") 無(wú)需權(quán)重訓(xùn)練!谷歌再向深度學(xué)習(xí)煉丹術(shù)發(fā)起 “攻擊”
無(wú)需權(quán)重訓(xùn)練!谷歌再向深度學(xué)習(xí)煉丹術(shù)發(fā)起 “攻擊”

神經(jīng)網(wǎng)絡(luò)訓(xùn)練中“權(quán)重”有多重要不言而喻。但現(xiàn)在,可以把權(quán)重拋諸腦后了。谷歌大腦最新研究提出“權(quán)重?zé)o關(guān)神經(jīng)網(wǎng)絡(luò)”,通過(guò)不再?gòu)?qiáng)調(diào)權(quán)重來(lái)搜索網(wǎng)絡(luò)結(jié)構(gòu),所搜索的網(wǎng)絡(luò)無(wú)需權(quán)重訓(xùn)練即可執(zhí)行任務(wù)!
還在為 “調(diào)參煉丹” 感到痛苦嗎?是時(shí)候重視下神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu)了!
前不久,新智元報(bào)道了谷歌給出首個(gè)神經(jīng)網(wǎng)絡(luò)訓(xùn)練理論的證明。這一研究在訓(xùn)練深度神經(jīng)網(wǎng)絡(luò)被戲謔為 “調(diào)參煉丹” 的當(dāng)下,猶如一道希望的強(qiáng)光,射進(jìn)還被排除在 “科學(xué)” 之外的深度學(xué)習(xí)領(lǐng)域,激動(dòng)人心。
而今天,谷歌再向煉丹術(shù)發(fā)起 “攻擊”:提出一種神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu)的搜索方法,該方法無(wú)需任何顯式的權(quán)值訓(xùn)練即可執(zhí)行任務(wù)!

arXiv 地址:
https://arxiv.org/pdf/1906.04358.pdf
這項(xiàng)研究的作者之一David Ha發(fā)表 Twitter 表示:
這項(xiàng)研究的關(guān)鍵思想是通過(guò)不再?gòu)?qiáng)調(diào)權(quán)重來(lái)搜索網(wǎng)絡(luò)結(jié)構(gòu)。
在搜索過(guò)程中,網(wǎng)絡(luò)每次在 rollout 的時(shí)候會(huì)分配一個(gè)共享的權(quán)重值,并進(jìn)行優(yōu)化,這就讓它能夠在很大的權(quán)重值范圍內(nèi)良好運(yùn)行。
這樣做的好處就是可以繞過(guò)高昂的內(nèi)部訓(xùn)練循環(huán)代價(jià)。
這項(xiàng)工作是由 Adam Gaier 所領(lǐng)導(dǎo)的,他在東京的谷歌大腦實(shí)習(xí)了 3 個(gè)月。特別有意思的是,這個(gè)研究想法是他在六本木喝了幾杯酒之后產(chǎn)生的。
Adam Gaier是一名AI研究員,在教學(xué)和研究方面具有廣泛的國(guó)際經(jīng)驗(yàn),在生物啟發(fā)的計(jì)算、機(jī)器人和機(jī)器學(xué)習(xí)方面有很強(qiáng)的背景。目前的研究主要集中在機(jī)器學(xué)習(xí)和進(jìn)化計(jì)算的集成上,其目標(biāo)是將人工智能應(yīng)用于現(xiàn)實(shí)世界的設(shè)計(jì)和控制問(wèn)題。
Adam Gaier的經(jīng)歷也頗為神奇,LinkedIn資料顯示,他本科在英國(guó)里士滿(mǎn)美國(guó)國(guó)際大學(xué)讀信息系統(tǒng)專(zhuān)業(yè),后又在英國(guó)薩塞克斯大學(xué)和德國(guó)波恩-萊茵-錫格應(yīng)用技術(shù)大學(xué)分別獲得碩士學(xué)位,攻讀自主系統(tǒng)專(zhuān)業(yè)。
