 電子發燒友App
電子發燒友App


盡管以太坊的許多理念在早先的加密貨幣(如比特幣)上已經運用并測試了5年之久,但從處理某些協議功能上來說,以太坊的處理方式與常見方式仍有許多不同。很多時候,以太坊會被用來建立全新的經濟方法,因為它具有許多其他系統不具備的功能。本文會詳細描述以太坊所有潛在的優點以及在構建以太坊協議過程中某些有爭議的地。另外,也會指出我們的方案及替代方案潛在的風險。
原則
以太坊協議的設計遵循以下幾點原則:
1.三明治復雜模型
我們認為以太坊的底層協議應盡可能的簡單,接口設計應易于理解,那些不可避免的復雜部分應放入中間層。中間層不是核心共識的一部分,且對最終用戶不可見,它包含:高級語言編譯器、參數序列化和反序列化腳本、存儲數據結構模型、leveldb存儲接口以及線路協議等。當然,這樣的設置也并非絕對。
2.自由
不應限制用戶使用以太坊協議,也不應試圖優先支持或不支持某些以太坊合約或交易。這一點與“網絡中立”概念背后的指導原則相似。比特幣交易協議就沒有遵循這一原則。在比特幣交易協議中,并不鼓勵為了“去除標簽”而使用區塊鏈(如,數據存儲,元協議)。某些情況下,對準協議進行明顯修改會引起不法分子以未經授權方式使用區塊鏈來攻擊應用。因此,在以太坊,我們強烈建議設置交易費用,且用戶使用區塊鏈的步驟越多,交易費用也就越多(類似庇古稅)。這樣,既可以將交易費用作為合法礦工的獎勵,又能讓那些不法分子付出代價,一舉兩得。
3.泛化
以太坊協議的特性和操作碼應最大限度地體現低層次的概念(就像基本粒子一樣),以便它們可以隨意組合。因此,通過剝離那些不需要的功能,使低層次的概念更加高效。遵循這一原則的例子是,我們選擇LOG操作碼作為向dapps提供信息的方式,而不是像之前那樣記錄下所有交易和消息信息。在早先,“消息(message)”的概念完完全全是多種概念的集合,它包含“函數調用(function call)”和“外在觀察者感興趣的事情(event interesting to outside watchers)”,而兩者是完全可以分離開來的。
4.沒有特點就是最大的特性點
為了遵循泛化原則,我們拒絕將那些高級用例內嵌為協議的一部分,哪怕是經常使用的用例,也絕不這么做。如果人們真的想實現這些用例,可以在合約內創建子協議(如,基于以太坊的子貨幣,比特幣/萊特幣/狗幣的側鏈等)。比如,在以太坊中就缺少類似比特幣中的“時間鎖定”功能。但是,通過以下協議可以模擬出這個功能:用戶發送簽名數據包到特定的合約中處理,如果數據包在特定合約中有效,則執行相應的函數。
5.沒有風險規避機制
如果風險的增加帶來了可觀的好處,我們愿意承擔更高的風險(例如,廣義狀態轉換,區塊時間提升50倍,共識效率)。
這些原則指導著以太坊的發展,但它們并不是絕對的;某些情況下,為了減少開發時間或者不希望一次作出過多改變,也會使我們推遲作出某些修改,把它留到將來的版本中去修改。
區塊鏈層協議
本節對以太坊中區塊鏈層協議的改變進行了描述,包括區塊和交易是如何工作的、數據如何序列化及存儲、賬戶背后的機制。
賬戶 ,而非UTXO①
比特幣及其許多衍生品,都將用戶的余額信息存儲在UTXO結構中,系統的整個狀態由一系列的“有效的輸出”組成(可以將這些“有效的輸出”想象成錢幣)。每個UTXO都有擁有者和自身的價值屬性。一筆交易在消費若干個UTXO同時也會生成若干個新的UTXO。“有效的輸出”中有效需滿足下面幾點約束:
1.每個被引用的輸入必須有效,且未被使用過;
2.交易的簽名必須與每筆輸入的所有者簽名匹配;
3.輸入的總值必須等于或大于輸出的總值。
因此,比特幣系統中,用戶的“余額”是該用戶的私鑰能夠有效簽名的所有UTXO的總和。下圖展示了比特幣系統中交易輸入輸出過程:
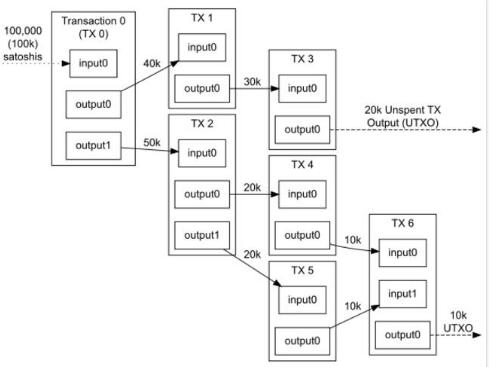
但是,以太坊拋棄了UTXO的方案,轉而使用更簡單的方法:采用狀態(state)的概念存儲一系列賬戶,每個賬戶都有自己的余額,以及以太坊特有的數據(代碼或內部存儲器)。如果交易發起方的賬戶余額足夠支付交易費用,則交易有效,那么發起方賬戶會扣除相應金額,而接受賬戶則計入該金額。某些情況下,接受賬戶內有需要執行的代碼,則交易會觸發該代碼的執行,那么賬戶的內部存儲器可能就會發生變化,甚至可能會創建額外的信息發送給其他賬戶,從而導致新的交易發生。
