") 以后不用學(xué)習(xí)拍照技術(shù)了實時在線AI構(gòu)圖模型VPN讓你變身攝影大神
以后不用學(xué)習(xí)拍照技術(shù)了實時在線AI構(gòu)圖模型VPN讓你變身攝影大神

前言
一年一度的人機交互領(lǐng)域國際頂級會議 ACM CHI 將于 5 月 4 號在英國格拉斯哥舉行,我的一篇文章 SmartEye: Assisting Instant Photo Taking via Integrating User Preference with Deep View Proposal Network 被會議接收,并獲得了最佳論文提名獎。(本文希望從思路上回憶自己產(chǎn)出這篇論文的過程,更多的描述了一個以用戶為中心的人機交互(HCI)領(lǐng)域的科研成果的形成過程,本文用到了計算機視覺和機器學(xué)習(xí)的相關(guān)方法,但并非一個技術(shù)文章,如果有技術(shù)方面的問題歡迎留言和我聯(lián)系)
動機
當(dāng)我們看到好看的風(fēng)景,有趣的小東西,可口的菜肴,可愛的小狗,我們喜歡掏出兜里的手機拍一張照。但是對著同樣的景物,有的人拍的很好看有的人拍的不那么好看,這其中的原因是什么?是構(gòu)圖的區(qū)別,構(gòu)圖在很大程度上決定了一張照片的美學(xué)質(zhì)量。但是構(gòu)圖并非一件容易的事,很多非專業(yè)的人無法掌握構(gòu)圖的技巧,因此我們打算利用技術(shù)幫助人們更好的去對照片進(jìn)行構(gòu)圖。
專業(yè)和非專業(yè)的攝影者拍攝出來的照片效果天差地別
現(xiàn)有問題:現(xiàn)在有很多幫助人們構(gòu)圖的算法,不過存在著一個很關(guān)鍵的問題就是實時性不夠強,需要先拍照,然后再離線處理,這樣會帶來兩個問題,一個是會需要額外的存儲和時間,另一個是離線算法是基于已經(jīng)拍好的照片的,會極大受限于這張照片,在拍照時移動手機的過程中好的構(gòu)圖很容易被錯過。
解決方案:我們利用了一個基于百萬級圖片訓(xùn)練出來的深度學(xué)習(xí)模型 View Proposal Network(VPN)來幫助構(gòu)圖[1],這是我們這篇文章的合作者魏子鈞博士發(fā)表在 CVPR 2018 中的一篇文章。VPN 具有 state-of-the-art 的表現(xiàn),以及具有很好的實時性(基于 One-stage object detection),可以達(dá)到 75fps。其作用可以簡單的描述為:輸入一張照片,基于圖片裁剪的方式(對原圖進(jìn)行各種 aspect ratio,size…… 的裁剪),生成一系列構(gòu)圖候選(Composition candidate),并且對每一個構(gòu)圖候選進(jìn)行打分,按照從高到低的順序輸出。
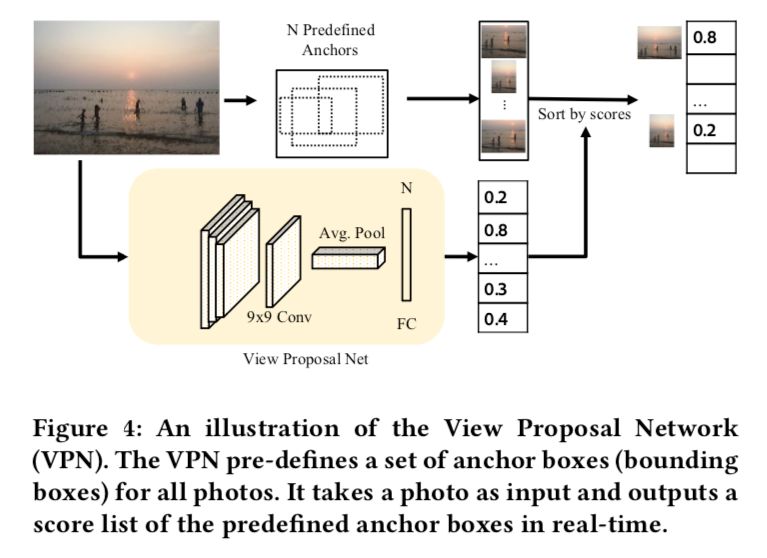
構(gòu)圖推薦網(wǎng)絡(luò)(View Proposal Network)流程圖

VPN 的效果圖(給定一張照片,可以給出一系列推薦構(gòu)圖)。
只有算法還不夠,還需要搭配更友好的交互方式:
但是僅僅有了一個實時的深度學(xué)習(xí)模型還不夠,我們需要讓這個算法能夠友好的為用戶所使用,應(yīng)用到拍照場景中去,這樣才是真正的幫助人們進(jìn)行拍照構(gòu)圖。
我們將 VPN 封裝為后端的算法,設(shè)計了一個 APP 來讓算法真正實用,同時設(shè)計了友好新穎的用戶界面和豐富的功能和特性來連接用戶和深度學(xué)習(xí)模型。
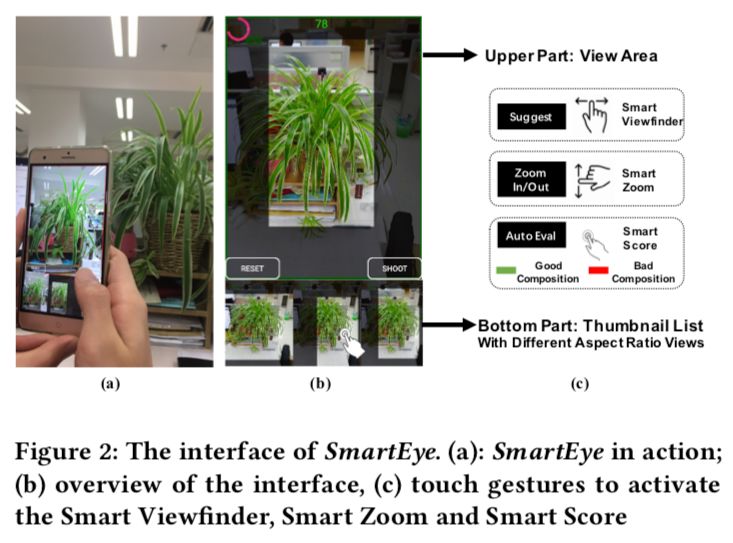
用戶界面圖:(a)用戶使用 SmartEye(b)主要用戶界面(c)功能和手勢支持圖
界面整體分為兩個部分,上面是一個視圖區(qū),下面是一個縮略圖列表,視圖區(qū)就像是一個普通的拍照取景區(qū)域,有三個功能,一個是用于實時的展示 SmartViewfinder(下面會介紹)的推薦,一個是可以放大顯示下方的縮略圖,還有一個是作為用戶選定構(gòu)圖之后的一個預(yù)覽窗口,下方的縮略圖列表顯示著由 VPN 推薦的各種比例的構(gòu)圖推薦,可以左右滑動來切換和查看各種各樣的構(gòu)圖。