而在2005年本科畢業(yè)到2011年再次回到學(xué)校的期間,有兩年半的時(shí)間 Adam Gaier 在北京烏巢餐廳擔(dān)任餐廳經(jīng)理、市場(chǎng)及 IT 總監(jiān);然后在清華大學(xué)國(guó)際學(xué)校,計(jì)算機(jī)科學(xué)系系主任。2019年1月至今他在谷歌大腦東京部門(mén)擔(dān)任實(shí)習(xí)研究員。
接下來(lái),新智元帶來(lái)這篇論文的詳細(xì)解讀:
無(wú)需學(xué)習(xí)權(quán)重,“一出生”就很秀的神經(jīng)網(wǎng)絡(luò)
在生物學(xué)中,早成物種(precocial species)是指那些從出生的那一刻起就具有某些能力的物種。有證據(jù)表明,蜥蜴和蛇的幼仔一出生就具備了躲避捕食者的行為,鴨子剛孵化后不久就能自己游泳和進(jìn)食。相反,我們?cè)谟?xùn)練AI智能體執(zhí)行任務(wù)時(shí),通常要選擇一個(gè)我們認(rèn)為適合為任務(wù)編碼策略的神經(jīng)網(wǎng)絡(luò)架構(gòu),并使用學(xué)習(xí)算法找到該策略的權(quán)重參數(shù)。
在這項(xiàng)工作中,我們受到自然界進(jìn)化的早成行為的啟發(fā),開(kāi)發(fā)了具有自然就能夠執(zhí)行給定任務(wù)的架構(gòu)的神經(jīng)網(wǎng)絡(luò),即使其權(quán)重參數(shù)是隨機(jī)采樣的。通過(guò)使用這樣的神經(jīng)網(wǎng)絡(luò)架構(gòu),AI智能體可以在不需要學(xué)習(xí)權(quán)重參數(shù)的情況下在其環(huán)境中運(yùn)行良好。
權(quán)重?zé)o關(guān)神經(jīng)網(wǎng)絡(luò)的例子:兩足步行者(左),賽車(chē)(右)
我們通過(guò)不再?gòu)?qiáng)調(diào)權(quán)重(deemphasizing weights)來(lái)搜索神經(jīng)網(wǎng)絡(luò)架構(gòu)。在每次rollout,網(wǎng)絡(luò)都被分配一個(gè)單獨(dú)的共享權(quán)重值來(lái)代替訓(xùn)練。在很大范圍的權(quán)重值上為預(yù)期性能進(jìn)行優(yōu)化的網(wǎng)絡(luò)結(jié)構(gòu)仍然能執(zhí)行各種任務(wù),而無(wú)需權(quán)重訓(xùn)練。
數(shù)十年的神經(jīng)網(wǎng)絡(luò)研究為各種任務(wù)領(lǐng)域提供了具有很強(qiáng)歸納偏差的構(gòu)建塊。卷積網(wǎng)絡(luò)特別適合于圖像處理。例如,Ulyanov等人證明,即使是一個(gè)隨機(jī)初始化的CNN也可以用作圖像處理任務(wù)(如超分辨率和圖像修復(fù))的手工預(yù)處理。Schmidhuber等人證明,具有學(xué)習(xí)線性輸出層的隨機(jī)初始化LSTM可以預(yù)測(cè)傳統(tǒng)RNN失效的時(shí)間序列。self-attention和capsule網(wǎng)絡(luò)的最新發(fā)展擴(kuò)展了構(gòu)建模塊的工具包,用于為各種任務(wù)創(chuàng)建具有強(qiáng)烈歸納偏差的架構(gòu)。
被隨機(jī)初始化的CNN和LSTM的內(nèi)在能力所吸引,我們的目標(biāo)是搜索與權(quán)重?zé)o關(guān)的神經(jīng)網(wǎng)絡(luò)(weight agnostic neural networks),這種結(jié)構(gòu)具有很強(qiáng)的歸納偏差,已經(jīng)可以使用隨機(jī)權(quán)重執(zhí)行各種任務(wù)。
MNIST分類(lèi)網(wǎng)絡(luò)演化為使用隨機(jī)權(quán)重