盡管以太坊沒有采用UTXO的概念,但UTXO也不乏有一些優點:
1.較高程度的隱私保護
如果用戶每次交易都使用一個新的地址,那么賬戶之間的相互關聯就很困難。這樣做適用于對安全性要求高的貨幣系統,但對任何dapp應用來說就不合適了。因為dapp通常需要跟蹤用戶復雜的綁定狀態,而dapp的狀態并不能像貨幣系統中的狀態那樣簡單地劃分。
2.潛在地可擴展性
UTXO在理論上可擴展性更好。因為我們只能依靠那些金融貨幣擁有者來維護能夠證明貨幣所有權的默克爾樹,即使所有的人(包括數據的擁有者)都遺忘了某一數據,真正受損也只有數據的擁有者,其他人不受影響。
在以太坊賬戶系統中,如果一個賬戶對應在默克爾樹中信息被所有人都丟失了,那么該賬戶將無法處理任何能夠影響它的消息,包括發送給它的消息,它也無法處理。
不過,并非只有UTXO能夠可擴展,也存在不依賴UTXO就能擴展的方式(此處沒有擴展開來講,譯者注)。
賬戶的好處有以下幾點:
1.節省大量空間
如果一個賬戶有5個UTXO,則從UTXO模式轉成賬戶模式所需空間會從300字節降到30字節。具體計算如下:
300 = (20+32+8)* 5 (20是地址字節數,32是TX的id字節數,8是交易金額值字節數);
30 = 20 + 8 + 2 ( 20是地址字節數,8是交易金額值字節數,2是nonce②字節數)
但實際節約并沒有這么大,因為賬戶需要被存儲在帕特里夏樹中。另外以太坊中交易也比比特幣中的更小(以太坊中100字節,比特幣中200-250字節),因為每次交易只需要生成一次引用,一次簽名,以及一個輸出。
2.可替代性更高
在UTXO結構中,“有效輸出”的源碼實現中沒有區塊鏈層的概念,所以不管是在技術還是法律上,通過建立一個紅名單/黑名單,并依據的這些“有效輸出”的來源區分它們并不是很實際。
3.簡單
以太坊編碼更簡單、更易于理解,尤其是在涉及到復雜腳本時。盡管任何去中心化應用都可以用UTXO方式來實現,但這種方式實質上是通過賦予一個腳本限制給定的UTXO能夠使用以及請求的UTXO的種類的方式來實現,包括腳本評估的應用更改根狀態的默克爾樹證明。因此,UTXO實現方式比以太坊使用賬戶的方式要復雜的多。
4.輕客戶端
輕客戶端可以隨時通過沿指定方向掃描狀態樹來訪問與賬戶相關的所有數據。在UTXO方式中,引用隨著每個交易的變化而變化,這對于長時間運行并使用了上文提到的UTXO根狀態傳播機制的dapp應用來說,無疑是繁重的。
我們認為,賬戶的好處大大超過了其他方式,尤其是對于我們正在處理的包含任意狀態和代碼的dapp應用而言。另外,本著“沒有特點就是最大的特點”的指導原則,我們認為如果用戶真的關心私密性,則可以通過合約中的簽名數據包協議來建立一個加密“混合器”進行加密。
賬戶方式的一個弱點是:為了阻止重播攻擊,每筆交易必須有nonce,這就使得賬戶需要跟蹤nonce的使用情況,并且只有在nonce最后使用后且值為1時才接受交易。這就意味著,即使不再使用的賬戶,也不能從賬戶狀態中移除。解決這個問題的一個簡單方法是讓交易包含一個區塊號,使它們在幾個時間段內不重復,并且每個時間段重置nonce。由于完全掃描賬戶的開銷太大,所以為了刪除未使用的賬戶,礦工或用戶需要通過“Ping”操作來實現。在1.0上我們沒有實現這個機制,1.1及以上版本可能會使用這個機制。
默克爾帕特里夏樹
默克爾帕特里夏樹(Merkle Patricia tree/trie),由Alan Reiner提出設想,并在瑞波協議中得到實現,是以太坊的主要數據結構,用于存儲所有賬戶狀態,以及每個區塊中的交易和收據數據。MPT是默克爾樹和帕特里夏樹的結合縮寫,結合這兩種樹創建的結構具有以下屬性:
1.每個唯一鍵值對唯一映射到根的hash值;在MPT中,不可能僅用一個鍵值對來欺騙成員(除非攻擊者有~2^128 的算力);
2.增、刪、改鍵值對的時間復雜度是對數級別。
MPT為我們提供了一個高效、易更新、且代表整個狀態樹的“指紋”。
關于MPT更詳細描述:https://github.com/ethereum/wiki/wiki/Patricia-Tree
MPT的具體設計決策如下:
1.有兩類節點
KV節點和離散節點。KV節點的存在提高了效率,因為如果在特定區域樹是稀疏的,KV節點可作為一個“快捷方式”,代替深度為64的樹。
2.離散節點是16進制,不是二進制
