噪音。
End-to-end Deep Reinforcement Learning Based Coreference Resolution
摘要:共指解析是信息抽取任務(wù)中不可或缺的組成部分。近期的基于端到端深度神經(jīng)網(wǎng)絡(luò)的方法,往往通過(guò)優(yōu)化啟發(fā)式的損失函數(shù)并做出一系列局部解析決策,缺乏對(duì)整個(gè)篇章的理解。本文首次提出了基于端到端深度強(qiáng)化學(xué)習(xí)的共指解析方法,在同一框架內(nèi)完成指稱檢測(cè)和指稱鏈接,并且直接優(yōu)化共指解析的評(píng)價(jià)指標(biāo),在 OntoNotes 上取得了良好效果。
應(yīng)用價(jià)值:知可用于識(shí)圖譜構(gòu)建,信息抽取。
-
百度
+關(guān)注
關(guān)注
9文章
2330瀏覽量
91934 -
論文
+關(guān)注
關(guān)注
1文章
103瀏覽量
15161 -
ACL
+關(guān)注
關(guān)注
0文章
61瀏覽量
12373
原文標(biāo)題:史上最大規(guī)模ACL大會(huì)放榜,百度10篇NLP論文被錄用!
文章出處:【微信號(hào):rgznai100,微信公眾號(hào):rgznai100】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
后摩智能四篇論文入選三大國(guó)際頂會(huì)
云知聲四篇論文入選自然語(yǔ)言處理頂會(huì)ACL 2025

百度文心大模型X1 Turbo獲得信通院當(dāng)前大模型最高評(píng)級(jí)證書






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論