使用隨機(jī)權(quán)重的網(wǎng)絡(luò)架構(gòu)不僅易于訓(xùn)練,而且還提供了其他優(yōu)勢(shì)。例如,我們可以為同一個(gè)網(wǎng)絡(luò)提供一個(gè)(未經(jīng)訓(xùn)練的)權(quán)重集合來(lái)提高性能,而不需要顯式地訓(xùn)練任何權(quán)重參數(shù)。
具有隨機(jī)初始化的傳統(tǒng)網(wǎng)絡(luò)在MNIST上的精度約為10%,但這種隨機(jī)權(quán)重的特殊網(wǎng)絡(luò)架構(gòu)在MNIST上的精度(> 80%)明顯優(yōu)于隨機(jī)初始化網(wǎng)絡(luò)。在沒(méi)有進(jìn)行任何權(quán)重訓(xùn)練的情況下,當(dāng)我們使用一組未經(jīng)訓(xùn)練的權(quán)重時(shí),精度提高到> 90%。
為了尋找具有強(qiáng)歸納偏差的神經(jīng)網(wǎng)絡(luò)架構(gòu),我們提出通過(guò)降低權(quán)重的重要性來(lái)搜索架構(gòu)。
具體實(shí)現(xiàn)方法是:
(1)為每個(gè)網(wǎng)絡(luò)連接分配一個(gè)共享權(quán)重參數(shù);
(2)在此單一權(quán)重參數(shù)的大范圍內(nèi)評(píng)估網(wǎng)絡(luò)。
我們沒(méi)有優(yōu)化固定網(wǎng)絡(luò)的權(quán)重,而是優(yōu)化在各種權(quán)重范圍內(nèi)性能良好的網(wǎng)絡(luò)結(jié)構(gòu)。我們證明了,我們的方法能夠產(chǎn)生可以預(yù)期用隨機(jī)權(quán)重參數(shù)執(zhí)行各種連續(xù)控制任務(wù)的網(wǎng)絡(luò)。
作為概念證明,我們還將搜索方法應(yīng)用于監(jiān)督學(xué)習(xí)領(lǐng)域,發(fā)現(xiàn)它可以找到即使沒(méi)有顯式的權(quán)重訓(xùn)練也可以在MNIST上獲得比chance test準(zhǔn)確率高得多(~92%)的網(wǎng)絡(luò)。
我們希望對(duì)這種權(quán)重?zé)o關(guān)的神經(jīng)網(wǎng)絡(luò)的demo將鼓勵(lì)進(jìn)一步研究探索新的神經(jīng)網(wǎng)絡(luò)構(gòu)建塊,不僅具有有用的歸納偏差,而且還可以使用不一定限于基于梯度的方法的算法來(lái)學(xué)習(xí)。
Demo:
一個(gè)執(zhí)行CartpoleSwingup任務(wù)的權(quán)重?zé)o關(guān)神經(jīng)網(wǎng)絡(luò)。請(qǐng)點(diǎn)擊本文原文鏈接,拖動(dòng)滑塊控制權(quán)重參數(shù),觀察不同共享權(quán)重參數(shù)下的性能。你也可以在這個(gè)demo中微調(diào)所有連接的各個(gè)權(quán)重。
關(guān)鍵技術(shù)解析:權(quán)重?zé)o關(guān)神經(jīng)網(wǎng)絡(luò)搜索
創(chuàng)建編碼解決方案的網(wǎng)絡(luò)架構(gòu)是一個(gè)與神經(jīng)結(jié)構(gòu)搜索(NAS)所解決的問(wèn)題完全不同的問(wèn)題。NAS技術(shù)的目標(biāo)是產(chǎn)生經(jīng)過(guò)訓(xùn)練的架構(gòu),其性能優(yōu)于人類(lèi)設(shè)計(jì)的架構(gòu)。從沒(méi)有人聲稱(chēng)這個(gè)解決方案是網(wǎng)絡(luò)結(jié)構(gòu)固有的。NAS創(chuàng)建的網(wǎng)絡(luò)“可訓(xùn)練”——但沒(méi)有人認(rèn)為這些網(wǎng)絡(luò)在不訓(xùn)練權(quán)重的情況下就能解決任務(wù)。權(quán)重就是解決方案;所發(fā)現(xiàn)的結(jié)構(gòu)僅僅是一個(gè)更好的承載權(quán)重的基底。