我們還設(shè)計了幾種強大的功能支持:
SmartViewfinder。當(dāng)我們移動手機時,基于實時的相機鏡頭捕捉到的圖像,SV 實時的提供構(gòu)圖推薦,在視圖區(qū)展示最好的一個,在縮略圖列表中存放著其他的。
SmartViewfinder 實時構(gòu)圖推薦
SmartScore。為當(dāng)前鏡頭進(jìn)行實時的打分,顯示在視圖區(qū)的最上方,鏡頭一旦移動或者鏡頭中的景物一旦變化,分?jǐn)?shù)就會隨著做出改變,如果當(dāng)前構(gòu)圖質(zhì)量很高,視圖區(qū)的邊框會變?yōu)榫G色,反之紅色,用來實時的提醒用戶給用戶反饋。
SmartScore 幫助鏡頭自動打分
因顯示視頻數(shù)量限制,Demo視頻可瀏覽:
http://v.qq.com/x/page/i0884109zj4.html
SmartZoom。一個智能的縮放功能,可以幫助用戶自動的縮放到一個最合適的尺度,這個功能旨在讓縮放操作變得更容易,因為人們總是一不小心就縮放過了。
SmartZoom 實現(xiàn)智能縮放
除此之外我們還提供了一些其他的功能,比如自定義推薦數(shù),用戶可以自己選擇在縮略圖列表中展示的推薦書,自由裁剪,在系統(tǒng)給出的構(gòu)圖推薦基礎(chǔ)上,用戶如果有一些不滿意,可以在此基礎(chǔ)上拖動裁剪框,再次進(jìn)行裁剪邊界的調(diào)整。APP 還提供了豐富的手勢來觸發(fā)和切換這些功能,比如左右滑來瀏覽 SmartViewfinder,手指上下滑動來進(jìn)行 SmartZoom 縮放,長按來激活 SmartScore。
好不好用?
我們找了一些人來使用這個 APP,收集了大家的反應(yīng)。大家都對這個 APP 持有積極的看法,但是一些用戶也提出了意見,“為什么我喜歡的構(gòu)圖排在了后面”、“如果這張構(gòu)圖能夠稍微向左靠一點就好了”、“盡管我可以通過裁剪加以調(diào)整,但是我希望系統(tǒng)能直接推薦給我我想要的”。
我們也發(fā)現(xiàn)了一些問題,VPN 按照得分高低順序推薦,但是在很多情況下,用戶并沒有選擇排在第一位的構(gòu)圖,我們簡單的做了一個實驗,固定 VPN 推薦的數(shù)量為 5,邀請了 16 個被試(被試情況在后面敘述)進(jìn)行了拍照,每個人拍攝 10 張照片,我們記錄了每張照片最后用戶選擇的是第幾張,結(jié)果如圖所示:
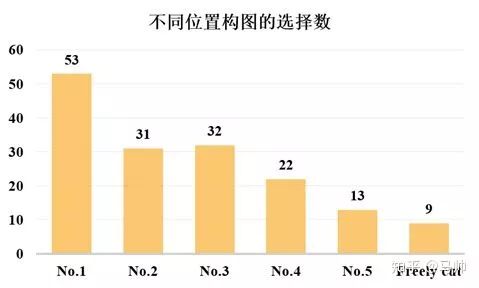
16 個被試拍攝 10 張照片的過程中,不同位置的選擇人次(No.1 代表構(gòu)圖候選列表中的第一個,以此類推,F(xiàn)reely cut 代表用戶沒有選擇推薦構(gòu)圖而是自己進(jìn)行了裁剪)
可以發(fā)現(xiàn)盡管第一位的數(shù)量有很多,但是第二位到第五位也同樣不少,還有一些用戶選擇了自己裁剪。
新的問題:用戶偏好的存在(本文核心)
于是我們挑選了 10 張照片,每張照片由 VPN 生成 5 個推薦構(gòu)圖,然后打亂順序,讓 16 個參與者分別挑選最喜歡的構(gòu)圖,我們對結(jié)果做了可視化的分析,得到了一個發(fā)現(xiàn),同樣一張照片,不同用戶最喜歡的構(gòu)圖方式(裁剪區(qū)域)有所不同,比如下面的這個圖中,為了容易看清,我們可視化了 3 位用戶最喜歡的構(gòu)圖方式,可以看到是不一樣的。
對于某一張照片三個用戶最喜歡的構(gòu)圖的邊框并不相同
然后我們在每張圖片上繪制了 16 個用戶最喜歡的構(gòu)圖中心點分布的 heatmap,可以發(fā)現(xiàn)并非所有的人都喜歡同樣的構(gòu)圖。這個發(fā)現(xiàn)十分明確和易于理解,因為一千個人眼中有一千個哈姆雷特,每個人的審美標(biāo)準(zhǔn)都不同,構(gòu)圖相對而言是一個主觀性十分強的任務(wù)(并不類似于計算機視覺中其他目標(biāo)檢測任務(wù)),而 VPN 只是通過眾包數(shù)據(jù)學(xué)習(xí)到了一個通用的審美標(biāo)準(zhǔn),所以我們認(rèn)為有必要將用戶的個人偏好考慮進(jìn)推薦算法中。
兩張照片中不同用戶最喜歡的構(gòu)圖的中心點組成的 heatmap
如何考慮用戶偏好?