這樣讓查找更有效率,我們現在認識到這種選擇并不理想,因為16進制樹的查找效率在二進制中可以通過批次存儲節點來模擬。MPT樹的結構實現是非常容易出錯的,最終至少會造成狀態根不匹配。
3.空值(empty value)與非會員(non-membership)之間沒有區別
這樣做是為了簡化邏輯,以太坊中未設置的值默認為0,空字符串也用0表示。然而,需要強調的是,這樣做犧牲了一些通用性,因而也不是最優的。
4.終節點和非終節點的區別
技術上,標識一個節點“是否是終節點”是沒必要的,因為以太坊中所有的樹都被用于存儲靜態秘鑰長度,但為了增加通用性,我們還是會添加這個標識,以期望以太坊的MPT的實現方式能夠被其他加密貨幣原樣采納。
5.在安全樹中采用SHA3(k)作為秘鑰(在狀態樹和賬戶存儲樹中使用)
使用SHA3(k),通過設置離散節點的鏈的深度為64,以及反復調用SLOAD 和 SSTORE指令,使那些企圖對樹采取Dos攻擊的行為變得非常困難。不過,這也讓窮舉樹的節點變得困難,如果你希望你的客戶端有窮舉的能力,最簡單的方法是維持一個數據庫映射:sha3(k) -》 k
RLP
RLP(recursive length prefix):遞歸長度前綴。
RLP編碼是以太坊中主要的序列化格式,它的使用無處不在:區塊、交易、賬戶狀態以及線路協議消息。詳見RLP正式描述: https://github.com/ethereum/wiki/wiki/RLP
RLP旨在成為高度簡化的序列化格式,它唯一的目的是存儲嵌套的字節數組③。不同于protobuf、BSON等現有的解決方案,RLP并不定義任何指定的數據類型,如Boolean、floa、double或者integer。它僅僅是以嵌套數組的形式存儲結構,并將其留給協議來確定數組的含義。RLP也沒有明確支持map集合,半官方的建議是采用 [[k1, v1], [k2, v2], 。..] 的嵌套數組來表示鍵值對集合,k1,k2 。.. 按照字符串的標準排序。
與RLP具有相同功能的方案是protobuf或BSON,它們是一直被使用的算法。然而,以太坊中,我們更偏向于使用RLP,因為:
1.它易于實現;
2.絕對保證字節的一致性。
許多語言的Map集合沒有明確的排序,并且浮點格式有很多特殊情況,這可能造成相同數據卻導致不同編碼和hash值。通過內部開發協議,我們能確保它是帶著這些目標設計的(這是一般原則,也適用于代碼的其他部分,如VM)。BitTorrent使用的編碼方式bencode也許可以替代RLP。不過它采用的是十進制的編碼方式,與采用二進制的RLP相比,稍微遜色了點。
壓縮算法
線路協議和數據庫都采用了一個自定義的壓縮算法來存儲數據。該算法可描述為:行程編碼④值為0并同時保留其他值(除了一些特殊情況如sha3(‘ ’) ),舉例如下:
》》》 compress(‘horse’)
‘horse’
》》》 compress(‘donkey dragon 1231231243’)
‘donkey dragon 1231231243’
》》》 compress(‘\xf8\xaf\xf8\xab\xa0\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\xbe{b\xd5\xcd\x8d\x87\x97’)
‘\xf8\xaf\xf8\xab\xa0\xfe\x9e\xbe{b\xd5\xcd\x8d\x87\x97’
》》》 compress(“\xc5\xd2F\x01\x86\xf7#《\x92~}\xb2\xdc\xc7\x03\xc0\xe5\x00\xb6S\xca\x82‘;{\xfa\xd8\x04]\x85\xa4p”)
‘\xfe\x01’
壓縮算法存在之前,以太坊協議的許多地方都有一些特殊情況,例如,sha3經常被覆蓋,所以sha3(‘ ’)=‘ ’,這樣不需要在賬戶中存儲代碼,可以節省64字節。然而,最近所有這些使得以太坊數據結構變得臃腫的特殊情況都被刪除了,取而代之的是將數據保存函數添加到區塊鏈協議之外的層,也就是將其放入線路協議以及將其插入用戶數據庫實現。這樣增加了模塊化能力,簡化了共識層,使得壓縮算法能持續更新以便相對容易部署。
樹(trie)的使用
以太坊區塊鏈中每個區塊頭都包含指向三個樹的指針:狀態樹、交易樹、收據樹。
狀態樹代表訪問區塊后的整個狀態;