要生成自己編碼解決方案的架構(gòu),就必須將權(quán)重的重要性降到最低。與其用最優(yōu)權(quán)重來(lái)判斷網(wǎng)絡(luò)的性能,不如根據(jù)隨機(jī)分布的權(quán)重來(lái)衡量網(wǎng)絡(luò)的性能。用權(quán)重采樣代替權(quán)重訓(xùn)練可以確保性能僅是網(wǎng)絡(luò)拓?fù)浣Y(jié)構(gòu)的產(chǎn)品。
不幸的是,由于高維數(shù),除了最簡(jiǎn)單的網(wǎng)絡(luò)外,可靠第對(duì)權(quán)重空間進(jìn)行采樣是不可行的。雖然維數(shù)災(zāi)難(curse of dimensionality)阻礙了我們有效地采樣高維權(quán)重空間,但是通過(guò)強(qiáng)制所有權(quán)重共享(weight-sharing),權(quán)重值的數(shù)量被減少到一個(gè)。系統(tǒng)地對(duì)單個(gè)權(quán)重值進(jìn)行采樣是直接且高效的,這使我們能夠在少數(shù)試驗(yàn)中近似網(wǎng)絡(luò)性能,然后可以使用這種近似來(lái)驅(qū)動(dòng)搜索更好的架構(gòu)。
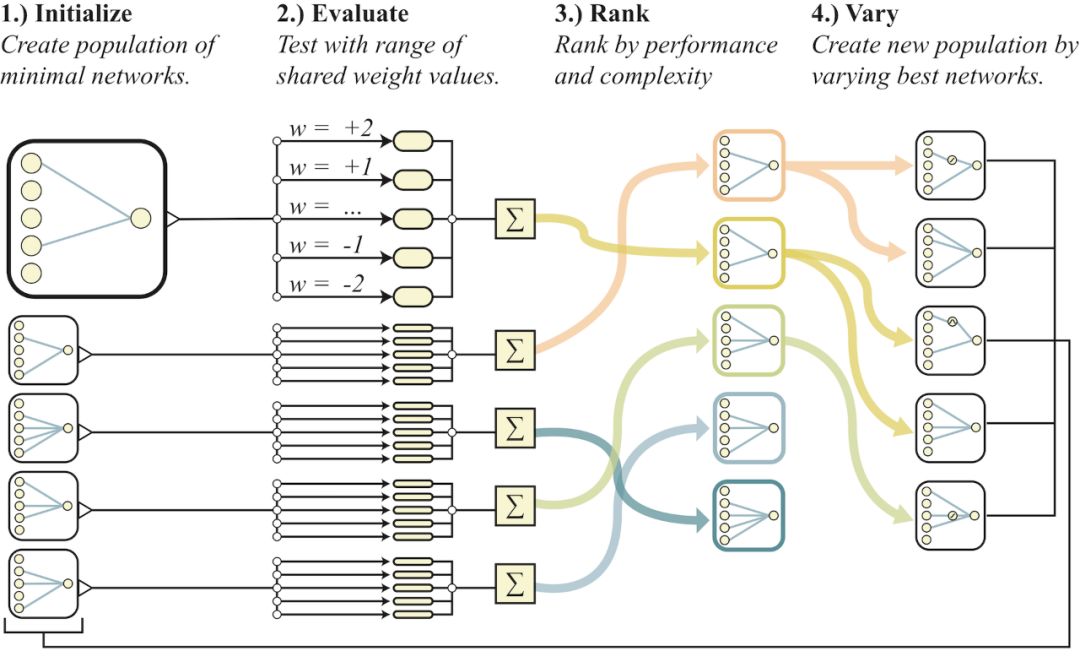
權(quán)重?zé)o關(guān)的神經(jīng)網(wǎng)絡(luò)搜索概述
在探索神經(jīng)網(wǎng)絡(luò)拓?fù)淇臻g時(shí),權(quán)值無(wú)關(guān)的神經(jīng)網(wǎng)絡(luò)搜索避免了權(quán)重訓(xùn)練,方法是在每次rollout時(shí)采樣一個(gè)共享的權(quán)值。網(wǎng)絡(luò)將通過(guò)多次rollout進(jìn)行評(píng)估。在每次rollout,都會(huì)為單個(gè)共享權(quán)重分配一個(gè)值,并記錄試驗(yàn)期間的累計(jì)獎(jiǎng)勵(lì)。然后根據(jù)網(wǎng)絡(luò)的性能和復(fù)雜度對(duì)網(wǎng)絡(luò)群體進(jìn)行排序。然后,概率性地選擇排名最高的網(wǎng)絡(luò),并隨機(jī)變化以形成新的群體,然后重復(fù)這個(gè)過(guò)程。
搜索權(quán)重?zé)o關(guān)神經(jīng)網(wǎng)絡(luò)(weight agnostic neural networks, WANNs)的過(guò)程可以概況如下(見(jiàn)上圖):
創(chuàng)建最小神經(jīng)網(wǎng)絡(luò)拓?fù)涞某跏既后w(population)。
通過(guò)多個(gè)rollout評(píng)估每個(gè)網(wǎng)絡(luò),每個(gè)rollout分配一個(gè)不同的共享權(quán)重值。
根據(jù)網(wǎng)絡(luò)的性能和復(fù)雜度對(duì)其進(jìn)行排名。
通過(guò)改變排名最高的網(wǎng)絡(luò)拓?fù)浣Y(jié)構(gòu)來(lái)創(chuàng)建新的population。
然后,算法從(2)開(kāi)始重復(fù),生成復(fù)雜度逐漸增加的與權(quán)重?zé)o關(guān)的拓?fù)浣Y(jié)構(gòu),這些拓?fù)浣Y(jié)構(gòu)在連續(xù)的幾代中表現(xiàn)得更好。
拓?fù)渌阉?Topology Search)
用于神經(jīng)網(wǎng)絡(luò)拓?fù)渌阉鞯倪\(yùn)算符(operators)受到神經(jīng)進(jìn)化算法NEAT的啟發(fā)。在NEAT中,拓?fù)浜蜋?quán)重值同時(shí)優(yōu)化,這里我們忽略了權(quán)重值,只應(yīng)用拓?fù)渌阉鬟\(yùn)算符。
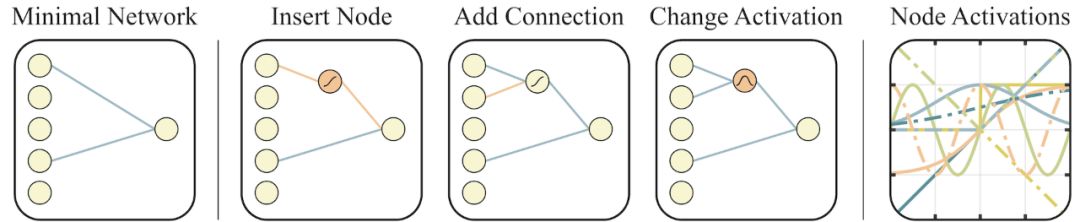
用于搜索網(wǎng)絡(luò)拓?fù)淇臻g的運(yùn)算符