這個問題是我們這片論文的一個難點。我們的第一個考慮十分直接,就是從數(shù)據(jù)出發(fā),VPN 既然能夠生成不同的構(gòu)圖,并且給它們打分,那我們就改造一下 VPN,讓它能夠把用戶的偏好也學(xué)習(xí)進(jìn)去。我們嘗試了一些方法來調(diào)整 VPN,包括 retrain 和 fine-tune,但是都因為數(shù)據(jù)量的問題以失敗告終了,因為我們很難通過少量的帶有用戶偏好的數(shù)據(jù)來調(diào)整一個已經(jīng)訓(xùn)練好的深度學(xué)習(xí)模型。
既然直接修改 VPN 并不容易,我們考慮加入一個模塊,能夠考慮用戶的偏好,這個模塊需要做到可以針對一張構(gòu)圖生成一個打分,這樣就可以用這個新的打分來調(diào)整一個構(gòu)圖最終的得分,從而調(diào)整模型最終的輸出順序。我們稱這個模塊為 Preference 模塊(P-Module),我們對 P-Module 有一些要求,一是能夠準(zhǔn)確的對用戶偏好進(jìn)行建模,而且對噪聲要有一定魯棒性;二是在分?jǐn)?shù)預(yù)測方面十分高效;三是 P-Module 要比較小巧,可以用小量的數(shù)據(jù)來訓(xùn)練和更新,代表著用戶偏好的圖片越多,P 模塊就理論上越能夠考慮用戶的偏好。
敲定了上述需求,P-Module 可以視為一個機器學(xué)習(xí)中的回歸問題,我們可以通過設(shè)計特征來對用戶偏好建模。
如何對偏好建模?
我們起初,直觀上覺得既然用戶的選擇來源于 VPN 的各種各樣構(gòu)圖推薦,不同的構(gòu)圖之間最明顯的區(qū)別是什么呀?是大小、位置、長寬比之類的啊,我們?yōu)楹尾荒軓倪@些方面入手,簡簡單單就可以 model 用戶偏好,豈不美哉?事實操作發(fā)現(xiàn)根本不怎么 work。
簡單的特征不奏效,那么我們就設(shè)計更復(fù)雜更有力的美學(xué)特征唄,于是我們通過閱讀相關(guān)的用戶偏好建模文獻(xiàn),以及攝影、美學(xué)相關(guān)的文章,從中吸取了大量經(jīng)驗,設(shè)計出了一個復(fù)雜的 feature set,又做了一系列特征選擇,但是發(fā)現(xiàn)效果并沒有多么理想,甚至在一些 test set 上還不如一開始最簡單的十來維特征有效。
那該怎么辦?用戶偏好為什么這么難以 model?我不禁問自己,總說要對偏好進(jìn)行建模,那在構(gòu)圖這個任務(wù)中,用戶偏好到底是什么啊?
經(jīng)歷了短暫的郁悶期,我突然清醒,既然你要研究用戶偏好,為何從用戶中來,到用戶中去呢?于是我深入群眾,去探討用戶偏好是什么的問題。
我們進(jìn)行了一些前期的 User Study 工作(在 User Study 部分會有詳細(xì)描述),收集了一大波用戶反饋意見,進(jìn)行了細(xì)致的整理和歸納,得到了許許多多有用的建議(在我的論文中進(jìn)行了歸納和整理,為了節(jié)約篇幅這里不做描述),并且基于用戶的這些建議和之前調(diào)研的一些攝影、構(gòu)圖、美學(xué)方面的知識我們設(shè)計并選擇了 4 類 32 維特征,分別是基于幾何學(xué)的、基于顯著區(qū)域的、基于構(gòu)圖規(guī)則的、基于拍照的。
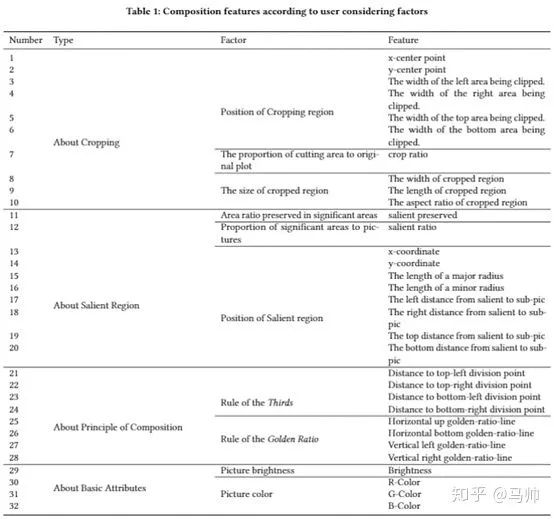
設(shè)計的 4 類 32 維特征
其中提取顯著區(qū)域的效果如下

圖片的顯著區(qū)域(由一個橢圓包圍)
(這里需要提一句的是:我們并不是說這些特征是最好用的,相反,我們希望其他人或者我在接下來的工作里可以通過設(shè)計新的 feature vector 從而獲得更好的結(jié)果。構(gòu)建能夠為我們的任務(wù)提供非常好的性能并且可以有效計算的特征集仍然是一個有趣的開放性問題。)
特征設(shè)計完了,到底有沒有用呢?我們進(jìn)行了詳細(xì)的實驗得出結(jié)論——特征顯著性和相關(guān)性都比較強,這個問題留在最后的 User Study 中敘述,我們接下來要討論的是構(gòu)建模型。
如何構(gòu)建 P-Module?