交易樹代表區塊中所有交易,這些交易由index索引作為key;(例如,k0:第一個執行的交易,k1:第二個執行的交易)
收據樹代表每筆交易相應的收據。交易的收據是一個RLP編碼的數據結構:
[ medstate, gas_used, logbloom, logs ]
其中:
? medstate:交易處理后,樹的根的狀態;
? gas_used:交易處理后,gas的使用量;
? logs:是表格[address, [topic1, topic2.。.], data]元素的列表。表格由交易執行期間調用的操作碼LOG0 。.. LOG4 生成(包含主調用和子調用);address 是生成日志的合約的地址topics是最多4個32字節的值;data 是任意字節大小的數組;
? logbloom:交易中所有logs的address和topic組成的布隆過濾器⑤。
區塊頭中也存在一個布隆過濾器,它是區塊中交易的所有布隆過濾器的邏輯或組成。這樣的構造使得以太坊協議輕客戶端的使用盡可能的友好。
Uncle塊(過時區塊)的獎勵
2013年10月,由喬森納和特拉維夫首次提出的GHOST協議是一項不起的革新。它是加快生成區塊時間的第一個認真嘗試。因為區塊在網絡中傳播需要一定時間,如果礦工A挖到一個區塊并向全網廣播,在廣播的路上,B也挖出了區塊,那么B的區塊是過時的,且B的本次挖礦對網絡的安全沒有貢獻。GHOST的目的正是要解決挖礦過時造成的安全性降低的問題。
此外,還有一個中心化問題:如果A是一個礦池,有30%的算力,B有10%的算力。A有70%的時間產生過時的區塊(因為另外的30%時間會產生最新區塊,所以它會立即挖到數據),而B有90%的時間產生過時區塊。如果區塊的產出時間間隔很短,那么過時率就會變高,則A憑借其更大的算力使挖礦效率也更高。所以,區塊生成過快,容易導致網絡算力大的礦池控制挖礦過程。
根據喬森納和特拉維夫的描述,GHOST解決了在計算哪個鏈是最長的鏈的過程中,因產生過時區塊而造成的網絡安全性下降的問題。也就是說,不僅是父區塊和更早的區塊,同時Uncle區塊⑥也被添加到計算哪個塊具有最大的工作量證明中去。
為了解決第二個問題:中心化問題,我們采用不同的策略:對過時區塊也提供區塊獎勵:挖到過時區塊的獎勵是該區塊基礎獎勵的7/8;挖到包含過時區塊的nephew區塊將收到1/32的基礎獎勵作為賞金。但是,交易費并不獎勵給Uncle區塊或nephew區塊。
在以太坊,過時分叉上7代內的親屬區塊才能稱作過時區塊。之所以這樣限制是因為,首先,GHOST協議若不限制過時區塊數量,將會花費大量開銷在計算過時區塊的有效性上;其次,無限制的過時區塊激勵政策會讓礦工失去在主鏈上挖礦的熱情;最后,計算表明,過時區塊獎勵政策限制在7層內提供了大部分所需的效果,而且不會帶來負面效應。
區塊時間算法的設計決策包括:
? 區塊時間12s:選擇12s是因為這已經是最快的時間了,基本上比網絡延遲更長。在2013年的一份關于測量比特幣網絡延遲的論文中,確定了12.6秒是新產生的區塊傳播到95%節點的時間;然而,該論文還指出傳播時間與區塊大小成比例,因此在更快的貨幣中,我們可以期待傳播時間大大減少。傳播間隔時間是恒定的,約為2秒。然而,為了安全起見,在我們的分析中,我們假定區塊的傳播需要12秒。
? 7個祖先塊的限制:這樣設計的目的是希望只保留少量區塊,而將更早之前的區塊清除。已經證明7個區塊可以提供大部分所需的效果。
? 1個后裔區塊的限制:如c(c(p(p(p(head))))) c=child, p = parent,就不合法,因為它有兩個后裔區塊。這樣設計的目的是為了簡單,上面的模擬結果顯示它并沒有構成大的中心化風險。
? **uncle塊要求具有有效性: **uncle塊必須是有效的header,而不是有效的區塊。這樣做也是為了簡化,將區塊鏈模型保持為線性數據結構。不過,要求uncle塊是有效的區塊也是合法的方法。
? 獎金分配:7/8的挖礦基礎獎勵分配給uncle塊,1/32分給nephew塊,它們交易費用都是0%。如果費用占多數,從中心化的角度看,這會使uncle塊激勵機制無效;然而,這也是為什么只要我們繼續使用PoW,以太坊就會不斷發行以太幣的原因。
難度更新算法
目前以太坊通過以下規則進行難度更新:
diff(genesis) = 2^32
diff(block) = diff.block.parent + floor(diff.block.parent / 1024) *