左:一個(gè)最小的網(wǎng)絡(luò)拓?fù)浣Y(jié)構(gòu),輸入和輸出僅部分連接。
中間:網(wǎng)絡(luò)以三種方式進(jìn)行改變:
(1)插入節(jié)點(diǎn):通過(guò)拆分現(xiàn)有連接插入新節(jié)點(diǎn)。
(2)添加連接:通過(guò)連接兩個(gè)以前未連接的節(jié)點(diǎn)來(lái)添加一個(gè)新連接。
(3)變更激活:重新分配隱藏節(jié)點(diǎn)的激活函數(shù)。
右:在[2, 2]范圍內(nèi)可能的激活函數(shù)(線性、階躍、正弦、余弦、高斯、tanh、sigmoid、inverse、絕對(duì)值、ReLU)。
實(shí)驗(yàn)設(shè)置與結(jié)果
對(duì)連續(xù)控制權(quán)重?zé)o關(guān)神經(jīng)網(wǎng)絡(luò)(WANN)的評(píng)估在三個(gè)連續(xù)控制任務(wù)上進(jìn)行。
第一個(gè)任務(wù):CartPoleSwingUp,這是一個(gè)典型的控制問(wèn)題,在給定的推車(chē)連桿系統(tǒng)下,桿必須從靜止位置擺動(dòng)到直立位置然后平衡,而推車(chē)不會(huì)越過(guò)軌道的邊界。這個(gè)問(wèn)題無(wú)法用線性控制器解決。每個(gè)時(shí)間步長(zhǎng)上的獎(jiǎng)勵(lì)都是基于推車(chē)與軌道邊緣的距離和桿的角度決定的。
第二個(gè)任務(wù)是BipedalWalker-v2 ,目的是引導(dǎo)一個(gè)雙腿智能體跨越隨機(jī)生成的地形。獎(jiǎng)勵(lì)是針對(duì)成功行進(jìn)距離,以及電動(dòng)機(jī)扭矩的成本確定。每條腿都由髖關(guān)節(jié)和膝關(guān)節(jié)控制,響應(yīng)24個(gè)輸入。與低維的CartPoleSwingUp任務(wù)相比,BipedalWalker-v2的可能連接數(shù)更多更復(fù)雜,WANN需要選擇輸入到輸出的路線。
第三個(gè)任務(wù)CarRacing-v0是一個(gè)從像素環(huán)境中自上而下行駛的賽車(chē)問(wèn)題。賽車(chē)由三個(gè)連續(xù)命令(點(diǎn)火,轉(zhuǎn)向,制動(dòng))控制,任務(wù)目標(biāo)是在一定時(shí)限內(nèi)行駛過(guò)盡量長(zhǎng)的隨機(jī)生成的道路。我們將任務(wù)的像素解釋元素交給經(jīng)過(guò)預(yù)訓(xùn)練的變分自動(dòng)編碼器(VAE),后者將像素表示壓縮為16個(gè)潛在維度,將這些信息作為網(wǎng)絡(luò)的輸入。這個(gè)任務(wù)測(cè)試了WANN學(xué)習(xí)抽象關(guān)聯(lián)的能力,而不是編碼輸入之間的顯式幾何關(guān)系。
在實(shí)驗(yàn)中,我們比較了以下4種情況下100次試驗(yàn)的平均表現(xiàn):
1.隨機(jī)權(quán)重:從μ(-2,2)范圍內(nèi)抽取的單個(gè)權(quán)重。
2.隨機(jī)共享權(quán)重:從μ(- 2,2)范圍內(nèi)中抽取的單個(gè)共享權(quán)重。
3.調(diào)整共享權(quán)重:在μ(-2,2)范圍內(nèi)表現(xiàn)最好的共享權(quán)重值。
4.調(diào)整權(quán)重:使用基于人口信息的強(qiáng)化調(diào)整的個(gè)體權(quán)重。
連續(xù)控制任務(wù)的隨機(jī)抽樣和訓(xùn)練權(quán)重的性能
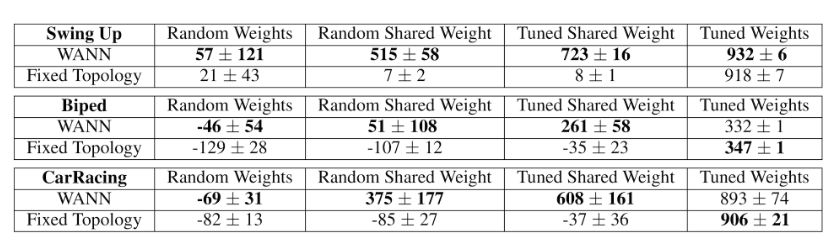