首先我們要確定模型類別,考慮到用戶在使用我們的 APP 時,從 N 個構(gòu)圖推薦中選擇最滿意的一個點擊 “拍照” 按鈕,然后保存到本地相冊,這是一個最自然不過的打 0/1 標(biāo)簽的過程(被選擇的是正樣本,其他的被隨機選擇為負(fù)樣本,避免樣本不均衡問題),所以我們暫定了 LogisticRegression 作為我們的打分模型(將 1 的概率映射為分?jǐn)?shù)),而且在收集的數(shù)據(jù)中(用戶實驗部分將要描述)跑了一下結(jié)果,發(fā)現(xiàn)作為一個 score model,各項指標(biāo)還是蠻不錯的。
給定一個構(gòu)圖 來自一張照片 , 我們提取了它的特征 并且把它送進(jìn) LR 模型得到了一個標(biāo)準(zhǔn)化的用戶偏好得分。
LR 的簡單性使得 P-Module 對噪聲魯棒、易于在線交互式的更新、以及高效的預(yù)測得分。
如何將 P-Module 和 VPN 進(jìn)行結(jié)合?
我們依據(jù)了一個基于記憶的算法(這個算法基于用戶過去的打分來預(yù)測現(xiàn)在的分?jǐn)?shù))把 VPN 打分和 P-Module 打分結(jié)合了起來。更具體的,我們動態(tài)的調(diào)整了對于一張構(gòu)圖 ,VPN 的打分 和 P-Module 的打分 的權(quán)重:
其中 是一個置信度(confidence score),用來描述當(dāng)前照片 和用戶過去選擇過的構(gòu)圖有多么相似。我們基于一個假設(shè):如果一個相似的圖片已經(jīng)作為知識(訓(xùn)練樣本)被 P-Module 學(xué)習(xí)過了,我們有理由相信最終的得分應(yīng)該更依賴于 P-Module 的打分。因此,我們通過計算當(dāng)前照片與已處理過的照片的構(gòu)圖距離來計算置信度。當(dāng)前照片與已有照片越相似,置信度越高,P-Module 的打分在最終打分中占的比重就越大。
置信度的計算公式如下:
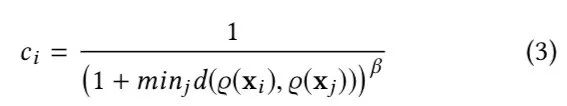
其中 是兩個構(gòu)圖的特征向量 之間的歐氏距離。 是一個超參數(shù)來控制 的變異率。在本文工作中,我們固定 。值得一提的是,置信度可以簡單的描述為當(dāng)前算法做出的推薦是更多依賴于 VPN 還是更多依賴于 P-Module,也就是用戶個人偏好,我們將置信度顯示在 APP 的界面中,并且進(jìn)行實時的更新,在之后的用戶實驗中也證明:在這種主觀性較強的,用戶可能不是十分相信 AI 算法的任務(wù)中,如果給用戶展示一個“當(dāng)前算法有多少依賴于你”,能讓用戶在查看算法給出的推薦時,更加容易做出選擇和覺得被尊重,也會讓用戶覺得系統(tǒng)更加人性化。
為了直觀表述兩張照片(構(gòu)圖)的相似性,我們對不同照片(構(gòu)圖)的特征向量進(jìn)行了 PCA 降維。

不同照片(構(gòu)圖)的特征向量在二維空間上的分布
算法整體流程
到此為止,我們的算法部分完全形成了,讓我們再一起回顧一下算法的流程。
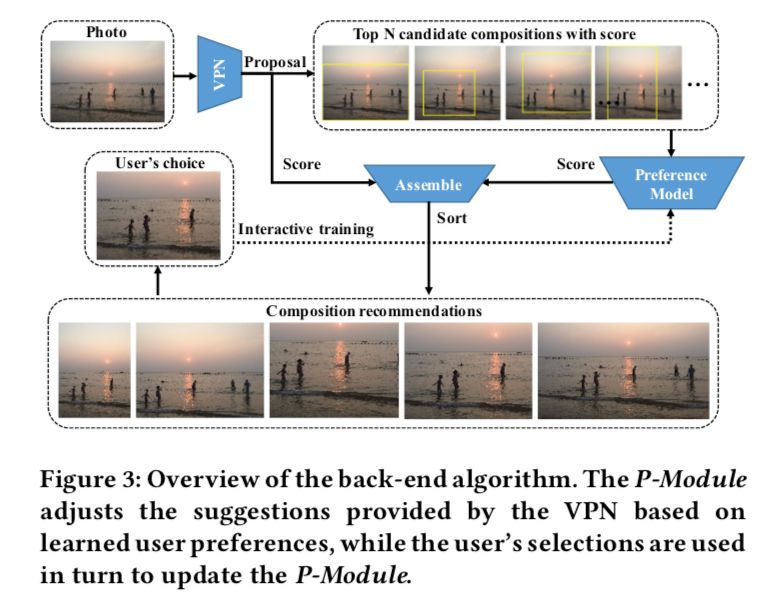
本文算法的整體流程,基于學(xué)到的用戶偏好,P-Module 調(diào)整 VPN 給出的推薦,同時用戶新的選擇也會反過頭來去更新 P-Module
給定一張照片,算法流程如下:
VPN 給出構(gòu)圖建議
針對 VPN 給出的所有推薦構(gòu)圖,P-Module 計算用戶偏好得分
通過插值算法動態(tài)的調(diào)整二者的權(quán)重,得到最終的得分,然后從高到低排序,展示給用戶
用戶從構(gòu)圖候選中選擇一個最喜歡的,這個被選擇的構(gòu)圖也會作為正樣本繼續(xù)更新 P-Module
整個算法交互式地、逐漸地學(xué)習(xí)到用戶偏好,這項技術(shù)屬于交互式機器學(xué)習(xí)(interactive Machine Learning)的范疇。
至此,整個系統(tǒng)可以用下面的這么一張圖來表示其核心內(nèi)涵。

