 闡述正態分布的概率,并解釋它的應用為何如此的廣泛
闡述正態分布的概率,并解釋它的應用為何如此的廣泛
為什么正態分布如此特殊?為什么大量數據科學和機器學習的文章都圍繞正態分布進行討論?我決定寫一篇文章,用一種簡單易懂的方式來介紹正態分布。
在機器學習的世界中,以概率分布為核心的研究大都聚焦于正態分布。本文將闡述正態分布的概率,并解釋它的應用為何如此的廣泛,尤其是在數據科學和機器學習領域,它幾乎無處不在。
我將會從基礎概念出發,解釋有關正態分布的一切,并揭示它為何如此重要。
文章結構
本文的主要內容如下:
概率分布是什么
正態分布意味著什么
正態分布的變量有哪些
如何使用 Python 來檢驗數據的分布
如何使用 Python 參數化生產一個正態分布
正態分布的問題
簡短的背景介紹
首先,正態分布又名高斯分布
它以數學天才 Carl Friedrich Gauss 命名
正態分布又名高斯分布
越簡單的模型越是常用,因為它們能夠被很好的解釋和理解。正態分布非常簡單,這就是它是如此的常用的原因。
因此,理解正態分布非常有必要。
什么是概率分布?
首先介紹一下相關概念。
考慮一個預測模型,該模型可以是我們的數據科學研究中的一個組件。
如果我們想精確預測一個變量的值,那么我們首先要做的就是理解該變量的潛在特性。
首先我們要知道該變量的可能取值,還要知道這些值是連續的還是離散的。簡單來講,如果我們要預測一個骰子的取值,那么第一步就是明白它的取值是1 到 6(離散)。
第二步就是確定每個可能取值(事件)發生的概率。如果某個取值永遠都不會出現,那么該值的概率就是 0 。
事件的概率越大,該事件越容易出現。
在實際操作中,我們可以大量重復進行某個實驗,并記錄該實驗對應的輸出變量的結果。
我們可以將這些取值分為不同的集合類,在每一類中,我們記錄屬于該類結果的次數。例如,我們可以投10000次骰子,每次都有6種可能的取值,我們可以將類別數設為6,然后我們就可以開始對每一類出現的次數進行計數了。
我們可以畫出上述結果的曲線,該曲線就是概率分布曲線。目標變量每個取值的可能性就由其概率分布決定。
一旦我們知道了變量的概率分布,我們就可以開始估計事件出現的概率了,我們甚至可以使用一些概率公式。至此,我們就可更好的理解變量的特性了。概率分布取決于樣本的一些特征,例如平均值,標準偏差,偏度和峰度。
如果將所有概率值求和,那么求和結果將會是100%
世界上存在著很多不同的概率分布,而最廣泛使用的就是正態分布了。
初遇正態分布
我們可以畫出正態分布的概率分布曲線,可以看到該曲線是一個鐘型的曲線。如果變量的均值,模和中值相等,那么該變量就呈現正態分布。
如下圖所示,為正態分布的概率分布曲線:
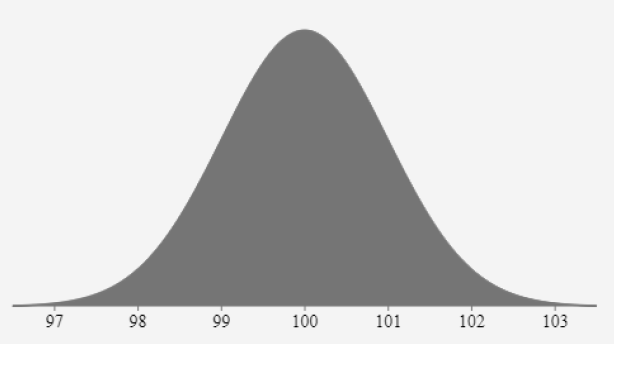
理解和估計變量的概率分布非常重要。
下面列出的變量的分布都比較接近正態分布:
人群的身高
成年人的血壓
傳播中的粒子的位置
測量誤差
回歸中的殘差
人群的鞋碼
一天中雇員回家的總耗時
教育指標
此外,生活中有大量的變量都是具有 x % 置信度的正態變量,其中,x<100。
什么是正態分布?
正態分布只依賴于數據集的兩個特征:樣本的均值和方差。
均值——樣本所有取值的平均
方差——該指標衡量了樣本總體偏離均值的程度
正態分布的這種統計特性使得問題變得異常簡單,任何具有正態分布的變量,都可以進行高精度分預測。
值得注意的是,大自然中發現的變量,大多近似服從正態分布。
正態分布很容易解釋,這是因為:
正態分布的均值,模和中位數是相等的。
我們只需要用均值和標準差就能解釋整個分布。
正態分布是我們熟悉的正常行為
為何如此多的變量都大致服從正態分布?
這個現象可以由如下定理理解釋:當在大量隨機變量上重復很多次實驗時,它們的分布總和將非常接近正態分布。
由于人的身高是一個隨機變量,并且基于其他隨機變量,例如一個人消耗的營養量,他們所處的環境,他們的遺傳等等,這些變量的分布總和最終是非常接近正態的。
這就是中心極限定理。
本文的核心:
我們從上文的分析得出,正態分布是許多隨機分布的總和。 如果我們繪制正態分布密度函數,那么它的曲線將具有以下特征:
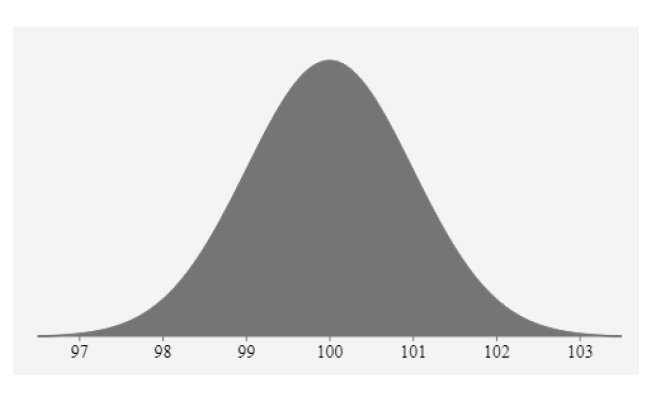
如上圖所示,該鐘形曲線有均值為 100,標準差為1:
均值是曲線的中心。 這是曲線的最高點,因為大多數點都是均值。
曲線兩側的點數相等。 曲線的中心具有最多的點數。
曲線下的總面積是變量所有取值的總概率。
因此總曲線面積為 100%
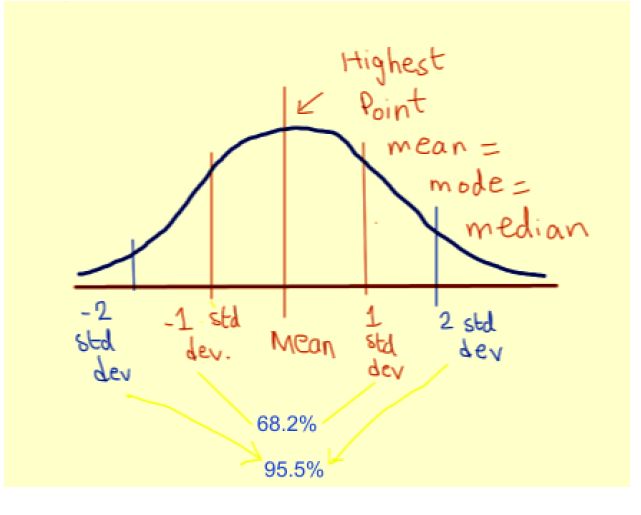
更進一步,如上圖所示:
約 68.2% 的點在 -1 到 1 個標準偏差范圍內。
約 95.5% 的點在 -2 到 2 個標準偏差范圍內。
約 99.7% 的點在 -3 至 3 個標準偏差范圍內。
這使我們可以輕松估計變量的變化性,并給出相應置信水平,它的可能取值是多少。例如,在上面的灰色鐘形曲線中,變量值在 99-101 之間的可能性為 68.2%。
正態概率分布函數
正態概率分布函數的形式如下:

概率密度函數基本上可以看作是連續隨機變量取值的概率。
正態分布是鐘形曲線,其中mean = mode = median。
如果使用概率密度函數繪制變量的概率分布曲線,則給定范圍的曲線下的面積,表示目標變量在該范圍內取值的概率。
概率分布曲線基于概率分布函數,而概率分布函數本身是根據諸如平均值或標準差等多個參數計算的。
我們可以使用概率分布函數來查找隨機變量取值范圍內的值的相對概率。 例如,我們可以記錄股票的每日收益,將它們分組到適當的集合類中,然后計算股票在未來獲得20-40%收益的概率。
標準差越大,樣品中的變化性越大。
如何使用 Python 探索變量的概率分布
最簡單的方法是加載 data frame 中的所有特征,然后運行以下腳本(使用pandas 庫):
DataFrame.hist(bins=10)#Make a histogram of the DataFrame.
該函數向我們展示了所有變量的概率分布。
變量服從正態分布意味著什么?
如果我們將大量具有不同分布的隨機變量加起來,所得到的新變量將最終具有正態分布。這就是前文所述的中心極限定理。
服從正態分布的變量總是服從正態分布。 例如,假設 A 和 B 是兩個具有正態分布的變量,那么:
?A x B 是正態分布
?A + B 是正態分布
因此,使用正態分布,預測變量并在一定范圍內找到它的概率會變得非常簡單。
樣本不服從正態分布怎么辦?
我們可以將變量的分布轉換為正態分布。
我們有多種方法將非正態分布轉化為正態分布:
1.線性變換
一旦我們收集到變量的樣本數據,我們就可以對樣本進行線性變化,并計算Z得分:
計算平均值
計算標準偏差
對于每個 x,使用以下方法計算 Z:

2.使用 Boxcox 變換
我們可以使用 SciPy 包將數據轉換為正態分布:
scipy.stats.boxcox(x,lmbda=None,alpha=None)
3.使用 Yeo-Johnson 變換
另外,我們可以使用 yeo-johnson 變換。 Python 的 sci-kit learn 庫提供了相應的功能:
sklearn.preprocessing.PowerTransformer(method=’yeojohnson’,standardize=True,copy=True)
正態分布的問題
由于正態分布簡單且易于理解,因此它也在預測研究中被過度使用。 假設變量服從正態分布會有一些顯而易見的缺陷。 例如,我們不能假設股票價格服從正態分布,因為價格不能為負。 因此,我們可以假設股票價格服從對數正態分布,以確保它永遠不會低于零。
我們知道股票收益可能是負數,因此收益可以假設服從正態分布。
假設變量服從正態分布而不進行任何分析是愚蠢的。
變量可以服從Poisson,Student-t 或 Binomial 分布,盲目地假設變量服從正態分布可能導致不準確的結果。
總結
本文闡述了正態分布的概念和性質,以及它如此重要的原因。
希望能幫助到你。
-
機器學習
+關注
關注
66文章
8453瀏覽量
133152 -
數據集
+關注
關注
4文章
1210瀏覽量
24860
原文標題:正態分布為何如此重要?
文章出處:【微信號:rgznai100,微信公眾號:rgznai100】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
一文解析LOPA應用-點火概率估算的策略與實踐

絕緣電阻測試的基礎以及為什么它如此重要
圖像高斯濾波的原理及FPGA實現思路

電網中防逆流為何如此重要?
【探討】DTAS尺寸公差分析與尺寸鏈計算邀您探索單孔銷浮動之奧秘(二),快來圍觀吧!
空載時為何OPA454如此發燙,這個發燙是正常現象嗎?
工廠人員定位為何如此重要?它有怎樣的方案優勢?
網絡延遲為何如此重要
環保又高效:365nm固化燈為何如此受歡迎?

揭秘芯片算力:為何它如此關鍵?

RISC-V為何如此重要?





 工商網監
工商網監
評論