1 if block.timestamp - block.parent.timestamp 《 9 else
-1 if block.timestamp - block.parent.timestamp 》= 9
難度更新規則的設計目標如下:
? 快速更新:區塊間的時間應該隨著hash算力的增減而快速調整;
? 低波動性:如果Hash算力恒定,那么難度不應劇烈波動;
? 簡單:算法的實現應相對簡單;
? 低內存:算法不應依賴于過多的歷史區塊,要盡可能少的使用”內存變量“。假設有最新的十個區塊,將存儲在這十個區塊頭部的內存變量相加,這些區塊都可用于算法的計算;
? 非開發性:算法不應讓礦工有過多篡改時間戳或者礦池、反復添加或刪除算力的能力,以使他們的收益最大化。
我們當前的算法在低波動性和非開發性上并不理想,至少我們計劃切換時間戳比較父區塊和祖父區塊,所以礦工只有在連續挖2個區塊時,才有動力去修改時間戳。另一個更強大的模擬公式: https://github.com/ethereum/economic-modeling/blob/master/diffadjust/blkdiff.py
Gas和費用
比特幣中所有交易大體相同,因此它們的網絡成本可以建成一個模型。以太坊中的交易要更復雜,所以交易費用需要考慮到賬戶的許多方面,包括寬帶費用,存儲費用和計算費用。尤其重要的是,以太坊編程語言是圖靈完備的,所以交易會使用任意數量的寬帶、存儲和計算成本。這就可能會導致在計算成本過程中,突遭停電而計算被迫中止。
以太坊交易費用的基本機制如下:
? 每筆交易必須指明一定數量的gas(即指定startgas的值),以及支付每單元gas所需費用(即gasprice),在交易執行開始時,startgas * gasprice 價值的以太幣會從發送者賬戶中扣除;
? 交易執行期間的所有操作,包括讀寫數據庫、發送消息以及每一步的計算都會消耗一定數量的gas;
? 如果交易執行完畢,消耗的gas值小于指定的限制值,則交易執行正常,并將剩余的gas值賦予變量gas_rem ; 在交易完成后,發送者會收到返回的gas_rem * gasprice 價值的以太幣,而給礦工的獎勵是(startgas - gas_rem)* gasprice價值的以太幣;
? 如果交易執行中,gas消耗殆盡,則所有的執行恢復原樣,但交易仍然有效,只是交易的唯一結果是將 startgas * gasprice 價值的以太幣支付給礦工,其他不變;
? 當一個合約發送消息給另一個合約,可以對這個消息引起的子執行設置一個gas限制。如果子執行耗盡了gas,則子執行恢復原樣,但gas仍然消耗。
上述提到的幾點都是必須滿足的,例如:
? 如果交易沒有指定gas限制,那么惡意用戶就會發送一個有數十億步循環的交易。沒有人能夠處理這樣的交易,因為處理這樣的交易花的時間可能很長很長,從而無法預先告知網絡上的礦工,這會導致拒絕服務的漏洞產生。
? 替代嚴格的gas計數、時間限制等機制的方案不起作用,因為它們太主觀了
? startgas * gasprice 的整個值,在開始時就應該設置好,這樣不至于在交易執行中因gas不夠而造成交易終止。注意,僅僅檢查賬戶余額是不夠的,因為賬戶可以在其他地方發送余額。
? 如果在gas不夠的情況下,交易執行沒有恢復操作(回滾),合約必須采用強有力的安全措施來防止合約發生變化。
? 如果子限制不存在,則惡意賬戶會通過與其他賬戶達成協議來對它們采取拒絕服務攻擊。在計算開始時插入一個大循環,那么發送消息給受害合約或者受害合約的任何補救嘗試,都會使整個交易死鎖。
? 要求交易發送者而不是合約來支付gas,這樣大大增加了開發人員的可操作性。以太坊早期的版本是由合約來支付gas的,這導致了一個相當嚴重的問題:每個合約必須實現“守護”代碼,確保每個傳入的消息有足夠的以太幣供其消耗。
gas消耗計算有以下特點:
? 對于任何交易,都將收取21000gas的基本費用。這些費用可用于支付運行橢圓曲線算法所需的費用。該算法旨在從簽名中恢復發送者的地址以及存儲交易所花費的硬盤和帶寬空間。