(a)左上角是一張輸入照片,View Proposal Network(VPN)會推薦一組多樣化的構(gòu)圖(如右上圖所示); P-Module 根據(jù)所學(xué)習(xí)的用戶偏好實時調(diào)整建議(如下圖所示);(b)SmartEye 以交互方式逐步學(xué)習(xí)用戶偏好:當(dāng)用戶在屏幕底部選擇他們喜歡的構(gòu)圖時,P-Module 會隨之更新。 因此系統(tǒng)會逐漸掌握用戶偏好。
用戶實驗
來到了人機交互領(lǐng)域研究中相當(dāng)重要的一個部分——用戶實驗(User Study)。
我們部署了兩個用戶實驗來探究如下三個問題:
1) 構(gòu)圖任務(wù)的個性化偏好建模中什么特征比較重要;
2) P-Module 是否幫助模型更好地吻合用戶的選擇;
3) 用戶使用 SmartEye 時的用戶體驗如何。
我們找了 16 個參與者(在人機交互學(xué)科中成為被試),其中有 8 位男性 8 位女性,有 8 位在攝影方面沒有基礎(chǔ),標(biāo)為 P1-P8,有 8 位具有一定的攝影基礎(chǔ),其中 5 位是大學(xué)攝影協(xié)會的,標(biāo)為 P9-P13,還有 3 位專業(yè)是美術(shù)和影視專業(yè)的,標(biāo)為 P14-P16。他們平均具有 4.13 年的攝影(拍照)經(jīng)驗。
Study 1 Effectiveness of P-Module
為了探究 P-Module 的有效性,我們設(shè)計了兩個任務(wù)。
Task1:從 VPN 的推薦構(gòu)圖打分
目的:看看該設(shè)計什么樣的特征,順便收集帶標(biāo)注的數(shù)據(jù)。
這個任務(wù)也是最基礎(chǔ)的一個任務(wù),涉及到特征的設(shè)計,我們在前面已有提到,在這進(jìn)一步詳細(xì)說明。
我們首先隨機收集了一個數(shù)據(jù)集 PhotoSetA,其中包含 50 張照片,以涵蓋人們通常拍攝的各種日常照片。然后,我們要求每位參與者貢獻(xiàn)他們拍攝的 100 張照片以形成 PhotoSetB(包括 16 位參與者拍攝的總共 1600 張照片)。這兩個數(shù)據(jù)集中的照片在內(nèi)容,樣式和寬高比等方面不做任何限制。
我們用 VPN 處理了 PhotoSetA 和 PhotoSetB 中的所有照片,每張照片都有 5 個推薦的構(gòu)圖。對于每個參與者,我們給了他 / 她 150 張照片(50 張來自 PhotoSetA,100 張來自 PhotoSetB 中自己拍攝的)以進(jìn)行評分,我們收集了 12000 張(16 張參與者 ×150 張照片 ×5 張構(gòu)圖)帶有主觀評分的照片。我們還要求每位參與者填寫調(diào)查問卷并就一些問題進(jìn)行了采訪。對于參與者剛剛打分的一些照片,我們問了被試一些問題:
a) 你在進(jìn)行構(gòu)圖選擇時考慮了哪些因素?
b) 你為什么喜歡這一個(構(gòu)圖)?
c) 你認(rèn)為你選擇的這一個比其他的好在哪?
從中獲得了很多有價值的見解,這也幫助我們設(shè)計了前面提到的 feature vector。
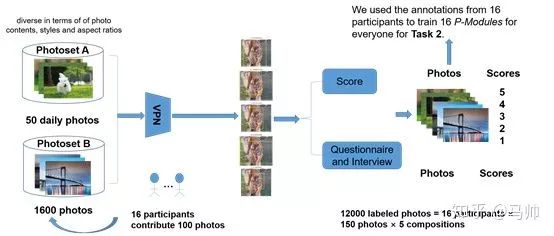
Task1 流程圖
需要說明的是,16 個被試所標(biāo)注的圖片數(shù)據(jù)將用來分別為這 16 個人訓(xùn)練自己的 P-Module 用于 Task2。
Task2:從不同的算法推薦的構(gòu)圖中進(jìn)行挑選
目的:我們想要探究 P-Module 是否有用,是否 outperform 了其他算法。
我們通過具有挑戰(zhàn)性的用戶實驗證明了 SmartEye 所推薦的構(gòu)圖的質(zhì)量,為此我們額外收集了 50 張不同風(fēng)格和內(nèi)容的照片。
對于每張照片,我們選擇了不同模型生成的前 5 種構(gòu)圖,讓參與者選擇最佳構(gòu)圖(第 1 名)。我們的實驗所用到的模型如下:1)帶有 P-Module 的 VPN;2)VPN; 3)基于顯著區(qū)域檢測和面部檢測的算法,表示為 Sal + Face。 Sal + Face 的工作原理如下:給出一張照片,Sal + Face 計算其顯著性圖并檢測面部,然后計算顯著性得分和面部得分之和,挑選具有最高得分的 5 種構(gòu)圖方式推薦給用戶。我們混合了不同模型的輸出(去掉順序?qū)Y(jié)果的影響)并將它們展示給 16 個參與者。我們要求他們在每張照片中選擇他們喜歡的構(gòu)圖。實驗結(jié)果在 Results 部分展示。