我們比較了過(guò)往研究中常用的標(biāo)準(zhǔn)前饋網(wǎng)絡(luò)的最佳權(quán)重?zé)o關(guān)網(wǎng)絡(luò)架構(gòu)的平均性能(測(cè)試次數(shù)超過(guò)100次)。通過(guò)均勻分布采樣的共享權(quán)重來(lái)測(cè)量其性能,從結(jié)果中可以觀察到網(wǎng)絡(luò)拓?fù)涞墓逃衅睢Mㄟ^(guò)調(diào)整此共享權(quán)重參數(shù),可以測(cè)出其最佳性能。為了便于與基線架構(gòu)進(jìn)行比較,允許網(wǎng)絡(luò)獲得獨(dú)特的權(quán)重參數(shù),并對(duì)其進(jìn)行調(diào)整。
結(jié)果如上表所示,作為基線的傳統(tǒng)固定拓?fù)渚W(wǎng)絡(luò)在經(jīng)過(guò)大量調(diào)整后只產(chǎn)生有用行為,相比之下,WANN甚至可以使用隨機(jī)共享權(quán)重。雖然WANN架構(gòu)編碼強(qiáng)烈偏向解決方案,但并不完全獨(dú)立于權(quán)重值,當(dāng)單個(gè)權(quán)重值隨機(jī)分配時(shí),模型就會(huì)失敗。WANN通過(guò)編碼輸入和輸出之間的關(guān)系來(lái)起作用,因此,雖然權(quán)重大小并不重要,但它們的一致性,特別是符號(hào)的一致性,是非常重要的。單個(gè)共享權(quán)重的另一個(gè)好處是,調(diào)整單個(gè)參數(shù)變得非常容易,無(wú)需使用基于梯度的方法。
表現(xiàn)最佳的共享權(quán)重值會(huì)產(chǎn)生令人滿(mǎn)意的行為:連桿系統(tǒng)在幾次擺動(dòng)之后即獲得平衡,智能體沿道路有效行進(jìn),賽車(chē)實(shí)現(xiàn)高速過(guò)彎。這些基本行為完全在網(wǎng)絡(luò)架構(gòu)內(nèi)編碼。雖然WANN能夠在未經(jīng)訓(xùn)練的情況下使用,但這并不能妨礙其在訓(xùn)練權(quán)重后達(dá)到類(lèi)似的最佳性能。
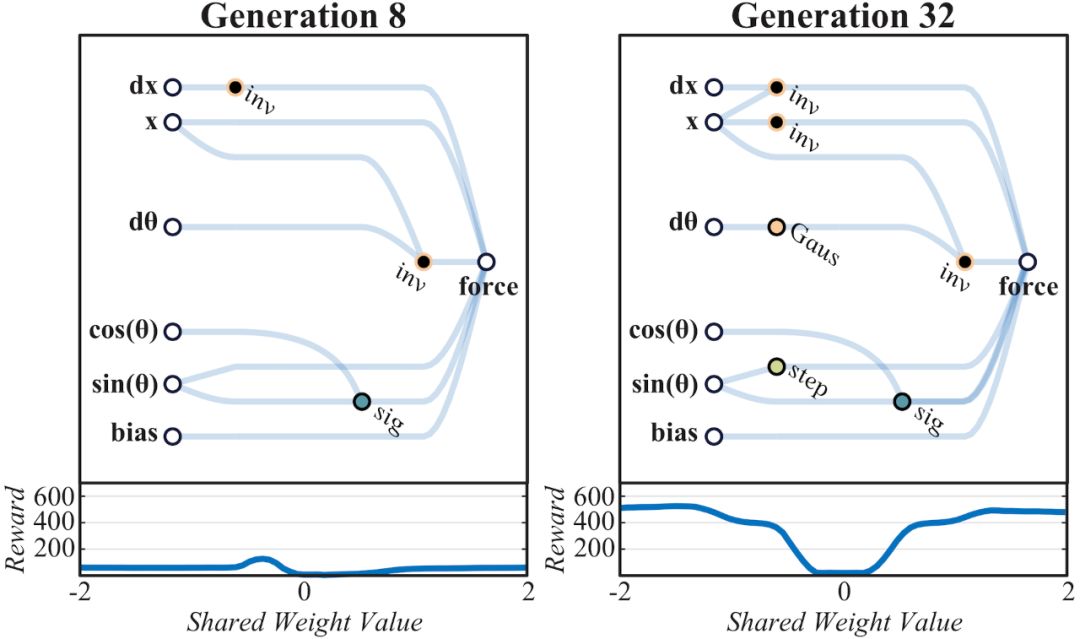
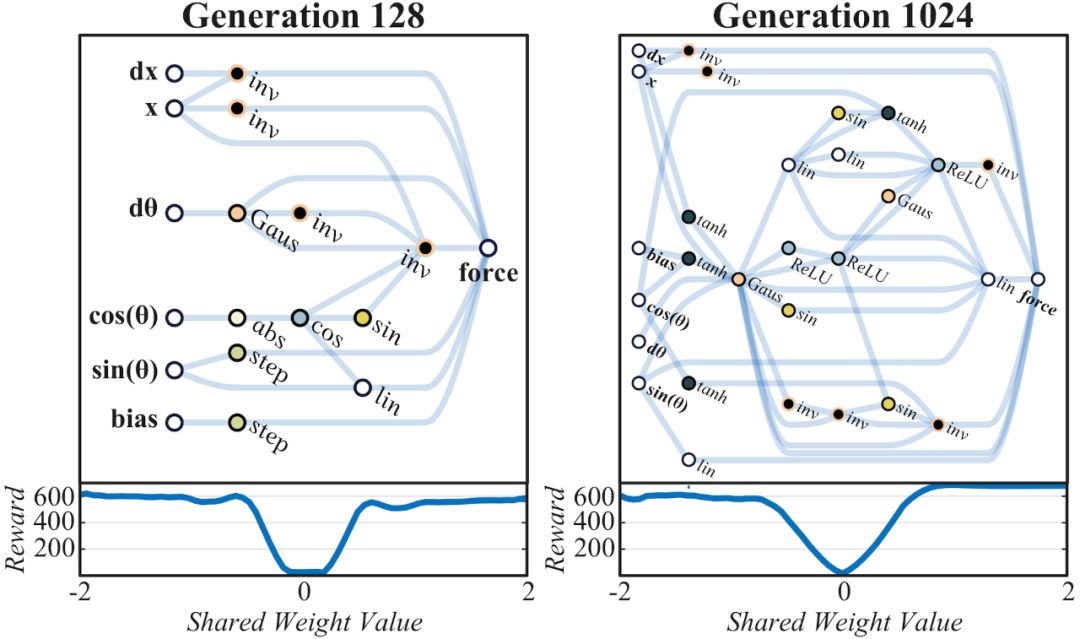
由于網(wǎng)絡(luò)規(guī)模小到可以解釋?zhuān)覀兛梢酝ㄟ^(guò)查看網(wǎng)絡(luò)圖來(lái)了解其運(yùn)行機(jī)制(見(jiàn)上圖)。解決“桿車(chē)實(shí)驗(yàn)”的WANN網(wǎng)絡(luò)開(kāi)發(fā)過(guò)程就體現(xiàn)了在網(wǎng)絡(luò)架構(gòu)內(nèi)對(duì)關(guān)系的編碼方式。在早期時(shí)代的網(wǎng)絡(luò)空間中,不可避免的需要使用隨機(jī)探索的方式。
網(wǎng)絡(luò)在第32代時(shí)形成初步架構(gòu),能夠支持比較一致的任務(wù)表現(xiàn),在軌道某某位置的逆變器可以防止小車(chē)沖出軌道,軌道中間為0點(diǎn),左邊為負(fù),右邊為正。在小車(chē)處于負(fù)區(qū)域時(shí)對(duì)其施加正方向作用力,反之亦然,網(wǎng)絡(luò)通過(guò)編碼在軌道中間設(shè)置一個(gè)強(qiáng)力牽引器。最終經(jīng)調(diào)整權(quán)重,在1024代達(dá)成最佳性能。
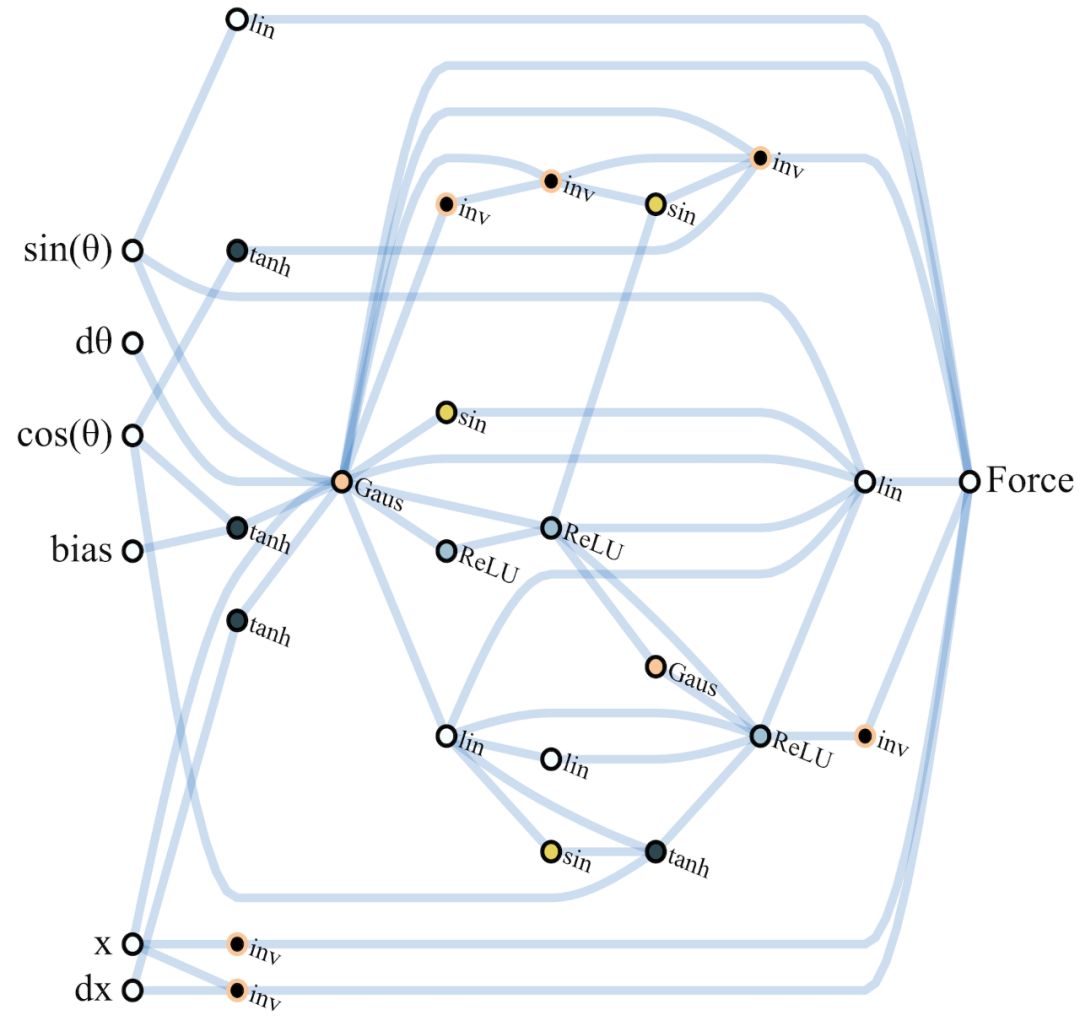
第1024代最佳性能的CartPoleSwingUp任務(wù)WANN網(wǎng)絡(luò)示意圖
我們可以使用最佳共享權(quán)重作為起點(diǎn),由共享權(quán)重參數(shù)得到偏移量,輕松訓(xùn)練網(wǎng)絡(luò)的每個(gè)單獨(dú)的權(quán)重連接。可以使用基于人口信息的強(qiáng)化對(duì)權(quán)重進(jìn)行微調(diào),但原則上可以使用任何其他學(xué)習(xí)算法。