? 交易可以包括無限量的“數據”。虛擬機中的某些操作碼,可以讓合約允許交易對這些數據的訪問。數據的固定消耗計算是:每個零字節4gas,非零字節68gas。這個公式的產生是因為合約中大部分的交易數據由一些列的32字節的參數組成,其中多數參數具有許多前導零字節。該結構看起來似乎效率不高,但由于壓縮算法的存在,實際上還是很有效率的。我們希望此結構能夠代替其他更復雜的機制:這些機制根據預期字節數嚴格包裝參數,從而導致編譯階段復雜性大增。這是三明治復雜模型的一個例外,但由于成本效益比,這也是合理的模型。
? 用于設置賬戶存儲器的操作碼SSTORE的消耗是:1.將零值改為非零值時,消耗20000gas;2.將零值變成零值,或非零值變非零值,消耗5000gas;3.將非零值變成零值,消耗5000gas,加上交易執行成功后退回的20000gas。退款金額上限是交易消耗gas總額的50%。這樣設置會激勵人們清除存儲器。我們注意到,正因為缺乏這樣的激勵,許多合約造成了存儲空間沒有被有效使用,從而導致了存儲快速膨脹;為存儲收取費用提供了很多好處,同時不會失去合約一旦確立就可以永久存在的保證。延遲退款機制是必要的,因為可以阻止拒絕服務攻擊。攻擊者發送一筆含有少量gas的交易,循環清除大量的存儲,直到用光gas,這樣消耗了大量的驗證算力,但實際并沒有真正清除存儲或消耗大量gas。50%的上限的是為了確保獲得了一定交易gas的曠工依然能夠確定執行交易的計算時間的上限。
? 合約提供的消息的數據是沒有成本的。因為在消息調用期間不需要實質復制任何數據,調用數據可以簡單地視為指向父合約內存的指針,該指針在子進程執行時不會改變。
? 內存是一個可以無限擴展的數組,然而,每擴展32字節的內存就會消耗1gas的成本,不足32字節以32字節計。
? 某些操作碼的計算時間極度依賴參數,gas開銷計算是動態變化的。例如,EXP的的開銷是指數級別的;復制操作碼(如:CALLDATACOPY, CODECOPY, EXTCODECOPY)的開銷是1+1(每復制32字節)。內存擴展的開銷不包含在這里,因為它觸發了二次攻擊。
? 如果值不是零,操作碼CALL會額外消耗9000gas。這是因為任何值傳輸都會引起歸檔節點的歷史存儲顯著增大。請注意,實際消耗是6700,在此基礎上,我們強制增加了一個自動給予接受者的gas值,這個值最小2300。這樣做是為了讓接受交易的錢包至少有足夠的gas來記錄交易。
gas機制的另一個重要部分是gas價格本身體現出的經濟學原理。比特幣中,默認的方法是采取純粹自愿的收費方式,礦工扮演守門人的角色并且動態設置收費的最小值。以太坊中允許交易發送者設置任意數目的gas。這種方式在比特幣社區非常受歡迎,因為它是“市場經濟”的體現:允許礦工和交易者之間依據供需關系來決定價格。然而,這種方式的問題是,交易處理并不遵循市場原則。盡管可以將交易處理看作是礦工向發送者提供的服務(這聽起來很直觀),但實際上礦工所處理的每個交易都必須由網絡中的每個節點處理,所以交易處理的大部分成本都由第三方機構承擔,而不是決定是否處理它的礦工。
當前,因為缺乏礦工在實際中的行為的明確信息,所以我們將采取一個非常簡單公平的方法:投票系統,來設定gas限定值。礦工有權將當前區塊的gas限定值設定在最后區塊的gas限定值的0.0975% (1/1024)內。所以最終的gas限定值應該是礦工們設置的中間值。我們希望將來能夠采用軟分叉的方法來使用更加精確的算法。
虛擬機
以太坊虛擬機是執行交易代碼的引擎,也是以太坊與其他系統的核心區別。請注意,虛擬機應該同“合約與消息模型”分開考慮。例如,SIGNEXTEND操作碼是虛擬機的一個功能,但實際上“某個合約調用其他合約并指定子調用的gas限定值”是“合約與消息模型”的一部分。 EVM的設計目標如下:
? 簡單:操作碼盡可能的少并且低級;數據類型盡可能少;虛擬機的結構盡可能少;
? 結果明確:在VM規范語句中,沒有任何可能產生歧義的空間,結果應該是完全確定的。此外,計算步驟應該是精確的,以便可以測量gas的消耗量;
? 節約空間:EVM組件應盡可能緊湊;
? 預期應用應具備專業化能力:在VM上構建的應用應能處理20字節的地址,以及32位的自定義加密值,擁有用于自定義加密的模數運算、讀取區塊和交易數據與狀態交互等能力;
? 簡單安全:為了讓VM不被利用,應該能夠容易地讓建立一套gas消耗成本模型的操作;
? 優化友好:應該易于優化,以便即時編譯(JIT)和VM的加速版本能夠構建出來。
同時EVM也有如下特殊設計:
? 臨時/永久存儲的區別:
我們先來看看什么是臨時存儲和永久存儲。