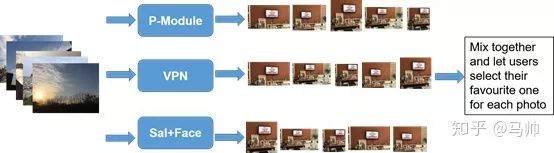
Task2 流程圖
Study 2: Usability of SmartEye
Task 3: 在手機上使用不同的算法進(jìn)行拍照
目的:探究在實際環(huán)境下,融合了 P-Module 的 SmartEye 是否好用
我們在 Android 設(shè)備上部署了以下系統(tǒng):1)搭載了 P-Module 和 VPN 的 SmartEye,2)只有 VPN 的 SmartEye,3)搭載了 Sal + Face 的 APP。我們還加入了 Android 原生相機,作為非構(gòu)圖推薦系統(tǒng)的參考。
我們引導(dǎo)參與者如何使用我們的系統(tǒng),并鼓勵他們在開始此任務(wù)之前嘗試所有功能。我們隨機分配了不同系統(tǒng)使用的順序來消除影響。參與者被要求使用每個系統(tǒng)拍攝至少 30 張照片。然后他們被要求填寫一個 post-task questionnaire。 此任務(wù)后調(diào)查問卷包含對被測試的算法的看法,偏好建模的效果以及對 SmartEye 中可用的支持功能的看法。
Task4:使用 SmartEye 一個月
目的:探究 SmartEye 是否可以隨著用戶越多使用,效果有越高的提升
在此任務(wù)中,我們讓每個參與者連續(xù)使用 SmartEye 一個月。每位參與者每天必須使用 SmartEye 拍攝至少 5 張照片。拍攝照片的內(nèi)容和風(fēng)格不受限制,這意味著用戶可以任意使用 SmartEye,只要他們每天拍攝 5 張照片。
在月底,我們收集了用戶們在這一個月內(nèi)保存下來的構(gòu)圖,并研究了 P-Module 隨著時間增長的進(jìn)步情況。
實驗結(jié)果
Study 1
根據(jù)任務(wù) 1 中 16 位參與者的構(gòu)圖選擇數(shù)據(jù),我們計算了用戶得分與 32D 特征之間的 Spearman 和 Pearson 相關(guān)系數(shù)。相關(guān)性如下圖所示。可以看到,不同參與者的相關(guān)性有所不同。幾乎每個參與者都關(guān)注基于幾何的特征和基于顯著性的特征。同樣有趣的是,有一定攝影基礎(chǔ)的用戶似乎更關(guān)注基于顯著性和基于構(gòu)圖規(guī)則的特征,而其他人可能更多地依賴于幾何和基于照片的特征。特征相關(guān)性的差異也反映了參與者之間構(gòu)圖偏好的差異。
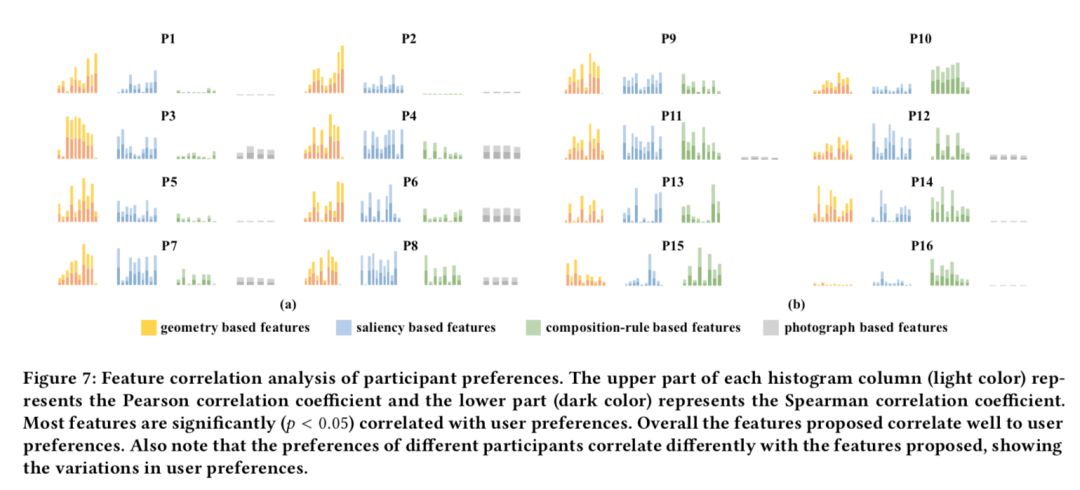
參與者偏好的特征相關(guān)分析。每個直方圖列的上方(淺色)表示 Pearson 相關(guān)系數(shù),下方(深色)表示 Spearman 相關(guān)系數(shù)。大多數(shù)特征與用戶偏好顯著(p<0.05)相關(guān)。總體而言,所提出的特征與用戶偏好具有很好的相關(guān)性。另請注意,不同參與者的偏好與所提取的特征有不同的相關(guān)性,顯示了用戶偏好的差異性。
我們還評估了系統(tǒng)建議的第一張構(gòu)圖恰好是用戶最喜歡構(gòu)圖的比率。我們將此度量表示為 Top 1 selection rate。下圖顯示了基于任務(wù) 2 中收集的參與者數(shù)據(jù)的 VPN,P-Module 和 Sal + Face 的比較。我們可以看到 P-Module 在每個用戶的構(gòu)圖選擇數(shù)據(jù)上表現(xiàn)優(yōu)于 VPN,總體而言,它大幅度的超越了其他 Baseline。基于成對 t 檢驗,我們發(fā)現(xiàn)結(jié)果很明顯:將 VPN 與 P-Module 進(jìn)行比較,T 值為 - 7.229,p <.001; 將 VPN 與 Sal + Face 進(jìn)行比較,T 值為 11.597,p <.001; 比較 P-Module 和 Sal + Face,T 值為 16.318,p <.001。我們還計算了三個模型的標(biāo)準(zhǔn)偏差值,如下圖所示。
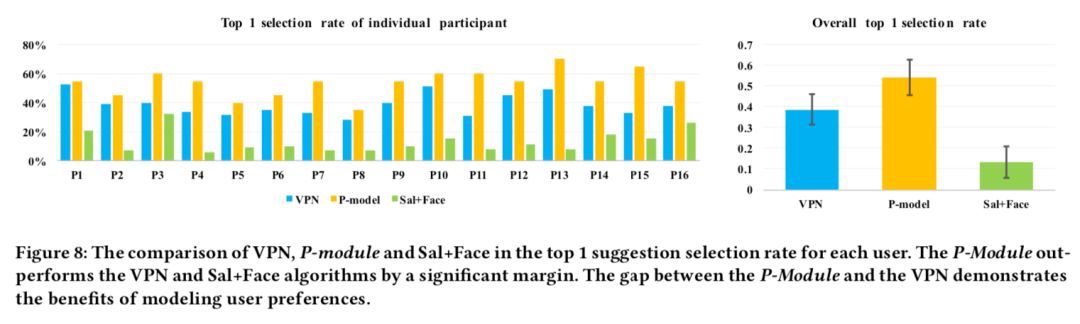