為了在訓(xùn)練分布之外可視化智能體的性能,可以使用比原始設(shè)置更多更雜初始條件。
隨著搜索過(guò)程的繼續(xù),有些控制器能夠在直立位置保持更長(zhǎng)時(shí)間,到第128代時(shí),這個(gè)保持時(shí)間已經(jīng)長(zhǎng)到能夠讓桿保持平衡。雖然在可變權(quán)重條件下,這種更復(fù)雜的平衡機(jī)制在可靠性上低于擺動(dòng)和居中行為,但更可靠的行為可以確保系統(tǒng)恢復(fù),并再次嘗試直到找到新的平衡狀態(tài)。值得注意的是,由于這些網(wǎng)絡(luò)對(duì)關(guān)系進(jìn)行編碼,并依賴(lài)于相互設(shè)置的系統(tǒng)之間的張力,因此網(wǎng)絡(luò)的行為與廣泛的共享權(quán)重值保持一致。
在BipedalWalker-v2和CarRacing-v0任務(wù)中,WANN網(wǎng)絡(luò)控制器在簡(jiǎn)單性和模塊性方面的表現(xiàn)同樣出色。前者僅使用了25種可能輸入中的17種,忽略了許多LIDAR傳感器信息和膝蓋運(yùn)動(dòng)速度數(shù)據(jù)。 WANN架構(gòu)不僅可以在未訓(xùn)練單個(gè)權(quán)重的情況下完成任務(wù),而且僅使用了210個(gè)連接,比常用拓?fù)渚W(wǎng)絡(luò)架構(gòu)(SOTA基線方法中使用了2804個(gè)連接)低一個(gè)數(shù)量級(jí)。
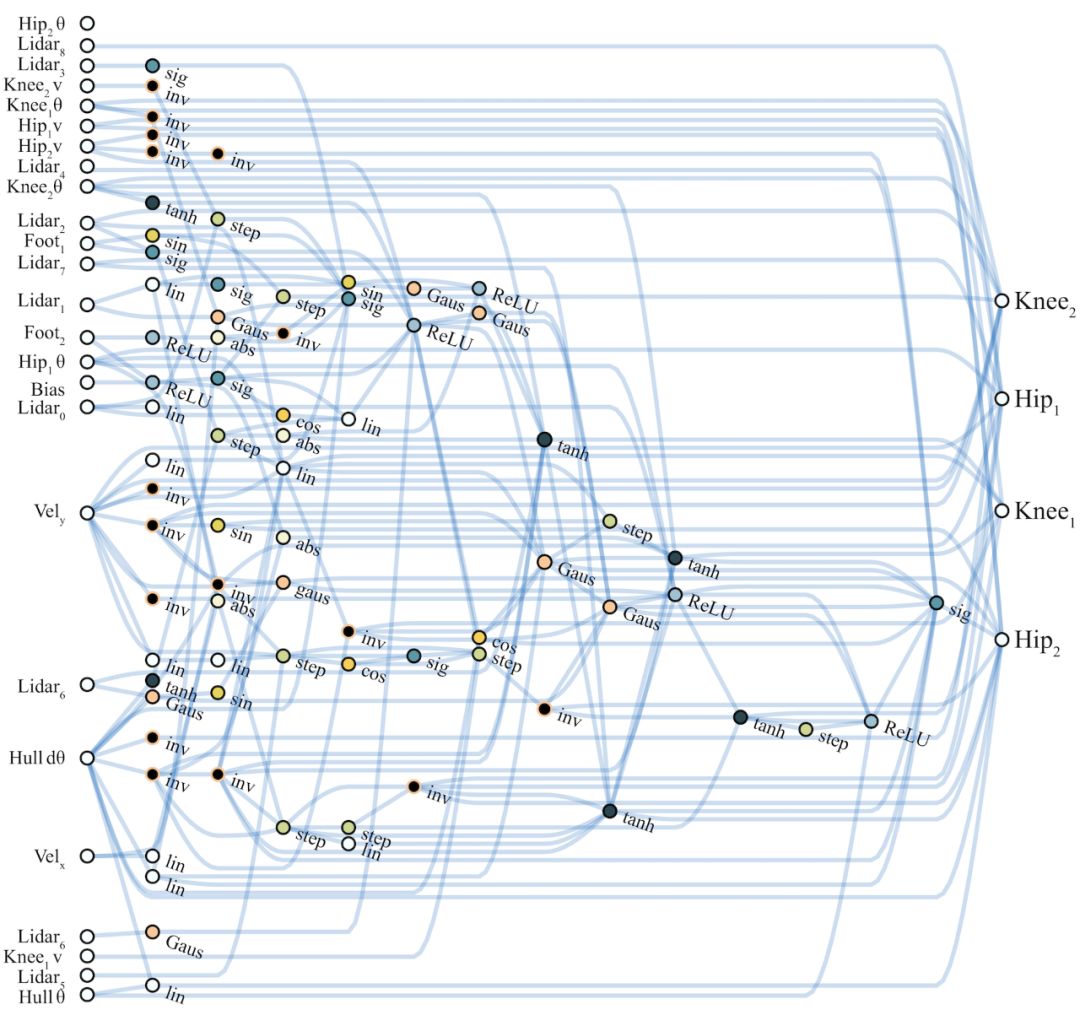
BipedalWalker任務(wù)最佳性能網(wǎng)絡(luò)示意圖
權(quán)重設(shè)置-1.5
權(quán)重設(shè)置-1.0
性能最優(yōu)的網(wǎng)絡(luò)
在賽車(chē)任務(wù)實(shí)驗(yàn)中,WANN架構(gòu)簡(jiǎn)單的優(yōu)勢(shì)也很突出。只需要稀疏連接的雙層網(wǎng)絡(luò)和單個(gè)權(quán)重值,就能編碼合格的駕駛行為。雖然SOTA基線方法也給出了預(yù)訓(xùn)練RNN模型的隱藏狀態(tài),但除了VAE對(duì)其控制器的表示外,我們的控制器僅在VAE的潛在空間上運(yùn)行。盡管如此,WANN還是能夠開(kāi)發(fā)出一種前饋控制器,可以獲得性能相當(dāng)?shù)姆謹(jǐn)?shù)。未來(lái)我們將探索如何從搜索中去掉前饋約束,讓W(xué)ANN開(kāi)發(fā)出與內(nèi)存狀態(tài)相關(guān)的循環(huán)連接。
權(quán)重設(shè)置+1.0
權(quán)重設(shè)置-1.4
性能最優(yōu)的網(wǎng)絡(luò)
WANN的應(yīng)用擴(kuò)展:探索圖像分類(lèi)任務(wù)
在強(qiáng)化學(xué)習(xí)任務(wù)中取得的好成績(jī)讓我們考慮擴(kuò)大WANN的應(yīng)用范圍。對(duì)輸入信號(hào)之間的關(guān)系進(jìn)行編碼的WANN非常適合強(qiáng)化學(xué)習(xí)任務(wù)。不過(guò),分類(lèi)問(wèn)題遠(yuǎn)沒(méi)有這么模糊,性能要求也要嚴(yán)格得多。與強(qiáng)化學(xué)習(xí)不同,分類(lèi)任務(wù)中的架構(gòu)設(shè)計(jì)一直是人們關(guān)注的焦點(diǎn)。為了驗(yàn)證概念,我們研究了WANN在MNIST數(shù)據(jù)集上的表現(xiàn),MNIST一個(gè)圖像分類(lèi)任務(wù),多年來(lái)一直是分類(lèi)任務(wù)架構(gòu)設(shè)計(jì)的關(guān)注焦點(diǎn)。
WANN在4種權(quán)重設(shè)定下在MNIST圖像數(shù)據(jù)集上的分類(lèi)表現(xiàn),WANN的分類(lèi)精度用多個(gè)權(quán)重值作為集合進(jìn)行實(shí)例化,其性能遠(yuǎn)遠(yuǎn)優(yōu)于隨機(jī)采樣權(quán)重