臨時存儲:存在于VM的每個實例中,并在VM執行結束后消失;
永久存儲:存在于區塊鏈狀態層。
假設執行下面的樹(S代表永久存儲,M代表臨時存儲):
1.A調用B;
2.B設置B.S[0]=5,B.M[0]=9 ;
3.B調用C;
4.C調用B。
此時,如果B試圖讀取B.S[0],它將得到B前面存入的數據,也就是5;但如果B試圖讀取B.M[0],它將得到0,因為B.M是臨時存儲,讀取它的時候是虛擬機的一個新的實例。
在一個內部調用中,如果設置B.M[0] = 13和 B.S[0] = 17 ,然后內部調用和C的調用都終止,再執行B的外部調用,此時讀取M,將會看到B.M[0] = 9(此值在上一次同一VM執行實例中設置的),B.S[0] = 17。如果B的外部調用結束,然后A再次調用B,將看到B.M[0] = 0,B.S[0] = 17。這個區別的目的是:1.每個執行實例都分配有內存空間,不會因為循環調用而減損,這讓安全編程更加容易。2.提供一個能夠快速操作的內存形式:因為需要修改樹,所以存儲更新必然很慢。
? 棧/內存模式
早期,計算狀態有三種:棧(stack,一個32字節標準的LIFO),內存(memory,可無限擴展的臨時字節數組),存儲(storage,永久存儲)。在臨時存儲端,棧和內存的替代方案是memory-only范式,或者是寄存器和內存的混合體(兩者區別不大,寄存器本質上也是一種內存)。在這種情況下,每個指令都有三個參數,例如:ADD R1 R2 R3: M[R1] = M[R2] + M[R3] 。選擇棧范式的原因很明顯,它使代碼縮小了4倍。
? 單詞大小32字節
在大多數結構中,如比特幣,單詞大小是4或8字節。4或8字節對存儲地址或加密計算來說局限性太大了。而太大的值又很難建立相應安全的gas模型。32字節是一個理想大小,因為它足夠存儲下許多加密算法的實現以及地址,又不會因為太大而導致效率低下。
? 我們有自己的虛擬機
我們的虛擬機使用java、Lisp或Lua等語言開發。我們認為開發一款專業的虛擬機是值得的,因為:
1. 我們的VM規范比其他許多虛擬機簡單的多,因為其他虛擬機為復雜性付出的代價更小,也就是說它們更容易變得復雜;然而,在我們的方案中每額外增加一點復雜性,都會給集約化發展帶來障礙,以及潛在的安全缺陷,比如造成共識失敗,這就讓我們的復雜性成本很高,因而不容易造成復雜;
2. 我們的VM更加專業化,如支持32字節;
3. 我們不會有復雜的外部依賴,復雜的外部依賴會導致我們安裝失敗;
4. 完善的審查機制,可以具體到特殊的安全需求;對外部VM而言,這一點無論如何都是必要的。
? 使用了可變、可擴展的內存大小
固定內存的大小是不必要的限制,太小或太大都不合適。如果內存大小是固定的,每次訪問內存都需要檢查訪問是否超出邊界,顯然這樣的效率并不高。
? 棧大小沒有限制
沒什么特別理由!許多情況下,該設計不是絕對必要的;因為,gas的開銷和區塊層gas的限制總是會充當每種資源消耗的上限。
? 1024調用深度限制
許多編程語言在棧的深度過大時觸發中斷比在內存過載時觸發中斷的策略要快的多。所以區塊中gas限制所隱含的限制是不夠的。
? 無類型
為了簡單起見,可以使用DIV, SDIV, MOD, SMOD的有符號或無符號的操作碼代替(事實證明,對于操作碼ADD和MUL,有符號和無符號是對等的);轉換成定點運算在所有情況下都很簡單,例如,在32位深度下,a * b -》 (a * b) / 2^32, a / b -》 a * 2^32 / b ,+, - 和 * 在整數下不變。
VM中某些操作碼的函數和作用很容易理解,但也有一些不太好理解,以下是一些特殊的原因:
*? ADDMOD, MULMOD *
大多數情況下,addmod(a, b, c) = a * b % c,但在橢圓曲線算法中,使用的是32字節模數運算,直接執行a * b % c 實際上是在執行((a * b) % 2^256) % c會得到完全不同的結果。計算公式a * b % c 使用32字節空間的32字節值是非常不常見且繁瑣。
? SIGNEXTEND
SIGNEXTEND操作碼的作用是為了方便從大的有符號整數到小的有符號整數的類型轉換。小的有符號整數是很有用的,因為未來的即時編譯虛擬機可能會檢測長時間運行的代碼塊,小的有符號整數能加快處理。
? SHA3