VPN,P 模塊和 Sal + Face 在每個用戶的 Top 1 selection rate 的比較。 P-Module 在很大程度上優(yōu)于 VPN 和 Sal + Face 算法。帶有 P-Module 的 VPN 和純 VPN 之間的差距證明了建模用戶偏好的好處。
Study 2
我們收集了任務(wù) 4 中各個參與者 30 天內(nèi)的拍照構(gòu)圖選擇,并在下圖中他們每天的平均 Top 1 selection rate。值得注意的是,總體來說,帶有 P-Module 的 SmartEye 的 Top 1 selection rate 在時間尺度上逐漸提高。它表明 SmartEye 能夠模擬用戶偏好并通過收集更多的用戶選擇數(shù)據(jù)來改進(jìn)自身。在第 6 天和第 15 天,性能略有下降。我們推測這些下降可能是由于用戶偏好會隨時間在某一天有所改變。照片構(gòu)圖任務(wù)與用戶的主觀判斷密切關(guān)聯(lián),在某些時間范圍內(nèi)可能發(fā)生局部下降。調(diào)查更為長期的影響可能是一項有趣的未來工作。
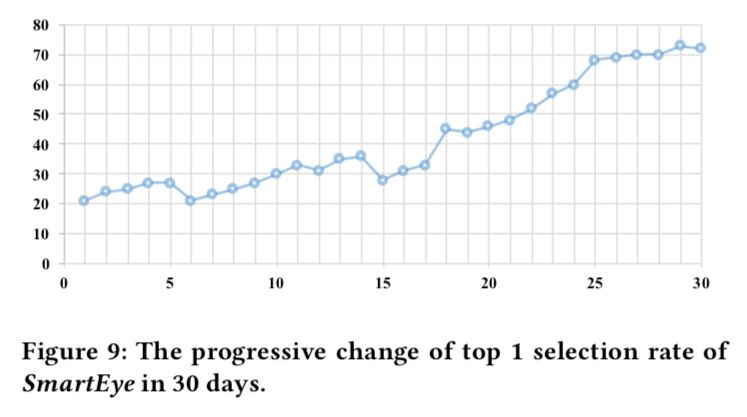
30 天內(nèi)所有參與者每一天的平均 top 1 selection rate
另外,下圖展示了在 30 天里每周的 4 種類型的特征和挑選出來的兩個用戶(P11 和 P5)構(gòu)圖偏好之間相關(guān)系數(shù)的變化。這個結(jié)果和 Task1 中的結(jié)果共同說明了不同的用戶可能依賴于不同的構(gòu)圖因素。它還表明一些用戶可能會隨著時間的推移個人喜好也會有所變化。同時,它有力的證明了為主觀任務(wù)建模用戶偏好的必要性。
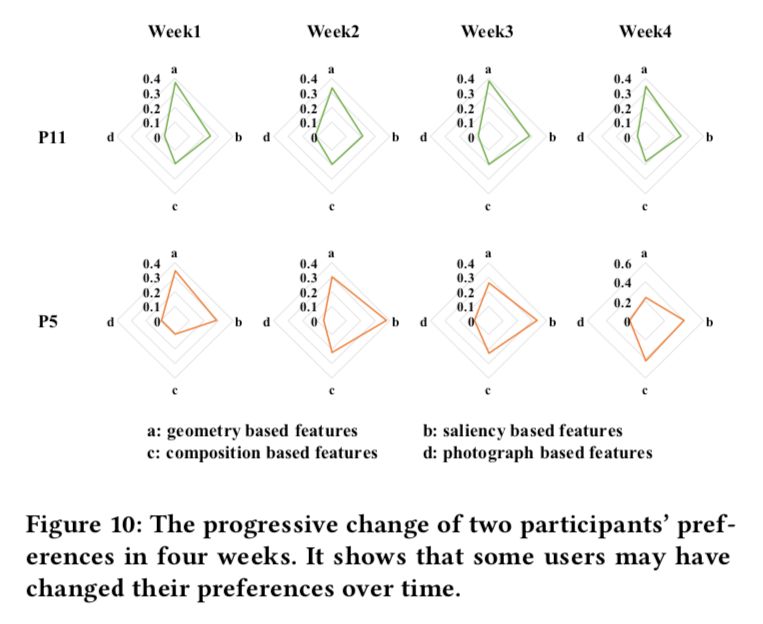
兩個參與者在四周時間內(nèi)偏好情況。這也表明了一些用戶的個人偏好會隨時間改變
Feedback from Interviews and Questionnaires
在這部分我們整理和收集了大量用戶的反饋意見,并進(jìn)行了歸納,為節(jié)約篇幅不做描述。
Preliminary and Post-Task Questionnaires
我們的實驗前問卷和實驗后問卷基于 5 分制,其中 5 分對應(yīng)強烈同意,1 分對應(yīng)強烈不同意。 下圖中的 Q1-Q8 驗證了自動構(gòu)圖和個性化構(gòu)圖推薦算法的有效性。Q9-Q20 顯示了關(guān)于本文提出的算法和設(shè)計的系統(tǒng)獲得的相關(guān)用戶反饋。總體而言,用戶對本文提出的 SmartEye 表達(dá)了相當(dāng)積極的態(tài)度。
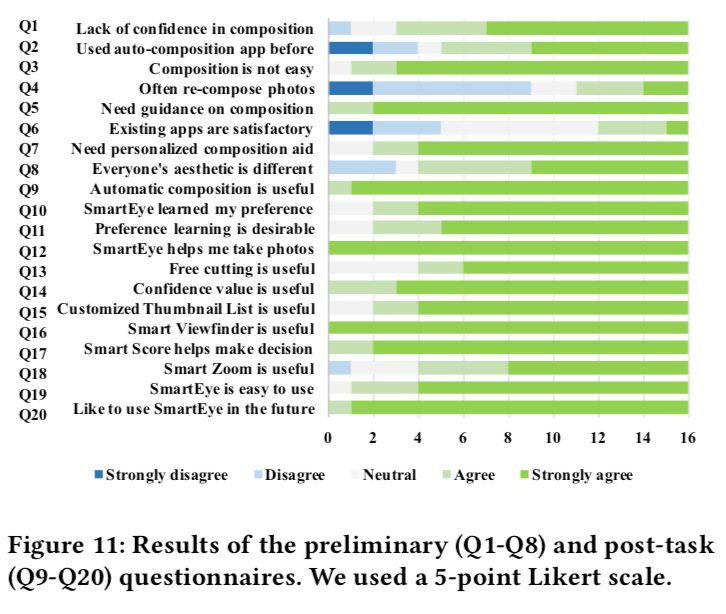
調(diào)查問卷和用戶訪談結(jié)果
討論
啟發(fā)
我們從中學(xué)習(xí)到了一些經(jīng)驗教訓(xùn),以進(jìn)一步改善具有個性化偏好建模的自動構(gòu)圖系統(tǒng)的用戶體驗。我們相信這些經(jīng)驗也適用于試圖將個性化偏好納入主觀任務(wù)的其他系統(tǒng)。
建模個性化偏好對于主觀任務(wù)很重要。根據(jù)訪談,我們發(fā)現(xiàn)參與者可以從系統(tǒng)從歷史數(shù)據(jù)中學(xué)習(xí)習(xí)慣和偏好的過程中獲益。
我們最好向用戶顯示系統(tǒng)如何 or 為何提出建議,而不是讓系統(tǒng)成為 “黑匣子”。在我們的采訪中,我們發(fā)現(xiàn) Smart Score 的得分以及置信度值得到了很多積極的反饋; 它幫助用戶完成構(gòu)圖任務(wù),并使系統(tǒng)更加透明和可靠。在更多細(xì)節(jié)中顯示“系統(tǒng)為什么這么認(rèn)為” 是這方面可能的未來方向。
未來工作
研究更 general 的構(gòu)圖推薦模型。我們的工作基于 VPN,并通過集成 P-Module 改善用戶體驗。請注意,VPN 并非一個自動構(gòu)圖的完美算法。通過采用更好的構(gòu)圖推薦模型,SmartEye 可以進(jìn)一步提升其性能。