即使在高維分類(lèi)任務(wù)中,WANN的表現(xiàn)也非常出色。 只使用單個(gè)權(quán)重值,WANN就能夠?qū)NIST上的數(shù)字以及具有通過(guò)梯度下降訓(xùn)練的數(shù)千個(gè)權(quán)重的單層神經(jīng)網(wǎng)絡(luò)進(jìn)行分類(lèi),產(chǎn)生的架構(gòu)靈活性很高,仍然可以繼續(xù)進(jìn)行權(quán)重,進(jìn)一步提高準(zhǔn)確性。
按權(quán)重計(jì)算的數(shù)字精度
直接對(duì)權(quán)重范圍進(jìn)行全部掃描,當(dāng)然可以找到在訓(xùn)練集上表現(xiàn)最佳的權(quán)重值,但WANN的結(jié)構(gòu)提供了另一個(gè)有趣的方式。在每個(gè)權(quán)重值處,WANN的預(yù)測(cè)是不同的。在MNIST上,可以看出每個(gè)數(shù)字的精度是不一樣的。可以將網(wǎng)絡(luò)的每個(gè)權(quán)重值視為不同的分類(lèi)器,這樣可能使用具有多個(gè)權(quán)重值的單個(gè)WANN,作為“自包含集合”。
MNIST分類(lèi)器。并非所有神經(jīng)元和連接都用于預(yù)測(cè)每個(gè)數(shù)字
將具有一系列權(quán)重值的WANN進(jìn)行實(shí)例化來(lái)創(chuàng)建網(wǎng)絡(luò)集合是最簡(jiǎn)單的方法之一。集合中的每個(gè)網(wǎng)絡(luò)給與一票,根據(jù)得票最多的類(lèi)別對(duì)樣本進(jìn)行分類(lèi)。這種方法產(chǎn)生的預(yù)測(cè)結(jié)果遠(yuǎn)比隨機(jī)選擇的權(quán)重值更準(zhǔn)確,而且僅僅比最佳權(quán)重值稍差。今后在執(zhí)行預(yù)測(cè)或搜索網(wǎng)絡(luò)架構(gòu)任務(wù)時(shí)可以不斷嘗試更復(fù)雜的技術(shù)。
-
谷歌
+關(guān)注
關(guān)注
27文章
6231瀏覽量
108075 -
神經(jīng)網(wǎng)絡(luò)
+關(guān)注
關(guān)注
42文章
4814瀏覽量
103508 -
深度學(xué)習(xí)
+關(guān)注
關(guān)注
73文章
5560瀏覽量
122765
原文標(biāo)題:告別深度學(xué)習(xí)煉丹術(shù)!谷歌大腦提出“權(quán)重?zé)o關(guān)”神經(jīng)網(wǎng)絡(luò)
文章出處:【微信號(hào):AI_era,微信公眾號(hào):新智元】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
BP神經(jīng)網(wǎng)絡(luò)與深度學(xué)習(xí)的關(guān)系
Flexus X 實(shí)例 ultralytics 模型 yolov10 深度學(xué)習(xí) AI 部署與應(yīng)用

GPU在深度學(xué)習(xí)中的應(yīng)用 GPUs在圖形設(shè)計(jì)中的作用
NPU在深度學(xué)習(xí)中的應(yīng)用
pcie在深度學(xué)習(xí)中的應(yīng)用
PyTorch GPU 加速訓(xùn)練模型方法
Pytorch深度學(xué)習(xí)訓(xùn)練的方法

GPU深度學(xué)習(xí)應(yīng)用案例
AI大模型與深度學(xué)習(xí)的關(guān)系
直播預(yù)約 |數(shù)據(jù)智能系列講座第4期:預(yù)訓(xùn)練的基礎(chǔ)模型下的持續(xù)學(xué)習(xí)






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論