在以太坊代碼中SHA3作為安全的高強度的hash集合應用非常廣泛,通常在使用存儲器時需要使用Hash函數來確保安全,以防止惡意沖突,在驗證默克爾樹和類似以太坊的數據結構時也需要使用到Hash函數。重要的是,與SHA3的相似的hash函數,如SHA256,ECRECVOR,RIPEM160不是以操作碼的形式包含在里面,而是以偽合約的形式。這樣做的目的是將它們放在一個單獨的類別中,如果當我們以后提出適當的“本地擴展”系統時,可以添加更多這樣的合約,而不需要擴展操作碼。
? ORIGIN
ORIGIN操作碼由交易的發送者提供,主要的作用是允許合約退回支付的gas。
? COINBASE
COINBASE的主要作用是:1.如果使用COINBASE操作碼,則允許子貨幣對網絡安全作出貢獻;2.開放使用礦工作為一個去中心化的經濟體,來設置基于子共識的應用,如Schellingcoin。
? PREVHASH
PREVHASH作為一個半安全的隨機來源,允許合約評估上一個區塊的默克爾樹狀態證明,而不需要高度復雜的遞歸結構“以太坊輕客戶端”。
? EXTCODESIZE, EXTCODECOPY
主要的作用是讓合約依據模板檢查其他合約的代碼,甚至是在與其他合約交互前,模擬它們。
? JUMPDEST
當跳轉(jump)目的地限制在幾個索引時(尤其是,動態目的跳轉的計算復雜度是O(log(有效挑戰目的數量)),而靜態跳轉總是恒定的),JIT虛擬機實現起來更簡單。于是,我們需要:1.對有效變量跳轉目的地做限制;2.使用靜態而不是動態跳轉的激勵方式。為了達到這兩個目標,我們定下了以下規則:1.緊接著push后的跳轉可以跳到任何地方,而不僅是另一個jump;2.其他的jump只能跳轉到JUMPDEST。對跳轉的限制是必須的,你可以通過查看代碼中的先前操作來決定是靜態還是動態的跳轉。缺乏對靜態跳轉的需求是激勵使用它們的原因。禁止跳轉進入push數據也會加快JIT虛擬機的編譯和執行。
*? LOG *
LOG是事件的日志。
? CALLCODE
該操作碼允許合約使用自己的存儲器,在單獨的棧空間和內存中調用其他合約的“函數”。這樣可以在區塊鏈上靈活實現標準庫代碼。
? SELFDESTRUCT
允許合約刪除它自己,前提是它已經不需要存在了。SELFDESTRUCT并非立即執行,而是在交易執行完之后執行。這是因為這樣做可以恢復那些執行后大大增加了緩存復雜度的SELFDESTRUCT操作碼。
? PC
盡管理論上不需要PC操作碼,因為所有的PC操作碼都可以根據將push操作的索引加入實際程序計數器來代替實現,但使用PC可以創建獨立代碼的位置(可復制粘貼到其他合約的編譯函數,如果它們以不同索引結束,不要打斷)。
注釋:
① UTXO: unspent transaction outputs。字面理解是:有效的交易輸出,它是比特幣協議中用于存儲交易信息的數據結構。
② Nonce,Number used once或Number once的縮寫,在密碼學中Nonce是一個只被使用一次的任意或非重復的隨機數值,在加密技術中的初始向量和加密散列函數都發揮著重要作用,在各類驗證協議的通信應用中確保驗證信息不被重復使用以對抗重放攻擊(Replay Attack)。
③ 嵌套數組:創建一個數組,并使用其他數組填充該數組。如數組pets:
var cats : String[] = [“Cat”,“Beansprout”, “Pumpkin”, “Max”];
var dogs : String[] = [“Dog”,“Oly”,“Sib”];
var pets : String[][] = [cats, dogs];
④ 行程編碼(run-length-encoding):一種統計編碼。主要技術是檢測重復的比特或字符序列,并用它們的出現次數取而代之。(百度百科)
⑤ 布隆過濾器:由 Howard Bloom 在 1970 年提出的二進制向量數據結構,它具有很好的空間和時間效率,被用來檢測一個元素是不是集合中的一個成員。(百度百科)
⑥ uncle:A挖出區塊后廣播途中,B也挖出了區塊(過時區塊),此時區塊鏈會出現分叉。過時分叉上的區塊就叫uncle區塊。它不是這個塊的父區塊,父區塊的兄弟區塊(平級關系)。












































 工商網監
工商網監
評論