使用協(xié)作過濾擴展到多個用戶。我們的偏好學(xué)習(xí)工作中的 P-Module 針對單個用戶進(jìn)行了更新; 因此,該推薦僅基于他 / 她自己的構(gòu)圖歷史。開發(fā)算法和交互技術(shù)以在許多用戶之間共享學(xué)習(xí)結(jié)果并以協(xié)作方式利用它們也是有趣的。
推薦手機鏡頭的移動方向。在拍照時實時地推薦手機移動方向似乎是我們的算法的直接擴展,但我們發(fā)現(xiàn)它在實踐中非常具有挑戰(zhàn)性:首先,因為一個圖像可能有多個好的建議,當(dāng)系統(tǒng)給出移動建議,但是用戶隨著指示移動鏡頭后,發(fā)現(xiàn)得到的構(gòu)圖不是自己想要的時候,它可能會損害用戶體驗;第二,系統(tǒng)必須跟蹤,平滑和記錄運動歷史,以預(yù)測下一個方向;第三,更絲滑的推薦移動方向(不讓用戶有延遲感),可能對系統(tǒng)響應(yīng)時間有更高的要求,解決它也可能是有趣的未來工作。
解釋有關(guān)模型決策的更多信息。VPN 是一種數(shù)據(jù)驅(qū)動模型,可直接從人類數(shù)據(jù)中學(xué)習(xí)構(gòu)圖知識。盡管我們有意收集了各類圖像數(shù)據(jù)用于構(gòu)圖,但很難保證我們現(xiàn)有的推薦模型考慮到了光照、聚焦等攝影學(xué)因素。通過觀察模型的輸出,我們推測 VPN 已經(jīng)隱含地考慮了這些方面。但是,在數(shù)據(jù)驅(qū)動模型的輸出中,很難明確地顯示哪個方面有多大程度的貢獻(xiàn)。為了明確地 model 其他方面的構(gòu)圖因素,我們可以在模型的輸出之后附加模塊,這些模塊特定于這些方面,畢竟許多這些方面的現(xiàn)成模型已經(jīng)取得了不錯的性能。
結(jié)論
我們研究了照片構(gòu)圖中的用戶偏好建模的概念,并且實現(xiàn)了一個新穎的系統(tǒng),該系統(tǒng)可以逐漸且交互式地學(xué)習(xí)用戶對照片構(gòu)圖的偏好。
同時,我們已經(jīng)證實,在構(gòu)圖任務(wù)中,不同用戶之間的偏好是不同的,甚至每個人的偏好也可能隨時間而變化,這進(jìn)一步表明了將用戶偏好學(xué)習(xí)應(yīng)用于當(dāng)前系統(tǒng)的必要性。 此外,我們將 P-Module 和 VPN 集成到一個交互式的實時的移動系統(tǒng) SmartEye 中,具有新穎的界面和一系列實用功能,如實時智能取景器,智能分?jǐn)?shù)和智能變焦。我們的用戶研究證明了 SmartEye 的有效性:我們已經(jīng)證明 SmartEye 優(yōu)于其他構(gòu)圖算法,系統(tǒng)支持的交互功能很有幫助,用戶對 SmartEye 整體十分滿意。
-
機器視覺
+關(guān)注
關(guān)注
163文章
4595瀏覽量
122844 -
VPN
+關(guān)注
關(guān)注
4文章
298瀏覽量
30574 -
AI
+關(guān)注
關(guān)注
88文章
35041瀏覽量
279220
原文標(biāo)題:拍照技術(shù)爛?實時在線AI構(gòu)圖模型VPN,讓你變身攝影大神!
文章出處:【微信號:rgznai100,微信公眾號:rgznai100】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
《AI for Science:人工智能驅(qū)動科學(xué)創(chuàng)新》第二章AI for Science的技術(shù)支撐學(xué)習(xí)心得
首創(chuàng)開源架構(gòu),天璣AI開發(fā)套件讓端側(cè)AI模型接入得心應(yīng)手
攝影新手必備器材
玩轉(zhuǎn)延時攝影,compass黑盒子的秘密
運動相機5種建筑攝影構(gòu)圖技巧
年輕人,以后讓AI給你升職加薪吧
【AI學(xué)習(xí)】AI概論:(Part-A)與AI智慧交流
《AI概論:來來來,成為AI的良師益友》高煥堂老師帶你學(xué)AI
《來來來,成為AI的良師益友》高煥堂老師AI學(xué)習(xí)資料大集合
基于MPLS的VPN技術(shù)原理及其實現(xiàn)
攝影/構(gòu)圖,攝影/構(gòu)圖是什么意思
VPN技術(shù)在數(shù)字社區(qū)的應(yīng)用






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論